3. SQL 기초
3.1 DCL
3.1.1 부속질의
"가장 비싼 도서의 이름은 무엇인가?" 라는 질문에 대한 답을 구한다고 생각해 보자. 가장 비싼 도서의 이름은 다음과 같이 구할 수 있다.
SELECT MAX(price)
FROM book;만약 가장 비싼 도서의 가격을 알고 있다면 가격이 35,000원인 도서의 이름을 바로 검색하면 된다.
SELECT bookname
FROM book
WHERE price = 35000;이 두 질의를 하나의 질의로 작성할 수 있는가? 가능하다. 두 번째 질의의 35000 값 위치에 첫 번째 질의를 대치하면 된다.
질의 3-28 가장 비싼 도서의 이름을 나타내시오.
SELECT bookname FROM book WHERE price = (SELECT MAX(price) FROM book);
위와 같이 SELECT 문의 WHERE 절에 또 다른 테이블 결과를 이용하기 위해 다시 SELECT 문을 괄호로 묶는 것을 부속질의라고 한다. 부속질의의 실행 순서는 1)WHERE 절의 부속질의를 먼저 처리하고 2)전체질의를 처리한다.
부속질의는 SQL 문이므로 결과는 테이블로 반환된다. 결과 테이블은 다음 네 가지 중 한 가지가 된다
단일행-단일열(1X1), 다중행-단일열(nX1), 단일행-다중열(1Xn), 다중행-다중열(nXn)
[질의3-28]에서는 부속질의의 결과가 단일행-단일열(1X1)로 한 개의 결과를 반환한다. 부속질의의 결과가 다중행-단일열(nX1)로 여러 개의 값을 반환하면 IN 키워드를 사용한다. 예를 들어 도서를 구매한 적 있는 고객의 이름을 알려면 어떻게 해야 할까?
도서를 구매한 적이 있는 고객은 여러 명이므로 다중행-단일열(nX1)이 된다. 따라서 먼저 orders 테이블에서 주문 내역을 살펴보고, 주문한 고객의 고객번호를 찾아야 한다.
SELECT custid
FROM orders;orders 테이블에서 도서를 주문한 고객번호를 찾으면 [1, 2, 3, 4]다. 박세리를 제외한 모든 고객이 도서를 구매한 적 있다. 다음으로, 찾은 고객번호를 이용하여 customer 테이블에서 고객의 이름을 찾는다.
SELECT name
FROM customer
WHERE custid IN (1, 2, 3, 4);이제 두 질의를 하나로 합쳐보자. 두 번째 질의의 IN 뒤에 첫 번째 질의문을 대치하면 다음과 같다.
질의 3-29 도서를 구매한 적이 있는 고객의 이름을 검색하시오.
SELECT name FROM customer WHERE custid IN (SELECT custid FROM orders);
세 개 이상의 중첩된 부속질의도 가능하다. 예를 들어 대한미디어에서 출판한 도서를 구매한 고객의 이름을 알고 싶다고 하자. 먼저 book 테이블에서 출판사가 대한미디어인 도서번호를 구하고, 이 도서번호를 이용하여 orders 테이블에서 도서를 주문한 고객들의 고객번호를 구한다. 다음으로 고객번호를 이용하여 customer 테이블에서 고객의 이름을 구한다.
질의 3-30 대한미디어에서 출판한 도서를 구매한 고객의 이름을 나타내시오.
SELECT custid FROM orders WHERE bookid IN(SELECT bookid FROM book WHERE publisher LIKE '대한미디어')
위 문법을 이해하려면 아래에서부터 읽어야 한다.
부속질의간에는 상하 관계가 있다. 하위 부속질의를 먼저 실행하고 그 결과를 이용하요 상위 부속질의를 실행한다. 반면, 상관 부속질의는 상위 부속질의의 투플을 이용하여 하위 부속질의를 계산한다. 즉, 상위 부속질의와 하위 부속질의가 독립적이지 않고 서로 관련을 맺고 있다.
예를 들어 출판사별로 출판사의 평균 도서 가격보다 비싼 도서를 구한다고 하자. 출판사 굿스포츠를 살펴보면 모두 3권의 도서를 출판하였고, 3권의 평균 가격은 7,000원이며, 3권 중 7,000원보다 비싼 도서는 '피겨 교본'이다. 이 문제는 평균을 구한 후 평균보다 비싼 도서를 구해야 하므로 부속질의 없이 단독 SQL문으로 작성하기 어렵다. 하위 부속질의는 상위 부속질의에서 도서와 출판사가 주어지면 종속적으로 출판사의 도서 평균을 구한다. 상위 부속질의는 이 도서가 평균보다 비싼지 비교한다.
