
DX트랙은 그저 데이터 분석만 하는 거 아니었어!?
- DX트랙이더라도 딥러닝까지 꼼꼼하게 배웁니다 ! ㅎㅎ
훌륭한 강사진분들이 아~주 쉽고 친숙해지도록 도와주세요 ㅎㅎ
딥러닝까지 배우는 에이블스쿨 이거 외않해;?
에이블스쿨하면 나도 데이터분석가가 되. 문송하지 않아도 되.
제가 가고싶은 분야에 있어 딥러닝이 어떻게 활용될지도 생각을 해보았는데요 !
딥러닝이 필요하지 않은 곳을 찾는게 어렵더라구요 ㅜㅜ!
저는 경영학과인지라금융분야에서의 딥러닝 활용을 생각했는데
주식 시장의 변동 예측, 고객 신용 평가, 사기 거래 탐지 등에 활용이 될 것 같네요 ㅎㅎ!!!
배워두면 어디든 써먹을 알아두면 쓸데 많은 지식입니다 !!ㅎㅎ딥러닝 기초 이론
퍼셉트론을 구성하는 노드는 인공신경망에서 정보를 처리하는 기본 단위
단층 퍼셉트론 : 노드 단위로 입력값에 가중치를 곱하고 이들 합이 특정 임계치를 넘으면 출력값으로 1을, 넘지않으면 0을 출력하는 형태로 0 또는 1의 출력을 생성
=> 간단한 패턴의 데이터 처리에 유효
다층 퍼셉트론 : 입력데이터에 가중치를 곱하고 이 결과를 합해 여러 은닉층을 통해 전파하는 순전파 과정을 거침, 그리고 이때 주로 시그모이드 함수(비선형활성화함수)를 사용
신경망에서 비선형 활성화 함수는 각 뉴런의 출력에 적용되어 네트워크가 비선형적인 복잡한 패턴을 학습할 수 있도록 합니다.
딥러닝 모델이 잘 학습된 것은 예측 결괏값이 실제 값에 가까워지며 오차가 최소화된 상태
- 역전파 : 출력에서 발생한 오차를 신경망을 거슬러 올라가며 각 층의 가중치가 오차에 얼마나 기여했는지 계산하고 정보를 사용해 가중치 업데이트
딥러닝은 최적화가 어려움
- 모델의 비선형성
- 고차원성과 과적함
- 그래디언트 소실 문제
- 하이퍼 파라미터의 민감성
딥러닝 모델링 시 고려사항
-
하이퍼 파라미터 : 사용자가 사전에 설정해야하는 값
-
배치크기 : 한번의 학습 단계에 사용되는 데이터 샘플 수, 메모리 사용량과 학습속도에 큰 영향 / 배치 크기가 크면 한 번에 많은 정보를 배우지만 속도가 느려지고, 작으면 빨리 배우지만 한 번에 적은 정보만 학습
-
학습률(Learning Rate) : 모델의 가중치를 어느정도로 업데이트할지 결정,
역전파 과정에서 계산된 그래디언트에 학습률을 곱해 가중치를 업데이트 -
에폭 수 (Epoch) : 학습 데이터를 몇 번 전체로 학습할지,
너무 많으면 학습시간이 길어지고, 과적합 초래 -
옵티마이저 : 손실함수를 최소화하기 위해 모델의 가중치를 어떻게 업데이트할지 결정
✓ 딥러닝 학습절차
▪ 가중치 초기값을 할당한다. (초기모델을만든다.)
▪ (초기)모델로 예측한다.
▪ 오차를 계산한다. (lossfunction)
▪ 가중치 조절: 오차를 줄이는 방향으로 가중치를 적절히 조절한다.(optimizer)
• 적절히 조절→ 얼마만큼 조절할지 결정하는 하이퍼 파라미터 : learning rate (lr)
▪ 다시 처음으로 가서 반복한다.
