sdfsd
CQRS를 고려하자!
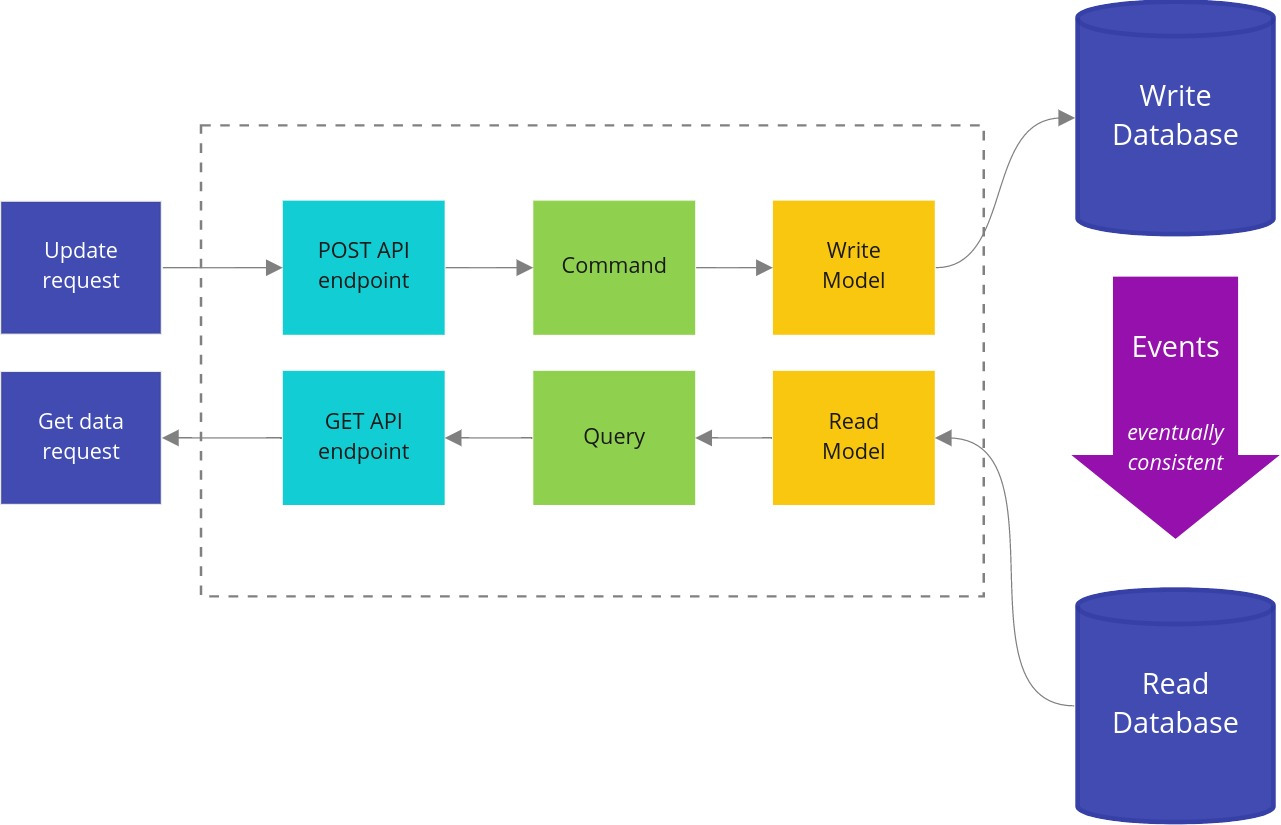
CQRS는 Command and Query Responsibility Segregation(명령과 조회의 책임 분리)을 나타냅니다. 이름처럼 시스템에서 명령을 처리하는 책임과 조회를 처리하는 책임을 분리하는 것이 CQRS의 핵심입니다. 굉장히 단순한 아이디어이지만 명령과 조회를 나누는것이 모호할때도 있고
무엇보다 디비의 동기화가 중요합니다. nestjs의 배치 모듈과 sqlite3의 backup 명령어를 통해 마스터(쓰기) -> 슬레이브(읽기)형식으로
구현하고자 했습니다.