질의 3-31 출판사별로 출판사의 평균 도서 가격보다 비싼 도서를 구하시오.
SELECT b1.bookname FROM book b1 WHERE b1.price >(SELECT AVG(b2.price) FROM book b2 WHERE b2.publisher = b1.publisher);
부속질의와 조인은 여러 테이블을 SQL문에서 다룬다는 점에서 유사하지만 몇 가지 차이점이 있다. 부속질의를 사용하면 SELECT문에 나오는 결과 속성을 FROM절의 테이블에서만 얻을 수 있고, 조인을 이용하면 조인한 모든 테이블에서 결과 속성을 얻을 수 있다. 한편, 조인에서는 부속질의로 가능한 모든 것을 할 수 있다. 그러나 조인을 이용해 부속질의를 작성해 보면, 부속질의만의 편리함과 간결함이 있음을 알 수 있다. 특히 한 개의 테이블에서만 결과를 얻는 여러 테이블 질의는 조인보다 부속질의로 작성하는 것이 훨씬 편하다.
3.1.2 EXISTS
EXISTS는 상관 부속질의문 형식이다. EXISTS는 원래 단어에서 의미하는 것과 같이 조건에 맞는 투플이 존재하면 결과에 포함시킨다. 즉, 부속질의문의 어떤 행이 조건에 만족하면 참이다. 반면 NOT EXISTS는 부속질의문의 모든 행이 조건에 만족하지 않을 때만 참이다. EXISTS와 NOT EXISTS는 상관 부속질의문의 다른 형태다. 예를 들어 도서를 주문한 고객의 이름을 찾으려면 고객 중 orders 테이블에 고객번호가 있는지 확인하면 된다.
질의 3-33 주문이 있는 고객의 이름과 주소를 나타내시오.
SELECT name, address FROM customer cs WHERE EXISTS (SELECT * FROM orders od WHERE cs.custid = od.custid);
EXISTS는 상관 부속질의문 형식이기 때문에 SELECT문 처리는 내포된다. 실행 순서는 다음과 같다.
1. cs의 첫 행을 가져와서 부속질의문에 cs값으로 입력한다. 부속질의문 od의 어떤 행에서 cs의 고객번호와 같은 것을 찾으면 EXISTS는 참이 되어 cs의 첫 행에 대한 name과 address가 반환된다.
2. 다음으로 cs의 두 번째 행이 부속질의문에 입력된다. 같은 방식으로 부속질의문에서 SELECT문이 처리되고 EXISTS가 참인지 거짓인지 판단한다. 참이면 두 번째 행에 대한 name과 address가 반환된다. cs의 모든 행에 대하여 이 과정이 반복된다.
3.2 DDL
데이터를 저장하려면 먼저 데이터를 저장할 테이블 구조를 만들어야 한다. SQL의 DDL은 바로 이 구조를 만드는 명령이다. 테이블의 구조를 만드는 CREATE문, 구조를 변경하는 ALTER문, 구조를 삭제하는 DROP문이 있다.
3.2.1 CREATE문
테이블을 구성하고, 속성과 속성에 관한 제약을 정의하며, 기본키 및 외래키를 정의하는 명령어다. CREATE문의 문법은 다음과 같다.
CREATE TABLE 테이블이름
({속성이름 데이터타임
[NULL | NOT NULL | UNIQUE | DEFAULT 기본값 | CHECK 체크조건]
}
[PRIMARY KEY 속성이름(들)]
[FOREIGN KEY 속성이름 REFERENCES 테이블이름(속성이름)]
[ON DELETE {CASCADE | SET NULL}]
)문법에서 대문자는 키워드, {} 안의 내용은 반복 가능, []은 선택적으로 사용, |는 1개를 선택, <>는 해당되는 문법 사항이 있음을 나타낸다.