• 전체 데이터를 적절히 나눠서(mini batch) 반복: batch_size
• 전체 데이터를 몇 번 반복 학습할 지 결정: epoch
스케일링
딥러닝은 스케일링이 필수
▪ 방법1 : Normalization(정규화)
• 모든값의 범위를 0 ~ 1로 변환
방법2 : Standardization(표준화)
• 모든값을, 평균= 0, 표준편차= 1 로변환
# 스케일러 선언
scaler = MinMaxScaler()
# train 셋으로 fitting & 적용
x_train = scaler.fit_transform(x_train)
# validation 셋은 적용만!
x_val = scaler.transform(x_val)
#fit은 훈련 데이터에만 적용하고, 검증 데이터에는 훈련 데이터의 기준으로 transform만 하여 일관된 스케일링을 유지x_train.shape[0]은 행 개수(데이터 샘플의 수)를 의미
x_train.shape[1]은 열 개수(특성 수)를 의미
#x_train 데이터의 특성(feature) 수를 변수 nfeatures에 저장
nfeatures = x_train.shape[1] #num of columns
nfeatures# 메모리 정리
clear_session()
# Sequential 타입
model = Sequential([Input(shape = (nfeatures,)),
Dense(1) ])
#output = dense
# 모델요약
model.summary()컴파일(Compile)
모델이 학습할 준비를 하는 단계로, 손실 함수, 옵티마이저, 그리고 평가 지표를 설정하는 과정( 모델이 무엇을 목표로 학습할지 설정 )
model.compile( optimizer = Adam(learning_rate = 0.1)
, loss='mse')
손실 함수 (Loss Function):
모델이 얼마나 잘못 예측했는지 측정하는 기준입니다. 손실 함수는 모델이 예측과 실제 값 사이의 차이를 줄이기 위해 필요한 정보를 제공. 예를 들어, 이진 분류 문제에서는 binary_crossentropy가 많이 사용.
• 회귀모델: mse
• 분류모델: cross entropy
옵티마이저 (Optimizer):
모델이 손실을 줄이기 위해 가중치를 어떻게 업데이트할지 결정하는 알고리즘. Adam, SGD 등 다양한 옵티마이저가 있으며, 학습 속도와 정확도에 영향을 줌.
▪Adam
•최근 딥러닝에서 가장 성능이 좋은 Optimizer로 평가됨.
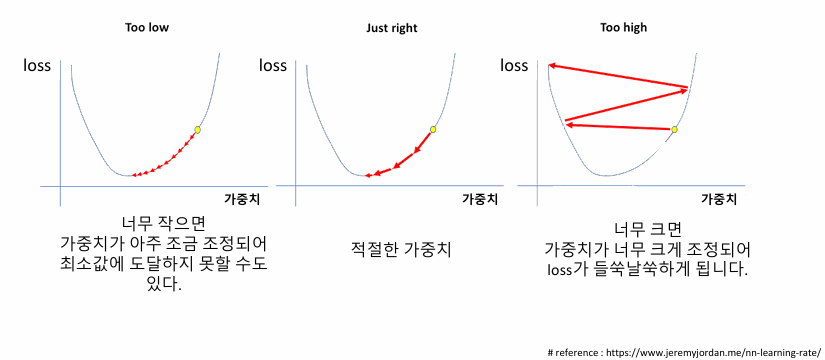
▪learning_rate
•업데이트 할 비율
•기울기(gradient)에 곱해지는 조정 비율
(걸음걸이의‘보폭’을 조정한다고 표현)
평가지표 (Metrics):
모델의 성능을 평가할 때 사용하는 지표. 예를 들어, accuracy는 분류 문제에서 예측이 얼마나 정확한지 나타냄. 학습 과정에서 평가 지표를 통해 모델의 성능을 확인 가능
학습
history = model.fit(x_train, y_train,
epochs = 20,
validation_split=0.2).history
✓Epoch 반복횟수
▪ 주어진 train set을 몇 번 반복 학습할 지 결정.
