원티드 X 위코드 백엔드 프리온보딩을 끝내고
Assignment 1 - 에이모

[필수사항]
- 필수 사용 데이터베이스: mongodb
[개발 요구사항]
- 원티드 지원 과제 내용 포함
- 게시글 카테고리
- 게시글 검색
- 대댓글(1 depth)
- 대댓글 pagination
- 게시글 읽힘 수
- 같은 User가 게시글을 읽는 경우 count 수 증가하면 안 됨
- Rest API 설계
- Unit Test
- 1000만건 이상의 데이터를 넣고 성능테스트 진행 결과 필요
나의 분석
저는 요구사항을 분석하기에 앞서 mongoDB의 기본사항과 특성을 확인했습니다.
그리고 요구사항 중 문제가 발생 할 만한 여지가 어느 부분에 있는지 집중해서 생각했습니다.
특정되지 않은 1000만건의 데이터가 게시글 또는 댓글, 대댓글로 몰려있는 상황을 가정하기로 했습니다.
결론
주어진 테스트 조건이 1000만건의 데이터를 저장하는 경우이기 때문에 하나의 문서에 방대한 데이터가 몰리거나 많은양의 데이터를 페이지네이션을 해야하는 경우가 언제든지 발생 할 수 있다고 판단했습니다.
하나의 문서에 많은 양의 데이터가 몰리는 경우
첫째로 당연히 많은 메모리를 차지합니다. 이것은 문서를 가져오기 위해 서버와 문서가 수신될 때 클라이언트에 할당되어야 하는 메모리입니다.
둘째, 대용량 문서는 네트워크를 통해 이동하는 속도가 느립니다.
셋째, MongoDB는 (상당히 의도적인) 16MB 문서 크기 제한을 부과합니다.
많은양의 문서가 있는 경우
결국 더 높은 번호의 페이지를 볼수록 페이지 사이를 이동하는 속도가 느려지게 됩니다.
우리는 위에 나열 된 테스트 조건을 테스트하기 위해 두가지 방법으로 프로젝트를 구현했습니다. 그리고 결론적으로 버킷 패턴을 사용해 많은 양의 데이터가 몰리는 것과 데이터를 스킵하는 과정을 줄이고자 했습니다.
테스트
성능 테스트 조건
1000만여 건의 데이터 추가 후 페이지당 100개씩 pagination을 시도
MongoDB에서 흔히 페이지네이션에서 사용하는 skip, limit를 사용하는 경우
Bucket Patten을 사용하여 페이지네이션을 사용하는 경우


1페이지 조회 할때는 기본적으로 제공하는 skip, limite이 빠른것을 알 수 있습니다. 하지만 많은 양의 데이터를 스킵하는 경우 속도차이가 나기 시작합니다. 그 이유는 skip, limit이 작동하는 방식으로 인해 발생하는 일반적인 문제입니다. 데이터베이스에서 점프해서 바로 이동하는게 아니라 데이터베이스는 빠르게 skip의 문서를 지나가고 limt에 맞춰 문서를 반환하기 때문입니다.
그리고 결론적으로 버킷 패턴을 사용해 많은 양의 데이터가 몰리는 것과 데이터를 스킵하는 과정을 줄여 유의미한 속도의 차이가 발생하게 되었습니다.
Assignment 2 - 8퍼센트

[필수사항]
- 필수 사용 데이터베이스: SQLite
[개발 요구사항]
✔️ API 목록
- 거래내역 조회 API
- 입금 API
- 출금 API
✔️ 주요 고려 사항은 다음과 같습니다.
- 계좌의 잔액을 별도로 관리해야 하며, 계좌의 잔액과 거래내역의 잔액의 무결성의 보장
- DB를 설계 할때 각 칼럼의 타입과 제약
- 거래내역이 1억건을 넘어갈 때에 대한 고려
- 이를 고려하여 어떤 설계를 추가하셨는지를 README에 남겨 주세요.
나의 분석
우선 요구사항에서 요구하는 잔액의 무결성을 최우선으로 고려했습니다. 일단 SQLite의 기본 격리 수준이
SERIALIZABLE이고 실제로 쓰기를 직렬화해서 직렬화 가능한 트랜잭션을 구현하고 있었습니다.
동시성을 위해 격리 수준을 낮추는것보다는 기본설정을 그대로 사용하고자 했습니다.
그리고 거래내역이 1억 건을 넘어가는 경우 DB의 용량과 속도에 이슈가 생길 것이라고 생각했습니다.
결론
물리적인 DB의 용량 문제와 속도문제를 해결하기 위해 분산 저장하기로 결정했습니다.
