경사하강
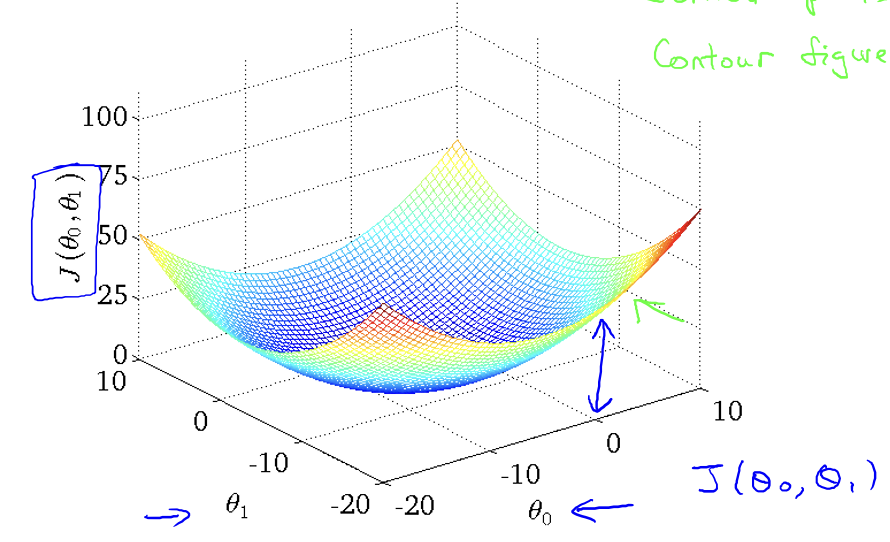
- 위처럼 convex한 함수는 항상 최적의 해를 찾음(local과 global이 같음)
- 하지만 실제모델은 저런 모양은 아니다
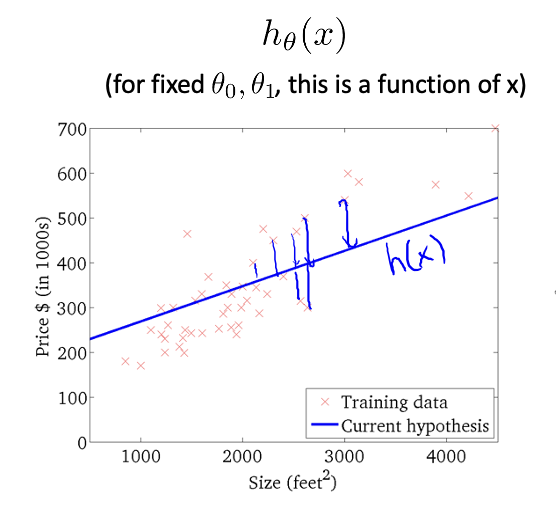
- 경사하강법으로 최적의 해를 찾아도 에러가 크면 다른 모델을 사용해야할 필요가 있다
Batch Gradient Descent
- 모든 트레이닝 데이터를 사용하는 일반적인 방법
- 트레인 데이터가 많으면 전부 사용하지 않는 방법도 있긴한데 여긴 없음
행렬
- (3,2) -> 밑으로 먼저 3