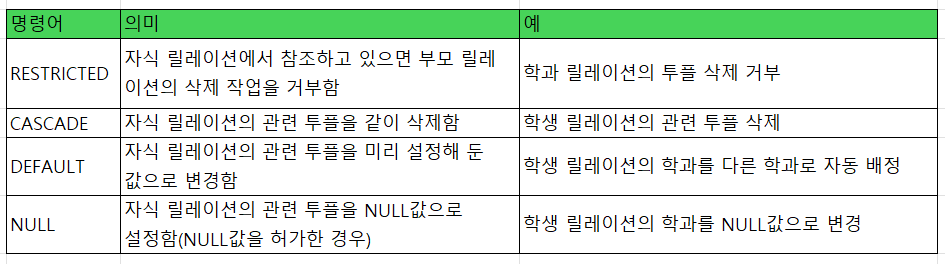
NOT NULL은 NULL값을 허용하지 않은 제약, UNIQUE는 유일한 값에 대한 제약, DEFAULT는 기본값 설정, CHECK는 값에 대한 조건을 부여할 때 사용된다. PRIMARY KEY는 기본키를 정할 때, FOREIGN KEY는 외래키를 정할 때, ON DELETE는 투플 삭제 시 외래키 속성에 대한 동작을 나타낸다. ON DELETE 옵션으로는 CASCADE, SET NULL이 있으며, 명시하지 않으면 RESTRICT(NO ACTION)이다.
질의 3-34
다음과 같은 속성을 가진 newbook 테이블을 작성하시오. 정수형은 INTEGER를 사용하며 문자형은 가변형 문자 타입인 VARCHAR을 사용한다.
- bookid - INTEGER
- bookname - VARCHAR(20)
- publisher - VARCHAR(20)
- price - INTEGER
풀이
CREATE TABLE newbook( bookid INTEGER, bookname VARCHAR(20), publisher VARCHAR(20), price INTEGER);
여기서 잠깐! 문자형 데이터타입 CHAR, VARCHAR:
CHAR(n)은 n 바이트를 가진 문자형 타입이다. 저장되는 문자의 길이가 n보다 작으면 나머지는 공백으로 채워서 n 바이트를 만들어 저장한다. VARCHAR(n) 타입도 n바이트를 가진 문자형 타입이지만 저장되는 문자의 길이만큼만 기억장소를 차지하는 가변형이다.
작성한 newbook 테이블에는 아무 제약사항이 없다. 만약 기본키를 지정하고 싶다면 다음과 같이 생성한다. 기본키 속성에 괄호는 필수다.
CREATE TABLE newbook(
bookid INTEGER,
bookname VARCHAR(20),
publisher VARCHAR(20),
price INTEGER,
PRIMARY KEY (bookid));또는 다음과 같이 써도 된다.
CREATE TABLE newbook(
bookid INTEGER PRIMARY KEY,
bookname VARCHAR(20),
publisher VARCHAR(20),
price INTEGER);만약 bookid 속성이 없어서 두 개의 속성 bookname, publisher가 기본키가 된다면 다음과 같이 괄호를 사용하여 복합키를 지정한다.
CREATE TABLE newbook(
bookname VARCHAR(20),
publisher VARCHAR(20),
price INTEGER,
PRIMARY KEY (bookname, publisher));newbook 테이블의 CREATE문에 좀 더 복잡한 제약사항을 추가하면 다음과 같다.
bookname은 NULL값을 가질 수 없고, publisher에는 같은 값이 있으면 안 된다. price에 값이 입력되지 않는 경우 기본값 10000을 저장한다. 또 가격은 최소 1,000원 이상으로 한다.
CREATE TABLE newbook(
bookname VARCHAR(20) NOT NULL,
publisher VARCHAR(20) UNIQUE,
price INTEGER DEFAULT 10000 CHECK(price >= 1000),
PRIMARY KEY (bookname, publisher));질의 3-35 다음과 같은 속성을 가진 newcustomer 테이블을 생성하시오.
- custid - INTEGER, 기본키
- name - VARCHAR(40)
- address - VARCHAR(40)
- phone - VARCHAR(30)
풀이
CREATE TABLE newcustomer( custid INTEGER PRIMARY KEY, name VARCHAR(40), address VARCHAR(40), phone VARCHAR(30));
참조 무결성 제약조건:
참조 무결성 제약조건은 외래키 제약이라고도 한다. 릴레이션 간의 참조 관계를 선언하는 제약조건이다. 자식 릴레이션의 외래키는 부모 릴레이션의 기본키와 도메인이 같아야 하며, 자식 릴레이션의 값이 변경될 때 부모 릴레이션의 제약을 받는다는 것이다. 즉 부모 릴레이션의 도메인과 다른 값으로 삽입/수정되거나, 반대로 자식 릴레이션에서 참조하는 값을 부모 릴레이션에서 삭제하거나 다른 값으로 변경할 경우 거부된다.