✓만약 Epoch = 10
▪ Train set을 10번 반복해서 학습하면서 최적의 가중치를 찾는다.
✓적정 Epoch의 수 찾기
▪ 최적의 값은 케이스마다 다름
▪ 하이퍼파라미터
✓validation_split = 0.2
▪ train 데이터에서 20%를 검증셋으로 분리
.history
▪ 학습을 수행하는 과정 중에 가중치가 업데이트되면서 학습 시 계산된 오차 기록
학습곡선
✓ 학습곡선이란 모델학습이 잘 되었는지 파악하기 위한 그래프
• 정답은 아니지만, 학습 경향을 파악하는데 유용.
▪ 각Epoch 마다 train error와 val error가 어떻게 줄어들고 있는지 확인
• Epoch = 10 : train data를 10번 반복 학습
-
Train error: 훈련 데이터(x_train)에 대해 모델이 예측한 값과 실제 값의 차이를 나타내는 오차, 모델이 훈련 데이터를 얼마나 잘 학습했는지 보여줍니다.
-
Val error: 검증 데이터(x_val)에 대해 모델이 예측한 값과 실제 값의 차이를 나타내는 오차, 이 값은 모델이 새로운 데이터에 대해 얼마나 일반화되었는지를 보여주는 지표입니다.
▪ 바람직한 학습 곡선
• ①초기 epoch에서는 오차가 크게줄고
• ②오차하락이 꺾이면서
• ③점차 완만해짐
그러나 학습곡선의 모양새는 다양함
✓바람직하지 않은 학습 곡선
▪ Case ① : 학습이 덜 됨
• 오차가 줄어들다가 학습이 끝남
• 조치: 학습을더!
▪ epoch수를늘리거나
▪ learning rate을 크게 한다.
✓바람직하지 않은 학습 곡선
▪ Case ② : train_err가 들쑥날쑥
• 가중치 조정이 세밀하지 않음
• 조치: 조금씩 업데이트
▪ learning rate을 작게
✓바람직하지 않은 학습 곡선
▪ Case ③ : 과적합
• Train_error는 계속줄어드는데,
val_error는 어느순간부터커지기시작
• 너무과도하게학습이된경우
• 조치
▪ Epoch수줄이기
은닉층O 모델링의 경우 ! (다층 퍼셉트론)
Hidden Layer
# Sequential 타입 모델 선언(입력은 리스트로!)
model3 = Sequential([Input(shape = (nfeatures,)),
Dense(2, activation = 'relu'),
Dense(1)])활성화함수
전 단계 레이어에서 각 노드로 들어온 값을 다음 레이어의 노드로 전달할 때 사용된다.
ReLU
다층퍼셉트론의 은닉층에서 선형 모델에 비선형성을 추가 할 때 사용됨.
활성화 함수를 사용하지 않으면 모델이 비선형성을 추가할 수 없게 됨.
여러 개의 Dense층이 있는데 단순히 가중치와 더하기만 하면 결과적으로 선형 함수를 이룸. => 결론적으로 활성화 함수 없이 모델을 구성하면 모델이 학습할 수 있는 표현의 다양성이 크게 줄어들어, 결국 비선형 문제를 해결할 수 없게 되는 것.
ReLU는 회귀 및 분류 모델 은닉층에서 비선형성을 추가하는 국룰 함수 !!!!!!!
+ 활성화함수에 대한 깊은 이해
은닉층 사용 함수
-
ReLU (Rectified Linear Unit):
특징: 입력이 0 이하일 때는 0을 반환하고, 0보다 클 때는 그대로 반환합니다.
비선형성을 제공하여 딥러닝 모델의 성능을 향상시킵니다.
학습 속도가 빠르고, 기울기 소실 문제를 완화할 수 있습니다.
