개인스터디
예제로 익히는 SQL 6회차
JOIN 함수 복습
JOIN 순서
1️⃣공통컬럼 찾기 > 2️⃣공통컬럼 관계찾기 > 3️⃣알맞은 JOIN 함수 선택하기
테이블 종류
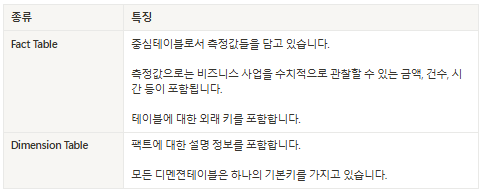
ex) Orders = Fact Table
나머지 = Dimension Table
적재주기
- Fact table : 대부분 시간, 일, 주, 월별로 기록 / 기업에 따라 상이
- Dimension table : 필요에 의해 업데이트
- 이벤트 및 업데이트가 있는 경우
적재방식
-
Tuncate
- 이전 데이터 삭제
- 테이블 구조(열,형식)은 그대로 보존
- 멤버십 등급 등 갱신정보가 필요한 테이블에 주로 사용
-
Insert
- 이전 데이터 유지된 상태로 추가
- 시간에 따른 데이터 흐름을 파악해야 하는 테이블에 주로 사용
- 대부분의 데이터가 취하는 형식 BUT 용량 이슈 야기
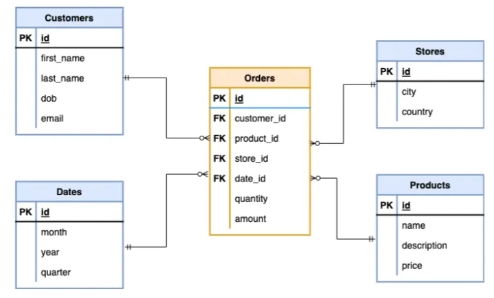
JOIN을 하는 이유
최소 두 개 이상의 테이블을 결합하여 하나의 테이블로 결합
→ 데이터를 효율적으로 검색하고 처리 가능
데이터 간 중복 최소화
숙제 피드백
🔗 3회차 숙제
문제 1 - 집계함수의 활용 🟢
#1번 정답쿼리
#substr 대신 date_format(first_login_date,"%Y-%m") 도 정답
select serverno, substr(first_login_date,1,7)as m, count(distinct game_account_id) as usercnt
from basic.users
group by serverno, substr(first_login_date,1,7)
;문제 2 - 집계함수와 조건절의 활용 🟢
#2번 정답쿼리
select first_login_date, count(distinct game_actor_id)as actor_cnt
from basic.users
group by first_login_date
having count(distinct game_actor_id)>10
;문제 3 - 집계함수와 조건절의 활용2 🟢
#3번 정답쿼리
select serverno, case when first_login_date <'2024-01-01' then '기존유저'
else '신규유저' end as gb
,count(distinct game_actor_id)as actor_cnt
,avg(level)as avg_level
from basic.users
group by serverno, case when first_login_date <'2024-01-01' then '기존유저'
else '신규유저' end
;문제 4 - SubQuery의 활용 🟡
내가 작성한 쿼리
SELECT first_login_date,
cnt_actor_id
FROM
(
SELECT first_login_date,
COUNT(DISTINCT game_actor_id) AS cnt_actor_id
FROM basic.users
GROUP BY first_login_date
) AS subquery
WHERE cnt_actor_id > 10정답 쿼리
#4번 정답쿼리
select * -- 굳이 서브쿼리에서 작성한 걸 다시 부를 필요가 없는듯
from( select first_login_date, count(distinct game_actor_id)as actor_cnt
from basic.users
group by first_login_date
)as a
where actor_cnt>10문제 5 - SubQuery의 응용 🟢
#5번 정답쿼리
select actor_cnt, count(distinct game_account_id)as accnt # 서브쿼리에서 group by 를 사용해 주었으므로 해당 구문의 distinct 는 필수가아닙니다.
