
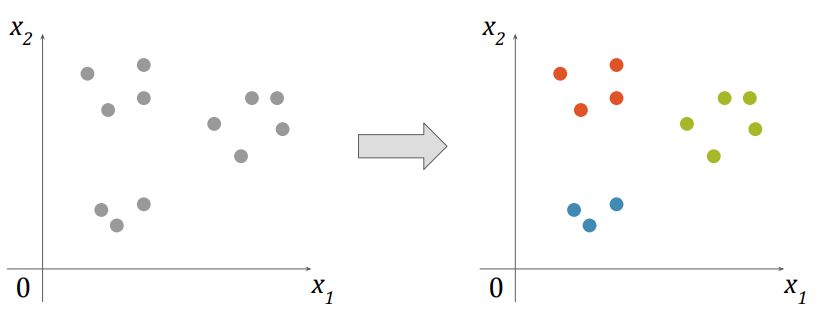
Clustering
비지도 학습중 하나
- 기계 학습(비지도 학습)중 하나임
- 데이터가 어떻게 구성되었는지 알아내는 문제

다차원 공간에서 여러개의 점들 중 서로 가까이 있는 점들을 서로 연관시키는 문제
- 인물 사진 분류(사진 중 닮은 사진 모으기)
- 활용 예시
- 비슷한 뉴스 모으기
- 스팸메일 분류
- 비슷한 성향의 사용자/영화 모으기
- 사진 압축
- 원본 이미지의 색 가지수를 줄일떄 비슷한 색끼리 묶는 것

K-Means Clustering
- 반복적인 연산을 통해 데이터를 k개의 클러스터로 분할하는 알고리즘
- 클러스터 분석 알고리즘
- 분할법(어떤 노드가 클러스터에 중복되게 포함하지 않도록 하는 것)
- 클러스터 개수 k는 사용자가 지정해야함
- 반복연산 사용
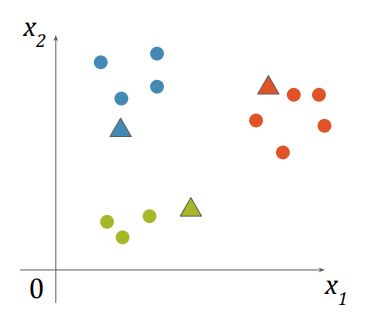
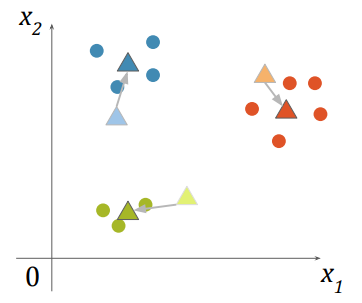
- 임의로 k개의 중심점을 생성
- 각각의 점을 가장 가까운 중심점의 클러스터에 포함 시킴
- 각 클러스터에 포함된 점들을 평균내어 새로운 중심점을 계산
- 그 후 다시 2번,3번을 반복
- 클러스터 변화가 없으면 종료
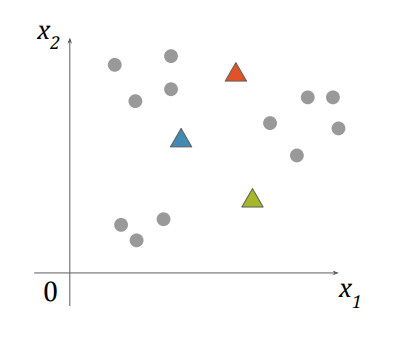
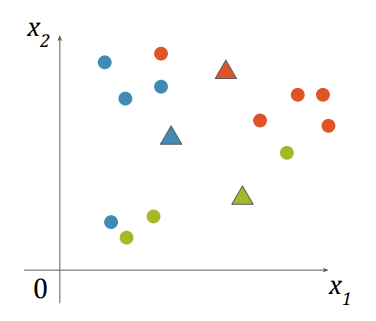
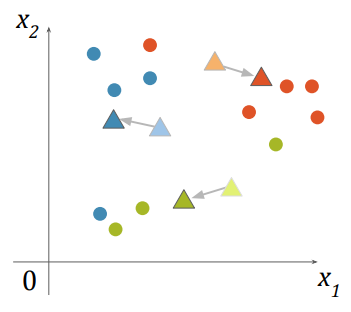
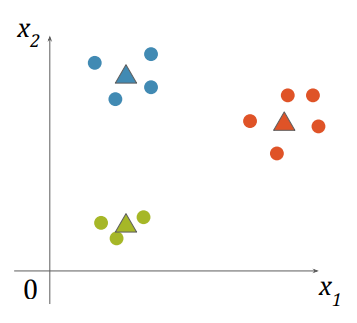
Local Optimum
- 초기화된 중심점에 의존하는 것
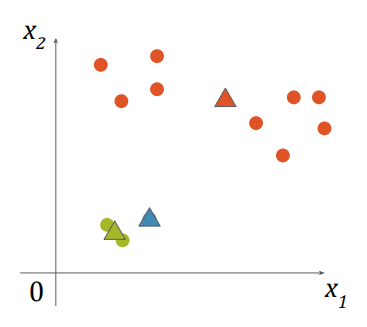
- 좋지 않은 결과가 나옴
중심점 초기화(Local Optimum을 피하기 위해)
- 중심점을 랜덤으로 여러번 시행
- 비어있는 클러스터가 생길 수 있음
- 데이터 점 들 중 임의로 중심섬을 선택
- 비어있는 클러스터가 생기지 않음
- 직접 중심점을 지정할 수도 있음
- 데이터를 얼추 알고 있을 때 사용 가능
- K-Means++
- 서로 가장 멀리 떨어진 점들을 중심점으로 사용
- 임의의 점 1개 지정
- 점에서 가장 멀리 떨어진 점을 중심점 1번으로 사용
- 중심점 1에서 가장 멀리 떨어진 점이 중심점 2
- 중심점 1,2둘에서 가장 멀리 떨어진 점이 중심점 3
- 서로 가장 멀리 떨어진 점들을 중심점으로 사용
K 값 선택
- 클러스터의 분산의 합이 낮으면 좋은 것
- k의 값을 1부터 증가시켜가면서 비용(분산)을 분석
- 비용의 감소가 급격히 줄어드는 지점을 선택
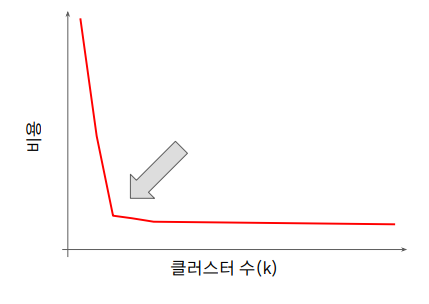
- 저 지점에서 k를 더 늘리면 비슷한 데이터에서 클러스트가 여러개 생길 수 있음

다른 클러스터링 방법


KMU SW