Spring Boot

: Spring 기반의 애플리케이션을 개발하기 쉽도록 많은 부분을 자동화하여, 사용자가 편하게 Spring을 활용할 수 있도록 돕는 프레임워크
- 스프링 프레임워크 위에 구축 (의존성 주입, 트랜잭션 관리, 웹 개발, 데이터 접근 등 가능)
- 스프링 확장 도구라고 할 수 있고, Spring Data, Spring Security, Spring Batch 등과 함께 사용되어 종합 개발 환경을 제공한다.
Spring Boot 특징
- 단독 실행 가능한 스프링 애플리케이션 생성
- 내장형 톰캣, 제티, 언더토우 존재 → WAR 파일로 배포할 필요가 없다.
- Starter로 기본 설정 컴포넌트를 쉽게 추가할 수 있다.
- 설정을 위한 XML 코드를 요구하지 않는다.
✳️ Spring Starter
: 여러 기술과 라이브러리에 대한 종속성들을 수동으로 추가하지 않아도 되며, 간편하게 필수 의존성을 관리할 수 있게 해주는 도구이다.
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
}- 위와 같이 JPA 기술을 사용하기 위해 JPA Starter를 사용하면 Hibernate, Spring ORM, Spring core, Spring Transaction 등 여러 의존성을 설정할 수 있다.
✳️ Spring Initializr를 이용한 프로젝트 생성
- Spring Initializr에서 Spring boot 실행 환경과 필요 라이브러리들을 손쉽게 포함해 템플릿을 만들 수 있다.
Project - 빌드 자동화 도구 선택

: Maven, Gradle 모두 Java 기반 프로젝트를 관리하고 빌드하는 데 사용되는 도구
- Maven : XML을 사용하는 설정파일 pom.xml을 사용하고, 규칙 기반 설정으로 초기 설정이 간단하고 관습적이다.
- Gradle : Groovy/Kotlin DSL을 사용하며, 유연하고 강력한 DSL(Domain-Specific Language)로 복잡한 빌드 로직을 쉽게 표현한다.
Spring Boot - 버전 선택

- 버전 뒤에 표기된 접미사는 "소프트웨어 생명 주기"를 의미한다.
- 일반적으로 GA 또는 아무런 접미사가 없는 버전을 선택한다.
- 버전
- SNAPSHOT : 안정화되지 않은 데일리 빌드 버전
- Mx(MileStone) : 팀이나 프로젝트마다 정해진 주기로 배포된 버전 (M2면 2번째 마일스톤. 주요 기능 구현마다 릴리즈하고 피드백을 받는 버전)
- RC(Release Candidate) : 전반적인 기능과 버그가 모두 수정된, 최종 배포 전 단계
- GA(General Availability) : 최종 배포 단계
Dependencies

- 원하는 모듈, 라이브러리를 추가할 수 있다.
- Spring Boot 환경에서 서로 다른 모듈 간 충돌없이 간단하게 추가할 수 있어 유용하다.
- 꼭 생성 단계에서 추가하지 않아도 build.gradle에 직접 등록해도 상관없다.
- 주요 모듈
- Spring Boot DevTools
: 애플리케이션 개발 및 디버깅에 도움을 주는 도구
코드 변경 시 자동 리로드(Re-Load), 라이브 리로드, 자동 재시작 기능 등을 제공 - Lombok
: 반복되는 getter, setter, toString 등의 메서드를 자동 생성하는 라이브러리
컴파일 시점에 코드를 자동 생성해주므로, 효율적인 코드 작성이 가능 - Spring Web
: 웹 애플리케이션 개발에 필요한 핵심 라이브러리 패키지
내장 톰캣을 포함해 MVC 패턴, RESP API 구현을 위한 주요 기능을 포함 - H2 Database
: 오픈소스 관계형 DBMS
프로젝트를 재가동할 때마다 데이터가 초기화되어, 테스트에 많이 사용된다.
- Spring Boot DevTools
✳️ 디자인 패턴 (Design Pattern)
: 과거 소프트웨어 개발 과정에서 발견된 설계 노하우를 추척해, 방법으로 만들어 규약으로 정리한 것으로,
특정 문맥에서 공통적으로 발생할 수 있는 문제에 대해 재사용 가능한 해결책이 된다.