from( select game_account_id , count(distinct game_actor_id) as actor_cnt
from basic.users
where level>=30
group by game_account_id
having actor_cnt>=2
)as a
group by actor_cnt 🔗 5회차 숙제
문제 1 - JOIN 활용 🟡
내가 작성한 쿼리
SELECT CASE WHEN p.pay_type IS NOT NULL THEN '결제함'
ELSE '결제안함'
END AS gb,
COUNT(DISTINCT u.game_account_id) AS usercnt
FROM users u
LEFT JOIN payment p
ON u.game_account_id = p.game_account_id
GROUP BY gb;정답 쿼리
select case when b.game_account_id is null then '결제안함' else '결제함' end as gb
, count(distinct a.game_account_id)as usercnt
from( select game_account_id
from basic.users
)as a
left outer join
( select game_account_id
from basic.payment
)as b
on a.game_account_id=b.game_account_id
group by case when b.game_account_id is null then '결제안함' else '결제함' end
;game_account가 기준이 되는 게 더 좋음 !LEFT JOIN을 기준으로 기준이 되는 테이블의 값은 모두 출력right에 위치한 테이블은left에 없을 경우null로 출력- 이를 활용해
null로 출력되는 경우를 '결제안함'으로,
null값이 아닌 경우를 '결제함'으로 풀이 가능
문제 2 - JOIN 응용1 🟡
내가 작성한 쿼리
SELECT game_account_id,
actor_cnt,
sumamount
FROM
(
SELECT u.game_account_id,
COUNT(DISTINCT u.game_actor_id) AS actor_cnt,
SUM(p.pay_amount) AS sumamount
FROM users u
LEFT JOIN payment p
ON u.game_account_id = p.game_account_id
WHERE u.serverno >= 2 AND p.pay_type = 'CARD'
GROUP BY u.game_account_id
)sub
WHERE actor_cnt >= 2
ORDER BY sumamount DESC;정답 쿼리
select *
from( select a.game_account_id, count(distinct game_actor_id) as actor_cnt,
sum(pay_amount)as sumamount
from( select game_account_id, game_actor_id
from basic.users
where serverno>=2
)as a
inner join
( select distinct game_account_id, pay_amount, approved_at
from basic.payment
where pay_type='CARD'
)as b
on a.game_account_id=b.game_account_id
group by a.game_account_id
)as a
where actor_cnt>=2
order by sumamount descLEFT JOIN사용 시 쿼리가 길어질 수 있고,WHERE절이 두번 쓰이므로 굳이 그렇게 작성할 필요가 없음- 다만, 이해하기 편한 방식으로 작성해주면 됨
문제3 - JOIN 응용2 🔴
내가 작성한 쿼리
SELECT serverno, round(avg(diffdate)) -- 소수점 자리수 빼먹음!
FROM
(
SELECT u.game_account_id,
u.first_login_date,
u.serverno,
DATEDIFF(p.date2, u.first_login_date) AS diffdate
FROM users u
INNER JOIN
(
SELECT p.game_account_id,
MAX(p.approved_at) AS date2
FROM payment p
GROUP BY p.game_account_id
)p
ON u.game_account_id = p.game_account_id
WHERE p.date2 > u.first_login_date)sub
WHERE diffdate >= 10
GROUP BY serverno
ORDER BY serverno DESC정답 쿼리
# 정답 쿼리
select serverno, round(avg(diffdate),0)as avgdiffdate
from( select a.game_account_id, datediff(date_format(date2,('%Y-%m-%d')) ,first_login_date) as diffdate,serverno
from( select game_account_id, first_login_date, serverno
from basic.users
)as a
inner join
( select game_account_id, max(approved_at)as date2
from basic.payment
group by game_account_id
)as c
on a.game_account_id=c.game_account_id
where date2>first_login_date
)as d
where diffdate>=10
group by serverno
order by serverno desc- 두 날짜 컬럼이 표현 방식이 달라서
DATE_FORMAT사용- 미세한 차이가 날 수 있음
users테이블 먼저 정리 후 JOIN
데이터 리터러시 1-1
데이터 리터러시란?