단점: 입력이 0 이하일 때 기울기가 0이 되기 때문에, 이로 인해 뉴런이 "죽어버리는" 현상(Dead Neuron)이 발생할 수 있습니다. -
tanh (Hyperbolic Tangent):
특징: 출력 값이 -1과 1 사이로 정규화됩니다.
평균이 0에 가까워, 학습이 더 빨라질 수 있습니다.
단점: 여전히 기울기 소실 문제가 발생할 수 있습니다. -
Leaky ReLU:
특징: ReLU의 변형으로, 입력이 0 이하일 때도 작은 기울기를 제공합니다.
죽은 뉴런 문제를 완화하는 데 도움을 줄 수 있습니다.
출력층 사용 함수 (분류모델에서 사용됨, 회귀모델에서는 출력층 활성화함수 필요하지 않아 !)
-
Sigmoid:
특징: 출력 값이 0과 1 사이로 변환됩니다.
주로 이진 분류 문제의 출력층에서 사용됩니다.
은닉층에서 사용: Sigmoid는 은닉층에서도 사용될 수 있지만, 깊은 네트워크에서는 기울기 소실 문제로 인해 덜 선호. -
Softmax:
특징: 다중 클래스 분류에서 사용됩니다.
출력 값이 0과 1 사이로 변환되고, 모든 클래스의 확률 합이 1이 되도록 정규화됩니다.
이진분류 모델 모델링
은닉층에서 선형모델에 비선형성을 추가하기 위해 ReLU 활성화 함수 사용
출력증에서 결과를 0, 1로 변환하기 위해 Sigmoid 활성화 함수 사용
이진분류 손실함수 : binary_crossentropy
# 메모리 정리
clear_session()
# Sequential 모델 만들기
model = Sequential( [Input(shape = (nfeatures,)),
Dense( 1, activation= 'sigmoid')])
# 모델요약
model.summary()
model.compile(optimizer = Adam(learning_rate=0.01), loss ='binary_crossentropy')
history = model.fit(x_train, y_train,
epochs = 50, validation_split=0.2).history
dl_history_plot(history)이진분류 모델의 예측 및 검증 (예측값 후속처리)
#예측
pred = model.predict(x_val)
print(pred[:5])#검증
# activation이 sigmoid --> 0 ~ 1 사이의 확률값.
# 그러므로 cut-off value(보통 0.5)를 기준으로 잘라서 0과 1로 만들어 준다.
pred = np.where(pred >= .5, 1, 0)
print(pred[:5])0.5보다 크거나 같으면 1 반환, 작으면 0 반환
다중분류 모델 모델링
은닉층에서 선형모델에 비선형성을 추가하기 위해 ReLU 활성화 함수 사용
출력증에서 결과를 0, 1로 변환, 모든 클래스의 확률 합이 1이 되도록 정규화 Softmax 활성화 함수 사용
다중분류 손실함수 : crossentropy
다중분류는 전처리가 중요 !
다중분류는 y가 범주이고, 범주가 3개 이상인 경우
범주에 대한 인코딩 필요
정수로 인코딩하는 다중분류의 손실함수 => sparse_categorical_crossentropy
ex) setosa(0), versicolor(1), virginica(2)
# 메모리 정리
clear_session()
# Sequential
model = Sequential( [Input(shape = (nfeatures,)),
Dense( 3, activation = 'softmax')] )
# 모델요약
model.summary()
model.compile(optimizer=Adam(learning_rate=0.1), loss= 'sparse_categorical_crossentropy')
history = model.fit(x_train, y_train, epochs = 50,
validation_split=0.2).history
dl_history_plot(history)다중분류 모델의 예측 및 검증 (예측값 후속처리)
pred = model.predict(x_val)
pred[:5]
✓예측결과에대한후속처리
▪ ①예측결과: 각클래스별확률값
▪ ②그중가장큰값의인덱스로변환
• np.argmax()
pred_1 = pred.argmax(axis=1)
pred_1
