
프론트엔드에서 코딩을 하다보면 "검색엔진을 최적화해야 한다" 라는 말을 자주 보고 듣게 됩니다. 검색엔진을 최적화해야 한다는 것이 무슨 소리일까요?
SEO, 그게 뭔데 🫤

검색엔진 최적화(SEO)는 Search Engine Optimization의 약어로, 검색엔진이 이해하기 쉽도록 홈페이지의 구조와 페이지를 개발해 검색 결과 상위에 노출될 수 있도록 하는 작업을 말합니다.
기본적인 작업 방식은 특정 검색어를 웹 페이지에 적절하게 배치하고 다른 웹 페이지에서 링크가 많이 연결되도록 하는 것입니다.
SEO, 왜 해야 할까 🤔
사용자가 구글, 네이버와 같은 검색 포털 사이트에서 특정 키워드를 검색하면 해당 키워드와 관련된 검색 결과가 출력됩니다.
이때, 검색 결과의 최상단에 "우리" 사이트를 위치하게 만드는 게 SEO를 하는 이유입니다. 검색 결과의 목록에서 후순위에 위치할수록 노출 효과는 급격히 떨어지게 되기 때문입니다.
결국 어떤 비즈니스 유형이든 SEO는 가장 중요한 마케팅 유형 중 하나일 수 밖에 없습니다. 검색 포털 사이트는 검색하는 사람들에게 긍정적인 사용자 경험(UX)을 선사하는 것이 목표이기 때문에 가능한 한 최고의 정보를 제공하길 원하기 때문입니다. 따라서, 검색 엔진 최적화를 위한 노력은 검색 엔진이 사이트의 콘텐츠를 특정 검색어에 대한 웹 상의 주요한 정보로 인식하도록 하는 과정에 포커스를 맞추어야 합니다.
SEO, 동작 원리부터 🧐

사용자가 검색어를 입력하고 검색 결과를 확인하기까지 크게 아래와 같은 프로세스를 거치게 됩니다. SEO 과정이나 단계에 대해 검색을 해보면 적게는 4단계, 많게는 7단계까지 상세히 나눠져 있습니다. 그리고 내용도 조금씩 상이합니다.
키워드로 나눠보자면 세 단계로 압축해볼 수 있을 것 같습니다.
① 크롤링 (Crawling)
웹 크롤러가 웹페이지의 콘텐츠를 복사해서 모든 정보를 수집하고 수집한 정보를 검색엔진으로 가져오는 단계
② 인덱싱 (Indexing)
웹 크롤러가 검색엔진으로 가져온 정보를 주제별로 색인(index)해서 데이터를 보관하는 단계
③ 랭킹 (Ranking)
색인된 콘텐츠를 검색 의도에 맞춰서 순위를 부여
사용자가 해당 키워드로 검색했을 때 랭킹 순서대로 결과를 제공하는 단계
웹 크롤러
위에서 언급된 웹 크롤러는 월드 와이드 웹에서 정보를 수집하는 컴퓨터 프로그램입니다. 검색 키워드와 검색 맥락을 파악하는 것부터 사이트를 상위로 노출하는 것까지 전부 웹 사이트의 크롤러 봇이 관여하게 됩니다.
① 웹페이지가 어떤 콘텐츠를 가지고 있는지
② 해당 페이지가 무엇에 대한 것인지
검색 엔진은 위 두 가지를 판단하기 위해 웹페이지를 크롤링하는 로봇인 웹 크롤러를 사용합니다. 웹 크롤러는 코드를 스캔하여 웹페이지에 표시되는 텍스트, 이미지, 동영상을 등을 수집하여 가능한 모든 정보를 얻습니다.
웹 크롤러가 각 페이지에서 사용할 수 있는 정보 유형에 대한 충분한 정보를 수집하여 해당 내용이 검색자에게 유용하다고 판단하면 해당 페이지를 색인(index)에 추가합니다. 여기서 말하는 색인은 본질적으로 검색 엔진이 잠재적인 검색자에게 제공하기 위해 저장한 모든 가능성 있는 웹 결과입니다.
