선형자료구조
일렬로 나열된 자료구조
1. 연결리스트
개념
노드가 포인터로 연결되어있는 자료구조 (공간적 효율성 극대화)
배열과 달리 크기가 동적으로 늘어난다.
배열과 달리 메모리 공간이 비연속적이다.
- 연결리스트(싱글) : next 포인터만 가짐, 맨뒤의 포인터는 null
- 이중 연결리스트 : next, prev 포인터를 가짐, 맨뒤의 next와 맨앞의 prev는 null
- 원형 이중 연결리스트 : 이중 연결리스트에서 맨뒤의 next가 헤드 노드를 가리킴(prev는 x)
시간복잡도
- 삽입, 삭제 : O(1)
- 탐색 : O(n)
- 접근 : O(1)
** 접근 : n번째 인덱스의 값을 찾는것
** 탐색 : 인덱스를 모를 때2. 배열
개념
크기가 정해져 있고, 연속된 메모리공간에있는 데이터를 모아놓은 자료구조
시간복잡도
- 삽입, 삭제 : O(n)
- 탐색 : O(1)
- 접근 : O(1)
배열과 연결리스트
배열은 정적인 자료구조이다. 한번 크기를 정해 놓으면 크기 수정이 불가하고 배열 크기 이상의 데이터를 저장할 수 없다. 반면 연결리스트는 동적인 자료구조이다. 크기의 제한이 없기 때문에 추가 삭제가 자유롭지만 배열처럼 연속적인 메모리 주소를 할당받지 않기때문에 임의 접근이 불가능하다.
삽입, 삭제가 빈번한 것 => 연결리스트를 쓰자
탐색이 빈번한것 => 배열을 쓰자
배열(Array)과 ArrayList
ArrayList는 내부적으로 Array로 구성되어있지만 가변길이이다.
3. 스택
개념
LIFO의 성질을 가진 자료구조
재귀 알고리즘이나 웹 방문기록에 쓰임
시간 복잡도
- 삽입, 삭제 :O(1)
- 탐색 : O(n)
4. 큐
개념
FIFO의 성질을 가진 자료구조
CPU 작업을 기다리는 프로세스, 스레드 행렬 또는 네트워크 접속을 기다리는 행렬, BFS, 캐시 등에 쓰임
시간복잡도
- 삽입, 삭제 : O(1)
- 탐색 : O(n)
비선형 자료구조
5. 그래프
개념
정점과 간선으로 이루어진 자료구조
원소간의 n:n 관계
공간복잡도
(1) 인접 행렬로 구현했을 때
O(V^2)의 공간복잡도 필요
(2) 인접 리스트로 구현했을 때
O(E)의 공간복잡도 필요
V: 정점
E: 간선6. 트리
개념
그래프의 일종으로 사이클이 없이 모든 정점이 연결되어있는 그래프
(사이클: 시작노드에서 다시 시작노드로 돌아올수있는것)
컴퓨터의 디렉토리 등에 쓰인다.
트리의 종류
(1) 이진트리
자식 노드의 수가 두개 이하인 트리
완전 이진 트리 : 왼쪽부터 채워진 이진트리 -> 마지막 레벨을 제외한 모든 레벨이 완전히 채워져있고 마지막 레벨은 왼쪽부터 채워져있다.
(2) 이진 탐색 트리
자식노드의 오른쪽에는 더 큰값, 왼쪽에는 더 작은 값이 들어있는 트리
중위 순회를 하면 크기 순대로 읽을 수 있다.
- 시간복잡도 : 탐색에 O(logn), 최악의 경우 O(n) (트리의 자식노드가 하나로 선형적으로 생성됐을때)
(3) AVL트리
최악의 경우인 선형적인 트리가 되는것을 방지하기 위한 이진탐색트리. 스스로 균형을 잡는다.
왼쪽 오른쪽의 서브트리의 높이차가 최대 1이다.
회전을 통해 균형을 잡는다. - 시간복잡도 : 탐색, 삽입, 삭제 O(logn)
(4) 레드 블랙 트리
균형 이진 탐색 트리이다. 각 노드는 빨간색, 검은색 색상을 나타내는 추가비트를 저장하며, 삽입 및 삭제 중에 트리가 균형을 유지하도록 사용된다. - 시간복잡도 : 탐색, 삽입, 삭제 O(logn)
7. 힙
완전 이진 트리 기반인 자료구조
최대힙
루트 노드에 있는 키는 모든 자식에 있는 키중에서 가장 크고 아래 노드도 똑같은 조건
최소힙
루트 노드에 있는 키는 모든 자식에 있는 키 중에서 최솟값이어야한다.
8. 우선순위 큐
우선순위가 높은 요소가 가장 먼저 제공되는 자료구조. 힙을 기반으로 구현된다.