참조 무결성 제약조건은 개체 무결성 제약조건과 달리 단일 릴레이션에 대한 내용이 아니다. 따라서 참조 무결성 제약조건을 준수하기 위해서는 두 릴레이션 간의 참조 관계에 따라 좀 더 복잡한 처리를 수행해야 한다. 다음 그림에서 학과는 부모 릴레이션, 학생은 자식 릴레이션이다.

- 삽입(자식 릴레이션에서)
위 그림에서 학생 릴레이션에 새로운 투플(601, 박세리, 3001)이 삽입되는 과정을 살펴보자. DBMS는 먼저 도메인 무결성 제약조건을 확인한 후 개체 무결성 제약조건에 위배되는 값이 없는지 확인한다. 이후 학과코드 값 3001이 학과 릴레이션의 기본키에 존재하는지 확인한다. 3001은 학과 릴레이션에 없으므로 삽입이 거부된다. 이 경우 학과 릴레이션에 새로운 투플(3001, 수학과)를 삽입한 후 수행하면 정상적으로 진행된다. 참고로, 학생 릴레이션 생성 시 외래키인 학과코드 속성에 NULL값을 허용하였다면 학과코드 값이 없어도 삽입할 수 있다. 부모 릴레이션에서 삽입은 개체 무결성 제약조건에 따르면 된다. - 삭제(부모 릴레이션에서)
삽입과는 반대로 자식 릴레이션에서 투플이 삭제되는 경우 부모 릴레이션에는 아무런 영향을 주지 않으므로 바로 삭제할 수 있다. 그러나 부모 릴레이션에서 투플이 삭제되는 경우에는 문제가 발생할 수 있다. 예를 들어 학과 릴레이션에서 체육학과를 삭제해야 한다면 DBMS는 우선 학과 릴레이션의 하과코드를 참조하고 있는 다른 릴레이션이 없는지 찾는다.
이 경우 학생 릴레이션의 (401, 김연아, 2001)과 (402, 김연경, 2001)이 참조하고 있으므로 문제가 생긴다. 이 문제에 대한 조치 방법으로 다음과 같은 네 가지를 고려할 수 있다.
- 즉시 작업을 중지한다.
- 자식 릴레이션의 관련된 투플을 삭제한다.
- 초기에 설정된 다른 어떤 값으로 변경한다.
- NULL값으로 설정한다.
이처럼 DBMS에는 부모 릴레이션에서 투플을 삭제할 때 참조 무결성 제약조건을 수행하기 위한 네 가지 옵션이 있다. 이는 제약조건 선언 시 자식 릴레이션에도 지정해 주어야 한다.
- 수정(부모 릴레이션에서)
수정은 삭제와 삽입 명령이 연속해서 수행된다고 보면 된다. 부모 릴레이션의 수정이 일어날 때 삭제 옵션에 따라 처리된 후 문제가 없으면 다시 삽입 제약조건에 따라 처리된다. 학과 릴레이션의 학과코드 1001을 A001로 수정할 경우, 삭제 옵션에 따라(옵션이 RETRICTED일 경우에는 작업 중지) 자식 릴레이션의 관련 투플을 처리한 후, 삽입 제약조건에 따라 학과 릴레이션에 삽입한다.
질의 3-36 다음과 같은 속성을 가진 neworders 테이블을 생성하시오.
- orders - INTEGER, 기본키
- custid - INTEGER, NOT NULL 제약조건, 외래키(newcustomer.custid, 연쇄 삭제)
- bookid - INTEGER, NOT NULL 제약조건
- saleprice - INTEGER
- orderdate - DATE
풀이
CREATE문에서 외래키를 생성해 보자. neworders 테이블은 고객의 주문 사항을 저장하며, 속성을 orderid, custid, saleprice, orderdate를 갖는다. orderid는 주문 번호를 나타내는 기본키이며, custid는 newcustomer의 custid를 참조하는 외래키이다.CREATE TABLE neworders( orderid INTEGER, custid INTEGER NOT NULL, bookid INTEGER NOT NULL, saleprice INTEGER, orderdate DATE, PRIMARY KEY(orderid), FOREIGN KEY(custid) REFERENCES newcustomer(custid) ON DELETE CASCADE);
외래키 제약조건을 명시할 때는 주의할 점이 있다. 반드시 참조되는 테이블(부모)이 존재해야 하며 참조되는 테이블의 기본키어야 한다. 외래키 지정 시 ON DELETE 옵션은 참조되는 테이블의 투플이 삭제될 때 취할 수 있는 동작을 지정한다.