- 데이터를 읽는 능력
- 데이터를 이해하는 능력
- 데이터를 비판적으로 분석하는 능력
- 결과를 의사소통에 활용할 수 있는 능력
목적
- 데이터 수집과 데이터 원천을 이해
- 주어진 데이터에 대한 활용법 이해
- 데이터를 통한 핵심지표 이해
→ 올바른 질문을 던질 수 있도록 만들어 줌
데이터 분석에 대한 착각
- 일반적으로 데이터 분석을 배운다고 한다면 SQL,Python,Tableau 등의 스킬 학습
- 데이터를 잘 분석하면 문제, 목적, 결론이 나올 것이라 생각
- 데이터를 잘 가공하면 유용한 정보를 얻을 수 있다고 생각
- 분석에 실패하면 방법론, 스킬이 부족한 것이라 생각
데이터 해석 오류 사례
심슨의 역설 (Simpson's Paradox)
'부분'에서 성립한 대소 관계가 그 부분들을 종합한 '전체'에 대해서는 성립하지 않는 모순적인 경우
시각화를 활용한 왜곡
자료의 표현 방법에 따라 해석의 오류 여지가 존재
샘플링 편향 (Sampling Bias)
전체를 대표하지 못하는 편향된 샘플 선정으로 인해 오류 발생
상관관계와 인과관계
- 상관관계
- 두 변수가 얼마나 상호 의존적인지를 파악
- 한 변수가 증가하면 다른 변수도 따라 증가/감소하되 추이를 따름
- 인과관계
- 실질적으로 하나의 요인으로 인해 다른 요인의 수치가 변하는 형태 의미
- 원인과 결과가 명확
활용 예제
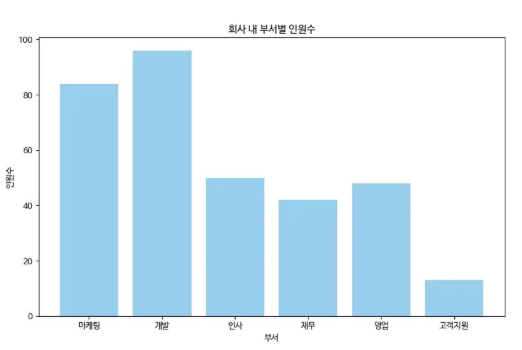
Q1. 위 그래프를 통해 어떤 것을 말할 수 있나요?
- 개발팀 인원이 가장 많음
- 고객지원팀은 다른 부서에 비해 현저히 적은 숫자
- 인사팀과 영업팀 인원이 비스함
Q2. 이 그래프를 작성한 사람은 무엇을 말하고 싶었을까요?
- 고객지원팀 인력 충원이 필요하다
정리
Q1은 데이터를 읽는 것
Q2는 데이터 작업 전 알고 싶은 것을 생각해보는 목적 사고적 방식
데이터 분석에 대한 접근법

'생각'이 주요한 단계에서 데이터 리터러시 필요
데이터 분석이 목적이 되지 않도록 '왜?'를 항상 생각해야 함
데이터 분석 파이썬 종합반 2주차
리스트✅
기본 사용법
- 가장 자주 사용되는 데이터 구조
- 가변한 시퀀스 (mutable sequence)
- 여러 값을 순서대로 담음
- 각 값은 쉼표로 구분
- 대괄호
[]사용
# 1. 리스트 생성
my_list = [1, 2, 3, 4, 5]
# 2. 리스트의 기본 구조
print(my_list) # 출력: [1, 2, 3, 4, 5]1) 인덱싱
# 리스트 생성
numbers = [1, 2, 3, 4, 5]
# 첫 번째 요소에 접근하기
first_number = numbers[0]
print("First number:", first_number)
# 두 번째 요소에 접근하기
second_number = numbers[1]
print("Second number:", second_number)
# 마지막 요소에 접근하기
last_number = numbers[-1]
print("Last number:", last_number)
# 음수 인덱스를 사용하여 역순으로 요소에 접근하기
second_last_number = numbers[-2]
print("Second last number:", second_last_number)2) 리스트의 메소드
-
append(): 항목 추가✅ -
extend(): 다른 리스트의 모든 항목 추가 -
insert(): 특정 위치에 항목 삽입 -
remove(): 특정 값 삭제 -
pop(): 특정 위치 값 제거 및 반환 -
index(): 특정 값 인덱스 찾기 -
count(): 특정 값 개수 세기 -
sort(): 리스트의 항목 정렬 -
reverse(): 리스트의 항목들을 역순으로 뒤집습니다.- 반환은 함수 결과값을 밖으로 끄집어낸다 = 결과 값을 얻어냈다 정도로만 이해!
