
Similarity
비슷한 문서 찾기
문서를 표현하는 방법 : Bag-of-Words

- 3중 어느 것이 비슷할까
- 1,2번이 유사한데 코드로 유사도를 어떻게 계산할지
- Bag-of-Words
- 문서를 정형화된 데이터로 표현하는 방법 중 하나
- 비정형 데이터를 정형 데이터인 벡터, 집합등으로 표현해 유사도 측정
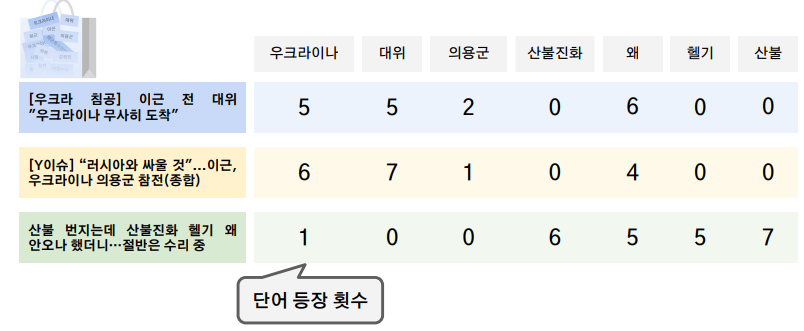
- 문서를 단어들의 중복집합(가방)으로 표현
- 단어가 얼마나 겹치는지를 판단