속성의 데이터 타입 부분에는 INTEGER, VARCHAR와 같은 데이터 타입을 명시한다.

3.2.2 ALTER문
ALTER문은 생성된 테이블의 속성과 속성에 관한 제약을 변경하며, 기본키 및 외래키를 변경한다. 기본 문법은 다음과 같다.
ALTER TABLE 테이블이름
[ADD 속성이름 데이터타입]
[DROP COLUMN 속성이름]
[ALTER COLUMN 속성이름 데이터타입]
[ALTER COLUMN 속성이름 [NULL | NOT NULL]
[ADD PRIMARY KEY(속성이름)]
[[ADD | DROP] 제약이름]
ALTER문에서 ADD, DROP은 속성을 추가하거나 제거할 때 사용하고 MODIFY는 속성을 변경할 때 사용한다. ADD<제약이름>, DROP<제약이름>은 제약사항을 추가하거나 삭제할 때 사용된다.
다음은 newbook 테이블을 생성하는 CREATE문이다.
CREATE TABLE newbook(
bookid INTEGER,
bookname VARCHAR(20),
publisher VARCHAR(20),
price INTEGER); 질의 3-37 newbook 테이블에 VARCHAR(13)의 자료형을 가진 isbn 속성을 추가하시오.
풀이
newbook 테이블에 isbn 속성을 추가하려면 다음과 같이 ALTER문을 사용해야 한다. 테이블을 수정할 때는 테이블을 삭제하고 다시 생성해도 되지만 테이블에 저장된 데이터를 그대로 두고 변경할 때는 ALTER문을 사용한다.ALTER TABLE newbook ADD isbn VARCHAR(13);
속성을 삭제하거나 제약사항을 변경하는 예를 보자.
질의 3-38 newbook 테이블에서 isbn 속성의 데이터 타입을 INTEGER형으로 변경하시오.
ALTER TABLE newbook MODIFY isbn INTEGER;
질의 3-39 newbook 테이블의 isbn 속성을 삭제하시오.
ALTER TABLE newbook DROP COLUMN isbn;
질의 3-40 newbook 테이블의 bookname 속성에 NOT NULL 제약조건을 적용하시오.
ALTER TABLE newbook MODIFY bookname VARCHAR(20) NOT NULL;
질의 3-41 newbook 테이블의 bookid 속성을 기본키로 변경하시오.
ALTER TABLE newbook ADD PRIMARY KEY(bookid);
3.2.3 DROP 문
DROP문은 테이블을 삭제하는 명령이다. DROP문은 테이블의 구조와 데이터를 모두 삭제하므로 사용할 때 주의해야 한다. 데이터만 삭제하려면 DELETE문을 사용해야 한다. 문법은 다음과 같다.
DROP TABLE 테이블이름질의 3-42 newbook 테이블을 삭제하시오.
DROP TABLE newboook;
질의 3-43 newcustomer 테이블을 삭제하시오. 만약 삭제가 거절된다면 원인을 파악하고 관련된 테이블을 같이 삭제하시오(neworders 테이블이 newcustomer를 참조하고 있다).
DROP TABLE newcustomer;삭제하려는 테이블의 기본키를 다른 테이블에서 참조하고 있다면 삭제가 거절된다. newcustomer 테이블을 삭제하려면 이 테이블을 삭제하고 있는 neworders 테이블부터 삭제해야 한다.
3.3 DML
만들어진 테이블에 투플을 삽입/삭제/수정한다.
3.3.1 INSERT문
테이블에 새로운 투플을 삽입하는 명령이다. 문법은 다음과 같다.
INSERT INTO 테이블이름[(속성리스트)]
VALUES(값리스트);질의 3-44 book 테이블에 새로운 도서 '스포츠 의학'을 삽입하시오. 스포츠 의학은 한솔의학서적에서 출간했으며 가격은 90,000원이다.
INSERT INTO book(bookid, bookname, publisher, price) VALUES(11, '스포츠 의학', '한솔의학서적', 90000);
3장 연습문제
1.
- 박지성이 구매한 도서의 수
SELECT COUNT(*) AS num_books
FROM orders o
JOIN book b ON o.bookid = b.bookid
JOIN customer c ON o.custid = c.custid
WHERE c.name = '박지성';
- 박지성이 구매한 도서의 출판사 수
SELECT COUNT(DISTINCT b.publisher) AS num_publishers
FROM book b
JOIN orders o ON b.bookid = o.bookid
JOIN customer c ON o.custid = c.custid
WHERE c.name = '박지성';2.