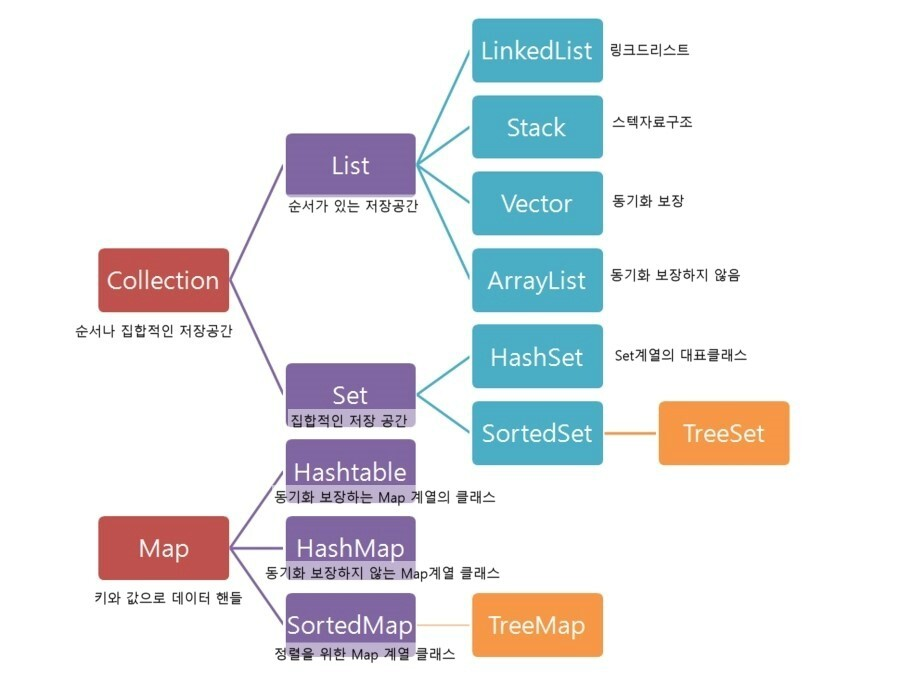
9. 맵
Key-Value 조합으로 형성된 자료구조이다. java의 treemap은 레드 블랙 트리 자료구조를 기반으로 형성된다.
Key는 맵에 오직 유일하게 있어야함.
맵의 종류
(1) HashMap
키를 해싱하여 자료를 저장하고 꺼내오기 때문에 속도가 빠르다.
중복을 허용하지 않고 순서를 보장하지 않음.
key와 value로 null이 허용됨.
해싱이란 산술적인 연산을 이용하여 키가 있는 위치를 계산하여 찾아가는 검색방식이다.(키값을 value값이 저장되는 주소값으로 바꾸기위한 수단) 키값을 원소 위치로 변환하는 함수를 해시 함수라고 한다.
학생의 이름을 넣으면 좌석번호가 생성되는것과 같다. (2) HashTable
해시 함수에 의해 계산된 주소에 값을 저장한 표를 해시 테이블이라고 한다.
HashMap과 기본적인 사용법이 동일하다.
HashTable과 HashMap의 차이
1. 동기화 여부 : HashMap은 동기화를 지원하지 않는다. -> 단일스레드환경에서 사용하기 좋은 자료구조이다.
HashTable은 동기화를 지원하여 thread-safe하다.-> 멀티 스레드 환경에서 사용하기 좋은 자료구조이다. HashMap에 비해 느리다.(다른 스레드가 block되고 unblock되는 대기 시간을 기다리기 때문이다.)
2. nulll 사용여부 : HashMap은 key,value에 null이 들어갈 수 있다.
HashTable은 key,value에 null이 들어갈 수 없다.
=>HashMap사용을 권장!! (최신형)(3) TreeMap
이진탐색트리의 형태로 key-value 쌍으로 이루어진 데이터를 저장한다. (레드블랙트리로 구현되어있다.)
정렬된 순서로 key-value 값을 저장하므로 빠른 검색이 가능하다.
저장시 정렬(오름차순)을 하기 때문에 저장시간이 다소 오래걸린다.
레드블랙트리 vs 해시
해시에는 순서가 없기 때문에 순서가 자료일 경우 레드블랙트리가 좋다.
검색과 정렬에 TreeMap이 더 뛰어나고 그이외의 것에는 HashMap이 더 좋은 성능을 가지고 있다.(4) LinkedHahsMap : 들어간 순서대로 저장되는 map
10. 셋
특정 순서에 따라 고유한 요소를 저장하는 컨테이너이다.
데이터를 중복 저장 할 수 없다.
(1) HashSet
(2) TreeSet
- 오름차순으로 데이터를 정렬한다.
(3) LinkedHashSet - 입력된 순서대로 데이터를 관리한다.
추가 참고
레퍼런스