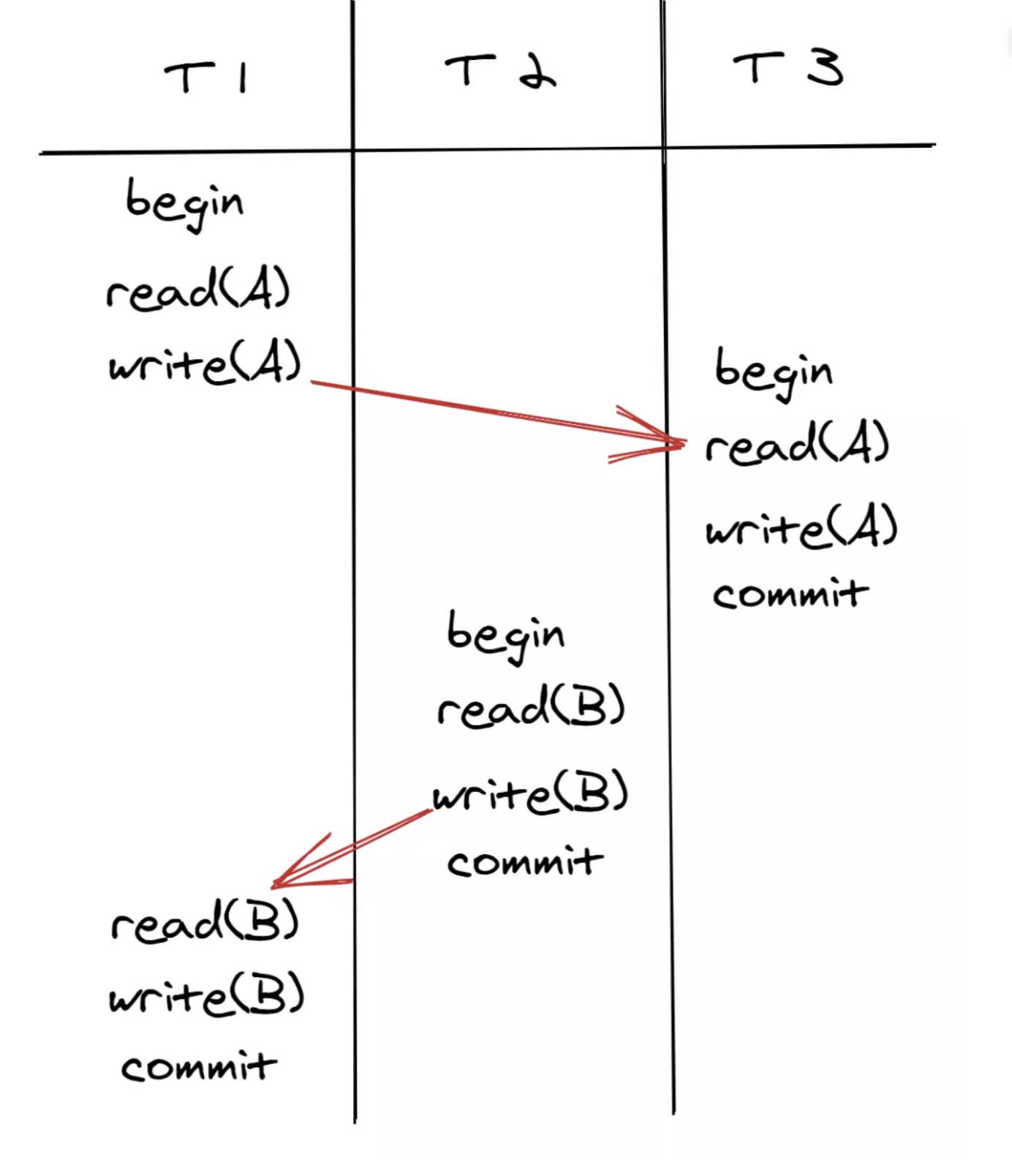
격리 수준은 SERIALIZABLE!
SQLite의 기본 격리 수준은 SERIALIZABLE입니다. SQLite는 실제로 쓰기를 직렬화하여 직렬화 가능한 트랜잭션을 구현합니다.
격리 수준을 설정하는 것에서 가장 큰 고민과 시간을 들이게 되었습니다. 동시성을 위해 격리 수준을 낮추는 것을 고려해봤지만 금융거래에서 가장 큰 치명적인 이슈를 데이터의 무결성이라고 생각했습니다. 아래와 같은 읽기-쓰기, 쓰기-읽기, 쓰기-쓰기 충돌로 인한 데데이터 무결성이 동시성보다 우선되어야 한다고 생각되어 시리얼라이저블을 선택하게 되었습니다.