유저 프라이머리키를 모듈러 연산을 해 입출금 DB를 나눠 사용하기로 했습니다. 그리고 분산 저장에서 자료를 검색 할때 고유한 계좌번호를 인덱스로 지정해 검색의 효율성을 높이고자 했습니다.
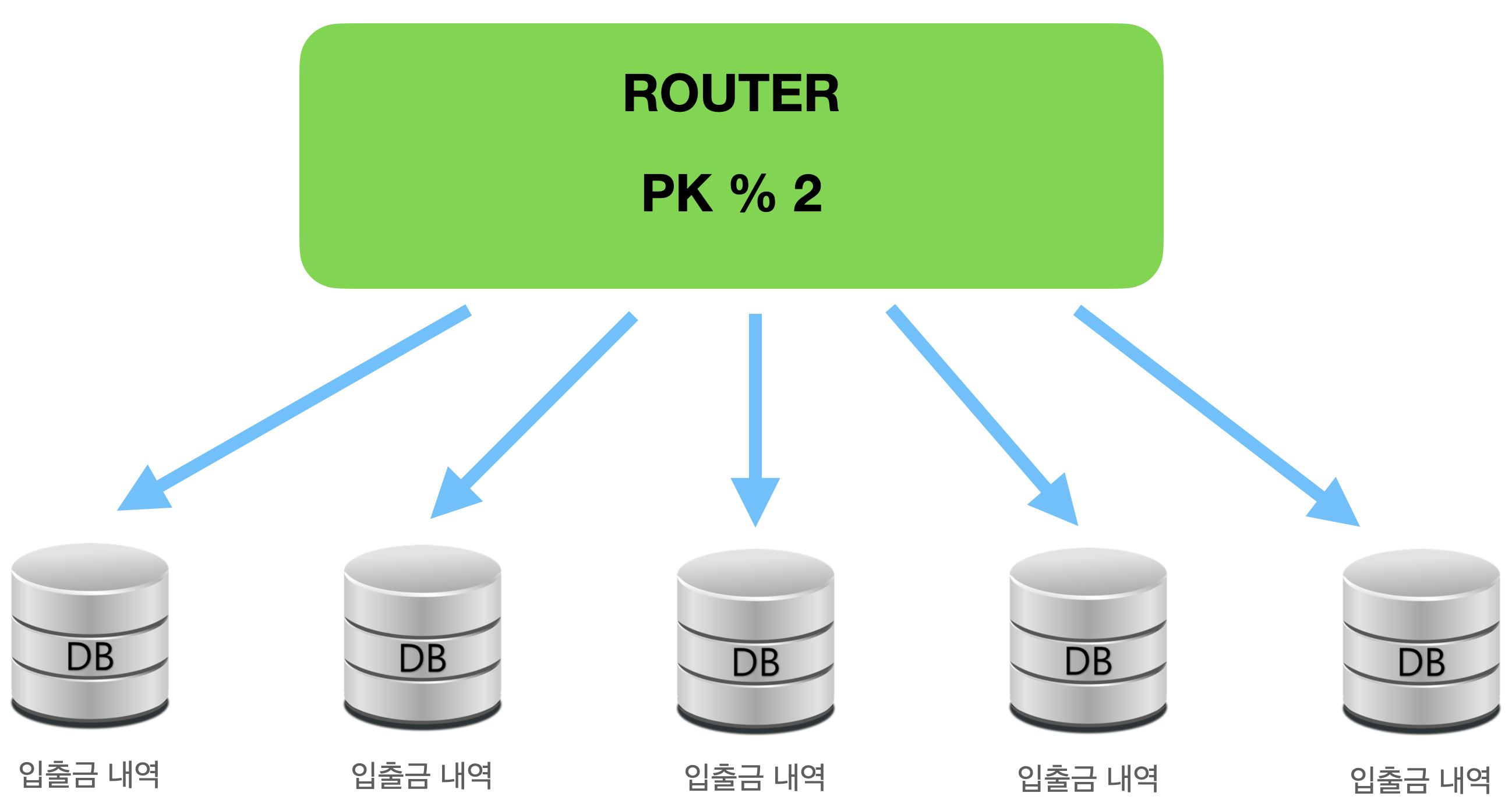
모듈러 샤딩을 사용해서 얻게 되는 이점과 단점
데이터 균등 분배
DB추가 증설시 모듈러 연산을 통해 재배치 필요
예측 가능한 범위에서 분산처리 할 데이터베이스를 미리 정하고 그에 따라 안정적으로 분산 저장하고 디비 리소스를 잘 활용 할 수 있습니다. 과제를 위해 유저와 계좌정보를 갖고 있는 마스터 DB와 유저 아이디를 기반으로 한 홀수, 짝수 두개의 디비에 분산 저장하기로 했습니다.
