앙상블
배깅 기법
여러 개의 서로다른 모델을 만들고 평균내면 분산이 줄어듦
-> 병렬적
- 원본 데이터에서 복원추출(BOOTSTRAP)로 여러 데이터셋 생성
- 각각 독립적으로 모델 학습
- 결과를 평균(회귀) 또는 다수결(분류)
Random Forest
부스팅 기법
이전 모델의 오차를 다음 모델이 보완
-> 순차적
- 첫 모델 생성
- 오차 계산
- 오차를 예측하는 모델 생성
- 반복
XGB (Level-wise : 균형적으로 오차 보완), Light GBM (Leaf-wise : leaf에 집중해서 오차 보완), Cat Boost (범주형 변수 처리 능력)
각 앙상블 모델을 사용하는 경우
-랜덤포레스트 : 빠르고 간단하고 성능이 무난함
-XGB : 최고 성능을 목표로 할 경우
-Light GBM : 대용량 데이터
-Catboost👍 : 범주형 컬럼이 많을 때
a-> 전부 트리기반 모델. 스케일링을 하지 않아도 됨
※ Cat : category
랜덤 포레스트


XGB
from xgboost import XGBClassifier
#타겟/피처 분리
y = (df["class"] == ">50K").astype(int) # 1: >50K, 0: <=50K
X = df.drop(columns=["class"])
#One-Hot 인코딩 (XGBoost는 기본적으로 범주형 raw string을 못 받으니 변환)
X_ohe = pd.get_dummies(X, columns=cat_cols, drop_first=True)


Catboost
from catboost import CatBoostClassifier
#cat_features 지정 (전처리 없이 그대로 사용)
cat_cols = X.select_dtypes(exclude=["number"]).columns.tolist()
cat_idx = [X.columns.get_loc(c) for c in cat_cols]


경사하강법
Cost(= Loss= Error)가 가장 낮은 파라미터 찾기. 최적해 구하기
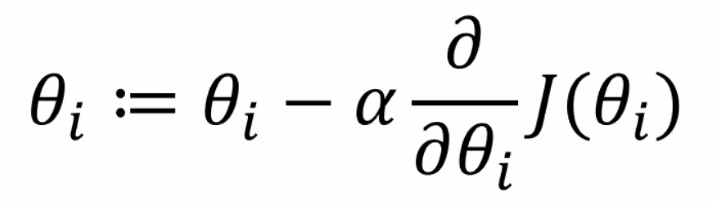
J: Loss function, theta: 파라미터, alpha: 학습률
-
쎄타에 대해서 오차를 편미분 -> 기울기 계산
- 쎄타가 바뀌는 것에 따라 오차가 얼마나 바뀌는가 -
기울이가 양수면, 파라미터는 음의 방향으로 조절.
기울이가 음수면, 파라미터는 양의 방향으로 조절해서 최소점으로 유도
- -> 수식에 '-'가 있는 이유
※ 파라미터와 하이퍼파라미터의 차이
파라미터는 모델 내부적으로 가지고 있는 파라미터(자동으로 결정 by 경사하강법)이고,
하이퍼파라미터는 사람이 조절하는 파라미터
코드
from sklearn.linear_model import SGDRegressor
파이프라인에서 줄 추가
pipe = Pipeline(...,
"sgd", SGDRegressor(random_state=42))
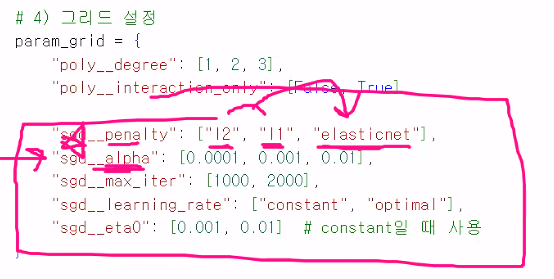
alpha : 규제강도. max_iter : 반복횟수, 몇 번 학습할지.
나머지 코드는 동일
주요 하이퍼파라미터
-max_iter 최대반복횟수
-learning_rate 학습률 전략
-eat0 초기학습률
