컬렉션(Collection)
객체들의 집합
-
객체를 담을 수 있으며 컨테이너(container)라고도 한다.
-
컬렉션에서는 객체를 컬렉션에 추가하거나 혹은 삭제하거나, 검색하는 등의 객체 단위의 연산을 제공한다.
-
배열은 사이즈가 고정되어 있는 반면에 컬렉션은 가변적(Resizable)이다.
컬렉션 프레임워크
-
컬렉션을 다루는 프레임워크
-
여기서 제공하는 모든 클래스는 Object 클래스형에 대한 연산만을 제공한다.
-
기본형 데이터는 다루지 않는다.
-
java.util 패키지 내에 있다.
구성 요소 세가지
-
인터페이스 : 컬렉션에서 공통으로 제공해야 하는 연산들을 추상적으로 정의하고, 구체적인 구현은 구현 클래스에 위임
-
구현 클래스 : 컬렉션을 실제로 어떤 자료구조를 적용해 구현하느냐에 따라서 컬렉션의 종류가 달라진다.
-
알고리즘 : 컬렉션마다 유용하게 사용할 수 있는 메서드를 의미한다.
컬렉션 프레임워크의 상속 계층도

-
크게 Collection 인터페이스와 Map 인터페이스로 나누고, 컬렉션을 다루는 기능을 정의해서 제공한다.
-
Collection 인터페이스에서 선언한 메서드는 컬렉션 프레임워크의 컬렉션에 참여하는 구현 클래스가 지켜야 하는 최소한의 공통된 기능을 정의한다.
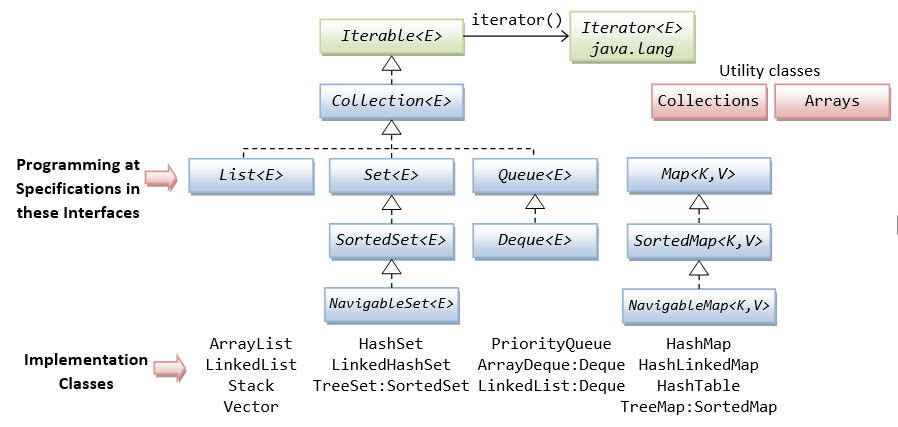
- 구현한 인터페이스의 이름이 클래스의 이름에 포함되어 있어서 클래스의 특징을 쉽게 알 수 있지만, Vector, Stack, Hashtable, Properties와 같은 컬렉션 클래스는 컬렉션 프레임워크가 정의되기 전에 만들어져서 명명 규칙에서 어긋난다.
컬렉션 프레임워크의 네 가지 종류
-
리스트 (List) : 인덱스 순서로 요소를 저장한다. 중복된 데이터를 저장할 수 있다.
-
큐 (Queue) : 선입선출(FIFO)의 구조
-
집합 (Set) : 순서가 없으며 데이터의 중복을 없앤다. 집합 연산(합집합, 교집합, 차집합)을 지원한다.
-
맵 (Map) : Key - Value 쌍으로 데이터를 저장하며 순서가 없다. Key는 중복될 수 없다.
- List와 Queue는 선형 구조로 인덱스가 있어서 순서가 있다. 반면에 Set와 Map은 비선형 구조로 순서가 없다.
Collection 인터페이스
-
가장 기본이 되는 인터페이스로 List, Set, Queue를 포함한다.
-
List, Set, Queue의 공통된 부분을 뽑아 일반화한 인터페이스
List 인터페이스
-
순서가 있는 데이터의 집합으로 중복을 허용한다.
-
List는 순서를 기억하고 있기 때문에 0번째 1번째 n번째의 자료를 꺼낼 수 있는 get(int)메소드를 가지고 있다.
-
정렬은 안된다.
-
구현 클래스의 종류 : ArrayList, LinkedList, Stack, Vector 등
ArrayList 클래스
-
순차 구조 : 반드시 물리적으로 연속해서 저장해야 한다.