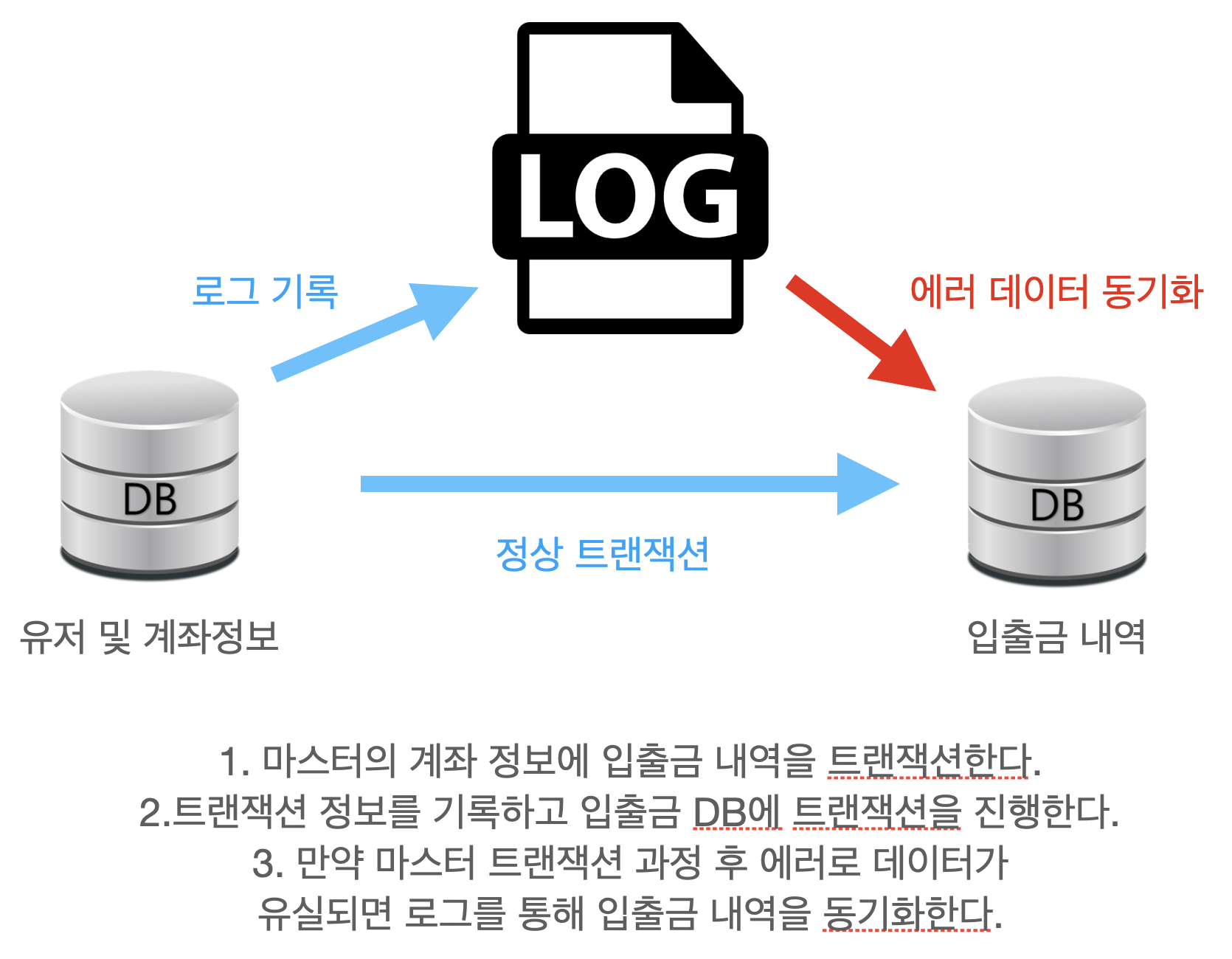

마스터 트랜잭션 과정 중에 로그를 남기고 그 로그를 통해 입출금 내역의 동기화를 시도하려고 했으나 시간이 부족했습니다. 분산 데이터 저장, 디비격리 수준, 멀티 데이터베이스 설정 등 부족한 지식을 채우면서 정말 이렇게 구현하는게 맞을까? 옳은 판단인지 정보를 수집하고 실험하는데 시간을 사용하게 되었습니다.
분산 저장 Master: 유저,계좌 A: 홀수 유저 거래내역 B: 짝수 유저 거래내역