
Deep Model Compression
Knowledge Distillation(지식 증류)
-
메모리, 전력을 효율적으로 사용하면서 성능을 유지하기 위해 나온 것이 Model compression
-
레이어가 더 많은 네트워크에서 적은 쪽으로 정보를 내줌(일반적으로 레이어가 많으면 성능이 좋다)
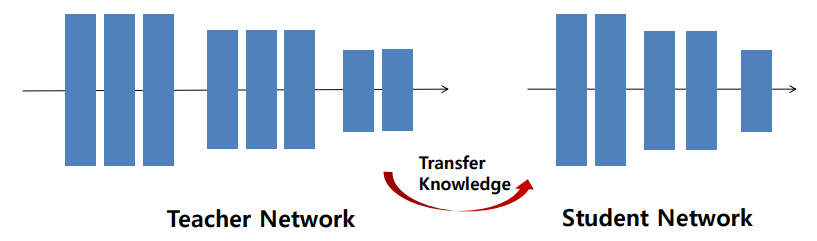
- Teacher의 정보를 활용해 Student를 학습
-
모델을 경량화
-
처음엔 teacher의 마지막 아웃풋을 student에게 전달하는 방법으로 구현했었음
-
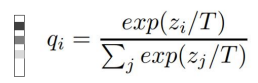
-
위는 소프트맥스를 합은 항상 1이 되면서(확률이기 때문) T로 나누어 y값의 차이를 줄여 평평하게 만듦
- teacher의 아웃풋을 평평하게 만들어 정답값으로 쓰는 것
- teacher에서 강아지라고 100% 확인했지만 강아지의 특성 중 늑대와 비슷하거나 털이 있는 등의 특성을 사용하기 위해 T를 사용하는 것
- T의 값이 클수록 평평해짐(평평할수록 다른 특성을 더 많이 보겠다는 의미)
-
attention map
- 정보를 넘겨줄때 픽셀의 값을 모두 더해서 한장으로 만들어서 넘겨주기
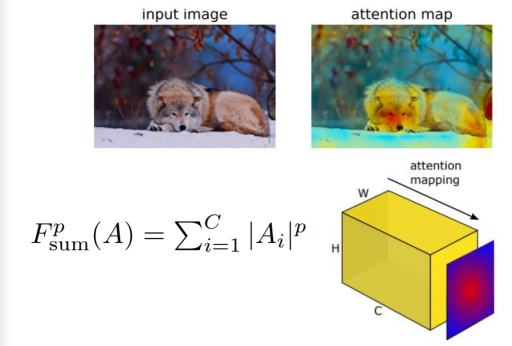
- 위에서 가로세로 각 픽셀마다 C장 만큼 절대값으로 다 더해서 같은 가로세로 크기의 attention map을 만들어서 넘겨줌
- 중간중간 피처를 넘겨주는 의미
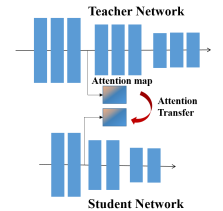
-
Factor Transfer
- teacher, student의 레이어, 피처의 크기와 개수가 다른데 teacher만의 결과를 넘겨주는것은 알맞지 않다고 생각하여 나온 방법
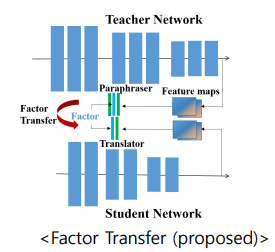
