Internet protocol (IP)
전송 방식은 기본적으로 TCP/IP protocol을 사용한다. 여기서 TCP와 IP는 다른 개념으로 분리하여 생각해야 한다.
IP는 기본적으로 Unreliable하고 Connectionless한 프로토콜이며, 문제를 해결해주지 않는 Best-effor 방식의 프로토콜이다.
그래서 이 안에서는 데이터그램이 없어질 수도 있고, 에러가 발생할 수도 있고, 순서가 뒤바뀔 수도 있다. 이런 오류에 대한 해결은 IP 단에서 하는게 아니라 이보다 상위 계층에서 TCP 프로토콜이 해결한다. 이 TCP 프로토콜은 추후에 자세히 다룰 예정이다.
IP Datagram
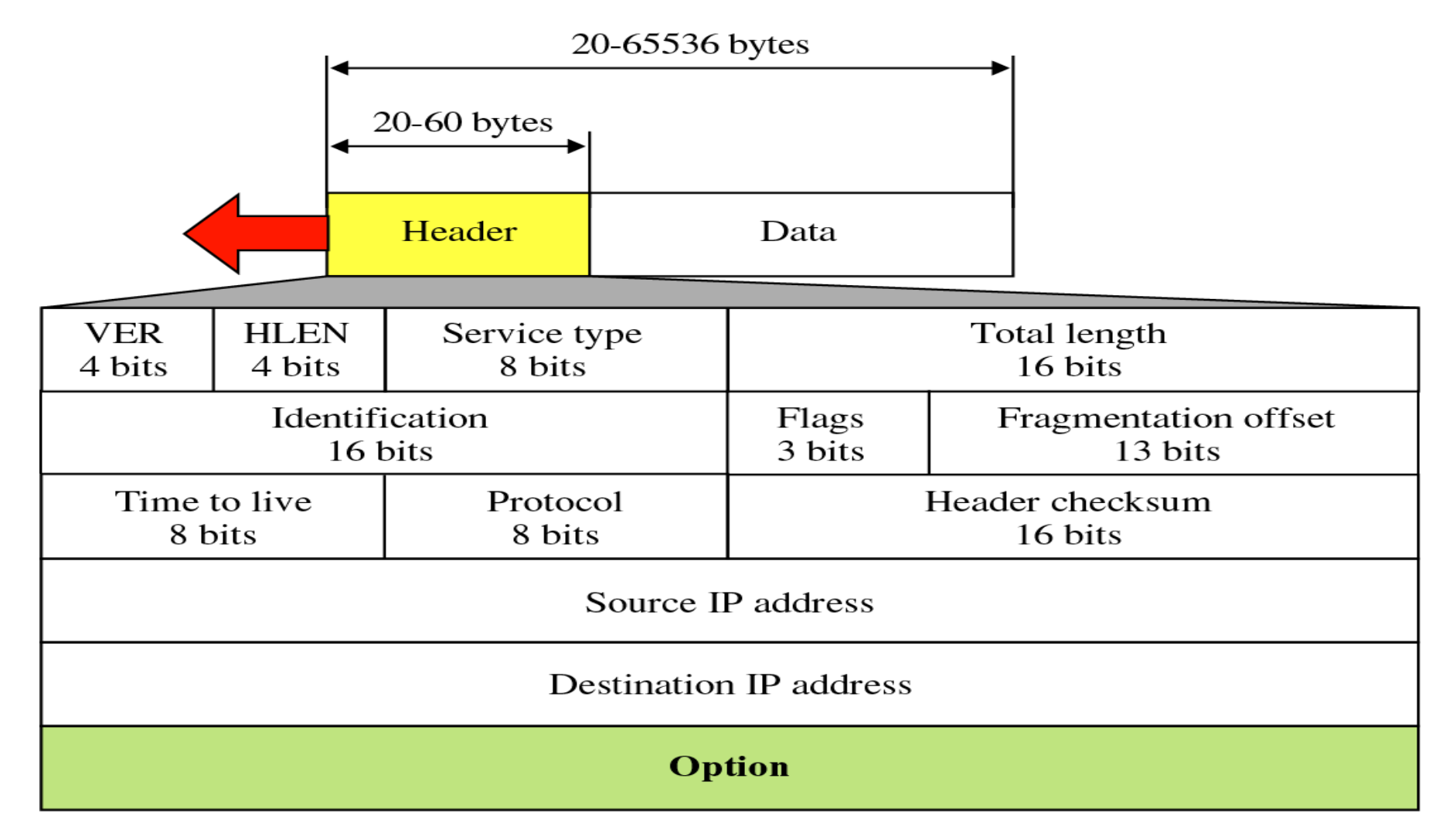
Packet을 보면, 내부에는 Header와 Data로 나뉜다. 여기서 나오는 것은 Header의 구조이다.