-
배열(Array)과 동일한 원리
-
중간에 값을 삽입하면 뒤에 있는 값들은 모두 뒤로 한 칸씩 밀려나고, 중간에 값이 삭제되면 뒤에 있던 값들은 모두 앞으로 한 칸씩 들어간다.
-
값을 검색은 빠르게 할 수 있지만 삽입이나 삭제가 자주 일어나는 경우 재배치 시간이 길어지기 때문에 주의해야 한다.
-
순차적인 추가와 삭제는 제일 빠르다.
-
값을 추가했을 때 배열이 동적으로 늘어나는 것이 아니라 용량이 꽉 찼을 경우 더 큰 용량의 배열을 만들어 옮기는 작업을 하게 된다.
-
더 큰 배열에다 기존 배열의 원소들을 복사한다.
-
DEFAULT_CAPACITY = 10
-
인덱스를 이용해서 접근성이 좋다.
LinkedList 클래스
연결 구조 기반으로 데이터의 추가와 삭제에 유리하지만, 데이터의 접근성은 떨어진다.
-
앞서 ArrayList 클래스와 같은 선형 구조의 단점은 삽입이나 삭제 후 재배치를 위해 값의 이동이 많아지고, 배열의 고정된 크기 이상으로 값을 집어 넣으면 더 큰 배열을 만들어서 기존 배열의 원소들을 복사해 집어 넣기 때문에 성능상 문제가 된다.
-
선형 구조의 단점을 보완하기 위해 나온 것이 연결 구조 방식(LinkedList)이다.
-
순차 구조처럼 값이 물리적으로 연속해서 저장하지 않아도 된다.
-
단, 물리적으로 연속적이지 않은 항목을 논리적 순서대로 연결해야 하기 때문에 하나의 항목은 다음 항목에 대한 주솟값을 가지고 있어야 한다. 이러한 단위 구조가 노드(node)다.
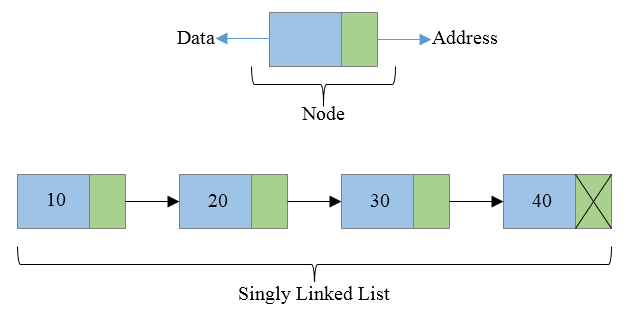
-
항목의 순서를 나타내는 것이 아니라 각 항목에 저장된 다음 항목의 주소를 참조하여 연결한다.
-
따라서, 물리적인 순서를 맞추는데 오버헤드(Overhead)가 발생하지 않는다.
-
ArrayList와 달리 중간값의 추가와 삭제가 쉽지만, 순차적인 추가와 삭제는 ArrayList보다 약간 더 느리다.
-
단순히 기존 포인터를 끊고 새로운 노드에 연결하면 되기 때문에 요소의 추가 삭제가 쉽다.
-
배열의 경우는 연속적으로 메모리상에 존재하고, 참조변수 하나당 4byte이기 때문에 시작배열 주소 + n * 데이터 타입의 크기를 통해서 원하는 인덱스에 쉽게 접근할 수 있다.
-
하지만, LinkedList는 불연속적으로 위치한 각 요소들이 서로의 주소를 참조해서 연결된 식이라서 처음부터 n번째 데이터까지 살펴봐야만 탐색이 가능하다.
-
즉, LinkedList는 저장해야하는 데이터의 개수가 많아질수록 데이터를 읽어 오는 시간, 접근 시간(access time)이 길어진다는 단점이 있다.
Stack 클래스
-
후입선출(LIFO)의 구조
-
스택에서 연산은 한쪽 끝에서만 추가, 삭제가 이루어진다.
-
Vector 클래스를 상속 받아서 구현
Vector 클래스
- 내부에서 동기화 처리가 일어나서 요즘은 잘 쓰지 않는다.
Set 인터페이스
-
순서를 유지하지 않아도 되는 집합으로 데이터 중복을 허용하지 않는다.
-
주로 해시 테이블(hash table)을 이용해 구현한다.
-
해시 테이블 : 해시 테이블은 데이터를 저장하는 테이블로, 해싱 함수에 의해 계산된 주소의 위치(테이블 내 위치)에 항목을 저장한다.