SEO, 어떻게 설정해? 😣
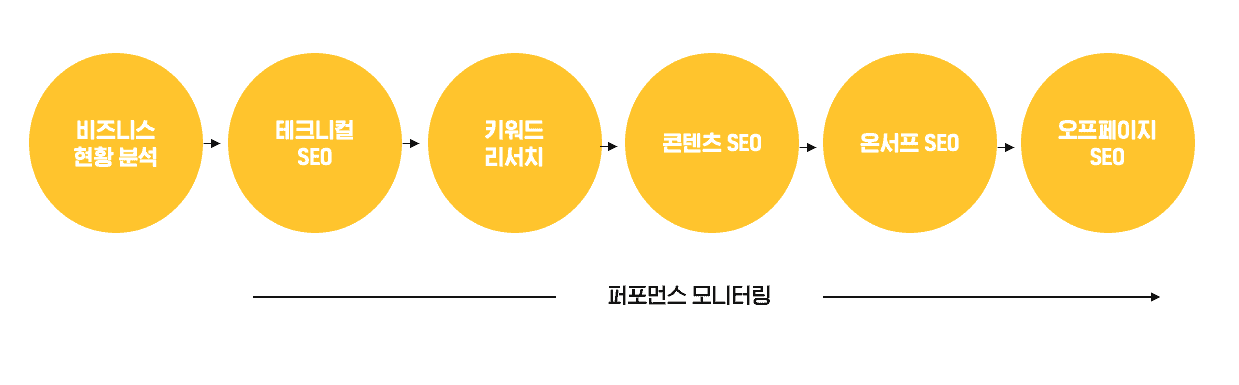
검색엔진 최적화 작업은 사실상 비즈니스 현황을 이해하는 것에서부터 시작합니다.
자사의 사업 분야와 관련 경쟁사에 대한 리서치를 통해 타깃 기장을 분석하고, 자사 웹사이트 퍼포먼스 진단을 통해 검색엔진 최적화 마케팅 전략을 수립하는 등 모든 단계를 포함합니다.
어떤 부분이 검색 엔진의 순위에 가장 큰 영향을 미치는지에 대해서는 정확히 알 방법이 없기 때문에 SEO 전략에는 다양한 전술을 포함하는 것이 유리합니다. 이러한 전술은 크게 On-page SEO와 Off-page SEO라는 두 가지 범주로 나눌 수 있습니다.
On-page? Off-page?
On-page SEO는 디자인 및 작성한 콘텐츠에서부터 메타데이터, 대체 텍스트 등에 이르기까지 웹페이지 자체에 구현하는 전략을 말합니다.
Off-page SEO는 페이지의 외부에서 수행하는 단계를 말합니다. 여기에는 외부 링크, SNS 게시물, 다른 웹사이트 프로모션 방식 등이 포함됩니다.
On-page SEO 및 Off-page SEO 모두 내 사이트로 트래픽을 유도하고, 궁극적으로 내 사이트가 인터넷에서 중요한 참가자라는 신호를 Google에 보내기 위해 필수적입니다. 내 페이지들이 중요하고, 사람들이 내가 제공하는 것들을 아는 것에 관심이 있다는 것을 검색엔진에게 알림으로써 내 페이지가 상위에 노출되고, 더 많은 트래픽을 유도하도록 만들 수 있습니다.
해당 포스팅에서는 프론트엔드 개발자가 관여할 부분인 테크니컬 SEO와 관련된 내용을 위주로 다룰 예정입니다.
technical SEO
테크니컬 SEO를 기점으로 본격적인 검색엔진 최적화 작업에 들어가게 됩니다.
구글이 발표한 랭킹 요소는 2021년 기준으로 200여 가지가 넘습니다. 하지만 랭킹 요소 200가지를 모두 동일하게 중요시할 필요는 없기 때문에 가장 중요한 요소를 우선적으로 적용하여 웹사이트를 최적화하는 것만으로도 웹사이트 퍼포먼스를 충분히 개선할 수 있습니다.
아래는 가장 기본적으로 적용해야 할 테크니컬 SEO 작업이기 때문에 신경을 써주는 것이 좋습니다.
🔒 HTTPS
2014년 구글은 공식적으로 보안은 구글의 최우선 순위이며, 사용자가 구글을 통해 접속하는 모든 웹사이트가 안전할 수 있도록 보안 프로토콜을 랭킹 요소로 지정하여 보안 프로토콜을 적용한 웹사이트에게 적용하지 않은 웹사이트(HTTP)보다 더 높은 점수를 부여할 것이라고 발표했습니다.
