Elastichsearch plugin
형태소 분석 사용을 위한 플러그인 제작(jar)
eleasticsearch version 7.5.0
lucene version 8.3.0
(버전에 따라 플러그인 구조 상이함)
Lucene Analyzer 동작
Lucene은 자바 정보검색 라이브러리
하나의 tokenizer와 다수의 filter로 구성이 되며, Filter 는 CharFilter와 TokenFilter 두 가지형태. CharFilter는 입력된 문자열에서 불필요한 문자를 normalization 하기 위해 사용되며 TokenFilter는 tokenizer에 의해 분해된 token에 대한 filter 처리.
lucene에서 제공하는 analyzer의 기본 구성과 동작
Ref: https://www.elastic.co/kr/blog/arirang-analyzer-with-elasticsearch
Plugin project 구조
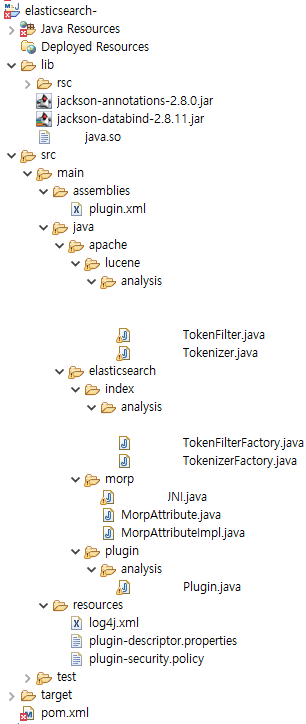
Plugin 형태 생성
Tokenizer(my_tokenizer), Token Filter(my_filter) 명칭 정의(override)
MyPlugin.java
public class MyPlugin extends Plugin implements AnalysisPlugin {
public static MyJNI myJNI = null;
public static long myJNILm = 0;
Logger logger = Loggers.getLogger(MyPlugin.class, "MyPlugin");
//so형태의 형태소 분석기를 갖고오기 위해 사용
public MyPlugin() {
this.myJNI = new MyJNI();
this.myJNILm = this.myJNI.initLm();
}
//형태소분석 플러그인api
@Override
public Map<String, AnalysisProvider<TokenizerFactory>> getTokenizers() {
Map<String, AnalysisProvider<TokenizerFactory>> tokenizerFactories = new HashMap<>();
tokenizerFactories.put("my_tokenizer", MyTokenizerFactory::new);
return tokenizerFactories;
}
//필터 플러그인 api
@Override
public Map<String, AnalysisProvider<TokenFilterFactory>> getTokenFilters() {
return singletonMap("my_filter", MyTokenFilterFactory::new);
}
}Tokenizer 생성
MyTokenizerFactory.java
public class MyTokenizerFactory extends AbstractTokenizerFactory {
public MyTokenizerFactory(IndexSettings indexSettings, Environment env, String name, Settings settings) {
super(indexSettings, settings, name);
}
@Override
public Tokenizer create() {
return new MyTokenizer();
}
}@Override
incrementToken() input형태로 질의가 들어옴
리턴 값이 True면 재호출. (형태소분석기를 통해 질의를 나눔)
analysis 시 결과 값 타입
termAttribute, morpAttribute(사용자정의), offsetAttribute, typeAttribute

MyTokenizer.java
public class MyTokenizer extends Tokenizer{
private CharTermAttribute termAttribute = addAttribute(CharTermAttribute.class);
private TypeAttribute typeAttribute = addAttribute(TypeAttribute.class);
private OffsetAttribute offsetAttribute = addAttribute(OffsetAttribute.class);
private MorpAttribute morpAttribute = addAttribute(MorpAttribute.class);
Logger logger = Loggers.getLogger(MyTokenizer.class, "MyTokenizer");
private int start = 0;
private Iterator<Map> iterator;
String globaltextString;
@Override
public final boolean incrementToken() throws IOException {
clearAttributes();
if (iterator == null) {
String textString;
textString = readerToString(input);
globaltextString = textString;
if (Strings.isNullOrEmpty(textString)) {
logger.error("isNullOrEmpty call ");
return false;
}
List<Map> wordMorp = new ArrayList<>();
try {
String morp = MyPlugin.myJNI.doLang(MyPlugin.myJNILm, textString);
ObjectMapper mapper = new ObjectMapper();
Map<String, Object> map = mapper.readValue(morp, new TypeReference<Map<String, Object>>(){});
List<Map> sentenceList = (List<Map>) map.get("sentence");
Map<String, Object > sentenceMap = sentenceList.get(0);
List<Map> morpList = (List<Map>) sentenceMap.get("morp");
for(int i = 0; i < morpList.size(); i++){
Map<String, Object > morpMap = morpList.get(i);