VER(Version)
IP Protocol의 버전을 나타낸다. 4bit로 이루어져있다. 현재 IP Protocol의 버전은 IPv4를 사용하고 휴대폰에서 사용하는 버전은 주로 IPv6으로 나타낼 수 있다.
HLEN(Header length)
4bit로 헤더의 길이를 표현한다. 값이 하나씩 증가할 때마다 단위는 32bit word, 즉 4byte를 의미한다.
0001 = 4byte 길이, 0011 = 12byte 길이 이런 식이다.
4bit로 헤더를 표현하기 때문에 60byte가 최대이다. (1111 = 15 -> 15 * 4 = 60)
기본적으로는 5(0101)을 사용하기 때문에 20byte가 최소 헤더의 길이이고, 옵션이 추가된다면 최대 60byte까지 늘어날 수 있다.
Type of Service(=Service type)
Application 계층에서 데이터나 서비스의 속성 등을 하위 계층에 알려주기 위해 사용하는 부분이다.
예를 들어, 스트리밍의 경우에는 실시간 처리 필요, 다운로드 성 데이터는 실시간 처리 필요 x니까 Application에서 이런 특성들을 IP 단에게 헤더에 넣어 알려주는 것이다.
이 Type of Service 헤더는 두 부분으로 나뉜다. 바로 6비트의 Diffserv와 2비트의 ECN이다.
앞서 말했던 서비스의 특성을 담는 부분이 Diffserv로 0부터 5까지 6비트를 사용한다. 이는 곧 64개의 다른 서비스를 정의할 수 있다는 것을 의미한다. 이 서비스들마다의 우선순위를 두어 추후 라우팅하게 된다.
ECN은 추후에 Congestion Control과 Transport layer 부분에서 설명할 예정이다.
TL(Total length)
헤더를 포함한 전체 패킷의 길이를 나타내는 부분으로 총 16비트를 차지한다. 단위는 바이트를 사용한다. 앞선 HLEN에서는 4바이트마다 값이 1 증가했는데, 여기서는 1 증가할 때마다 1바이트가 증가하는 것을 의미한다.
Id, Flag, Fragmentation offset
flagmentation을 위해 사용되는 부분이다. 이는 아래에서 자세히 다뤄보자.
TTL(Time to live)
해당 패킷이 Destination에 도착하기 전까지 거쳐야 하는 네트워크, 즉 거쳐야 하는 라우터(hops)의 개수를 지정하기 위해 사용한다. 이 TTL을 사용해 패킷이 Destination에 방문하기까지 최대로 거칠 수 있는 hop이나 라우터의 개수를 조절할 수 있다. 여기서는 8bit를 사용한다.
라우터가 패킷을 받으면, TTL을 1 감소시킨다. 만약, 들어온 패킷에 TTL 헤더 부분을 1 감소시켰는데 값이 0이 나왔다면 이 패킷은 더 이상 라우터를 거칠 수 없으므로 그 라우터에서 바로 Discard시킨다.