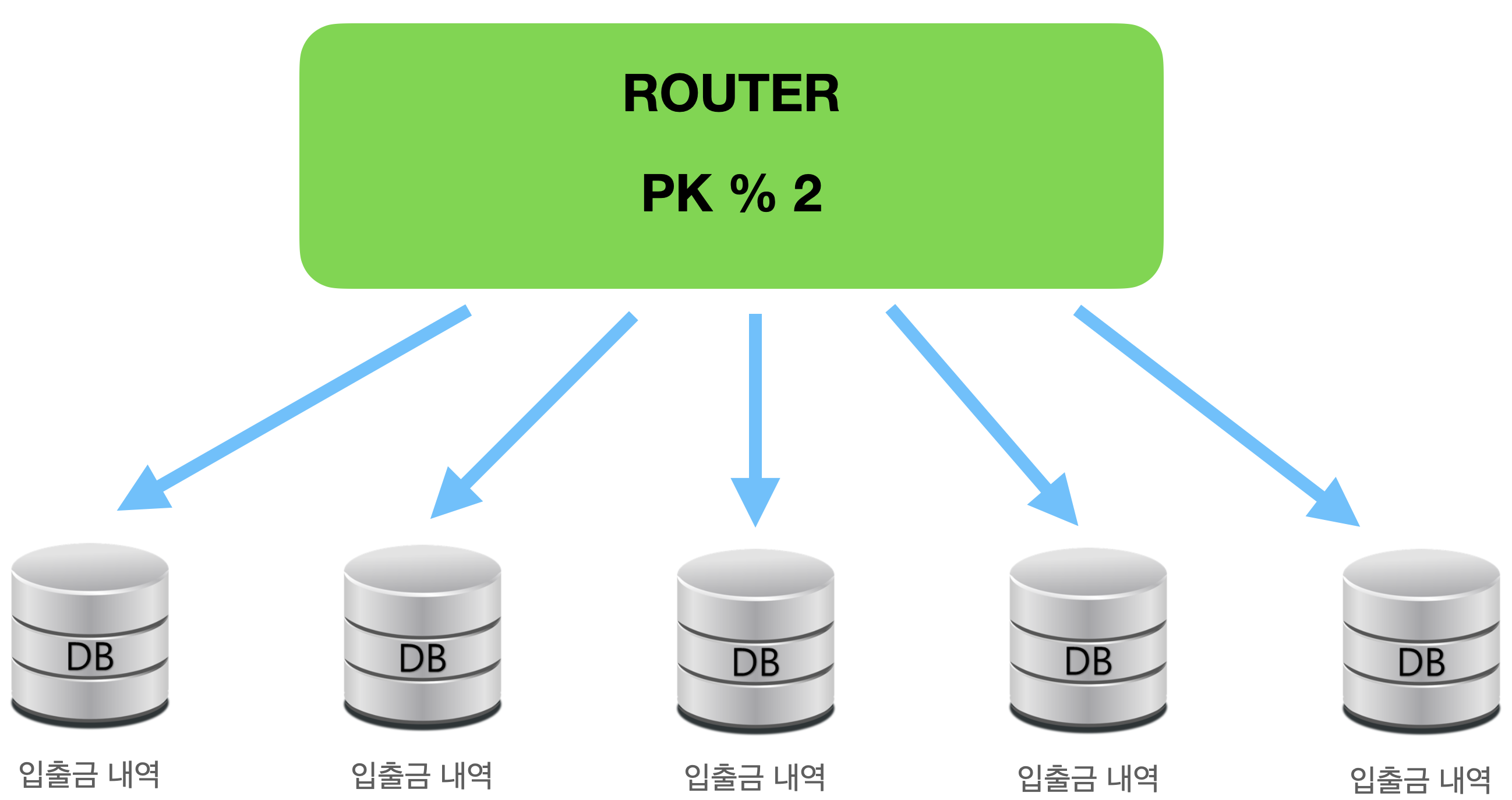
DB분산 처리를 위해 나눠보자!
이번 과제에서는 거래내역 1억건 이상이라는 가정이 있었고 이에 따라 하나의 디비에 데이터를 저장하게 되면 아래와 같은 이슈를 만날 수 있다고 판단 했습니다.
- CRUD속도
- 용량이슈
그래서 디비를 분산 저장하기 위해 모듈러샤딩을 고려하고 적용하게 되었습니다.
요구 사항
- 라우팅 구분을 위해 유저 PK를 샤딩을 위해 사용합니다.