✳️ MVC 패턴 (Model - View - Controller)
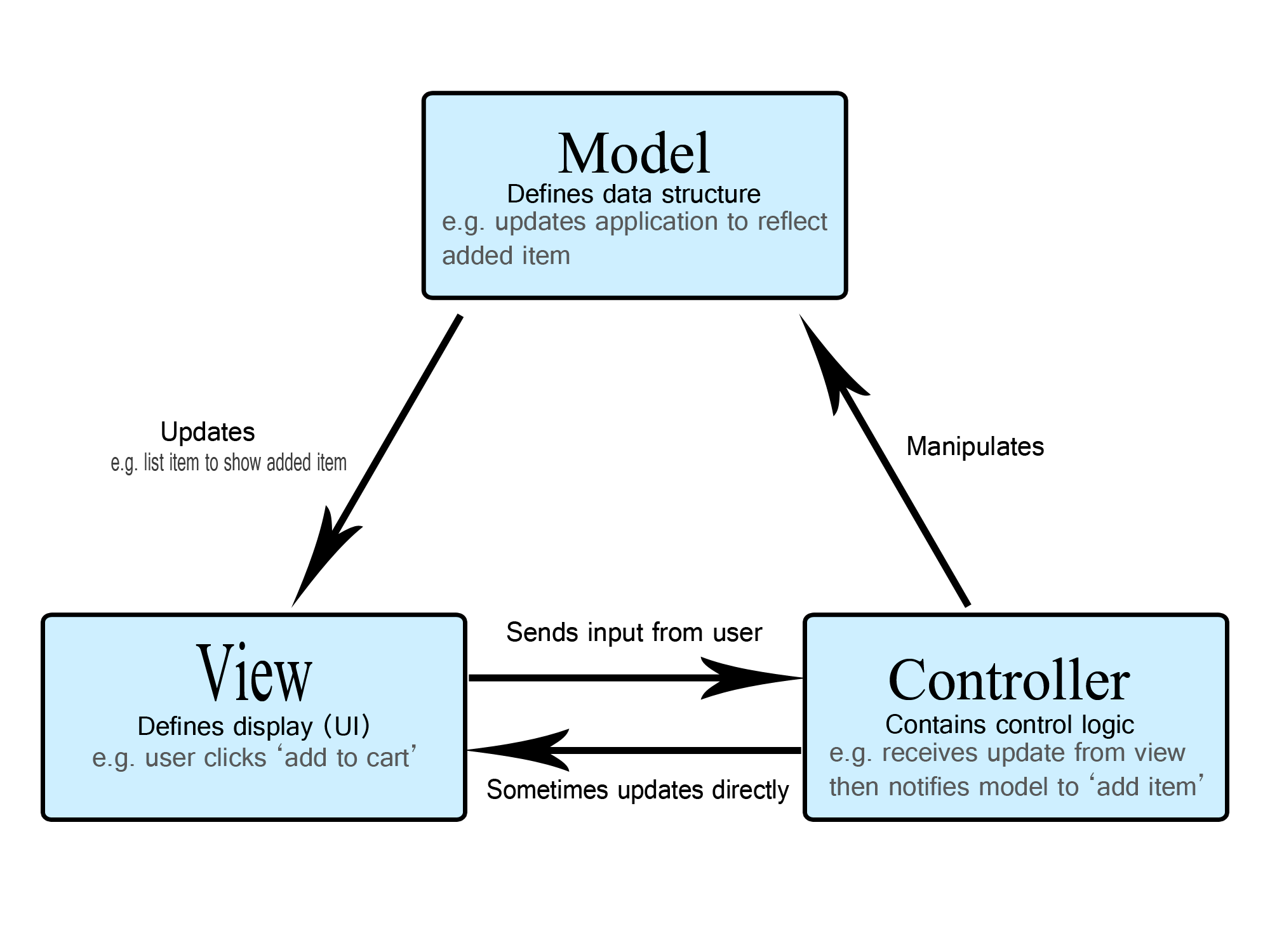
- 애플리케이션을 3가지 역할로 구분하여 개발하는 패턴
- 비즈니스 로직과 UI 로직을 분리해, 코드 종속성을 줄일 수 있다.
- 구성요소 간 역할을 명확하게 구분하여 분리가 쉽고, 협업에 용이하다.
Controller (컨트롤러)
- 사용자 입력을 받아, 데이터를 변경하거나 이를 뷰(View)에 전달하는 역할
- 모델(Model)과 뷰(View) 사이에서 데이터를 주고 받으며, 전체적인 흐름을 조절하는 역할
- Spring에서는 @Controller 어노테이션을 통해 컨트롤러 역할 스프링 빈 생성이 가능하다.
Model (모델)
- 데이터 처리 영역. DB와 연동하여, 입/출력 데이터를 다룬다.
View (뷰)
- 애플리케이션이 처리한 데이터 또는 그 작업 결과를 사용자에게 출력 화면(UI)으로 만든다.