따라서 모든 웹사이트에 보안 프로토콜 (HTTPS) 적용을 강력히 권고하지만, 특히나 웹사이트 상에서 금전적 거래가 이루어지는 웹사이트 혹은 사용자의 개인 정보를 수집하는 웹사이트의 경우는 필수적으로 적용해야 합니다.
보안 프로토콜을 적용하는 데는 여러 가지 방법이 있습니다.
그 중에서 클라우드 플레어 (CloudFlare)라는 웹사이트에서 무료로 HTTPS를 손쉽게 적용할 수도 있기 때문에 보안 프로토콜 적용 비용이 부담스러운 회사나 개인의 경우에는 이 방법을 이용하면 될 것 같습니다. 🙂
🗺️ Sitemap
웹사이트를 등록했다면 Sitemap을 제출해야 합니다.
Sitemap(사이트맵)
웹사이트를 구성하는 개별 페이지의 목록을 담은 xml 파일
검색 포탈에게 웹사이트의 존재를 알렸다면 이제 웹 크롤러가 웹사이트를 구성하는 개별 페이지를 모두 확인해 정보를 수집하게 됩니다. 웹 크롤러는 특정 페이지에서 다른 페이지로 연결된 하이퍼 링크를 따라가며 각 페이지의 정보를 파악합니다. 이때 페이지 사이의 연결이 잘 안 됐다면, 웹 크롤러가 개별 페이지를 읽는 과정에서 어려움을 겪게 됩니다.
이러한 문제를 해결하기 위해 사이트맵이 존재합니다. 사이트 맵은 웹사이트가 어떻게 구성됐는지 웹 크롤러에게 미리 알려줌으로써, 개별 페이지의 탐색을 잘 할 수 있도록 도와주는 (이름에서도 알 수 있지만) 일종의 지도 역할을 하는 겁니다.
🗺️ react-router-sitemap
① install → npm i --save react-router-sitemap
② sitemapRoutes.js 파일 생성
기존에 라우트를 관리하는 컴포넌트 파일이 존재한다면 해당 파일로 react-router-sitemap을 실행했을 때 Babel 이슈가 발생하기 때문에 새롭게 작성해주는 것이 좋습니다.
react-router의 버전에 따라 4 이전이라면 Route를, 4 이후라면 Switch를 사용하면 됩니다.
// sitemapRoutes.js
import React from 'react';
import { Switch } from 'react-router';
export default (
<Switch>
<Route path='/' />
<Route path='/about' />
</Switch>
);③ sitemapGenerator.js 파일 생성
sitemapGenerator는 sitemap 파일을 생성하는 파일입니다.
require("@babel/register")({
presets: ["@babel/preset-env", "@babel/preset-react"]
});
const router = require("./sitemapRoutes").default; // sitemapRoutes 파일의 경로
const Sitemap = require("react-router-sitemap").default;
function generateSitemap() {
return (
new Sitemap(router)
.build("https://www.yourDomainName.com") // 도메인 이름
.save("./public/sitemap.xml") // sitemap.xml 파일이 생성될 위치
);
}
generateSitemap();④ 위 파일을 실행하기 전 아래 dev dependecy들을 설치해주세요.
npm install --save-dev @babel/register @babel/preset-env @babel/preset-react⑤ package.json 파일에 sitemaGenerator 파일의 경로 추가
// package.json
// ... 코드 생략
"scripts": {
// ... 코드 생략
"sitemap": "babel-node ./sitemaGenerator.js"
} 이제 npm run sitemap 명령어로 sitemap을 실행하게 되면 public 디렉토리 안에 sitemap.xml 파일이 생성된 것을 확인할 수 있게 됩니다.
🤖 robots.txt
robots.txt를 로봇 배제 표준 파일이라고 하며 React 프로젝트 생성 시 기본적으로 제공되는 파일 중 하나이기도 합니다. 로봇 배제 표준 파일은 웹 크롤러의 접근을 차단 및 허용과 관련된 내용을 작성하는 용도로 사용됩니다. 구글이나 네이버를 포함한 모든 검색엔진 로봇에게 공통된 명령을 내릴 수도 있고 각 검색엔진 로봇별로 다른 명령을 내릴 수도 있습니다.
예를 들어, 웹사이트의 모든 페이지를 모든 검색엔진 크롤러에게 색인 허용하고 싶다면 아래와 같이 로봇 배제 표준 파일을 작성하면 됩니다.