- 다 외우려고 하지 말고 필요할때 찾아보면 됨
- 굳이 외우려면 ✅만!
# 리스트 생성
my_list = [1, 2, 3, 4, 5]
#리스트의 다양한 메서드(Methods)
my_list.append(6) # 리스트에 새로운 항목 추가
print(my_list) # 출력: [1, 2, 3, 4, 5, 6]
my_list.extend([7, 8, 9]) # 다른 리스트의 모든 항목을 추가
print(my_list) # 출력: [1, 2, 3, 4, 5, 6, 7, 8, 9]
my_list.insert(2, 10) # 두 번째 위치에 값 삽입
print(my_list) # 출력: [1, 2, 10, 3, 4, 5, 6, 7, 8, 9]
my_list.remove(3) # 값 3 삭제
print(my_list) # 출력: [1, 2, 10, 4, 5, 6, 7, 8, 9]
popped_value = my_list.pop(5) # 다섯 번째 위치의 값 제거하고 반환
print(popped_value) # 출력: 6
print(my_list) # 출력: [1, 2, 10, 4, 5, 7, 8, 9]
print(my_list.index(4)) # 출력: 3 (값 4의 인덱스)
print(my_list.count(7)) # 출력: 1 (값 7의 개수)
my_list.sort() # 리스트 정렬
print(my_list) # 출력: [1, 2, 4, 5, 7, 8, 9, 10]
my_list.reverse() # 리스트 역순으로 뒤집기
print(my_list) # 출력: [10, 9, 8, 7, 5, 4, 2, 1]insert메소드
list.insert(index, element)
# 요소를 삽입할 위치의 인덱스, 삽입할 요소의 값 3) 리스트 값 삭제
# 특정 값 삭제
del my_list[0]
print("첫 번째 항목 삭제 후 리스트:", my_list)
# 전체 삭제
my_list.clear()
print("모든 항목 제거 후 리스트:", my_list) 4) 리스트 값 변경
특정 위치 리스트 값을 다른 값으로 변경
my_list = ['apple', 'banana', 'cherry', 'date', 'elderberry']
# 리스트 값 변경하기
my_list[3] = 'dragonfruit'
print(my_list) # 출력: ['apple', 'banana', 'cherry', 'dragonfruit', 'elderberry']5) 중첩된 리스트에서 인덱싱
# 중첩된 리스트에서 인덱싱하기
nested_list = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
print(nested_list[1][0]) # 출력: 4 (두 번째 리스트의 첫 번째 항목)고급 사용법
1) 슬라이싱✅
- 리스트의 일부분 추출
- 특정 범위 항목 선택, 리스트 자르기
# 리스트 슬라이싱의 구분
# 아래는 실행하는 코드가 아닙니다
new_list = old_list[start:end:step]- ⚠️주의
- 처음을 가리키는 인덱스가 0 (❌1 아님❌)
- 끝에 입력할 인덱스는 내가 선택할 인덱스보다 +1
ex) 1부터 12번째 가져오고 싶다 =[0:13]
my_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 1. 일부분만 추출하기
print(my_list[2:5]) # 출력: [3, 4, 5]
# 2. 시작 인덱스 생략하기 (처음부터 추출)
print(my_list[:5]) # 출력: [1, 2, 3, 4, 5]
# 3. 끝 인덱스 생략하기 (끝까지 추출)
print(my_list[5:]) # 출력: [6, 7, 8, 9, 10]
# 4. 음수 인덱스 사용하기 (뒤에서부터 추출)
print(my_list[-3:]) # 출력: [8, 9, 10]
# 5. 간격 설정하기 (특정 간격으로 추출)
print(my_list[1:9:2]) # 출력: [2, 4, 6, 8]
# 6. 리스트 전체를 복사하기
copy_of_list = my_list[:]
print(copy_of_list) # 출력: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 7. 리스트를 거꾸로 뒤집기
reversed_list = my_list[::-1]
print(reversed_list) # 출력: [10, 9, 8, 7, 6, 5, 4, 3, 2, 1]2) 정렬 (sort)
- 리스트 항목 정렬 (오름차순)
- 항목이 동일한 형태일 경우에만 정렬
- 원래 리스트를 변경 / ❌새로 정렬된 리스트를 반환하지 않음❌
- 내림차순 정렬
numbers.sort(reverse = True)- 다시 오름차순
numbers.sort(reverse = False)
- 다시 오름차순
튜플
- 변경할 수 없는 시퀀스 자료형(immutable sequence)
- 여러 개의 요소를 저장하는 컨테이너
