JPA(Java Persistence API)
- 자바 진영에서 ORM(Object-Relational Mapping) 기술 표준으로 사용되는 인터페이스의 모음
JDBC,Spring JDBC
JDBC(Java DataBase Connectivity)
-
Spring을 사용하기 전에,일반 Java 언어에서 DB 연결을 위해 사용하는 것 (자바와 데이터베이스를 연결하기 위한 Java 표준 인터페이스)
-
JBC 표준 인터페이스는 다음 3가지 기능을 표준 인터페이스로 정의
• java.sql.Connection : 연결
• java.sql.Statement : SQL을 담은 내용
• java.sql.ResultSet : SQL 요청 응답 -
Spring Data JDBC, Spring Data Jpa 등과 같은 기술이 등장하면서 JDBC API를 직접적으로 사용하는 일이 줄어들었으나 Spring Data JDBC, Spring Data Jpa 같은 기술도 데이터 베이스와 연동하기 위해 내부적으로 JDBC를 이용하기 때문에 JDBC 동작흐름에 대해 알필요가 있다.
JDBC의동작흐름

- JDBC는 Java 애플리케이션 내에서 JDBC API를 사용하여 데이터베이스에 접근하는 단순한 구조이다.
- JDBC API를 사용하기 위해서는 JDBC 드라이버를 먼저 로딩한 후 데이터베이스와 연결하게 된다.
※ JDBC 드라이버
- 데이터베이스와의 통신을 담당하는 인터페이스
- Oracle, MS SQL, MySQL 등과 같은 데이터베이스에 알맞은 JDBC 드라이버를 구현하여 제공
- JDBC 드라이버의 구현체를 이용해서 특정 벤더의 데이터베이스에 접근할 수 있음
JDBC API 사용 흐름
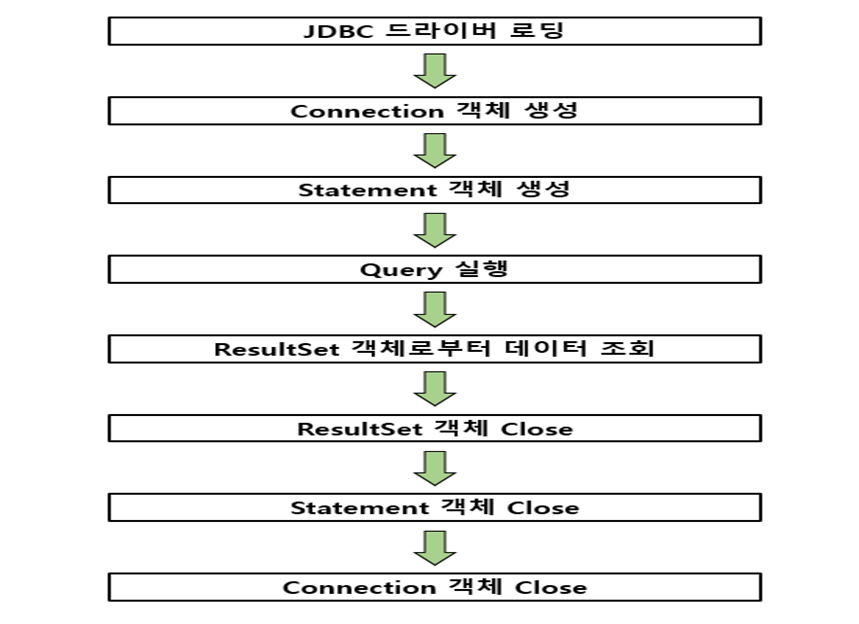
- JDBC 드라이버 로딩
• 사용하고자 하는 JDBC 드라이버를 로딩한다. JDBC 드라이버는 DriverManager 클래스를 통해 로딩된다. - Connection 객체 생성
• JDBC 드라이버가 정상적으로 로딩되면 DriverManager를 통해 데이터베이스와 연결되는 세션(Session)인 Connection 객체를 생성한다. - Statement 객체 생성
• Statement 객체는 작성된 SQL 쿼리문을 실행하기 위한 객체로 정적 SQL 쿼리 문자열을 입력으로 가진다. - Query 실행
• 생성된 Statement 객체를 이용하여 입력한 SQL 쿼리를 실행한다. - ResultSet 객체로부터 데이터 조회
• 실행된 SQL 쿼리문에 대한 결과 데이터 셋이다. - ResultSet, Statement, Connection 객체들의 Close
• JDBC API를 통해 사용된 객체들은 생성된 객체들을 사용한 순서의 역순으로 Close 한다.