Protocol
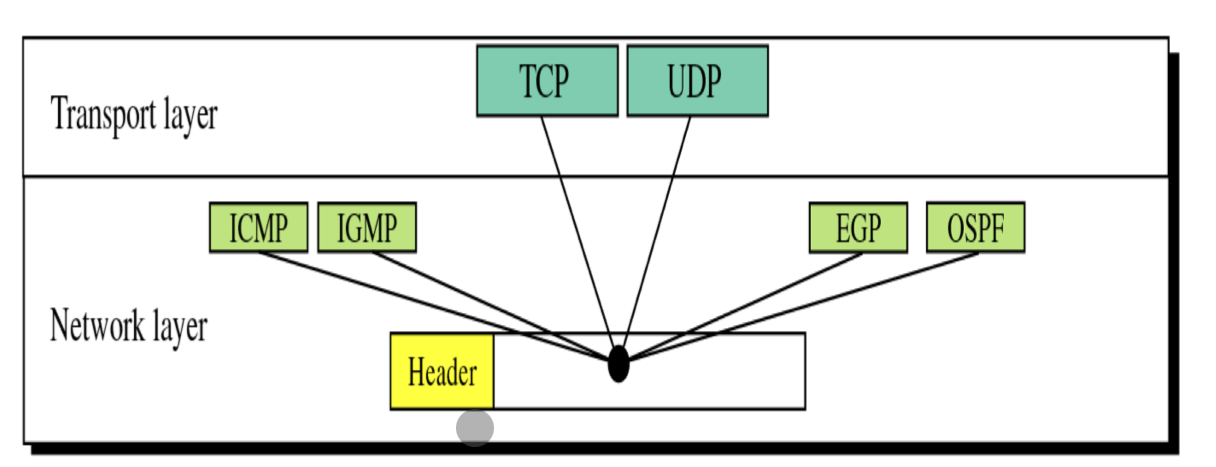
IP 계층의 서비스를 이용하는 상위 계층의 데이터가 어떤 프로토콜을 사용하는 지를 나타내는 필드로 8bit를 사용한다.

예를 들어, 1로 설정되어 있으면 이 데이터는 ICMP 데이터이고, 2로 설정되어 있으면 IGMP 데이터, 6이면 TCP 데이터 등으로 설정할 수 있다.
그래서 리시버는 패킷의 헤더에 17이 들어있으면 해당 패킷의 데이터를 UDP 모듈로 올려보내는 작업을 진행한다.
Checksum
IP 헤더에 에러가 있는 지를 확인하기 위해 사용하는 16bit짜리 필드이다. TCP/IP 프로토콜에서는 Error Detection은 제공하지만 Error correction은 제공하지 않는다. 왜냐하면 Unreliable connectionless 방식이기 때문이다. 이 checksum은 Error Detection을 제공하기 위한 기능이다.

Sender에서 우선 checksum 16bit를 모두 0으로 만들어서 설정한다.

그리고선 헤더의 모든 값을 더하여 Sum값을 만든다. Checksum은 이 Sum값을 반전시켜(=1의 보수로 만들어) 얻어낸다. 이 Checksum을 다시 아까 0으로만 넣었던 헤더 자리에 넣고 Sender가 패킷을 보낸다.
이후 Router가 이 패킷을 받으면, TTL(Time to live)값을 1 감소시킨다.
그러나, 이러면 Router는 Checksum 계산을 매번 처음부터 새로 해야한다. 이 계산을 처음부터 다시 하는 작업은 시간이 굉장히 오래 걸린다. 이 계산을 다시 할 순 없으니 Checksum 앞 부분에 1을 더하는 방식으로 문제를 해결한다.
TTL에서 1이 빠지면 Sum값이 1만큼 감소 ➡️ Sum값에 1의 보수를 취한 Checksum은 1 증가
Fragmentation 되었거나 옵션이 걸려있을 때도 헤더값이 변한다. 이 경우에는 예외없이 Router에서 계산을 매번 새로 해야한다. 때문에 옵션은 거의 사용하지 않는 것이 좋고, Fragmentation도 성능을 저하시킬 수 있어서 IPv6에서는 Fragmentation을 아예 사용하지 않는 방법을 사용한다.
참고로 이렇게 더했을 때 캐리값이 생기면 캐리값을 버리고 1을 더한다.

Source address & Destination address
각각 32bit로 패킷을 보내는 소스의 주소와 패킷을 받아야 하는 목적지의 주소를 나타낸다. 이 주소들은 패킷을 전송하고 도달할 때까지 바뀌면 안되는 주소이다.
단, Destinaion address의 경우 특정한 한 사람을 가리킬 수도 있고, 여러 사람, 모든 사람을 가리킬 수도 있다. 여기서 특정한 한 사람을 가리키면 Unicast, 여러 사람을 가리키면 Multicast, 모든 사람을 가리키면 Broadcast address라고 한다. Anycast address라는 것도 존재하지만, 이는 다루지 않는다.
Anycast는 같은 번호 중에 가장 가까운 번호로 연결시켜주는 방법에서 사용된다. ( ex - 프랜차이즈 음식점 전화번호)
IP header options
이 옵션은 필수로 들어가야 하는 부분은 아니다. 실질적으로는 잘 쓰지 않는 부분인데, 그 이유는 이 옵션을 사용하면 라우터에서 이 옵션을 처리하는 시간이 오래 걸려서 잘 쓰지 않는다. 보통 네트워크의 테스트나 디버깅을 위해서 사용하는 부분으로 옵션에 대한 처리는 IP Software에서 담당한다. 이 옵션이 있으면 라우터에서 옵션들을 처리해야 하기 때문에 가능하면 클라이언트는 이 옵션을 집어넣지 않도록 한다.