- 모델, 컨트롤러와의 종속성이 없도록 구현해야 한다.
✳️ Spring MVC
: Spring에서 제공하는 웹 모듈로, 사용자의 HTTP 요청을 처리하여 다양한 응답(단순 Text, REST 형식, html 등)을 지원하는 프레임워크이다.
- 클라이언트의 요청을 처리하는 프론트 컨트롤러 패턴에 기초한 웹 MVC 프레임워크이다.
- DispatcherServlet은 프론트 컨트롤러 패턴에 의해 설계된 진입점으로, 사용자 요청을 분석해 이를 처리할 컨트롤러를 찾아 호출하게 된다.
DispatcherServlet의 동작 과정
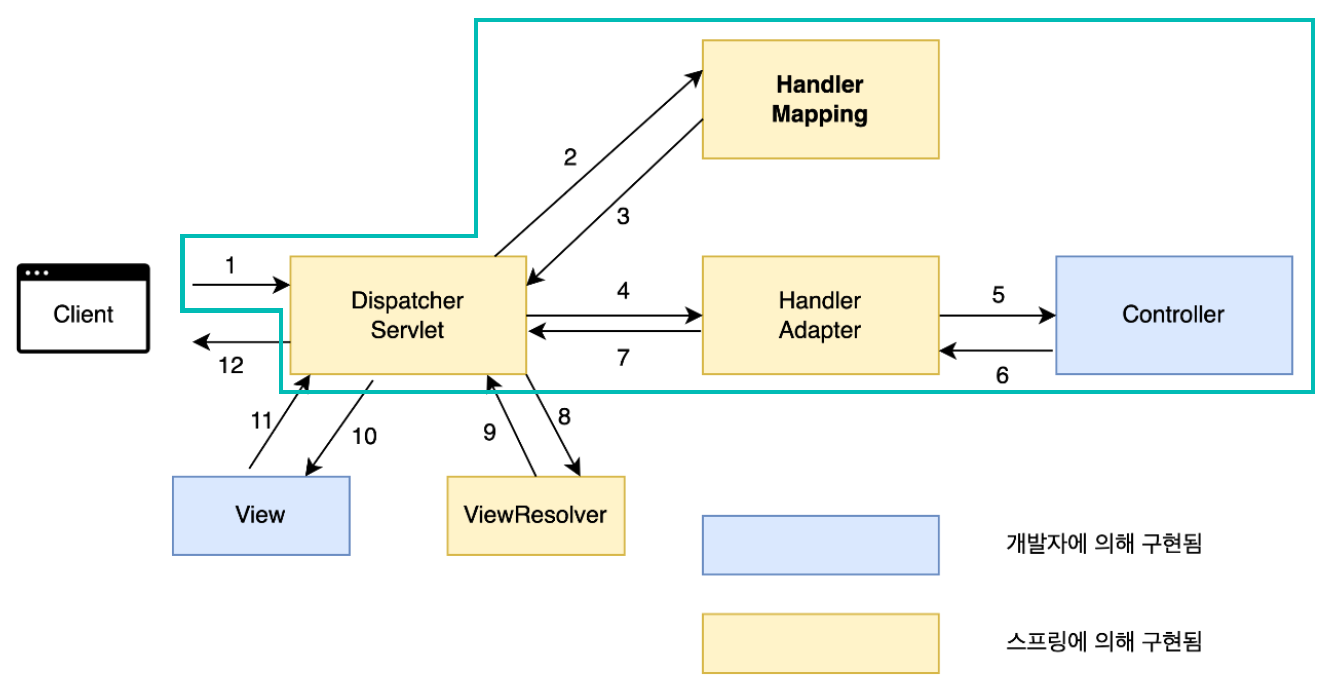
-
클라이언트 요청을 Dispatcher Servlet이 받는다.
-
요청 정보를 기반으로, 이 요청을 처리할 컨트롤러를 Handler Mapping으로 검색한다.
-
검색된 컨트롤러 정보를 Dispatcher Servlet에 리턴한다.
-
Handler Adapter에게 컨트롤러에 있는 Handler Method를 호출하도록 위임한다.
-
해당 컨트롤러의 Handler Method를 호출한다.
-
Model 데이터(응답)를 Handler Adapter에게 전달한다.
-
전달 받은 Model 데이터와 View 정보를 Dispatcher Servlet에게 전달한다.
-
전달 받은 View 정보를 View Resolver에게 전달해, 알맞은 View 검색을 요청한다.
-
검색한 View를 Dispatcher Servlet에 리턴한다.
-
전달받은 View 객체를 통해 Model 데이터를 넘기면서, 클라이언트에 전달할 응답 데이터 생성을 요청한다.