- 벡터 : nx1형태의 행렬이 벡터
선형회귀
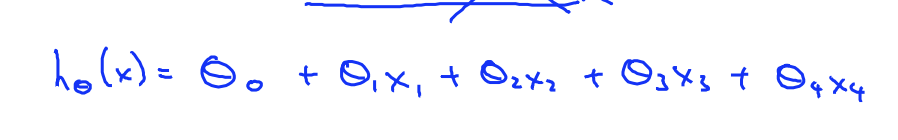
- 선형모델 유지를 위해 제곱형태가 없어야함
- 세타0를 바이오스로 사용할때 벡터곱에서 1를 곱하는 형식으로 따로 세타0을 더하는 과정을 생략하기도 함
- feature의 범위
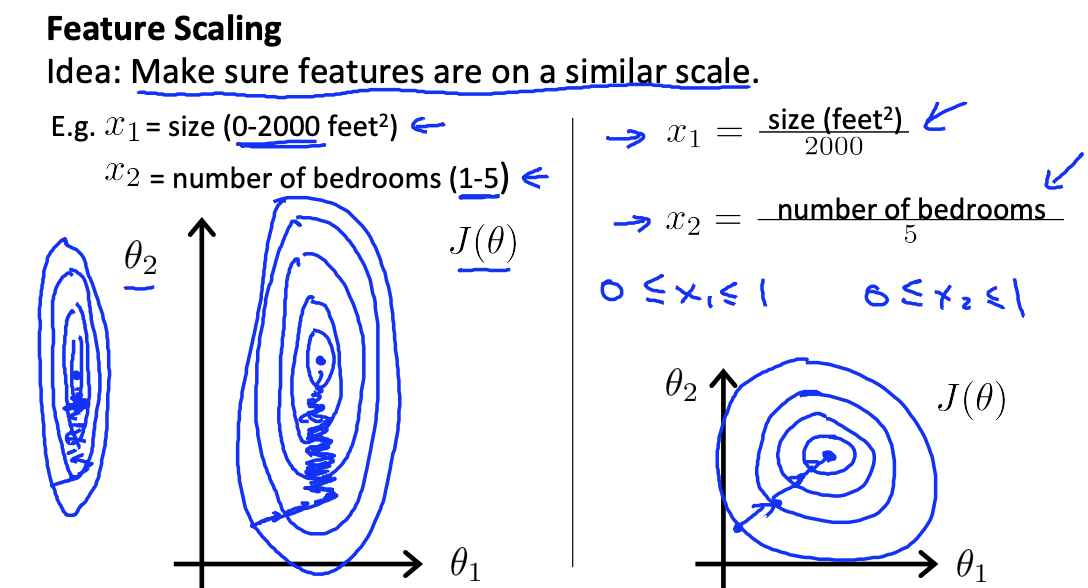
- 피처들을 동시에 바꾸기 때문에 범위가 다르면 범위가 큰 피처가 최적해를 잘 찾아가지만 작은 피처는 그렇지 않음
- 피처들의 범위를 맞춰줘야함 -> feature scaling
제곱이 있는 선형