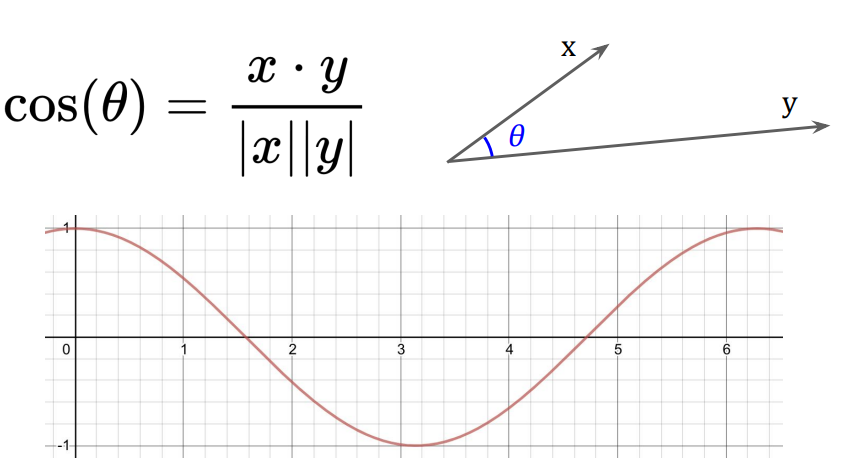
Cosine Similarity
- 문서를 Bag-of-Words로 표현한 후 단어마다 벡터로 표현
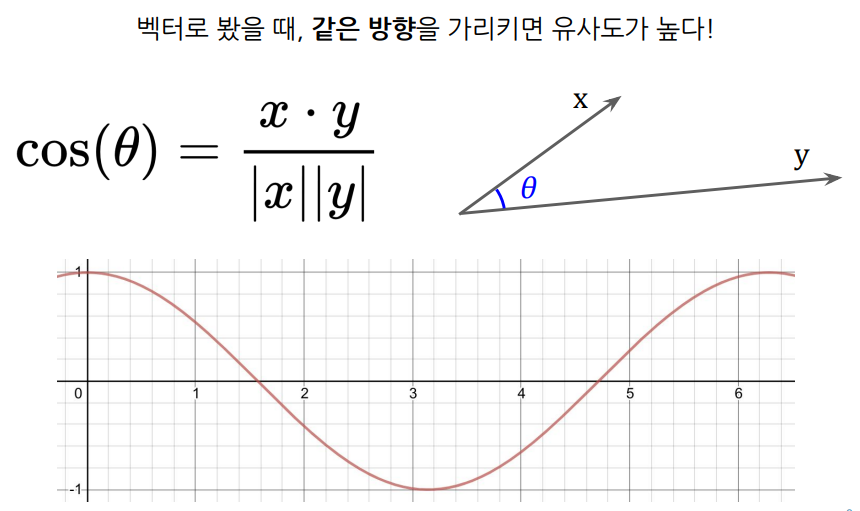
- 벡터간의 각도가 작으면(같은 방향을 가리키면) 값이 커지는 코사인을 활용
- 각각의 벡터간의 코사인 값을 구해 유사도를 구함
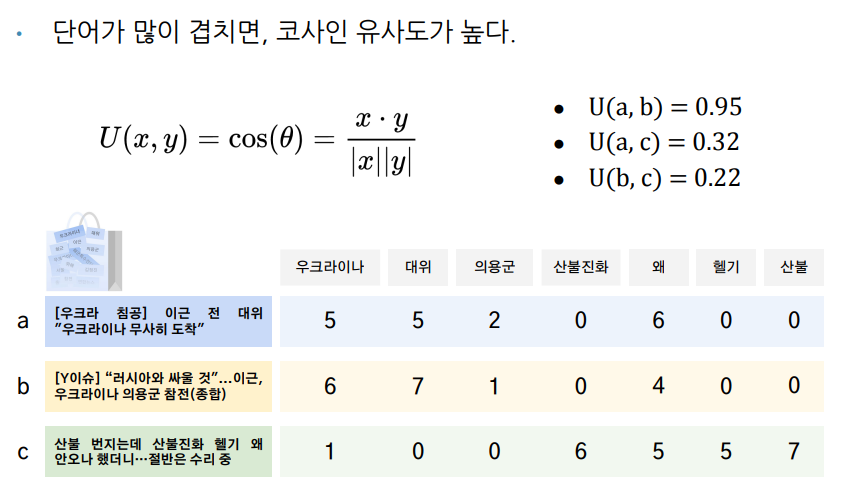
- a,b의 유사도 = 5x6 + 5x7 + 2x1 + 6x4 / sqrt(x의 크기 25+25+4+36) x sqrt(y의 크기 36 + 49 + 1 + 16)
Jaccard Similarity
- Bag-of-Words의 합집합과 교집합 사용
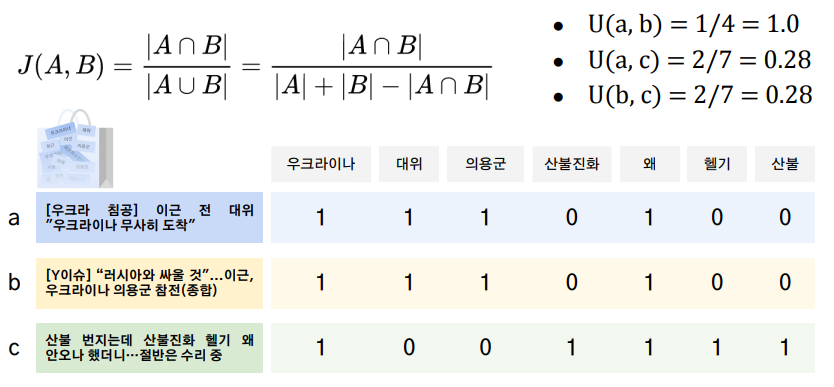
- u(a,b) = 4/4 = 1임
- 분모에 합집합을 사용하는 이유는 매우길거나 특별히 모든 단어를 집어넣은 파일과 유사도를 구할때 교집합만을 사용하면 실제 유사성과 관련없이 매우 높은 유사도(1에 가까운)가 나오기 떄문에 합집합을 패널티로 주기 위함
Bag-of-Words의 단점

- 위 문장과 같이 의미는 반대이지만 유사도가 1로 계산되는 경우가 있음
- 단어의 순서를 고려하지 않는다
- 자주 등장하는 단어가 유사도에 큰 영향을 미친다
- a, the, of, you등의 단어
- Sparsity : 다른 문서에서 등장하지 않는 단어가 훨씬 많다
- 한 문서에 10만 단어가 있으면 10만차원의 벡터를 만들어 다른 문서와 구분해야하는데 완전히 다른 주제의 문서라면 [1,0,0,0,0,0,...0,0]과 같은 벡터가 만들어짐
- 계산 시간과 정확도에 문제가 생김
- 새로운 단어가 등장하면?
- 새로운 단어는 BoW에서 아무런 의미가 없음
n-gram
- BoW개선
- 연달아 등장하는 단어 n개를 하나의 묶음으로 만듬
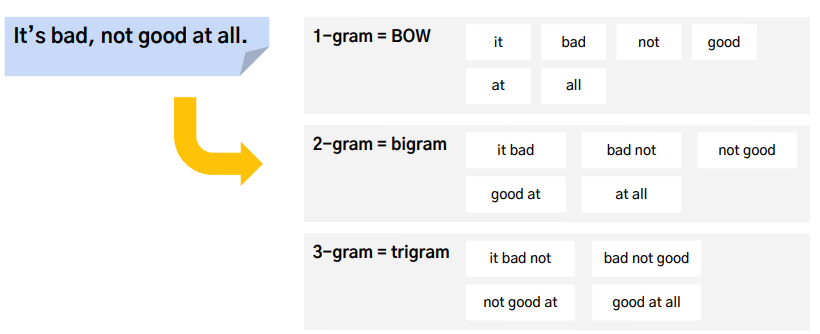
- 단어의 순서를 고려하고 자주 등장하는 단어의 비중이 줄어듬