모듈러 샤딩을 사용해서 얻게 되는 이점과 단점
- 데이터 균등 분배
- DB추가 증설시 모듈러 연산을 통해 재배치 필요
예측 가능한 범위에서 분산처리 할 데이터베이스를 미리 정하고 그에 따라 안정적으로 분산 저장하고 디비 리소스를 잘 활용 할 수 있습니다. 과제를 위해 유저와 계좌정보를 갖고 있는 마스터 DB와 유저 아이디를 기반으로 한 홀수, 짝수 두개의 디비에 분산 저장하기로 했습니다.
분산 저장 된 계좌번호에 Index
아무리 분산 저장되어 하나의 DB에 저장된 데이터가 적다하더라도 결국 검색 과정에서 풀 스캔 하게 됩니다.
하지만 다행히 sqlite는 인덱싱을 지원합니다. 따라서 효율성을 높이기 위해 쿼리 빈도가 높은 필드인 계좌번호에 인덱싱을 했습니다.
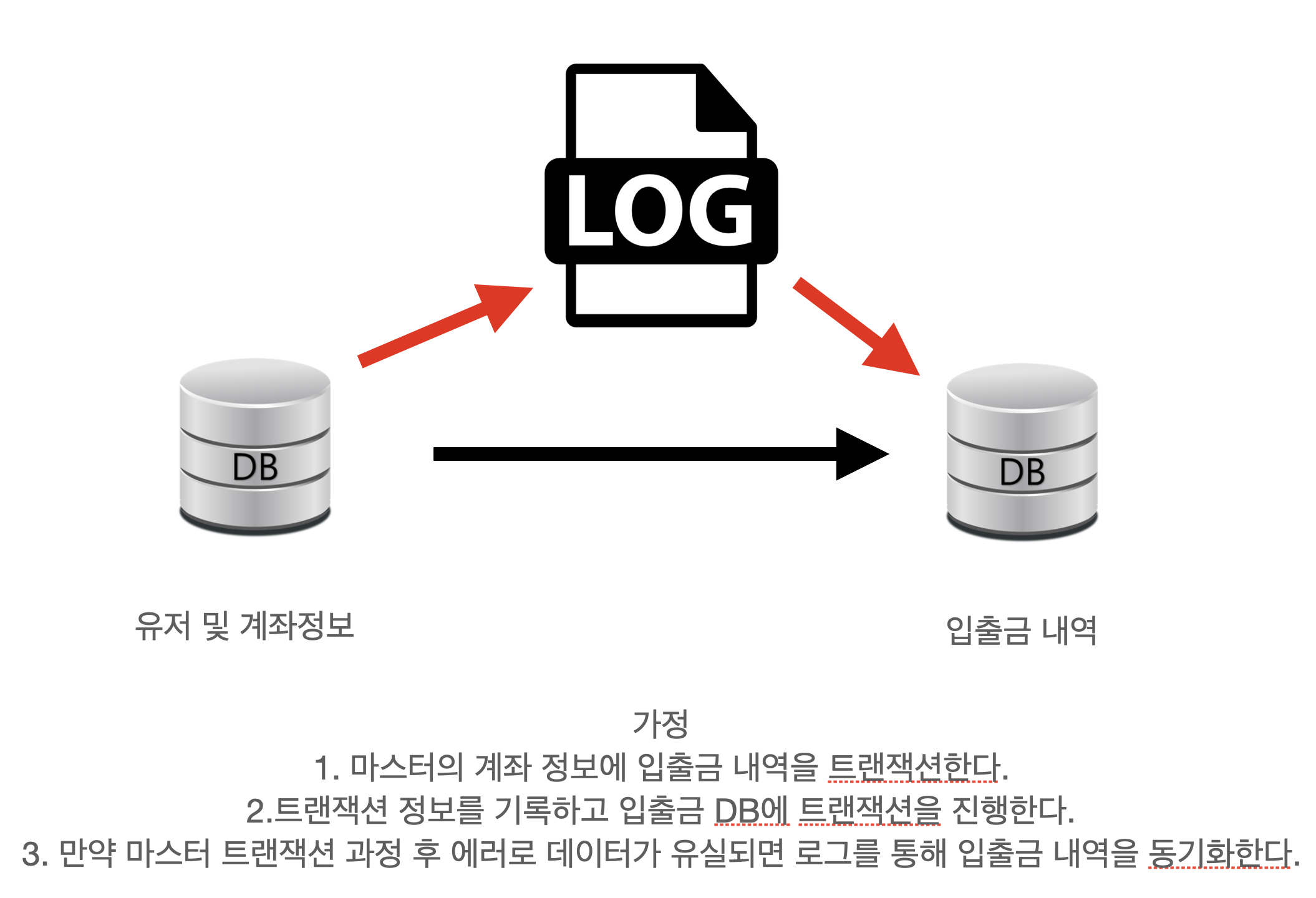
무결성을 보존하기 위한 로직
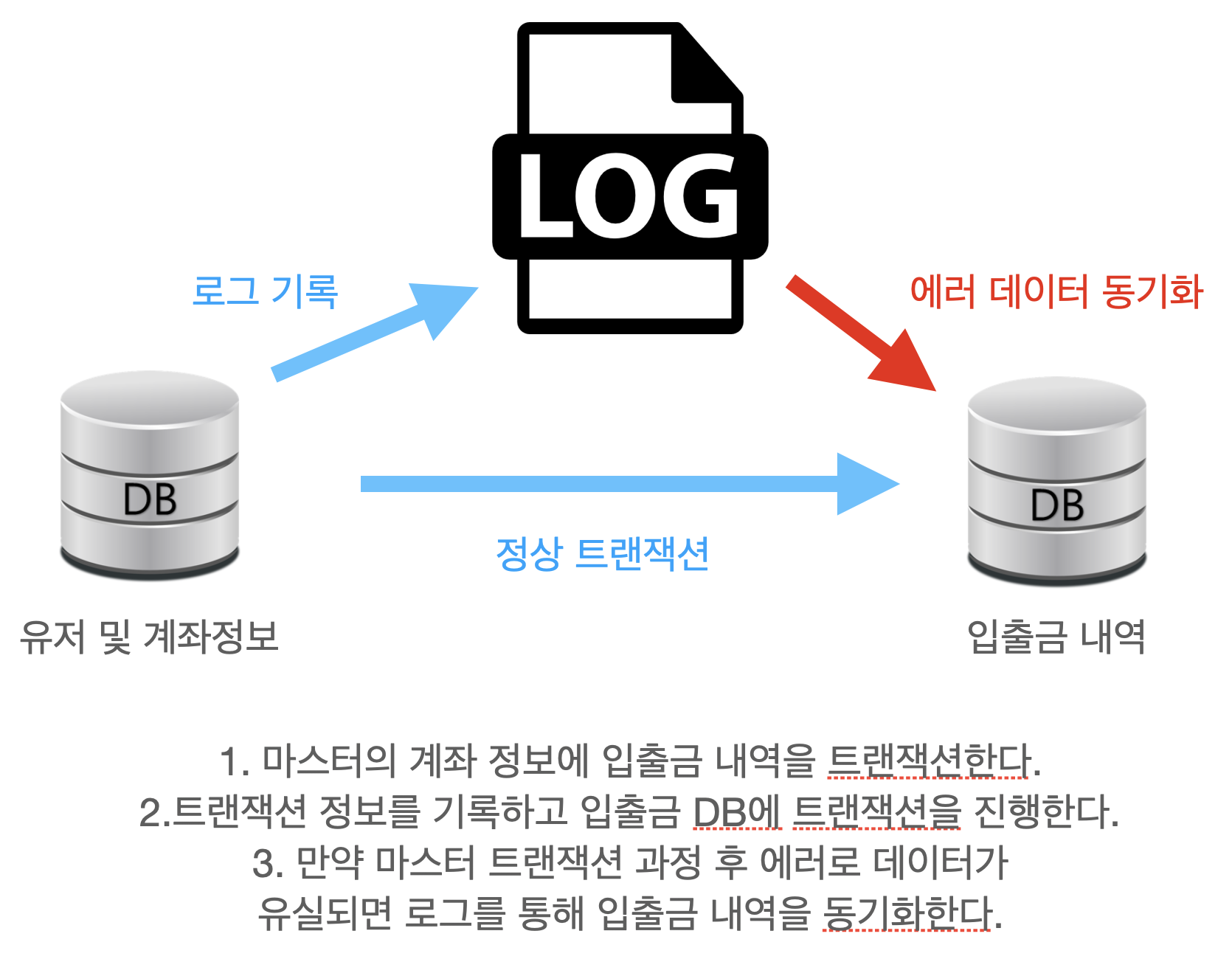
하지만 실제 구현은!

마스터 트랜잭션 과정 중에 로그를 남기고 그 로그를 통해 입출금 내역의 동기화를 시도하려고 했으나 시간이 부족했습니다.
분산 데이터 저장, 디비격리 수준, 멀티 데이터베이스 설정 등 부족한 지식을 채우면서 정말 이렇게 구현하는게 맞을까? 옳은 판단인지 정보를 수집하고 실험하는데 시간을 사용하게 되었습니다.