- 2024년 7월 4일 ~ 7월 7일 사이에 주문받은 도서의 주문번호
SELECT orderid
FROM orders
WHERE orderdate BETWEEN '2024-07-04' AND '2024-07-07';- 2024년 7월 4일 ~ 7월 7일 사이에 주문받은 도서를 제외한 도서의 주문번호
SELECT orderid
FROM orders
WHERE orderdate NOT BETWEEN '2024-07-04' AND '2024-07-07';- 고객의 이름과 고객별 구매액
SELECT c.name, SUM(o.saleprice)
FROM customer c
JOIN orders o ON c.custid = o.custid
GROUP BY c.name;- 도서의 가격(book 테이블)과 판매가격(orders 테이블)의 차이가 가장 많은 주문 -> ABS는 집계함수 아님에 유의
SELECT o.orderid, b.bookname, ABS(b.price - o.saleprice) AS difference
FROM orders o
JOIN book b ON o.bookid = b.bookid
ORDER BY difference DESC
LIMIT 1;- 도서의 판매액 평균보다 자신의 구매액 평균이 더 높은 고객의 이름
SELECT c.name
FROM customer c
JOIN orders o ON c.custid = o.custid
GROUP BY c.name
HAVING AVG(o.saleprice) > (SELECT AVG(saleprice) FROM orders);
3.
- 박지성이 구매한 도서의 출판사와 같은 출판사에서 도서를 구매한 고객의 이름
SELECT DISTINCT c1.name
FROM customer c1
JOIN orders o1 ON c1.custid = o1.custid
JOIN book b1 ON o1.bookid = b1.bookid
WHERE b1.publisher IN (
SELECT b2.publisher
FROM book b2
JOIN orders o2 ON b2.bookid = o2.bookid
JOIN customer c2 ON o2.custid = c2.custid
WHERE c2.name = '박지성'
) AND c1.name != '박지성';- 두 개 이상의 서로 다른 출판사에서 도서를 구매한 고객의 이름
SELECT c.name
FROM customer c
JOIN orders o ON c.custid = o.custid
JOIN book b ON o.bookid = b.bookid
GROUP BY c.custid, c.name
HAVING COUNT(DISTINCT b.publisher) >= 2;- 전체 고객의 30% 이상이 구매한 도서
SELECT b.bookname
FROM book b
JOIN orders o ON b.bookid = o.bookid
GROUP BY b.bookname
HAVING COUNT(DISTINCT o.custid) > (
SELECT COUNT(DISTINCT c.custid) * 0.3
FROM customer c
);
4.
- 새로운 도서('스포츠 세계', '대한미디어', 10000원)이 마당서점에 입고되었다. 삽입이 안 될 경우 필요한 데이터가 있는지 더 찾아보시오.
INSERT INTO book (bookname, publisher, price)
VALUES ('스포츠 세계', '대한미디어', 10000);- '삼성당'에서 출판한 도서를 삭제하시오.
DELETE FROM book
WHERE publisher = '삼성당';- '이상미디어'에서 출판한 도서를 삭제하시오. 삭제가 안 되면 원인을 말하시오.
DELETE FROM book
WHERE publisher = '이상미디어';- 출판사 '대한미디어'를 '대한출판사'로 이름을 바꾸시오.
UPDATE book
SET publisher = '대한출판사'
WHERE publisher = '대한미디어';- (테이블 생성) 출판사에 대한 정보를 저장하는 테이블 bookcompany(name, address, begin)을 생성하고자 한다. name은 기본키이며 VARCHAR(20), address는 VARCHAR(20), begin은 DATE 타입으로 선언하여 생성하시오.
CREATE TABLE bookcompany (
name VARCHAR(20) PRIMARY KEY,
address VARCHAR(20),
begin DATE
);- (테이블 수정) bookcompany 테이블에 인터넷 주소를 저장하는 webaddress 속성을 VARCHAR(30)으로 추가하시오.
ALTER TABLE bookcompany
ADD COLUMN webaddress VARCHAR(30);- bookcompany 테이블에 임의의 투플 name = 한빛아카데미, address = '서울시 마포구', begin = 1993-01-01 webaddress = www.naver.com을 삽입하시오.