-
응답 데이터를 Dispatcher Servlet에게 전달한다.
-
전달 받은 응답 데이터를 최종 클라이언트에게 전달한다.
정리하면,
Dispatcher Servlet은 애플리케이션 가장 앞에 배치되어,
다른 구성요소와 상호작용하며 클라이언트 요청을 처리한다.
✳️ Spring Database Access
데이터베이스 (DB)
: 데이터를 영구적으로 저장 및 관리하는 부분
데이터베이스 관리 시스템 (DBMS)을 사용해 구현된다.
영속성 (Persistence)
: 데이터를 생성한 프로그램의 실행이 종료되더라도 사라지지 않는 특성
- Java에서 데이터베이스 프로그래밍은 Java Database Connectivity를 통해 이루어진다.
- 영속성은 파일시스템, 관계형 데이터베이스 등을 통해 구현할 수 있다.
Java Database Connectivity
: Java에서 데이터베이스에 접근할 수 있도록 하는 기본 DB 프로그래밍 방법이다.
규격에 따라 정의된 인터페이스들을 구현한 Driver 클래스를 사용해, 서로 다른 DB를 동일한 방법으로 사용가능하다.
- 별도 추가 라이브러리 설치 없이도 사용할 수 있어 호환성이 가장좋지만,
DB마다 다른 SQL 구문을 지원하거나 트랜잭션이나 성능에 대해서는 직접 구현해야 하는 부분이 많다.
데이터 액세스 기술 유형
-
SQL 중심 기술
- mybatis와 Template가 대표적이다.
- 데이터베이스 접근을 위해 SQL 쿼리문을 직접 작성하는 것이 중심이 된다.'
- ex) MyBatis
<select id="findNews" resultType="News"> SELECT * FROM NEWS WHERE news_id = #{newsId} </select> - SQL Mapper 설정 파일에서 SQL 쿼리문을 직접 작성한다 → DBMS에 종속적인 문제점이 발생
-
객체 중심 기술
-
데이터를 객체 관점으로 바라보는 기술
-
SQL 쿼리문을 직접 작성하기 보다는 Java 객체를 이용해 애플리케이션 내부에서 객체를 SQL 쿼리문으로 자동 변환 후 DB 테이블에 접근한다.
-
JPA
- Java Persistence API로, ORM(Object Relational Mapping) 기술 중 하나이다.
- 객체와 RDB 간 매핑을 제공하며, ORM 사용을 위한 표준 인터페이스의 모음
- JPA의 대표적인 구현체 : Hibernate, EclipseLink
- ORM은 객체 지향 프로그래밍과 DB 간 경계를 허물어, 개발자가 SQL 쿼리를 직접 작성하지 않고도 객체를 DB 테이블에 저장 및 검색할 수 있게 해준다.
-
ORM
: 객체지향 프로그래밍은 클래스를 사용, RDB는 테이블을 사용한다. 객체 모델과 관계형 모델 간에는 패러다임의 불일치가 존재한다.
그럼에도 ORM은 OOP와 RDB를 연결할 계층의 역할로 제시된 패러다임으로, 객체 간 관계를 바탕으로 SQL을 자동 생성하여, 불일치를 해결해준다.
- ORM의 장점
- 객체지향적으로 데이터를 관리할 수 있어, 프로그램 구조 전체를 일관되게 유지할 수 있다.
- 로직을 SQL 쿼리에 집중하기 보다 객체 자체에 집중할 수 있다.
- 프로그래밍 언어와 문법으로 메서드를 활용하므로 가독성이 높다.
- 데이터베이스에 대한 종속성을 줄일 수 있다.
- ORM 단점
- 학습 곡선이 높고, 진입 장벽이 높다.
- ORM으로 모든 쿼리는 대체할 수 없어, JPQL, QueryDSL 등의 기술도 사용할 수 있어야 한다.
- 복잡한 쿼리 작성 시, ORM 사용에 대한 난이도가 급증한다.
- 호출 방식에 따라 성능이 천차만별이라, 잘못 구현되면 속도 저하 및 일관성이 무너질 수 있다.