- 각각의 결과를 모듈을 통과시켜 크기를 중여 factor로 추출
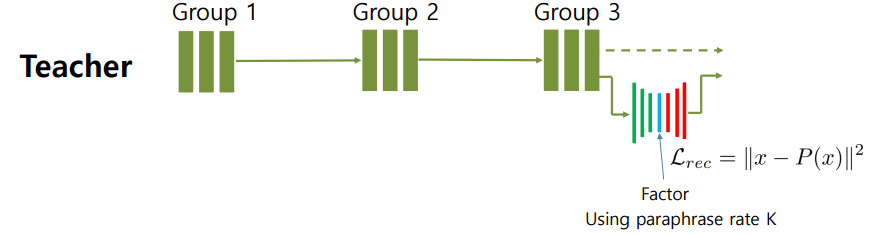
- teacher의 결과를 압축후 다시 복원했을때 압축전과 복원 후의 결과가 비슷하면 할수록 가운데의 크기가 가장 작은 부분은 원본의 특징을 가장 잘 표현했다고 말할 수 있음
- 이것은 teacher의 결과를 잘 표현하면서 크기를 잘 줄여준것임
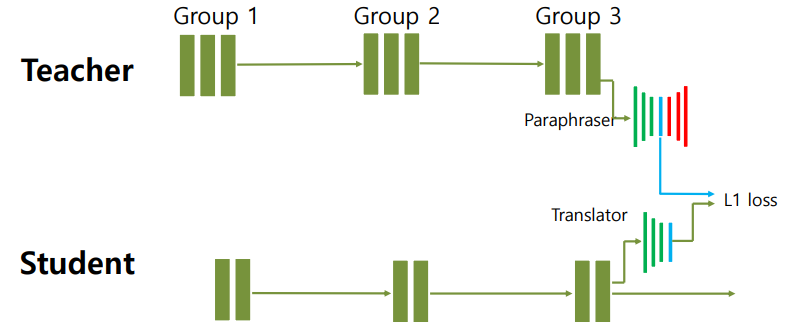
- student도 학습후 결과를 factor로 압축하고 teacher와 student의 factor의 차이를 줄여서 사용
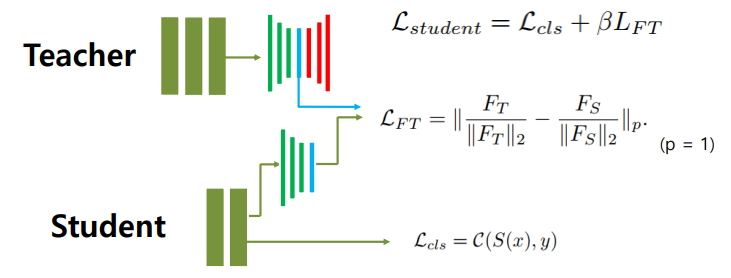
-
FT의 성능
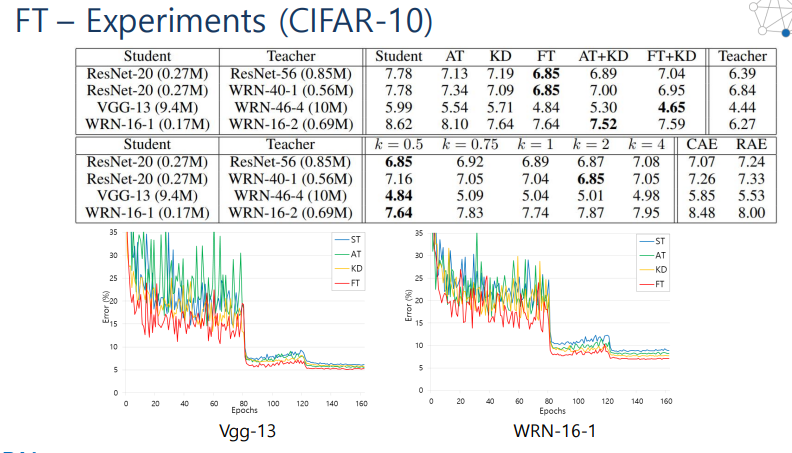
- k : 압축 작으면 압축을 더 많이 한것(압축을 많이한다는 것은 factor의 크기가 작아지는 것)
- ST는 teacher를 활용하지 않는 결과
- 일반적으로 압축을 많이하고 teacher의 정보를 활용한것이 성능이 좋음
Quantization(양자화)
- 연속적인 신호를 디지털화 하는 것

- Full precision : 32비트 체제라하면 32비트를 모두 사용 하는 것
- Low Precision : 32비트 중 8비트정도만 사용한다하면 히스토그램에서 막대의 개수가 2^32에서 2^8로 줄어드는 것
- 연산량을 줄임
- 크게 QAT, PTQ로 나눔
- QAT(Quantization Aware Training)
- 최대 성능(FP))를 학습하고 난 후 양자화된 데이터를 가지고 더 학습함
- PTQ(Post-Training Quantization)
- FP를 학습하고 난 후 그 결과를 활용해 양자화하는 방법
- FP는 무조건 하고 그 후에 둘 중 하나를 사용함
- QAT(Quantization Aware Training)