- 각 값은 쉼표로 구분
- 한 번 생성된 이후에는 요소를 추가, 삭제, 수정 불가
데이터를 보호하고 싶을 때 주로 사용(무결성 유지, 불변성 보장)- 튜플을 합치거나 반복하여 새로운 튜플 생성은 가능
- 소괄호
()사용
# 1. 튜플 생성
my_tuple = (1, 2, 3, 'hello', 'world')
# 2. 튜플의 기본 구조
print(my_tuple) # 출력: (1, 2, 3, 'hello', 'world')1) 튜플의 인덱싱, 슬라이싱
리스트와 기본 원리는 똑같음
my_tuple = (1, 2, 3, 'hello', 'world')
print(my_tuple[0]) # 첫 번째 요소에 접근
print(my_tuple[-1]) # 마지막 요소에 접근
print(my_tuple[2:4]) # 인덱스 2부터 3까지의 요소를 슬라이싱2) 튜플의 메소드
count(): 지정 요소 개수 반환index(): 지정 요소 인덱스를 반환
# 튜플 생성
my_tuple = (1, 2, 3, 4, 1, 2, 3)
# count() 메서드 예제
count_of_1 = my_tuple.count(1)
print("Count of 1:", count_of_1) # 출력: 2
# index() 메서드 예제
index_of_3 = my_tuple.index(3)
print("Index of 3:", index_of_3) # 출력: 23) 튜플 ↔ 리스트
- 튜플 → 리스트 :
list() - 리스트 → 튜플 :
tuple()
# 튜플을 리스트로 변경하기
my_tuple = (1, 2, 3, 4, 5)
my_list = list(my_tuple)
print(my_list) # 출력: [1, 2, 3, 4, 5]
# 리스트를 튜플로 변경하기
my_list = [1, 2, 3, 4, 5]
my_tuple = tuple(my_list)
print(my_tuple) # 출력: (1, 2, 3, 4, 5)딕셔너리
- 키 - 쌍 값의 데이터를 저장하는 자료구조
- 표로 만들기 좋음 >
pandas활용 - 키는 유일해야 하지만 값은 중복될 수 있음
- 해시테이블 구성
- 중괄호
{}사용
my_dict = {
'key1': 'value1',
'key2': 'value2',
'key3': 'value3'
}1) 기본기
# 빈 딕셔너리 생성
empty_dict = {}
# 학생 성적표
grades = {
'Alice': 90,
'Bob': 85,
'Charlie': 88
}
# 접근하기
print(grades['Alice']) # 출력: 90
# 값 수정하기
grades['Bob'] = 95
# 요소 추가하기
grades['David'] = 78
# 요소 삭제하기
del grades['Charlie']2) 딕셔너리의 메소드
keys(): 모든 키를 dict_keys 객체로 반환values(): 모든 값을 dict_values 객체로 반환items(): 모든 키-값 쌍을 (키, 값) 튜플로 구성된 dict_items 객체로 반환get(): 지정된 키에 대한 값을 반환- 키가 존재하지 않으면 기본값 반환
pop(): 지정된 키와 해당 값을 딕셔너리에서 제거 및 값 반환popitem(): 마지막 키-값 쌍을 제거 및 반환
# 딕셔너리 생성
my_dict = {'name': 'John', 'age': 30, 'city': 'New York'}
# keys() 메서드 예제
keys = my_dict.keys()
print("Keys:", keys) # 출력: dict_keys(['name', 'age', 'city'])
# values() 메서드 예제
values = my_dict.values()
print("Values:", values) # 출력: dict_values(['John', 30, 'New York'])
# items() 메서드 예제
items = my_dict.items()
print("Items:", items) # 출력: dict_items([('name', 'John'), ('age', 30), ('city', 'New York')])
# get() 메서드 예제
age = my_dict.get('age')
print("Age:", age) # 출력: 30
# pop() 메서드 예제
city = my_dict.pop('city')
print("City:", city) # 출력: New York
print("Dictionary after pop:", my_dict) # 출력: {'name': 'John', 'age': 30}
# popitem() 메서드 예제
last_item = my_dict.popitem()
print("Last item popped:", last_item) # 출력: ('age', 30)
print("Dictionary after popitem:", my_dict) # 출력: {'name': 'John'}퀴즈
1) 리스트 활용 퀴즈
- 다음 리스트에서 세번째 요소를 출력하세요.