✳️ JPA (Java Persistence API)
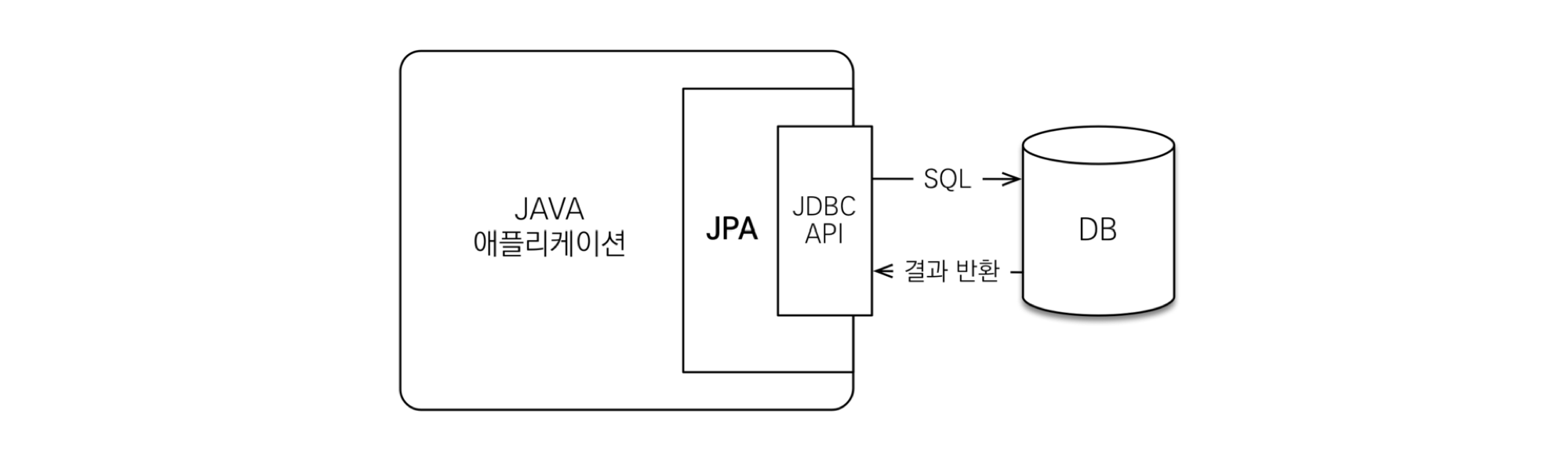 [출처] https://gmlwjd9405.github.io/2019/08/04/what-is-jpa.html#google_vignette
[출처] https://gmlwjd9405.github.io/2019/08/04/what-is-jpa.html#google_vignette
: Java 애플리케이션에서 관계형 데이터베이스를 객체-관계 방식으로 사용할 수 있도록 만든 인터페이스
- 단순 명세(인터페이스)이기 때문에 구현체가 없고, 다양한 ORM 프레임워크에서 구현 가능한 공통 API를 제공한다.
- Hibernate는 JPA의 구현체로, JPA의 모든 기능을 지원한다.
영속성 컨텍스트 (Persistence Context)
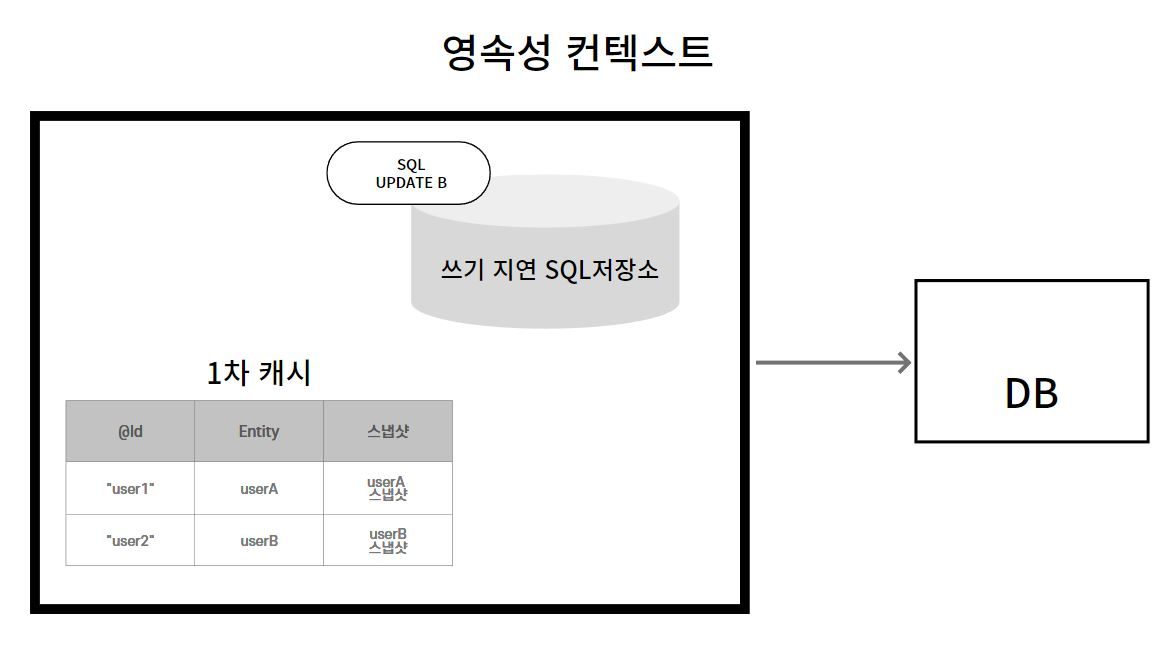
: 엔티티를 영구 저장하는 환경. 애플리케이션과 DB 사이에서 객체를 보관하는 가상의 DB 역할을 한다.