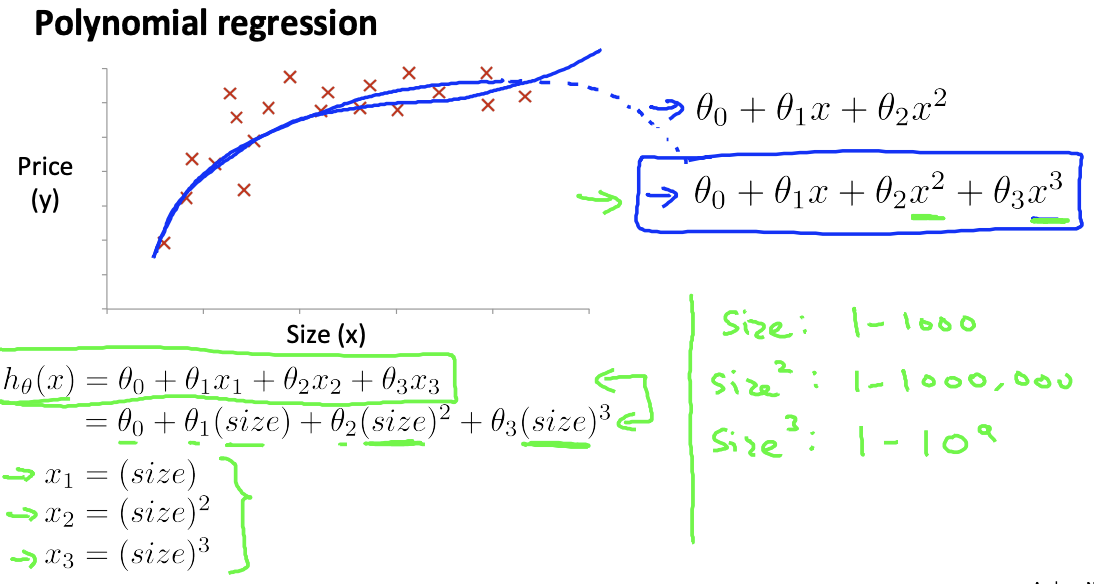
- x제곱, 세제곱을 x2,x3로 치환하여 평면의 개수를 늘려 선형성을 유지할 수 있음
분류(regression)
- loss함수를 로그함수로 사용하는 이유 -> convex형태로 만들어서 local미니멈에 머물지 않게 하기 위해

- 정답값이 1, 0일때의 로스함수를 하나로 합친 형태
- y에 1이나 0을 대입할때 뒤, 앞 부분이 날아감
- 시그모이드 미분(과정?) -> 시그모이드(1-시그모이드)
군집화(Clustering)
k-means
- 랜덤한 점 k개를 찍음 -> 기준점
- 모든 점을 기준점중 가까운 기준점에 매칭