INSERT INTO bookcompany (name, address, begin, webaddress)
VALUES ('한빛아카데미', '서울시 마포구', '1993-01-01', 'www.naver.com');7.
SELECT *
FROM R
WHERE A = a2;SELECT A, B
FROM R;SELECT *
FROM R
JOIN S ON R.C = S.C;4. SQL 고급
4.1 내장 함수, NULL
-
str_to_date()는 문자열을 날짜 형식으로 바꾸며, 문자열과 format이 같아야 한다.
-
date_format()은 날짜 형식을 문자열로 바꾼다.
null은 아직 지정되지 않은 값이므로 =, <, >등과 같은 비교 연산자로 비교할 수 없다. null값의 연산을 수행하면 결과 역시 null로 반환된다.
집계 함수를 사용할 때 null값이 포함된 행에 대하여 다음과 같은 주의가 필요하다.
- 'null + 숫자' 연산의 결과는 null이다.
- 집계 함수를 계산할 때 null이 포함된 행은 집계에서 빠진다.
- 해당되는 행이 하나도 없을 경우 sum, avg 함수의 결과는 null이 되고, count 함수의 결과는 0이 된다.
null값을 찾을 때는 = 연산자가 아닌 is null을 사용하고, null이 아닌 값을 찾을 때는 is not null을 사용한다.
ifnull 함수는 null값을 다른 값으로 대치하여 연산하거나 다른 값으로 출력하는 함수다. ifnull함수를 사용하면 null을 임의의 다른 값으로 변경할 수 있다.
ifnull(속성, 값) : 속성이 null이면 '값'으로 대치한다.
sql문 결과로 나오는 행에 번호를 붙이거나 행번호에 따라 결과의 개수를 조절하는 방법은 무엇인가? mysql에서는 변수를 사용하여 처리한다. mysql에서 변수는 이름 앞에 @를 붙이며 치환문에는 set과 := 기호를 사용한다.
질의 4-11: 고객 목록에서 고객번호, 이름, 전화번호를 앞의 2명만 나타내시오.
set @seq := 0; select (@seq := @seq + 1) 순번, custid, name, phone from customer where @seq < 2;
4.2 부속질의
부속질의는 하나의 SQL문 안에 다른 SQL문이 중첩된 형태를 말한다. 부속질의는 주로 메인 쿼리의 조건에 따라 서브쿼리의 결과를 가져와서 메인 쿼리에서 사용하는 용도로 활용된다. 부속질의를 사용하여 다른 테이블에서 가져온 데이터로 현재 테이블에 있는 정보를 찾거나 가공하는 등의 작업을 수행할 수 있다. 예를 들어 마당서점 DB의 orders 테이블에서 주문 내역은 알 수 있지만 도서를 주문한 고객의 이름은 알 수 없다. 고객 이름과 주문 내역을 같이 보려면 orders 테이블과 customer 테이블을 연관시켜야 한다. 두 테이블의 관계를 기초로 박지성 고객의 주문 내역을 확인하려면 어떻게 해야 할까? 이 경우 조인 또는 부속질의를 사용한다.
- 조인을 사용할 경우: customer와 orders를 조인하여 필요한 데이터를 추출한다.
- 부속질의를 사용할 경우: customer 테이블에서 박지성 고객의 고객번호를 찾고, 찾은 고객번호를 바탕으로 orders 테이블에서 확인한다.
데이터가 대량일 경우 부속질의의 성능이 더 좋다.
실무에서는 where 부속질의를 중첩질의, select 부속질의를 스칼라 부속질의, from 부속질의를 인라인 뷰라 한다.
4.2.1 중첩질의-where 부속질의
중첩질의는 where절에서 사용되는 부속질의이다. where절은 보통 데이터를 선택하는 조건 또는 술어(predicate)와 함께 사용된다. 그래서 중첩질의를 술어 부속질의라고도 한다. 중첩질의는 주질의에 사용된 자료 집합의 조건을 where절에 서술한다. 주질의의 자료 집합에서 한 행씩 가져와 부속질의를 수행하며, 연산 결과에 따라 where절의 조건이 참인지 거짓인지를 확인하여 참일 경우 주질의의 해당 행을 출력한다.