-
엔티티 매니저 (EntityManager)를 통해 엔티티를 저장하거나 조회하면,
영속성 컨텍스트에 엔티티를 보관하고 관리한다.
-
1차 캐시
: 영속성 컨텍스트 내부에 갖는 캐시
ID, 엔티티를 키, 값으로 하는 Map 형식으로 이루어져 있다.
데이터 조회 시 1차 캐시에 존재하면 DB에 접근하지 않아도 된다. -
쓰기 지연 SQL 저장소
: 단일 트랜잭션(Transaction)에서 이루어지는 쿼리를 쌓아놓는 공간
트랜잭션이 커밋되는 순간 한 번에 DB로 쿼리를 날린다.
DB 연결 시간을 줄이고, 한 트랜잭션이 테이블에 접근하는 시간을 줄일 수 있다. -
변경 감지
: 영속성 컨텍스트 1차 캐시에는 "스냅샷 컬럼"이 존재한다.
1차 캐시 저장 순간의 데이터를 스냅샷에 기록하고,
flush() 시점에 변경된 부분이 있으면 자동으로 UPDATE 쿼리를 보낸다.
-
지연 로딩(Lazy Loading)
: 연관관계 매핑되어 있는 엔티티 조회 시, 우선 프록시 객체를 반환하고
실제로 필요할 때 쿼리를 날려 데이터를 가져오게 한다.
✳️ Spring Data JPA
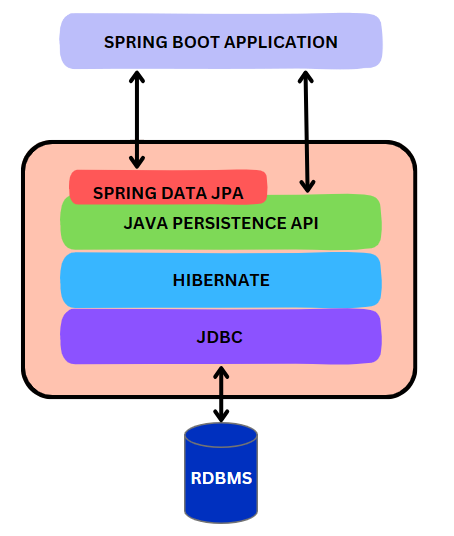
: Spring 프레임워크에서 제공하는 모듈 중 하나. 개발자가 더 쉽고 편하게 JPA를 사용할 수 있도록 해준다.
- JPA를 한 단계 추상화시킨 Repository라는 인터페이스를 제공하면서 이루어진다. (Repository 내부 구현부에 JPA가 사용됨)
Spring Data란
: 기본 DB에 대한 특정은 유지하면서, 데이터 액세스 방법에 대해 익숙한 접근 방법을 제시하는 목적을 가진 Spring 기반 프로그래밍 모델
- 데이터 액세스, 관계형 및 비관계형 데이터베이스, 클라우드 기반 데이터 서비스 쉽게 사용 가능
- 어떤 RDBMS를 쓰더라도, 일관적인 방법의 프로그래밍으로 데이터에 접근 가능
Spring Boot JPA 사용 설정하기
spring:
datasource:
driver-class-name: org.h2.Driver
url: jdbc:h2:~/{스키마 이름}
username: {사용자 이름}
password: {사용자 암호}
jpa:
hibernate:
ddl-auto: update
show-sql: true엔티티 매핑
: JPA를 이용해 DB 테이블과 상호작용하기 위해 DB Table ←→ Entity Class 간 매핑 작업이 필요하다.
엔티티 클래스를 생성하면 DB 테이블 구조가 자동으로 만들어진다.
(application.yml의 ddl-auto 설정에 따라 테이블 생성 결정)
@Entity
@Getter @Setter
@NoArgsConstructor @AllArgsConstructor
public class News {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long newsId;
@Column(name = "news_title", nullable false, length = 255)
private String title;
@Column(nullable = false)
private String content;
}[예시] /domain/News.java
- Reflection
- 구체적인 클래스 타입을 알지 못해도, 그 클래스의 메서드, 타입, 변수에 접근할 수 있도록 해주는 Java API
- JPA는 DB 값을 Java 객체로 직렬화할 때 Reflection을 이용한다.