Spring JDBC : 스프링에서 DB를 사용하기 위한 오리지널 디펜던시, MyBatis처럼 XML을 이용하여 의존성 주입을 한 후,사용하는 방식, java 코드에 직접 SQL 쿼리를 질의하고, 이를 함수화 하여 사용
- Spring JDBC가 하는일
• Connection 열기와 닫기
• Statement 준비와 닫기
• Statement 실행
• ResultSet Loop처리
• Exception 처리와 반환
• Transaction 처리
Spring JDBC에서 개발자가 할 일
핵심적으로 해야될 작업만 해주면 나머지는 Framwork가 알아서 처리해준다.
• datasource 설정
• sql문 작성
• 결과 처리
Sql Mapper(MyBaits),ORM
Sql Mapper
- Sql을 직접 작성해서 직접 DB 조작, Sql문과 객체의 필드를 매핑하여 데이터를 객체화
MyBaits
- 의존성 주입을 XML로 진행하고, JDBC에 사용하는 순수 코드들 역시 모두 자동으로 작성하며, SqlSession을 열고 SQL쿼리를 실행한다. XML에 SQL 쿼리를 질의하고, java코드에서 인터페이스를 만들어,Mapping 하는 형태로 코딩을 진행한다
ORM(Object-Relational Mapper)
- 객체와 RDBMS의 데이터를 자동으로 매핑해주는 것
• 객체(객체지향)와 RDBMS의 데이터(관계지향)를 매핑한다
• RDB의 관계를 객체에 반영
• 객체를 통해서 간접적으로 DB데이터를 다룬다.
• 객체와 DB데이터를 자동으로 매핑해줌.
-> 어떻게? ORM이 객체와 관계 사이에서 SQL을 자동으로 생성해줌.
• 메소드로 DB데이터 조작 = 객체지향
-> OOP의 언어를 그대로 쓰면서 객체와 RDBMS의 데이터를 매핑
(OOP를 OOP답게)
• ex) JPA, Hibernate
JPA,Hibernate
JPA(Java Persistent API)
- 자바 ORM(Object Relational Mapping) 기술에 대한 API 표준 명세를 의미(ORM을 사용하기 위한 인터페이스를 모아둔 것)
- JPA를 사용하기 위해서는 JPA를 구현한 Hibernate, EclipseLink, DataNucleus 같은 ORM 프레임워크를 사용하며 가장 범용적으로 다양한 기능을 제공하는 Hibernate를 가장 많이 사용
- javax.persistence 패키지의 대부분은 interface , enum , Exception, 그리고 Annotation 들로 이루어져 있습니다.
Hibernate
- Hibernate는 JPA의 구현체 중 하나
- Hibernate는 SQL을 사용하지 않고 직관적인 코드(메소드)를 사용해 데이터 조작 가능
- Hibernate가 SQL을 직접 사용하지 않는다고 해서 JDBC API를 사용하지 않는 것은 아님
Hibernate의 장점
- Hibernate는 SQL을 직접 사용하지 않고, 메소드 호출만으로 query가 수행되어 생산성이 높음
- 유지보수 측면에서 좋다.
- 객체지향적으로 데이터를 관리할 수 있기 때문에 비즈니스 로직에 집중할 수 있다.
• 특정 DB 벤더 (MySQL, ORACLE 등 . .)에 종속적이지 않다.
(설정 파일에서 JPA에게 어떤 DB를 사용하고 있는지 알려주기만 하면 얼마든지 DB를 변경할 수 있다.)
Hibernate의 단점
- 많은 내용이 감싸져 있기 때문에 JPA를 잘 사용하기 위해서는 알아야 할 것이 많기에 잘 이해하고 사용하지 않으면 데이터 손실이 있을 수 있다.
- 잘 이해하고 사용하지 않으면 데이터 손실이 있을 수 있다.