옵션은 다음과 같이 1byte짜리 옵션이 있고, 여러 byte짜리 옵션이 있다.
No operation
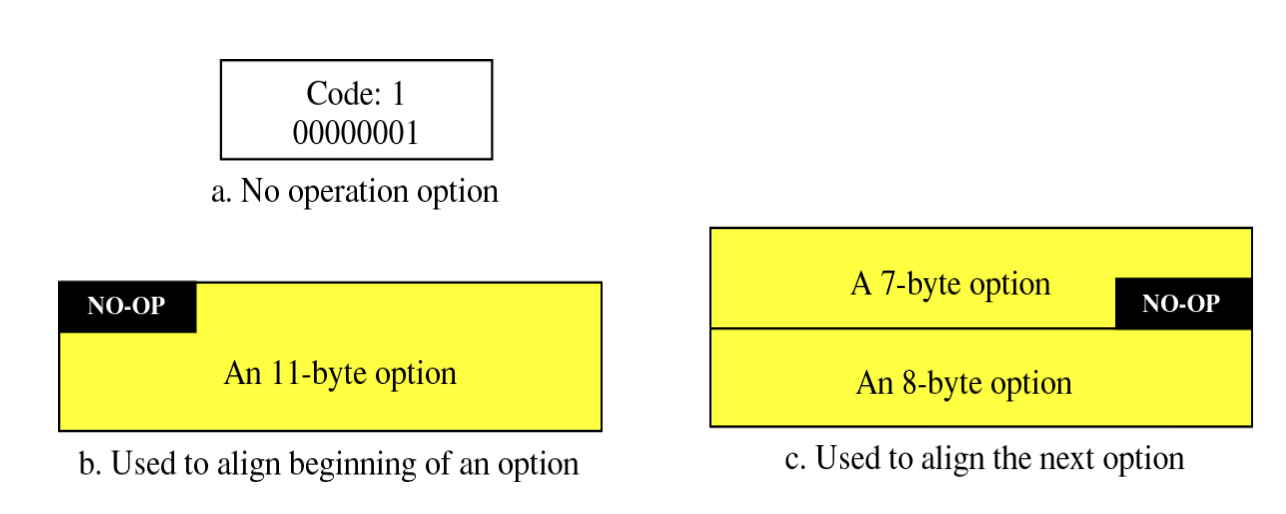
옵션 사이에 filler로 사용하는 옵션이다. 특별한 의미나 작업을 하는게 아니라 옵션들이 1word 단위인 4byte의 배수로 이루어지지 않는 경우 그 공간을 채우기 위해 사용하는 옵션이다.
End of option
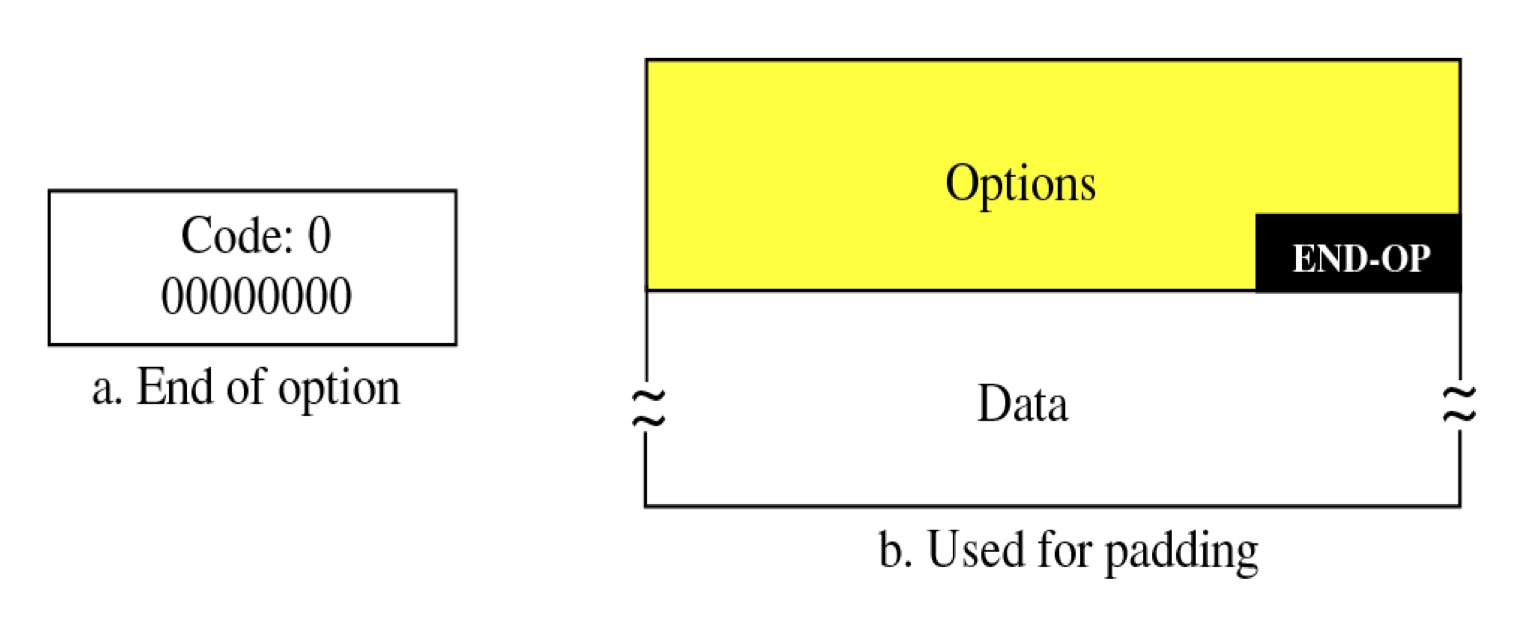
이 옵션도 No operation 옵션과 비슷하게 옵션 부분이 끝났다라는 것을 알려줌과 동시에 옵션 부분을 4byte의 배수로 맞추기 위해 들어가는 옵션이다.