- JPA에서 Java 객체로 직렬화 할 때, 기본생성자를 통해 먼저 객체를 만들고, Reflection을 통해 필드 값을 주입한다.
- 그러므로 Entity에는 기본생성자가 필수적이다. (없으면 예외 발생, InstantiationException)
Lombok에서 제공하는 Annotation
-
@NoArgsConstructor
: 매개변수가 없는 기본 생성자 생성
Reflection을 위해 필수적이다. -
@AllArgsConstructor
: 모든 필드 값을 매개변수로 받는 생성자 생성 -
@Getter / @Setter
: getter / setter 메서드를 자동 생성한다.
필드에 사용하면 해당 필드에 대해서만, 클래스에 사용하면 모든 필드에 대해서 메서드를 만든다.
JPA에서 제공하는 Annotation
-
@Entity
: 영속성 컨텍스트가 엔티티로 인식하고, JPA가 테이블과 매핑하게끔 알려준다. -
@Table
: 엔티티 클래스를 DB의 특정 테이블로 매핑할 때 사용
테이블 이름, 카탈로그, 스키마, 유니크 ㅔㅈ약조건 등 명시적으로 정의 가능하다. -
@Id
: PK 설정을 위한 식별자 필드.
엔티티의 필드를 테이블의 ID 기본 키 컬럼에 매핑한다. @GeneratedValue와 함께 사용 -
@GeneratedValue
: PK 생성 전략을 지정한다.
strategy 속성(IDENTITY, SEQUENCE, TABLE, AUTO 등)으로 지정 (직접 할당, 자동 생성 등) -
@Enumerated
: Java의 enum 타입을 매핑할 때 사용한다.
EnumType.ORDINAL(인덱스를 DB값으로 저장) / EnumType.STRING(이름을 DB값으로 저장) -
그 외의 Annotations
| Annotation | Description |
|---|---|
| @Temporal | 날짜 타입 (Date/Calender) 매핑 |
| @CreationTimestamp | 엔티티가 DB에 저장될 때의 시간을 자동 기록 |
| @UpdateTimestamp | 엔티티가 생성 or 업데이트될 때 시간을 자동 기록 |
| @Transient | 특정 필드를 DB에 매핑하지 않음 |
| @Lob | DB의 BLOB, CLOB 타입 매핑 (DB에서 큰 데이터 저장에 사용하는 유형) |
✳️ JPA 연관관계 매핑
: 엔티티 클래스 간 관계를 만들어주는 것.
객체는 참조를 사용해 관계를 맺고, 테이블은 외래키를 사용해서 관계를 맺는다.
- 1 : 1(일대일) / 1 : N(일대다) / N : M(다대다)
- 방향은 객체 관계에만 존재하고, 테이블 관계는 항상 양방향이다.
class Student {
private Department department;
...
}
class Department {
private List<Student> students;
...
}단방향 연관 관계
: 'EntityA'가 'EntityB'를 참조하고 있지만,
'EntityB'는 'EntityA'를 참조할 수 없다.
@Entity
public class EntityA {
@ManyToOne
private EntityB entityB;
...
}
@Entity
public class EntityB {
...
}양방향 연관 관계
: 두 엔티티 간 서로 참조 가능한 관계
양쪽에서 서로 참조해야 하거나, 접근이 필요한 경우 사용한다.
양방향 연관관계 매핑을 위해서는 "연관관계의 주인"을 정해야 한다.
- 연관관계의 주인만이 DB 연관관계와 매핑되고, 외래키를 관리할 수 있다. (연관관계의 주인이 외래키를 갖는다.)
- 연관관계의 주인이 아니라면 mappedBy 속성을 사용해, 속성 값으로 연관관계 주인을 지정해야 한다.
public class News {
...
@ManyToOne
@JoinColumn(name = "user_id")
private User user;
}News.java
public class User {
...
@OneToMany(cascade = CascadeType.ALL, mappedBy = "user")
private List<News> news;
}User.java
- @JoinColumn
: 외래키 매핑에 사용되는 어노테이션
name 속성을 지정하지 않으면 기본으로 필드명 + "_" + 테이블의 @Id 컬럼명을 사용한다. 연관관계의 주인인 News 테이블에는 User 테이블의 id를 외래키(FK)로 갖게 된다.
양방향 매핑 시에는 무한 루프에 빠지지 않게 조심해야 한다.