my_list = [10, 20, 30, 40, 50]
정답
print(my_list[2])
- 다음 리스트에 60을 추가하세요.
my_list = [10, 20, 30, 40, 50]
정답
my_list.append(60)
- 다음 리스트의 길이를 출력하세요.
my_list = ['apple', 'banana', 'orange', 'grape']
정답
print(len(my_list))
- 다음 리스트의 마지막 요소를 제거하세요.🔴
my_list = ['car', 'bus', 'bike', 'train']
정답
del my_list[-1]
# 쓰여있는 정답은
my_list.pop(-1)
- 다음 리스트를 역순으로 출력하세요.
my_list = ['red', 'green', 'blue', 'yellow']
정답
my_list.reverse()
print(my_list)2) 튜플 활용 퀴즈
- 다음 튜플에서 세번째 요소를 출력하세요.
my_tuple = (10, 20, 30, 40, 50)
정답
print(my_tuple[2])
- 다음 튜플의 길이를 출력하세요.
my_tuple = ('apple', 'banana', 'orange', 'grape')
정답
print(len(my_tuple))
- 다음 튜플을 역순으로 출력하세요.🔴
my_tuple = ('red', 'green', 'blue', 'yellow')
정답
reversed_tuple = my_tuple[::-1]
print(reversed_tuple)
- 다음 튜플을 리스트로 변환하세요.
my_tuple = (1, 2, 3, 4, 5)
정답
list(my_tuple)
- 다음 튜플과 다른 튜플을 연결하여 새로운 튜플을 만드세요.🔴
my_tuple1 = ('a', 'b', 'c') my_tuple2 = ('d', 'e', 'f')
정답
connected_tuple = my_tuple1 + my_tuple23) 딕셔너리 활용 퀴즈
- 다음 딕셔너리에서 'name'에 해당하는 값을 출력하세요.
my_dict = {'name': 'Alice', 'age': 30, 'city': 'New York'}
정답
answer = my_dict['name']
print(answer)
- 다음 딕셔너리에 'gender'를 추가하세요.
my_dict = {'name': 'Bob', 'age': 25, 'city': 'Los Angeles'}
정답
my_dict['gender'] = 'female'
print(my_dict)
- 다음 딕셔너리의 길이를 출력하세요. 🔴
my_dict = {'a': 100, 'b': 200, 'c': 300}
정답
answer = len(my_dict)
print(answer)다음 딕셔너리에서 'age'를 제거하세요.
my_dict = {'name': 'Charlie', 'age': 35, 'city': 'Chicago'}
정답
del my_dict['age']데일리퀘스트
SQL - 카테고리 별 상품 개수 구하기
SQL - 고양이와 개는 몇 마리 있을까
SQL - 입양 시각 구하기(1)
SQL - 진료과별 총 예약 횟수 출력하기
일기
- SQL
코드카타 24-27✅라이브세션 6회차✅ - Python
종합반 2주차✅ - 데이터리터러시
1-1강 복습✅1-2강✅
새로운 조 편성 완료😊 기존 조랑은 분위기가 또 확연히 다르다
뭔가 알짝딱+잔잔하게 흘러가는 느낌 ! 조용한 분들이 상대적으로 더 많은 것 같고 아직까지는 나도 낯을 가리고 있어서 분위기에 적응중 (포데이토의 활발한 분위기가 좀 그립지만 이것도 좋다)
잠을 못 자는 바람에 라이브세션 해설할때쯤 잤다 ㅋ 아효효
그거 녹강 다시 듣고 어쩌고 하느라 생각보다 많은 걸 하진 못했지만 그래도 목표는 다 이뤘으니 성공이야
기초 프로젝트까지 함께 할 팀원들이니 유대관계를 잘 쌓아보아야겠다
내일도 파이팅.. 🍀