비교 연산자 사용 시 부속질의가 반드시 단일 행, 단일 열을 반환해야 하며, 아닐 경우 질의를 처리할 수 없다. 처리 과정을 보면, 주질의의 대상 열 값과 부속질의의 결과 값을 비교 연산자에 적용하여 참이면 주질의의 해당 열을 출력한다.
in 연산자는 주질의의 속성값이 부속질의에서 제공한 결과 집합에 있는지 확인하는 역할을 한다. in 연산자에서 사용 가능한 부속질의는 그 결과로 다중행, 다중열을 반환할 수 있다. 주질의는 where절에 사용되는 속성값을 부속질의의 결과 값과 비교해 하나라도 있으면 참이 된다.
all, some 연산자는 비교 연산자와 함께 사용된다. all이나 some은 부속질의의 대상 범위를 지정하는 역할을 한다. > 연산자와 함께 사용할 경우, all은 최대, some은 최소의 역할을 한다.
4.2.2 스칼라 부속질의-select 부속질의
select절에서 사용되는 부속질의로, 부속질의의 결과 값을 단일행, 단일열의 스칼라값으로 반환한다. 만약 결과값이 다중행이거나 다중열이면 dbms는 그 중 어떤 행과 열을 출력해야 하는지 알 수 없어 에러를 출력한다. 또 결과가 없는 경우에는 null값을 출력한다. 스칼라 부속질의는 원칙적으로 스칼라 값이 들어갈 수 있는 모든 곳에 사용할 수 있으며, select문과 update set 절에 사용된다. 주질의의와 부속질의의 관계는 상관/비상관 모두 가능하다.
질의 4-17: 마당서점의 고객별 판매액을 나타내시오. (고객이름과 고객별 판매액 출력)
select (select name from customer cs where cs.custid = od.custid) 'name', sum(saleprice) 'total' from orders od GROUP BY od.custid;
orders 테이블은 마당서점의 매출 정보를 가지고 있다. 매출 정보만 확인하고자 한다면 orders 테이블만으로도 충분하다. 하지만 orders 테이블만 사용하면 고객번호, 도서번호와 같이 코드 값만 보이므로 고객 이름이나 도서 이름을 바로 확인하기 어렵다. 위 스칼라 부속질의에서, 주질의의 orders 테이블에서 필요한 데이터를 가져온 후 부속질의의 customer 테이블에서 custid를 기준으로 name을 가져와 최종 결과를 출력한다.
스칼라 부속질의는 select문과 함께 update문에서도 사용할 수 있다. orders의 bname 속성에는 null값이 저장되어 있다. 데이터를 입력하기 위해서는 모든 도서의 도서이름을 수정해야 한다. 다음은 bookid가 1번인 도서의 이름을 수정하는 예다.
update orders
set bname = '피겨 교본'
where bookid = 1이 명령문을 쓸 경우 모든 도서에 대하여 일일이 처리해야 하므로 비효율적일뿐만 아니라 데이터가 많으면 아예 쓸 수 없다. 이때 스칼라 부속질의를 사용하면 도서이름을 일괄 수정할 수 있다.
질의 4-18: orders 테이블에 각 주문에 맞는 도서이름을 입력하시오.
update orders set bname = (select bookname from book where book.bookid = orders.bookid);
4.2.3 인라인 뷰-from 부속질의
인라인 뷰는 from절에서 사용되는 부속질의를 말한다. from 절에는 테이블 이름이 들어가는데, 여기에 테이블 이름 대신 인라인 뷰 부속질의를 사용하면 보통의 테이블과 같은 형태로 사용할 수 있다. 부속질의의 결과 값은 다중행, 다중 열이어도 상관없다. 다만 가상의 테이블인 뷰 형태로 제공되기 때문에 상관 부속질의로 사용될 수는 없다.
질의 4-19 고객번호가 2 이하인 고객의 판매액을 나타내시오.
select name, sum(saleprice) from (select custid, name from customer where custid <= 2) cs, orders od where cs.custid = od.custid GROUP BY cs.name;
질의의 from절에는 두 개의 테이블이 있다. 실행 과정을 보면, 먼저 cs 테이블을 계산해서 가상의 테이블(뷰)를 만들고 od와 조인한다. 이를 customer 테이블과 orders 테이블을 조인한 후 고객번호가 2 이하인 고객만 출력하는 형태로 작성할 수도 있다. 그러나 그 방법을 사용하면 조인 결과 테이블에서 필요 없는 데이터를 삭제해야 하므로 성능이 저하된다. 인라인 뷰를 사용하면 조인에 참여하기 직전 customer 테이블에서 필요한 데이터만 뽑아 조인시킬 수 있으므로 처리 성능을 높일 수 있다.