(toString(), equals(), hashCode() 메서드 사용 시 특히 주의)
✳️ 순환 참조
- User 홍길동이 3개의 News 객체를 갖고 있다고 하자. (News1, News2, News3)
- User 홍길동의 정보를 가져오기 위해서, New1,News2,News3의 정보를 그대로 가져오고
- 각각의 News1, News2, News3에 대한 작성자(user)도 또 가져오려고 하게 된다.
- 이렇게 반복적으로 참조하는 필드의 정보를 가져오려 하는 상황이 순환 참조이다.
- Spring Data JPA에서는
@JsonManagedReference 와 @JsonBackReference 어노테이션을 사용해 순환참조를 제어할 수 있다. - 연관관계의 주인 쪽에는 @JsonBackReference
- 주인이 아닌 쪽에는 @JsonManagedReference를 붙여 사용한다.
public class News {
...
@ManyToOne
@JoinColumn(name = "user_id")
@JsonBackReference
private User user;
}News.java
public class User {
...
@OneToMany(cascade = CascadeType.ALL, mappedBy = "user")
@JsonManagedReference
private List<News> news;
}User.java
✳️ 매핑 관계 (1:1, 1:N, N:1, N:M)
*️⃣ 일대일 (1:1) - @OneToOne
- 일대일 관계는 양쪽이 서로 하나의 관계만 갖는다.
- 외래키를 갖는 쪽은 둘 중 어느 곳이어도 상관 없다.
- 전통적으로 DB 개발자들은, "대상 테이블"에 외래키(FK)를 두는 것을 선호한다.
(테이블 관계를 일대다로 변경할 때, 테이블 구조를 유지할 수 있기 때문)
- 1:1 관계에서 단방향 관계
// 주 테이블 (사람)
@Entity
public class Member {
@Id @GeneratedValue(strategy = GeneratedType.IDENTITY)
private Long memberId;
@Column
private String name;
}
// 대상 테이블 (사물함)
@Entity
public class Locker {
@Id @GeneratedValue(strategy = GeneratedType.IDENTITY)
private Long lockerId;
@Column
private String name;
@OneToOne
@JoinColumn(name = "member_id")
private Member member;
}- **1:1 관계에서 양방향 관계**
// 주 테이블 (사람)
@Entity
public class Member {
@Id @GeneratedValue(strategy = GeneratedType.IDENTITY)
private Long id;
@OneToOne(mappedBy = "member")
private Address Address;
}
// 대상 테이블 (주소)
@Entity
public class Locker {
@Id @GeneratedValue(strategy = GeneratedType.IDENTITY)
private Long id;
@OneToOne
@JoinColumn(name = "member_id")
private Member member;
}*️⃣ 다대일(N:1) / 일대다(1:N) - @ManyToOne / @OneToMany
- 다대일 관계의 반대는 항상 일대다,
일대다 관계의 반대는 항상 다대일이다. - DB의 일(1)대 다(N) 관계에서 외래키(FK)는 항상 다(N)쪽에 있다.
따라서 객체 양방향 관계에서 연관관계 주인은 항상 다(N)쪽이다.
- 1:N, N:1 단방향
@Entity
public class Member {
@Id @GeneratedValue(strategt = GeneratedType.IDENTITY)
private Long memberId;
@Column
private String name;
@ManyToOne
@JoinColumn(name = "TEAM_ID")
private Team team;
}
@Entity
public class Team {
@Id @GeneratedValue(strategt = GeneratedType.IDENTITY)
private Long teamId;
@Column
private String name;
}- 1:N, N:1 양방향
@Entity
public class Member {
@Id @GeneratedValue(strategt = GeneratedType.IDENTITY)
private Long memberId;
@Column
private String name;
@ManyToOne
@JoinColumn(name = "TEAM_ID")
private Team team;
}
@Entity
public class Team {
@Id @GeneratedValue(strategt = GeneratedType.IDENTITY)
private Long teamId;
@Column
private String name;
@OneToMany(mappedBy = "team")
private List<Member> members = new ArrayList<Member>();
}- 양방향은 외래키(FK)가 있는 쪽이 연관관계의 주인이다.
- Member 테이블이 외래키를 가지므로, Member.team이 연관관계의 주인이다.
- 양방향 연관관계는 항상 서로를 참조해야 한다.
*️⃣ 다대다(N:M) - @ManyToMany
- 관계형DB는 정규화된 테이블 2개로 다대다 관계를 표현할 수 없다.
- 테이블 설계 시, 다대다 관계는 중간에 테이블을 하나 추가하여 두 개의 일대다 관계를 만들어주는 것이 일반적이다.