- Sparsity는 오히려 더 심해짐
- 새로운 단어의 처리도 불가능
- 보통은 1-gram, 2-gram, 3-gram을 섞어서 사용하긴 함
TF - IDF
- 단어에 중요도를 부여함
- 이 문서에 자주 등장하고 다른 문서에는 잘 등장하지 않을수록 중요한 단어(이 문서에만 자주 등장하면 the, it같은 단어를 중요하게 생각할수도 있기 떄문)

- TF : 이 단어가 이 문서에서 얼마나 자주 등장했는지
- 해당단어 / 전체 단어
- DF : 이 단어가 모든 문서에서 얼마나 자주 등장했는지
- 해당 단어가 등장한 문서수 / 전체 문서수
- IDF : DF의 역수(값 보정을 위해 log를 씌우기도 함


- 다른 문서에서 적개 나오면 DF값이 낮아지고 점수화 하기 위해서 IDF로 역수를 취한 후 곱함
비슷한 드라마 찾기
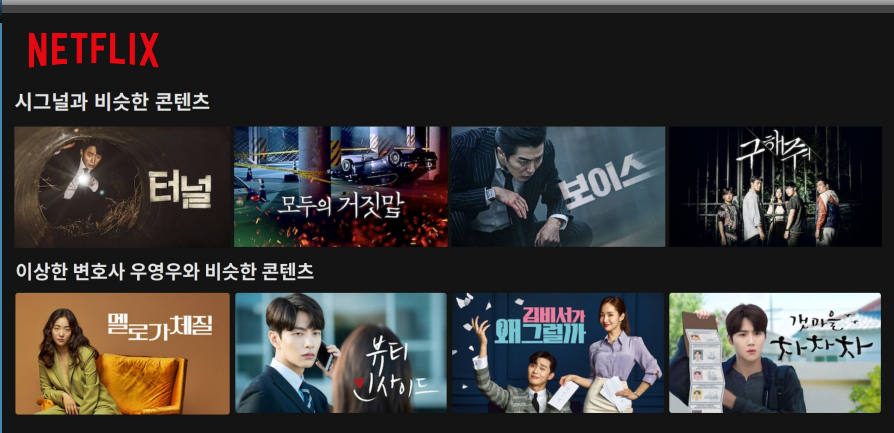
- 유사도를 어떻게 측정할 것인가
- 장르나 키워드의 유사도
- 사람들의 평가의 유사도(드라마 a,b의 한 사람의 평가가 유사하면 a,b도 유사할 것이다)
- 키워드
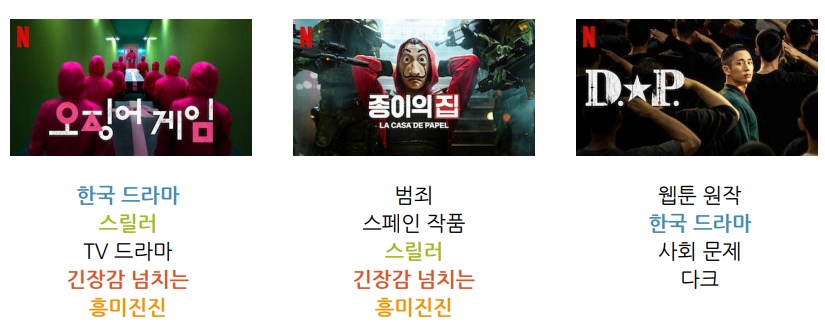
- 자카드 유사도
- 평가 유사도

