회귀(Regression) : 평균으로의 회귀
부모와 자녀 간 키의 관계를 관찰한 연구로부터 유래된 표현
부모 키가 너무 크면 자녀 키는 그보다 작은 경향이 있고
부모 키가 너무 작으면 자녀 키는 그보다 큰 경향이 있었다고 함
from sklearn.linear_model import LinearRegression
--> 선형회귀
from sklearn.preprocessing import PolynomialFeatures
--> 다항회귀
from sklearn.pipeline import Pipeline
평가지표
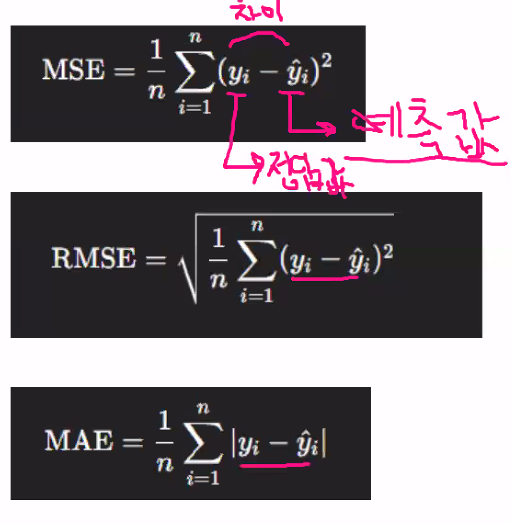
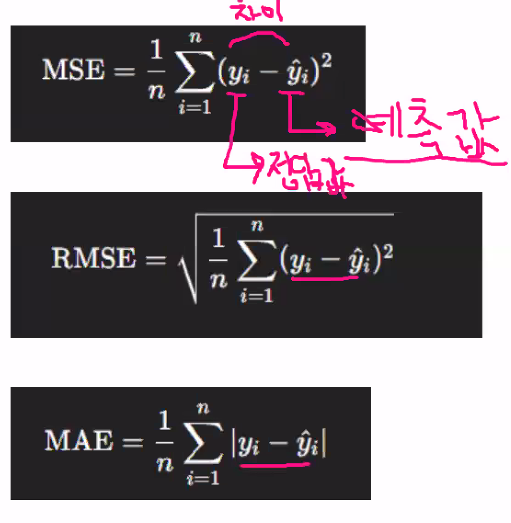
mae, mse, rmse : 오차 계산
- mae = mean_absolute_error(y_true, y_pred)
- mse = mean_squared_error(y_true, y_pred)
- rmse = np.sqrt(mean_squared_error(y_true, y_pred))
※ mae = 절대값, mse = 제곱
※ m = mean , e = error, r = root
※ mse보다는 rmse를 많이 씀
r2 (r스퀘어) : 얼마나 해석 능력이 좋은지 (0~1 사이. 1에 가까울수록 좋음. 음수가 나오면 대단히 잘못된 것..)
선형회귀 > 단순회귀 / 다중회귀
--> 코드 상으로는 차이가 없음. 데이터와 정의 상 차이가 있을 뿐.


❗다항회귀
- 비선형회귀
머신러닝에서는 n차항을 또다른 문자 X_2, X_3..로 보고 다중회귀로 처리 가능
대신 데이터 전처리 필요!
e.g. x^2 컬럼을 따로 새로 생성하면 됨. 컬럼 하나 더 늘어난 형태로 다중회귀 넣어주는 느낌.


규제 Regularization
극단적인 파라미터로 인해 오차가 튀게 됨
머신러닝은 오차가 커지면 커질수록 더 공격적으로 학습함
파라미터를 최대한 얌전히 만듦 --> 패널티(=오메가)
즉, 파라미터를 제한하는 느낌. 과적합을 막음
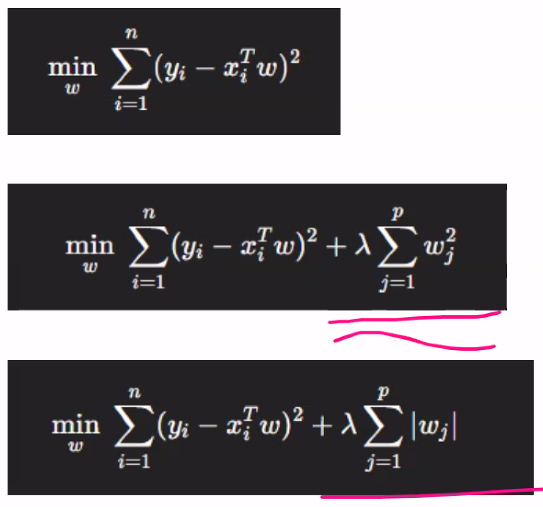
제곱 : Ridge , 절대값 : Lasso
람다(상수값) = 오메가항을 얼마나 강하게 넣어줄지 조정하는 역할. 규제항의 양을 많이 할지 적게 할지 결정함
from sklearn.linear_model import Ridge
ridge = Ridge(alpha=0.01, random_state=42,
from sklearn.linear_model import Lasso
lasso = Lasso(alpha=0.01,