User-agent: *
Allow: /여기서 User-agent는 웹 크롤러를 의미하며, * (별표) 입력 시 모든 크롤러에게 명령을 내린다는 뜻입니다.
📋 MataData
메타데이터는 내 웹페이지에 포함된 내용을 설명하기 위해 Google에 제공하는 정보를 말합니다. 메타데이터의 중요한 측면에는 메타 설명과 타이틀 태그가 포함됩니다.
웹 크롤러에게는 또한 각 페이지 안에서 중요한 정보와 그렇지 않은 정보를 알려줄 필요가 있습니다. 중요도가 높은 정보를 강조할수록 웹 크롤러가 해당 페이지가 어떤 정보를 담고 있는지 쉽게 파악할 수 있기 때문입니다.
페이지의 정보 중요도를 알려주는 방식은 크게 두 가지로 나눌 수 있습니다.
① Mata Tag 삽입
② 태그의 위계질서 설정
메타 태그는 HTML 문서 안에 삽입되어 있으며 이 태그들은 해당 문서의 메타데이터, 즉 데이터에 대한 정보를 제공합니다. 이 정보는 주로 브라우저나 검색 엔진 등이 사용하며 웹 페이지의 제목, 설명, 작성자, 문자 인코딩 등을 포함할 수 있습니다.
메타 태그를 사용하면 사용자에게 웹 페이지의 내용과 관련된 보조 정보를 제공하거나, 검색 엔진이 웹 페이지를 색인할 때 도움이 됩니다. 또한 페이지의 핵심적인 내용이 무엇이지 크롤러 봇에게 바로 알려줄 수 있습니다.
대표적인 메타 태그로는 <title>, <meta charset>, <meta name="description">, <meta name="keywords"> 등이 있습니다.
🔖 OG tag
OG(Open Graph) 태그도 SEO에 빼놓을 수 없는 부분입니다.
오픈 그래프 태그는 웹 페이지의 링크가 카카오톡이나 다른 SNS에서 공유될 때 어떻게 노출될지를 정의할 수 있게 도와줍니다.
단순히 SNS를 통한 공유에 효과적일 뿐만 아니라 검색엔진 최적화 과정에서 해당 웹페이지가 SNS에서 얼마나 공유되고 있는지 판단하는 기준이 될 수도 있기 때문에 검색 상위 노출을 위한 품질 평가에도 영향을 줍니다.
og:title→ 웹페이지 제목og:description→ 웹페이지 상세 설명og:image→ 웹페이지 카드에 나타나는 썸네일 이미지 (1200*630)og:type→ 웹페이지 유형og:url→ 웹페이지 주소
위 공유된 링크에서 보일 내용들에 대한 정보는 아래와 같습니다.
import type { Metadata } from "next";
export const metadata: Metadata = {
title: "Juyeon OH",
description: "juyeon OH's portfolio",
};metadata 안의 title이 og:title, description이 og:description과 같습니다. 그리고 썸네일 이미지에 대한 내용이 없음에도 og:image가 보여지고 있는 것을 확인할 수 있습니다.
이는 NextJS가 자체적으로 페이지를 렌더링할 때 미리보기 이미지를 생성하여 반환하는 기능을 제공하고 있기 때문입니다. 그래서 페이지를 공유했을 때 공유된 페이지에 Open Graph 태그가 없거나 이미지가 명시적으로 설정되지 않았더라도 기본 이미지가 생성되어 나타나게 됩니다.
만약 react로 만든 프로젝트라면 기본적으로 제공되는 index.html 파일 내에서 관련 코드를 작성해 추가할 수 있습니다.
아래는 제가 진행했던 다른 토이 프로젝트 중 하나인 postMobism의 index 파일입니다.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<link rel="icon" type="image/svg+xml" href="/favicon.svg" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<link rel="preconnect" href="https://fonts.googleapis.com">
<link rel="preconnect" href="https://fonts.gstatic.com" crossorigin>
<link href="https://fonts.googleapis.com/css2?family=Roboto+Condensed:ital,wght@0,100..900;1,100..900&display=swap" rel="stylesheet">
<title>post-mobism</title>
</head>
<body>
<div id="root"></div>
<script type="module" src="/src/main.tsx"></script>
</body>
</html>
이렇게 오픈 그래프와 관련된 내용이 없다면 링크를 공유하게 되었을 때 페이지에 대한 정보가 나타나지 않게 됩니다.