Record route

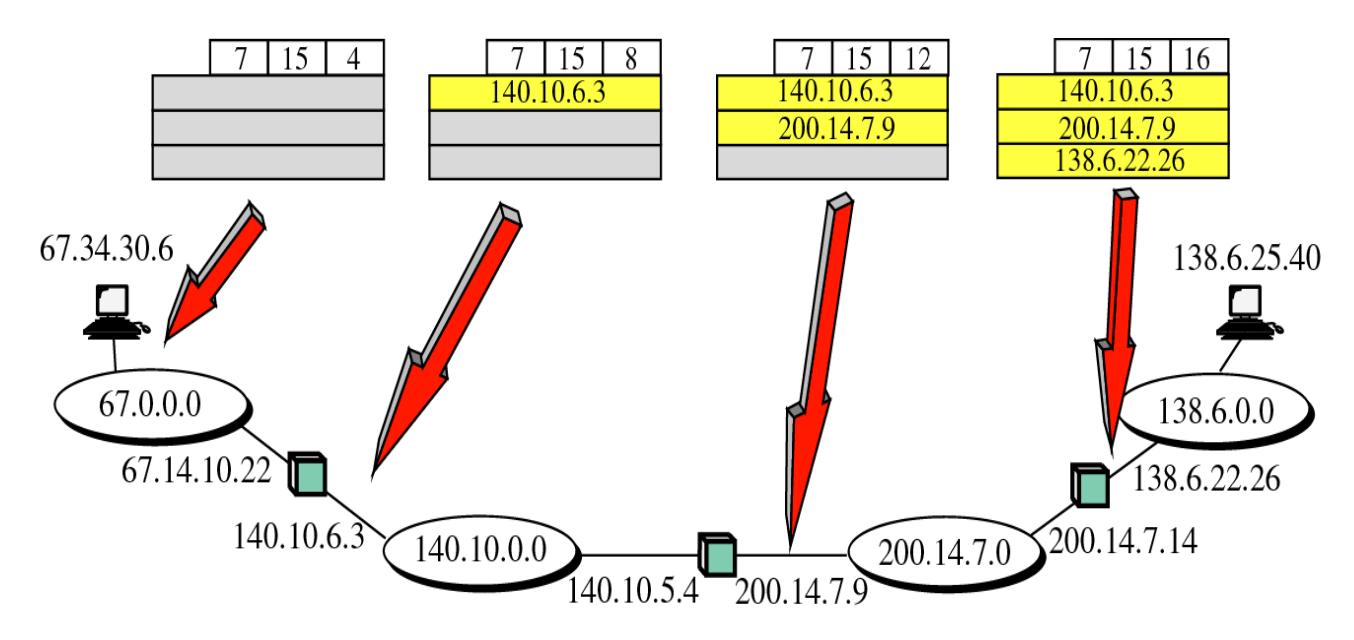
데이터를 처리하는 라우터를 기록하기 위해 사용한다. 이 옵션을 사용하면 라우터가 패킷을 받아서 보내기 전에 보내는 인터페이스의 IP 주소를 적어서 보낸다. 이렇게 되면 Destination은 이 데이터그램이 어느 라우터를 거쳐서 왔는가를 알 수 있게 된다. 그래서 이 데이터그램이 제대로 된 경로를 거쳐서 왔는지 혹은 라우터가 뭔가 잘못된 동작을 했는지 등을 테스트할 수 있다.