- 평가를 벡터로 생각, 벡터간의 유사도를 구하면 된다(코사인 유사도)
- 내적/크기
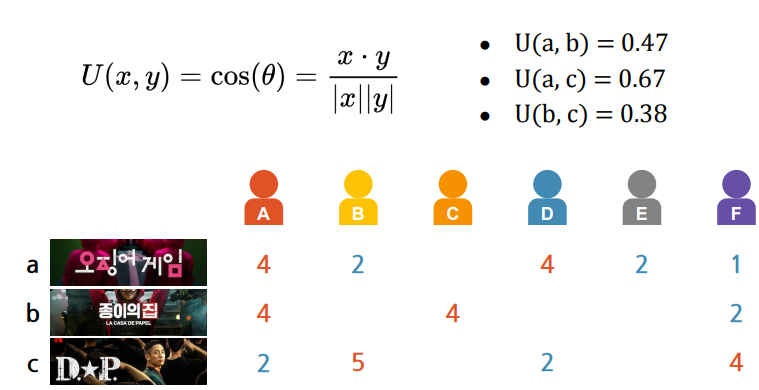
- a,c가 유사하게 나온 이유 : 평가 안한 부분을 0으로 채워서 0점이라는 같은 평가를 한 것으로 계산하게 됨
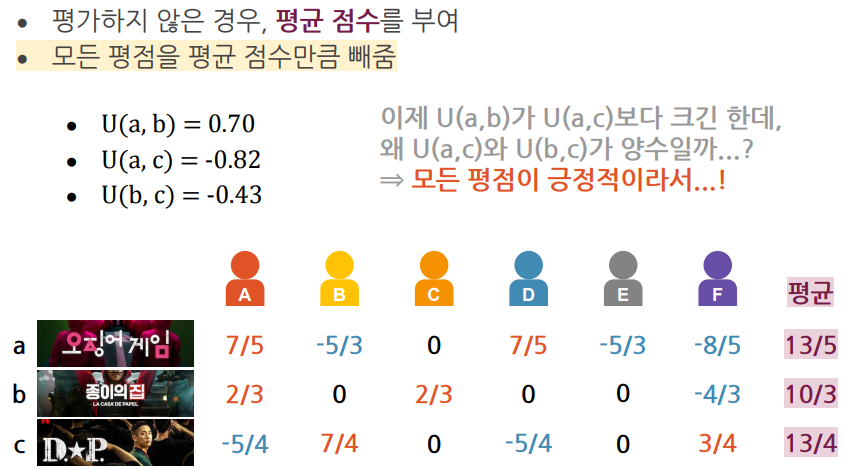
- 평가하지 않은 부분에 평균값을 부여

- 코사인 유사도는 범위가 -1과 1사이 유사하지 않은 드라마간에는 음수값을 부여하고 싶음
- 평균값을 0으로 판단하고 모든 값에서 평균값만큼 빼줌
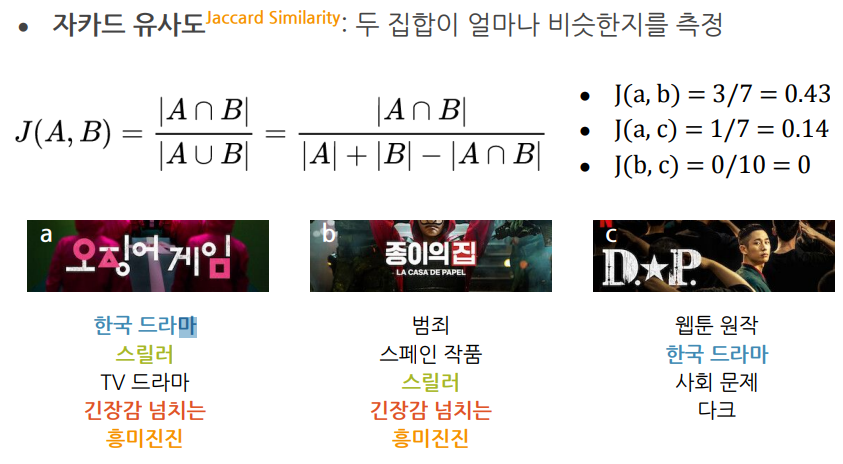
- 자카드 유사도(장르, 키워드)와 코사인 유사도(평가)에 가중치를 두어 2개를 같이 사용하여 점수를 부여할 수 있음(유사도 점수)
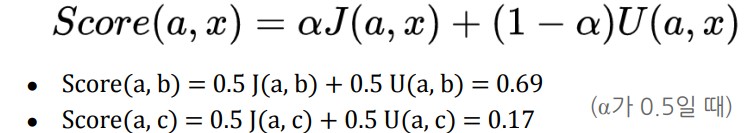


KMU SW