오픈 그래프 태그는 아래와 같이 추가하면 됩니다.
<!DOCTYPE html>
<html lang="en">
<head>
<!-- 🔖 Open Graph Meta Tags -->
<meta property="og:title" content="post-mobism" />
<meta property="og:description" content="post your code and get reviews" />
<meta property="og:type" content="website" />
<meta charset="UTF-8" />
<link rel="icon" type="image/svg+xml" href="/favicon.svg" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<link rel="preconnect" href="https://fonts.googleapis.com">
<link rel="preconnect" href="https://fonts.gstatic.com" crossorigin>
<link href="https://fonts.googleapis.com/css2?family=Roboto+Condensed:ital,wght@0,100..900;1,100..900&display=swap" rel="stylesheet">
<title>post-mobism</title>
</head>
<body>
<div id="root"></div>
<script type="module" src="/src/main.tsx"></script>
</body>
</html>NextJS와는 달리 React로 프로젝트를 만들 경우 SEO에 신경을 더욱 쓸 수 밖에 없습니다. NextJS가 기본적으로 제공해주는 기능들을 React에서는 직접 구현해야 하기 때문이죠.
React는 SPA이기 때문에 웹 크롤러가 리액트로 제작된 웹사이트에 대한 정보를public/index.html, 단 하나의 파일에서만 얻을 수 있습니다. 이는 각각의 페이지에 대한 정보를 읽지 못한다는 단점으로 이어지게 되죠.
React에서도 NextJS처럼 페이지마다 메타태그를 별도로 지정하고 싶다면 react-helmet-async 라이브러리를 사용하면 됩니다.
⛑️ react-helmet-async
이러한 라이브러리를 사용하는 이유는 React가 NextJS처럼 SSR이 아닌 SPA이기 때문입니다. SPA는 head 태그 내부는 수정할 수 없기 때문에 이와 같은 라이브러리를 사용할 수 밖에 없는 것이죠.
검색을 하다보면 react-helmet이라는 라이브러리도 있고 react-helmet-async라는 라이브러리도 있습니다.
react-helmet은 react-side-effect에 의존하기 때문에 thread-safe하지 않습니다. 따라서, 비동기 데이터 처리에 문제가 생길 우려가 있습니다.
react-helmet-async는 react-helmet의 단점을 보완해주는 라이브러리이므로 꼭 async를 사용해줘야 합니다.
thread-safe
여러 스레드로부터 동시에 접근이 이루어져도 프로그램의 실행에 문제가 없음
react-helmet-async의 적용 방법은 간단합니다.
① install → npm i react-helmet-async / yarn add react-helmet-async
② <HelmetProvider>로 <App /> 감싸기
// Index.js
import { HelmetProvider } from 'react-helmet-async';
ReactDOM.render(
<BrowserRouter>
<HelmetProvider>
<App />
</HelmetProvider>
</BrowserRouter>
);③ app.js 안에 <helmet>으로 메타태그 적용
// App.js
import { Helmet } from 'react-helmet-async';
const App = () => {
return (
<>
<Helmet>
<title>your project name</title>
</Helmet>
<RouterProvider router={router} />
</>
);
};페이지별 메타태그는 각 페이지 컴포넌트 파일 안에 app.js와 마찬가지로 helmet 컴포넌트를 통해 정의해주면 됩니다.
Helmet 메타태그 우선순위
더 깊숙한 곳에 위치한 Helmet이 우선순위가 더 높습니다.
react-helmet을 사용해 메타 태그를 설정하려고 하는데 index.html에 이미 메타 태그와 관련된 코드가 있다면 중복 메타 태그들은 반드시 삭제해 중복 적용을 막아야 합니다.
메타태그의 내용을 따로 분리해 관리하고 싶다면 metatags.js와 같이 별도의 파일로 만들면 좋을 것 같습니다.
<img alt="⭐️" />
대체 텍스트는 내 사이트에 표시되는 이미지에 대한 짧은 설명을 말합니다. 이는 사이트의 HTML에 포함되어 있으며, 중요한 SEO 에셋입니다. 웹 크롤러는 이미지 내용을 이해하기 위해 대체 텍스트를 빠르게 읽을 수 있습니다.