- QAT가 성능이 좋긴하지만 학습하는데 시간도 오래걸리고 어려움 PTQ는 학습없이 한번의 알고리즘을 돌리면 사용가능해서 빠름(성능은 떨어질 수 있음)
- PSGD
- 처음부터 정밀도가 낮은 모양으로 학습을 시키는것

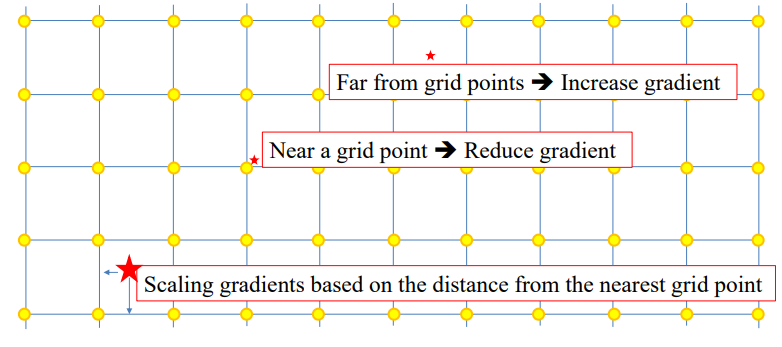
- W를 양자화시킬때 막대가 노란색 점에 있어야함
- 위에서 별표가 W가 양자화된 위치라 할때 노란점 근처에 있으면 양자화가 잘 되었기 떄문에 업데이트시 움직이지 않게 하고 노란점에서 멀면 양자화가 잘 안된 것이라 판단해 다음 업데이트시 많이 움직이게 만듬

- S(X)가 노란점과의 거리, 밑의 식에서 거리만큼 곱해져서 움직이게 됨
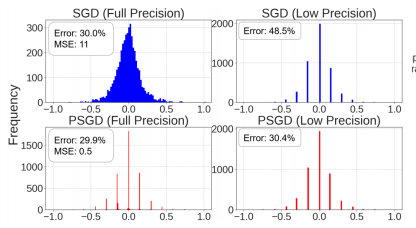
- 왼쪽그림은 둘다 FP임 2개를 양자화 시켜 비트수를 줄인것이 오른쪽
- 처음 학습할떄부터 양자화를 고려하면 에러가 줄어듬
- 처음부터 몇비트로 양자화할지 알아야 가능한 방법이라는 단점이 있음(노란점의 개수를 정해줘야 하기 떄문)
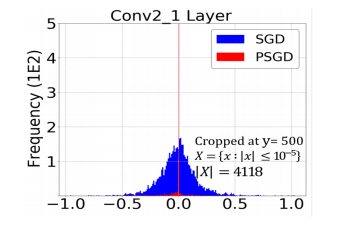
- 양자화 할때 여러 값을 0으로 만든것인데 그럼에도 성능이 나온다면 pruning효과까지 얻은것
- PSGD는 처음부터 양자화후의 모습과 유사하게 학습하기 때문에 학습 완료 후 바로 양자화가 쉬움(타켓 비트를 가지고 학습하기 떄문에 타겟 비트로 양자화하면 성능이 잘 나옴)
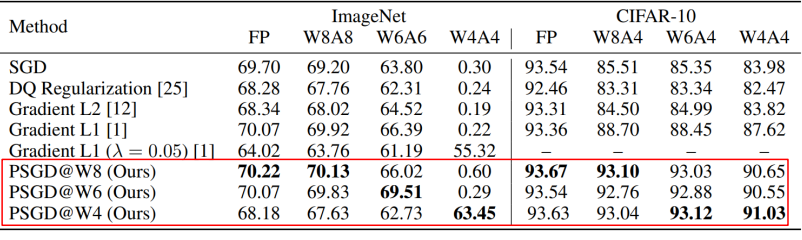
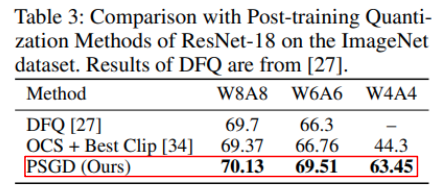
- On-the-fly quantization(타겟 비트로 한번에 양자화)해도 성능이 잘 나옴
- 처음 학습시 양자화에 친숙하게 학습하기 때문에 PTQ를 섞어써도 성능이 잘 나옴

Pruning
- 중요하지 않은 웨이트를 지우는 것(0으로 만드는 것)
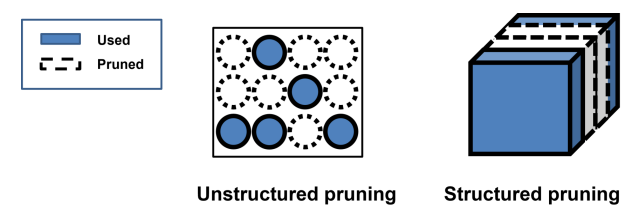
