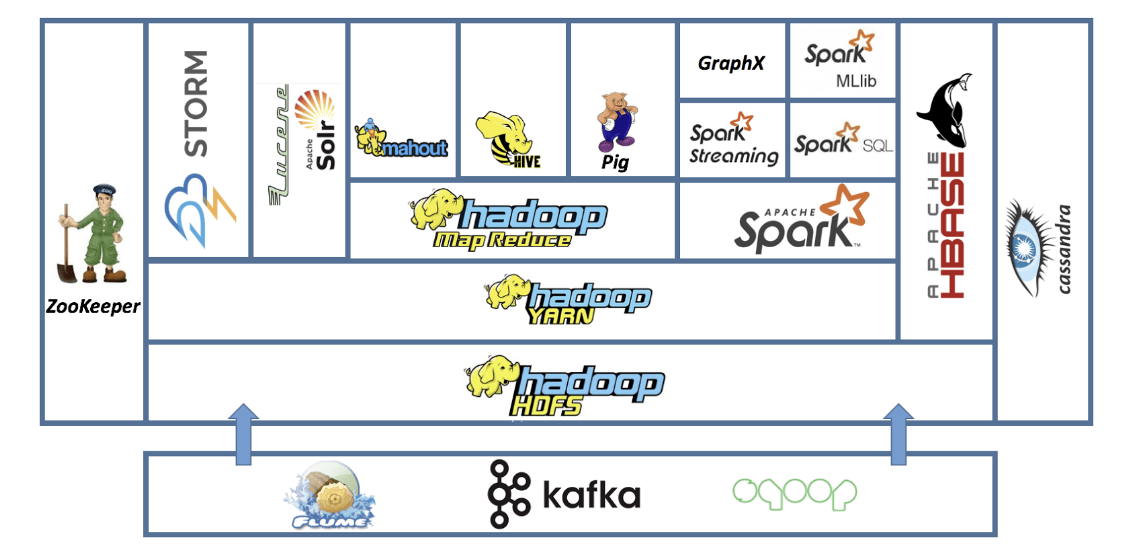
HDFS
- Hadoop 분산 파일 시스템
- 빅데이터를 클러스터의 컴퓨터들에 분산 저장하는 시스템.
- 데이터의 여분 복사본까지 만들어 데이터의 손실을 자동을 회복함.
- Hadoop의 데이터 저장 부분.
YARN
- 'Yet Another Resource Negotiator'의 약어이며 '또 다른 리소스 교섭자'라는 뜻.
- YARN은 Hadoop의 데이터 처리 부분.
- 컴퓨터 클러스터의 리소스를 관리하는 시스템.
- 누가 작업을 언제 실행하고 어떤 노드가 추가 작업을 할 수 있고 누구는 할 수 없고 등을 결정.
MapReduce
- 데이터를 클러스터 전체에 걸쳐 처리하도록 하는 프로그래밍 모델.
- Mapper와 Reducer로 구성되어 있어 프로그램을 사용할 때 사용하는 두 개의 구분된 함수
- Mapper는 클러스터에 분산돼있는 데이터를 효율적으로 동시에 변경할 수 있음.
Pig
- Pig는 고수준의 API'로써 많은 경우 SQL과 비슷한 간단한 스크립트를 작성해 쿼리를 연결하고 복잡한 답을 구할 수 있다.
- 프로그래밍 언어를 사용하지 않아도 사용 가능.
- Pig는 작성된 스크립트를 MapReduce가 읽을 수 있도록 번역하고 MapReduce는 다시 YARN과 HDFS에게 데이터를 처리하고 원하는 답을 가져오게한다.
- Pig는 MapReduce위에 있는 고수준 스크립팅 언어.
Hive
- MapReduce위에 구축돼 Pig처럼 작동하지만 더 SQL 데이터베이스 역할을 수행함.
- 셸 클라이언트나 ODBC(Open Database Connectivity) 등을 통해 데이터베이스에 접속할 수 있으며 Hadoop 클러스터에 저장돼있는 데이터가 내부적으로는 관계형 데이터베이스가 아님에도 불구하고 SQL로 쿼리한다