-
해시 테이블은 배열(array)과 해싱 함수(hash function)을 사용하여 맵(map)을 구현하고, key-value 쌍을 저장한다. Map과 마찬가지로 key는 중복이 안된다.
-
해싱(hashing)은 키 값을 비교하여 찾는 검색 방법이 아니라, 산술 연산을 이용해 키가 있는 위치를 계산하여 바로 찾아가는 검색 방법이다.
-
해싱은 문자열을 원래보다 짧고 상징적인 값이나 키(key)로 변환해 검색할 때 사용한다. 왜냐하면 원래의 값을 이용해 검색하는 것보다 빠르기 때문이다.
-
해싱 함수(hashing function) : 키 값의 항목의 위치로 변환하는 함수
-
예를 들어 "John Smith"를 찾으려면 먼저 객체의 해시 코드를 계산하고 테이블의 크기에 맞추어 나머지 연산을 수행한 후 결과로 나오는 값을 테이블의 인덱스(index)로 사용하면 된다.
-
데이터를 Key로 저장하기 때문에 중복이 안된다.
-
구현 클래스의 종류 : HashSet, LinkedHashSet, TreeSet 등
HashSet
-
비정렬이면서 비순차적(Unordered)인 세트(set) 구조
-
객체를 추가할 때 해시 코드를 사용한다.
LinkedHashSet
-
HashSet 클래스를 순차 구조로 만든 버전
-
모든 항목에 대해 이중 연결 리스트 구조
-
객체가 추가된 순서로 처리 가능
TreeSet
-
두 개의 정렬 컬렉션 중 하나 (다른 하나는 TreeMap)
-
이진 검색 트리 방법 중 red-black 트리 구조 사용

-
레드 블랙 트리 : 부모노드보다 작은 값을 가지는 노드는 왼쪽 자식으로, 큰 값을 가지는 노드는 오른쪽 자식으로 배치하여 데이터의 추가나 삭제 시 트리가 한쪽으로 치우쳐지지 않도록 균형을 맞추어준다.
-
오름차순으로 정렬
Queue 인터페이스
-
선입선출(FIFO)의 구조
-
프론트(front) : 첫번째 데이터로 나가는 쪽(삭제 연산 수행)
-
리어(rear) : 마지막 데이터로 들어오는 쪽(삽입 연산 수행)
-
인큐(enqueue) : 삽입 연산 수행(리어)
-
디큐(dequeue) : 삭제 연산 수행(프론트)
-
LinkedList 클래스가 Queue 인터페이스 구현
-
구현 클래스의 종류 : priorityQueue, priorityBlockingQueue, LinkedList, ArrayBlockingQueue, LinkedBlockingQueue 등
Map 인터페이스
-
키(key)를 값(value)에 매핑(mapping)하는 자료구조를 제공한다.
-
순서가 없다.
-
키(key)는 중복이 허용되지 않지만, 값(value)는 중복이 된다.
-
key와 value 모두 참조형만 가능
-
저장할 때 put()메소드를 이용하여 key와 value를 함께 저장한다.
-
원하는 값을 꺼낼때는 key를 매개변수로 받아들이는 get()메소드를 이용하여 값을 꺼낸다.
-
두 키가 같은지 결정하기 위해서는 Set 인터페이스처럼 equals() 메서드를 사용한다.
HashMap 클래스
-
비정렬이면서 비순차적인 구조
-
배열 기반과 연결 구조 기반이 결합된 형태로 추가, 삭제, 검색, 접근성 모두 뛰어나다.
-
key는 key가 되는 객체의 해시 코드를 기반으로 한다.
-
null을 갖는 키를 하나 저장할 수 있다.
LinkedHashMap 클래스
-
LinkedHashSet 클래스처럼 객체가 추가되는 순서를 유지
-
항목의 추가나 삭제에는 HashMap보다 느리지만, 순차적이면서 반복 처리인 경우 더 빠르다.
TreeMap
-
TreeSet과 같이 정렬 컬렉션
-
모든 항목이 자연율(기본값)에 의해 정렬된다.
-
데이터를 추가, 삭제가 빠르고 검색도 빠르다.
-
하지만 데이터를 저장할 때는 정렬을 하기 때문에 다른 자료구조보다 조금 늘다.
-
TreeSet처럼 Comparable이나 Comparator 인터페이스를 구현하는 클래스(정렬 순서를 정의하고 있는) 객체를 생성자의 매개 변수로 전달할 수 있다.