- Unstructed pruning : 필터 안에서 웨이트를 지우는 것
- Structed pruning : 여러개의 필터중 특정 필터를 통채로 날림
- 일반적으로 절대값의 크기가 작은 것을 지움
- 방법은 여러가지가 있다
- One-shot or Iterative
- 한번에 원하는 만큼 크기를 줄이거나 점차적으로 하는것에 따라 나누어짐
- Iterative는 조금씩 줄이면서 중간중간 학습을 다시하기 때문에 결과가 한번에 줄이는것과 달라짐(일반적으로 성능이 좋음)
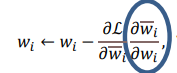
- 햇을 씌운게 프루닝을 하고난 후의 결과
- 갱신할때 프루닝을 안한 것을 프루닝을 한걸로 갱신하는게 말이 안되기 때문에 채인룰을 사용한 것
- 파란 동그라미는 마스크를 의미함(w햇이 wx마스크인데 w햇에 대해 미분했기 때문)
- 실제 마스크값을 곱하면 마스크가 0이면 업데이트가 전혀 안됨
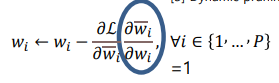
- 그냥 마스크값을 1로 만들자는 방법(Dynamic Prining)
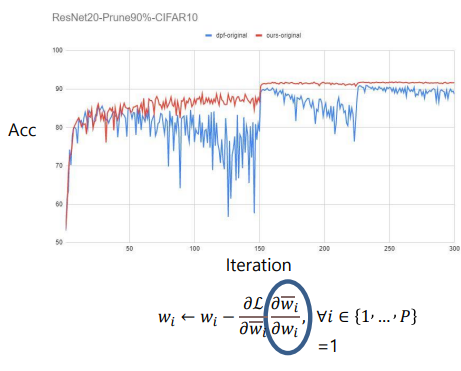
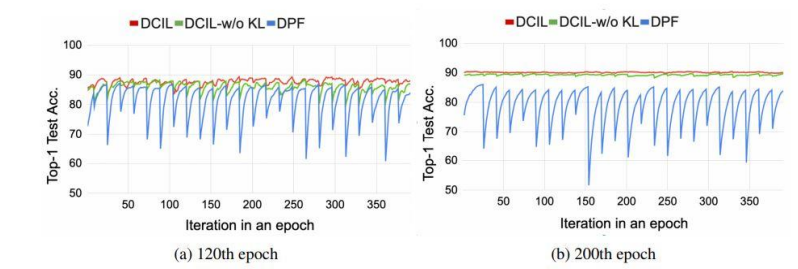
- 위에서 다 1로 만든것이 파란색(dpf)
- 성능이 요동치게 됨
- 마스크가 1일때 실제로 업데이트 하는것은 트루 업데이트(문제가 안됨)
- 그런데 마스크가 0인데 실제로 업데이트 한 경우는?
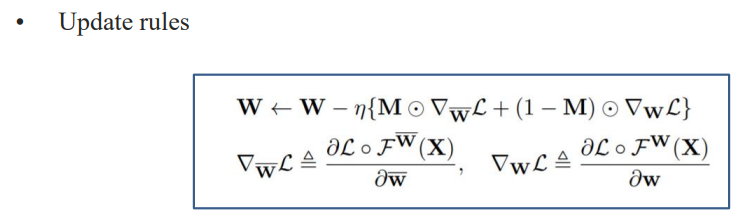
- 뒤의 식에서 M은 마스크의 값 0이거나 1, 마스크가 1이면 마스크를 씌운 후 값인 w햇을 업데이트하고 마스크가 0이면 그냥 w를 업데이트함
- dpf를 개선한것(dpf 위의 파란색은 뒤의 식 부분에서 마스크가 0이어도 w햇을 업데이트 한거임)

KMU SW