Spring Batch size INSERT 적용법
Batch size INSERT 적용법에 대해 알아보겠습니다.
Batch Size란?
Batch size는 JPA가 다수의 INSERT, UPDATE, DELETE 작업을 처리할 때 SQL 실행을 모아서 일괄 실행(batch execution) 하는 단위를 뜻합니다.
예를 들어 도서 관리 시스템에서 도서별 평점 평균을 기반으로 순위를 집계하여 통계(Statistics)테이블에 저장하는 로직이 있다면, 통계 테이블에 저장하는 과정에서 엔티티별로 Insert 쿼리가 실행됩니다.
즉 100개 도서의 평점 평균을 집계하여 통계 테이블에 저장하게 되면, 100개의 Insert 쿼리가 실행됩니다.
이 때 Batch size를 50으로 설정해주면, Insert쿼리를 50개씩 묶어서 2번 실행하여 성능을 최적화합니다.
사용 시 주의사항
우선 Batch size는 엔티티(Entity)의 PK 생성전략이 IDENTITY일 경우 사용할 수 없습니다.
그 이유는 아래 블로그를 참조하여 설명하겠습니다.
IDNETITY전략은, DB에 데이터가 저장될 때 ID값을 AUTO INCREMENT하여 값을 자동으로 1씩 증가시켜 저장해줍니다.
그러나 Batch Size INSERT는 쿼리를 묶어서 처리하기 때문에 값이 저장될 때 ID값을 할당하는 IDENTITY전략과는 맞지 않습니다. 예를들어 10개의 쿼리를 묶어서 처리하려면, 묶어둔 10개의 데이터에 각각 PK를 지정해주어야하는데, IDENTITY전략의 경우 데이터가 저장될 때 PK값을 할당하므로 동작하지 않습니다.

@GeneratedValue의 generator값은 @SequenceGenerator의 name과 일치해야합니다.
- seuqenceName : DB 내의 실제 시퀀스 이름을 뜻합니다.
- allocationSize : 한 번에 가져올 ID의 수를 설정합니다. 기본값은 50이나, 예시를위해 임시로 100으로 설정하였습니다.
Batch Size 사용 방법
우선 하이버네이트 배치 설정을 해주어야 합니다.
application.yml 파일에 jpa.properties.hibernate.jdbc.batch_size 설정을 적용합니다.
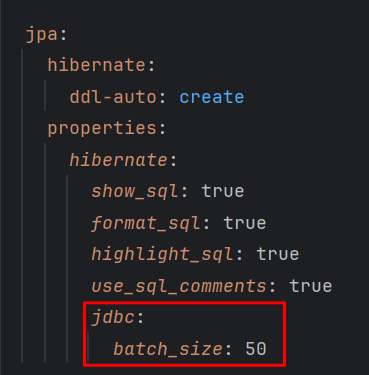
반드시 properties.hibernate에 적용해야 합니다.
saveAll메서드로 한 번에 저장하기 위해 리스트를 만들고, 리스트에 값을 담아준 뒤 saveAll메서드를 실행합니다.
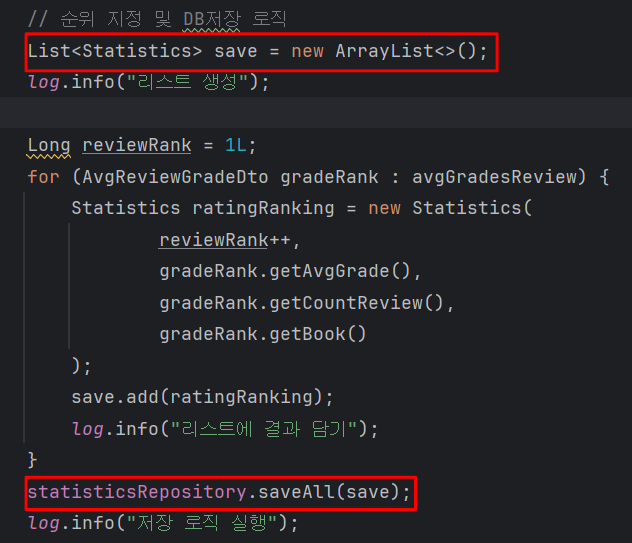
콘솔에 출력된 로그를 보겠습니다.
여전히 쿼리가 개별적으로 나가는것으로 확인됩니다.
관련 정보를 찾던 중
참고 블로그
MySQL JDBC의 경우 JDBC URL에 rewriteBatchedStatements=true 옵션을 추가해주면 된다. 는 내용을 보아 .env파일에 추가 해주었습니다.