wordMorp.add(morpMap);
}
} catch (IOException e) {
logger.error("mapper error: " + e);
}
iterator = wordMorp.iterator();
}
if (!iterator.hasNext()) {
return false;
}
Map<String, Object > morpMap = iterator.next();
int length = morpMap.get("lemma").toString().length();
while( globaltextString.charAt(0) == ' ' )
{
globaltextString = globaltextString.substring(1);
start += 1;
}
if( globaltextString.length() > length)
globaltextString = globaltextString.substring(length);
termAttribute.append(morpMap.get("lemma").toString());
morpAttribute.setMorpType(morpMap.get("type").toString());
offsetAttribute.setOffset(correctOffset(start), correctOffset(start+length));
typeAttribute.setType("word");
start = start+length;
iterator.remove();
return true;
}
@Override
public final void end() throws IOException {
super.end();
offsetAttribute.setOffset(start, start);
}
@Override
public final void reset() throws IOException {
super.reset();
globaltextString = "";
start = 0;
iterator = null;
}
private String readerToString(Reader reader) throws IOException {
char[] arr = new char[8 * 1024];
StringBuilder buffer = new StringBuilder();
int numCharsRead;
while ((numCharsRead = reader.read(arr, 0, arr.length)) != -1) {
buffer.append(arr, 0, numCharsRead);
}
return buffer.toString();
}Filter 생성
MyTokenFilterFactory.java
public class MyTokenFilterFactory extends AbstractTokenFilterFactory {
public MyTokenFilterFactory(IndexSettings indexSettings, Environment env, String name, Settings settings) {
super(indexSettings, name, settings);
}
@Override
public TokenStream create(TokenStream tokenStream) {
return new MyTokenFilter(tokenStream);
}
}@Override
incrementToken()에 input.incrementToken 값에 MyTokenizer를 통한 토큰값들이 넘어옴
리턴값이 Flase면 필터링
ExobrainTokenFilter.java
public class MyTokenFilter extends TokenFilter{
private CharTermAttribute termAttribute = addAttribute(CharTermAttribute.class);
private MorpAttribute morpAttribute = addAttribute(MorpAttribute.class);
private PositionIncrementAttribute posIncrAttribute = addAttribute(PositionIncrementAttribute.class);
private boolean ENABLE_POSITION_INCREMENTS_DEFAULT = false;
private boolean enablePositionIncrements = ENABLE_POSITION_INCREMENTS_DEFAULT;
Logger logger = Loggers.getLogger(MyTokenFilter.class, "MyTokenFilter");
private String[][] morpTypeList = { {"JKS", "주격조사"},
{"JKC", "보격조사"},
{"JKG", "관형격조사"},
{"JKO", "목적격조사"},
{"JKB", "부사격조사"},
{"JKV", "호격조사"},
{"JKQ", "인용격조사"},
{"JX", "보조사"},
{"JC", "접속조사"},
{"SF", "마침표, 물음표, 느낌표"},
{"SP", "쉼표, 가운뎃점, 콜론, 빗금"},
{"SS", "따옴표, 괄호표, 줄표"},
{"SE", "줄임표"},
{"SO", "줄임표(물결)"},
{"NA", "분석불능범주"}
};
Map<String, Integer> morpHashException = new HashMap<String, Integer>();
public MyTokenFilter(TokenStream input) {
super(input);
for(int i = 0; i<morpTypeList.length; i++) {
morpHashException.put(morpTypeList[i][0], 1);
}
}
@Override
public boolean incrementToken() throws IOException {
while(input.incrementToken()) {
if( morpHashException.get(morpAttribute.morpType()) == null )
return true;
// 위치 정보기반으로 필요할때 사용
// posIncrAtt.setPositionIncrement(posIncrAtt.getPositionIncrement() + skippedPositions);
// skippedPositions += posIncrAtt.getPositionIncrement();
}
return false;
}
}