- 메소드 호출로 쿼리를 실행하는 것은 내부적으로 많은 동작이 있다는 것을 의미하므로, 직접 SQL을 호출하는것보다 성능이 떨어질 수 있다.
- 메소드 호출로 SQL을 실행하기 때문에 세밀함이 떨어진다
영속성 컨텍스트
- 엔티티를 영구 저장하는 환경이라는 뜻이다. 애플리케이션과 데이터베이스 사이에서 객체를 보관하는 가상의 데이터베이스 같은 역할을 한다. 엔티티 매니저를 통해 엔티티를 저장하거나 조회하면 엔티티 매니저는 영속성 컨텍스트에 엔티티를 보관하고 관리한다.(트랜잭션이 끝나면 DB에 저장)
- 사용하는 이유 : 1차 캐시(조회 기능을 높여줌),동일성 보장,트랜잭션을 지원하는 쓰기 지연
즉시/지연 로딩
지연 로딩(LAZY)
- 연관된 엔티티를 프록시로 조회. 프록시를 실제 사용할 때 초기화하면서 데이터베이스를 조회.(필요한 시점에 연관된 객체의 데이터를 불러오는 것)
즉시 로딩(EAGER)
- 연관된 엔티티를 즉시 조회. 하이버네이트는 가능하면 SQL 조인으로 한번에 조회.( 데이터를 조회할 때, 연관된 모든 객체의 데이터까지한번에 불러오는 것)
JPA에서는 가급적 지연로딩을 권장
프록시(Proxy)
- 대리인이라는 사전적 의미, 내가 어떤 객체를 사용하려고 할 때 해당 객체에 직접 요청하는 것이 아닌 중간에 가짜 프록시 서버(대리인)를 두어서 프록시 객체가 대신해서 요청을 받아 실제 객체를 호출해 주도록 하는 것.

- 프록시 모드를 설정하게 되면, 의존성 주입을 통해 주입되는 빈은 실제 빈이 아닌 해당 빈을 상속받은 가짜 프록시 객체이다.
- 스프링은 CGLIB이라는 바이트 코드를 조작하는 라이브러리를 사용해서 프록시 객체를 주입해준다.
- 프록시 객체 내부에는 실제 빈을 요청하는 로직이 들어있어, 클라이언트의 요청이 오면 그때 실제 빈을 호출해준다.(실제 빈의 조회를 필요한 시점까지 지연 처리)
- 프록시 객체는 원래 빈을 상속받아서 만들어지기 때문에 클라이언트 입장에서는 실제 빈을 사용하는 것과 똑같은 방법으로 사용하면 된다.
- @Scope 애노테이션의 proxyMode 옵션을 사용하여 설정할 수 있다.
연관관계
고아객체
- 부모 엔티티와 연관관계가 끝어진 자식 엔티티로 orphanRemoval 옵션을 통해서 고아객체를 자동으로 삭제하는 기능을 제공함
단방향 매핑
- JPA에서 단방향 매핑은 JoinColumn과 One(Many) ToOne(Many)를 통해 할 수 있다.
양방향 매핑
- 양방향 매핑은 Team Class에 Member를 추가하고 mappedBy를 통해 맺을 수 있다.
- 사실 연관관계는 단방향 매핑으로 다 맺어진것이다.
- 단지 객체 그래프 탐색을 위해 설정을 하는 것이다.
단방향 매핑만으로도 이미 연관관계는 맺어진다.
양방향 매핑은 반대 반향으로 조회(객체 그래프 탐색) 기능이 추가된 거뿐이다.
연관관계의 주인은 가능한 한 외래 키 기준으로 정하자
N+1 문제
- 연관 관계에서 발생하는 이슈로 연관 관계가 설정된 엔티티를 조회할 경우에 조회된 데이터 갯수(n) 만큼 연관관계의 조회 쿼리가 추가로 발생하여 데이터를 읽어오게 되는 문제
발생이유
- N+1 문제가 발생하는 이유는 JPA가 JPQL을 분석해서 SQL을 생성할 때는 글로벌 Fetch 전략을 참고하지 않고 오직 JPQL 자체만을 사용하기 때문
- 해결 방법 : Fetch Join ,EntityGraph 어노테이션 , Batch Size,QueryBuilder 등의 방법이 있다.

기록 블로그