다시 실행해보겠습니다.
여전히 개별 처리되는것을 볼 수 있습니다.
다시 블로그 내용을 보니
MySQL의 경우 실제로 생성된 쿼리는 logger=com.mysql.jdbc.log.Slf4JLogger&profileSQL=true 옵션으로 로그를 통해 확인할 수 있다.는 내용을 확인해 .env 파일의 DB_URL에 &profileSQL=true&logger=Slf4JLogger를 추가해준 후 다시 실행시켰습니다.
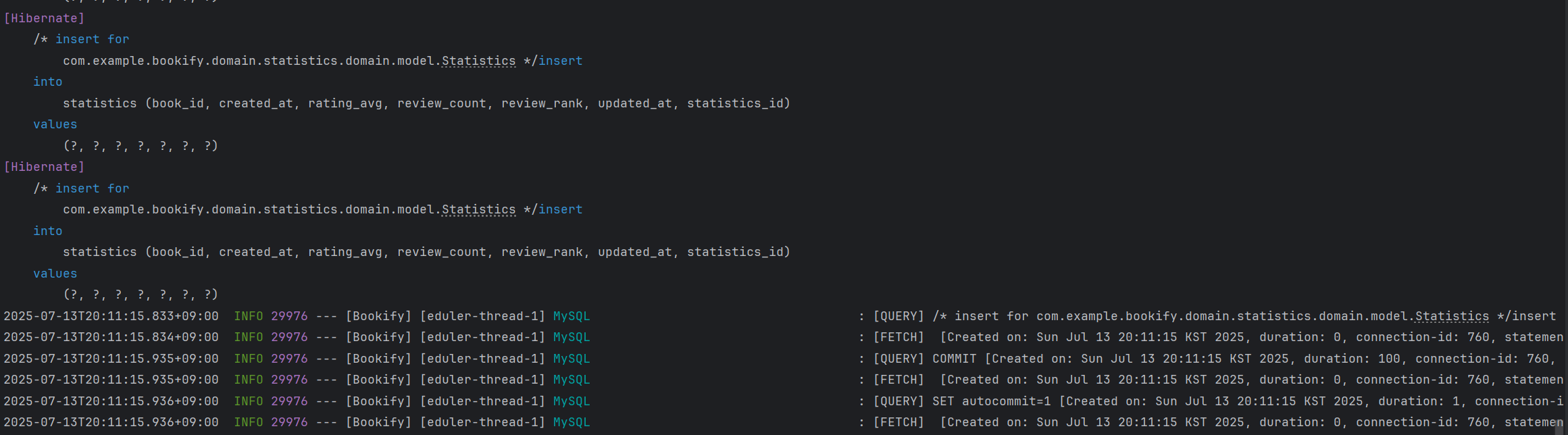
여전히 콘솔에서는 개별 처리된 것으로 보이지만 아래 새로 찍힌 로그를 자세히 살펴보겠습니다.

: [QUERY] /* insert for com.example.bookify.domain.statistics.domain.model.Statistics */insert into statistics (book_id,created_at,rating_avg,review_count,review_rank,updated_at,statistics_id) values (1,'2025-07-13 20:11:15.800214',5.0,3,1,'2025-07-13 20:11:15.800214',402),(2,'2025-07-13 20:11:15.809448',5.0,3,2,'2025-07-13 20:11:15.809448',403),(7,'2025-07-13 20:11:15.809448',5.0,2,3,'2025-07-13 20:11:15.809448',404),(8,'2025-07-13 20:11:15.810449',5.0,2,4,'2025-07-13 20:11:15.810449',405),(3,'2025-07-13 20:11:15.810449',4.0,3,5,'2025-07-13 20:11:15.810449',406),(9,'2025-07-13 20:11:15.810449',4.0,2,6,'2025-07-13 20:11:15.810449',407),(10,'2025-07-13 20:11:15.810775',3.0,2,7,'2025-07-13 20:11:15.810775',408),(4,'2025-07-13 20:11:15.810775',2.5,6,8,'2025-07-13 20:11:15.810775',409),(6,'2025-07-13 20:11:15.810775',2.3333,3,9,'2025-07-13 20:11:15.810775',410),(5,'2025-07-13 20:11:15.811279',1.0,3,10,'2025-07-13 20:11:15.811279',411) [Created on: Sun Jul 13 20:11:15 KST 2025, duration: 0, connection-id: 760, statement-id: 0, resultset-id: 0, at com.zaxxer.hikari.pool.ProxyStatement.executeBatch(ProxyStatement.java:128)]위 내용을 요약하면 다음과 같습니다.
: [QUERY] */insert into statistics (각 컬럼) values (1),(2),(7),(8,),(3,),(9,),(10,),(4,),(6,),(5,) [Created on: Sun Jul 13 20:11:15 KST 2025, duration: 0, connection-id: 760, statement-id: 0, resultset-id: 0, at com.zaxxer.hikari.pool.ProxyStatement.executeBatch(ProxyStatement.java:128)]즉 배치 처리가 성공적으로 처리되었지만 하이버네이트는 배치처리 여부와 관계없이 무조건 콘솔에 쿼리를 엔티티마다 한건 씩 처리한다는 사실을 알 수 있습니다.
사용법 정리
-
PK생성 전략이IDENTITY가 아닐 것 -
application.yml파일에jpa.properties.hibernate.jdbc.batch_size설정을 적용할 것 -
DB저장 시saveAll메서드를 사용할 것 -
JDBC URL에rewriteBatchedStatements=true옵션을 추가해줄 것
위 4가지 조건을 만족할 경우 Batch Size 적용이 완료됩니다.