대체 텍스트는 시각 장애인 웹 브라우저가 눈으로 보지 않아도 페이지의 전체적인 그림을 파악할 수 있도록 도와주는 중요한 접근성 기능이기도 합니다. 웹페이지를 소리 내어 읽는 도구는 이미지를 볼 수 없는 사람들에게 어떤 이미지가 포함되어 있는지 설명하는 대체 텍스트를 읽어줍니다.
SEO가 목적이라면 여러분의 대체 텍스트에 대해 전략적으로 생각하고 사이트를 더 많이 알릴 수 있는 키워드를 포함하는 것이 좋습니다. 하지만, 대체 텍스트는 키워드에만 초점을 맞출 수 없습니다. 이미지가 묘사하는 것을 정확하게 설명하고 있는지 또한 중요하기 때문입니다.
📱 Responsive
예전에는 집집마다 컴퓨터가 있었지만 요즘은 가족 구성원마다 핸드폰을 갖고 있습니다. 컴퓨터를 통한 검색량이 모바일을 통한 검색량에 뒤쳐지게 되면서 모바일 중심 색인 생성이 중요해졌습니다.
모바일 중심 색인 생성
모바일 버전의 콘텐츠를 우선적으로 색인한다는 의미입니다.
그렇다 보니 웹사이트 모바일 친화성은 아주 중요한 랭킹 요소가 되었습니다.
웹사이트의 모바일 친화성은 반응형이 적용되어 있는가와 밀접한 연관이 있습니다.
만약 모바일 전용 웹사이트(예: m.example.com)를 사용 중인 경우에는 모바일 웹사이트와 데스크톱 웹사이트의 상관관계를 알리는 캐노니컬 태그 를 반드시 적용해야 합니다.
캐노니컬 태크는 <head>태그 안에 삽입하는 코드로 특정 웹페이지의 대표 url주소를 검색엔진에게 알려주는 역할로 상위노출 시키는데 중요한 역할을 합니다.
💡 Lighthouse
페이지 로딩 속도란 웹사이트 혹은 웹 페이지를 클릭했을 때 로딩되기까지 시간이 얼마나 걸리는지를 의미합니다. 페이지 로딩 속도는 사용자 경험에 막대한 영향을 끼치기 때문에 보안 프로토콜, 모바일 친화성과 함께 구글이 가장 중요하게 생각하는 랭킹 요소 중 하나입니다.
구글은 데스크톱의 경우 3초 미만, 모바일의 경우 2초 미만의 로딩 속도를 보유한 웹사이트가 가장 경쟁력이 있다고 보고 있습니다.
웹사이트 로딩 속도는 구글이 제공하는 PageSpeed Insights 도구를 통해 진단할 수도 있고 개발자 도구의 Lighthouse로도 진단할 수 있습니다. Lighthouse와 페이지 로딩 속도에 대한 자세한 내용은 제 다른 게시글인 <React, 성능 최적화 (feat.Devtools)>에서 확인할 수 있습니다.
🔑 keyword
SEO를 이해하고 구현하는 데 있어서 가장 중요한 부분 중 하나는 키워드 리서치입니다. 키워드 리서치는 내 웹페이지에서 사용할 가장 관련성이 높은 단어를 찾는 과정입니다.
전문적인 키워드 리서치 도구를 사용함으로써 전 세계 사람들이 자사 혹은 개인의 제품 또는 서비스와 관련된 것들을 어떻게 검색하는지 이해할 수 있습니다. 검색엔진마다 키워드 리서치 도구를 제공하기 때문에 주 타겟이 될 검색엔진의 서비스를 이용하는 것이 좋겠죠? 🙂
🔍 SEO service
검색 포털 사이트마다 SEO를 위해 제공하는 서비스도 있습니다.
구글 → Search console
네이버 → Search advisor
위의 서비스는 두 가지 기능을 제공합니다.
① 검색 포탈에서 웹사이트를 등록
② 포탈에서 자사 사이트의 검색 데이터를 확인
단, 위 서비스를 통해 웹 사이트를 등록하려면 한 가지 조건이 충족되어야 합니다. 바로 HTML의 <head> 안에 관련 정보를 저장하는 <meta> 태그를 추가하는 것입니다.
<meta> 태그는 직접 추가할 수도 있고 도메인을 통해 간접적으로 등록할 수도 있습니다.
References.