- 매칭된 점들의 평균값으로 기준점을 이동시킴
- 위의 단계를 평균이 편하지 않을때까지 반복
- 처음 찍는 기준점의 위치에 따라 결과가 달라질 수 있음
NN(Neural Networks)
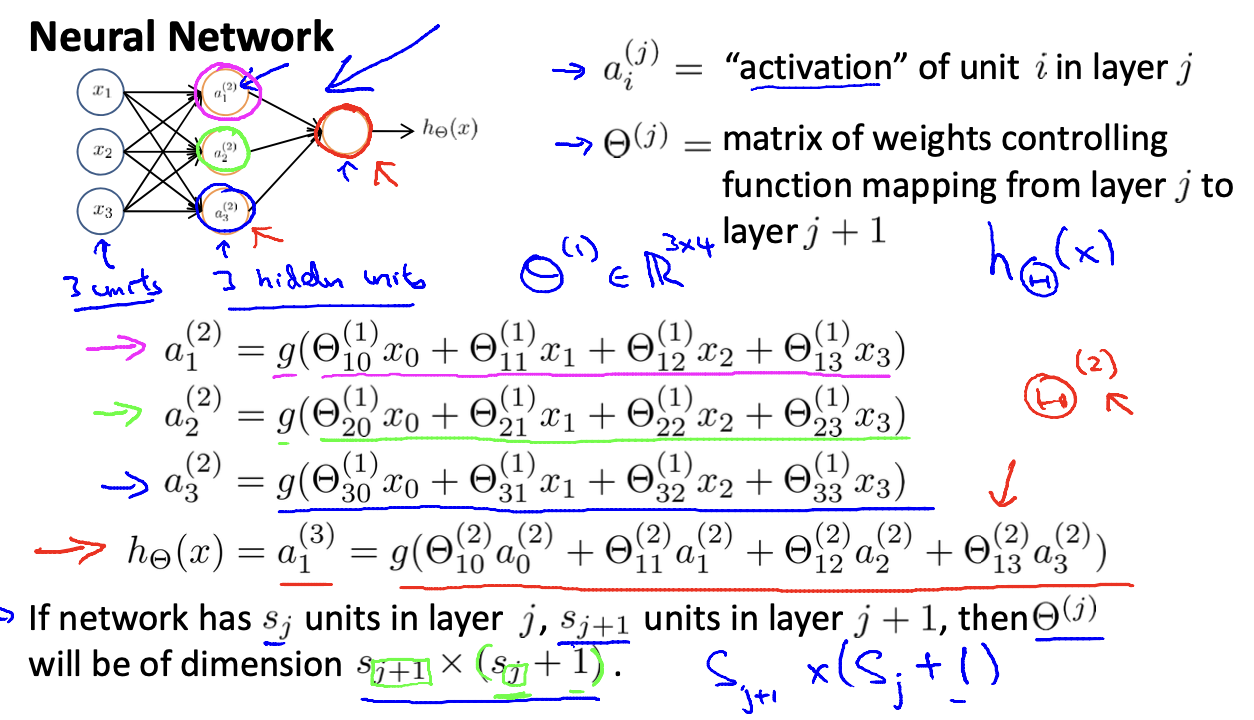
- 각 색깔에서 하나의 곱셉이 하나의 화살표를 의미
- 연결된 모든 선이 결과에 관여함
bagging and boosting
- bagging
- 데이터셋을 여러개 만드는 것
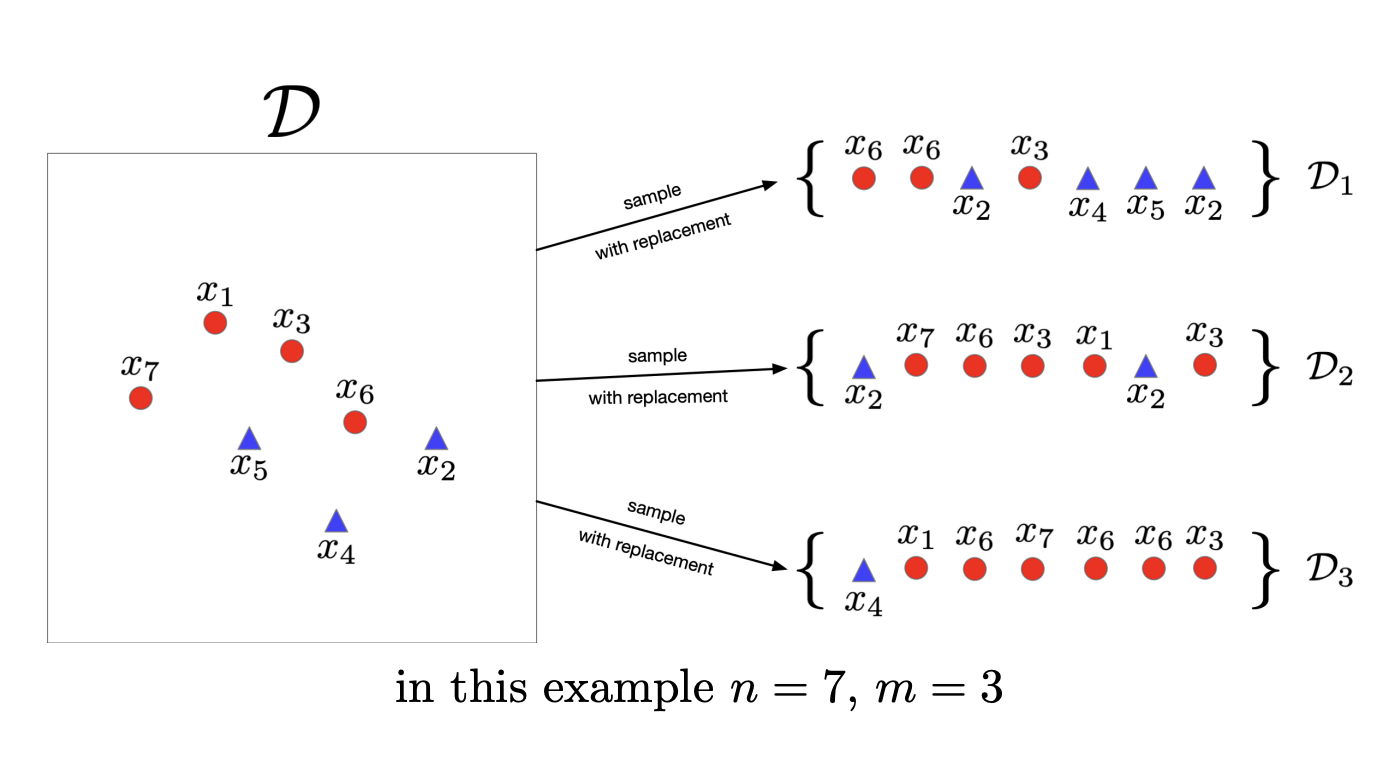
- 분산값이 떨어져서 성능이 향상됨

KMU SW