Strict source route

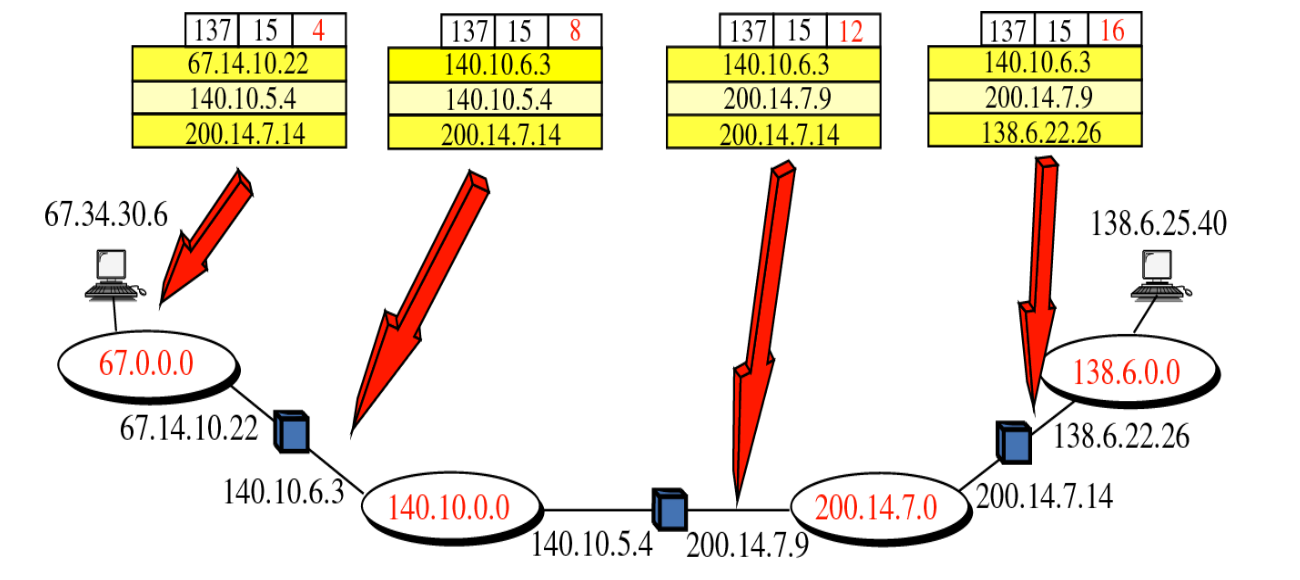
도착하기까지의 경로를 hop by hop으로 미리 지정해둔 것을 말한다. 만약, 여기에 적혀있는 IP주소까지 한번에 갈 수 없다면 바로 그 패킷을 Discard 시켜버린다. 역시 여기서도 Record route 특성을 살린다. 처음 테이블에서는 라우터로 들어갈 인터페이스의 IP주소가 기입되어 있었는데, 라우터를 지나고 나니 라우터에서 빠져나온 인터페이스의 IP 주소가 그 Record route에서의 기존 라우터 주소를 대체하게 된다.
Loose source route

이 옵션은 Strict source route 옵션에서는 hop by hop으로 주소를 지정해서 다음 IP 주소로 가지 못하면 바로 Discard 시켰는데, 이 방식은 다른 여러 hop을 거쳐서 적힌 걸로 갈수만 있으면 괜찮다는 방식이다.
Timestamp
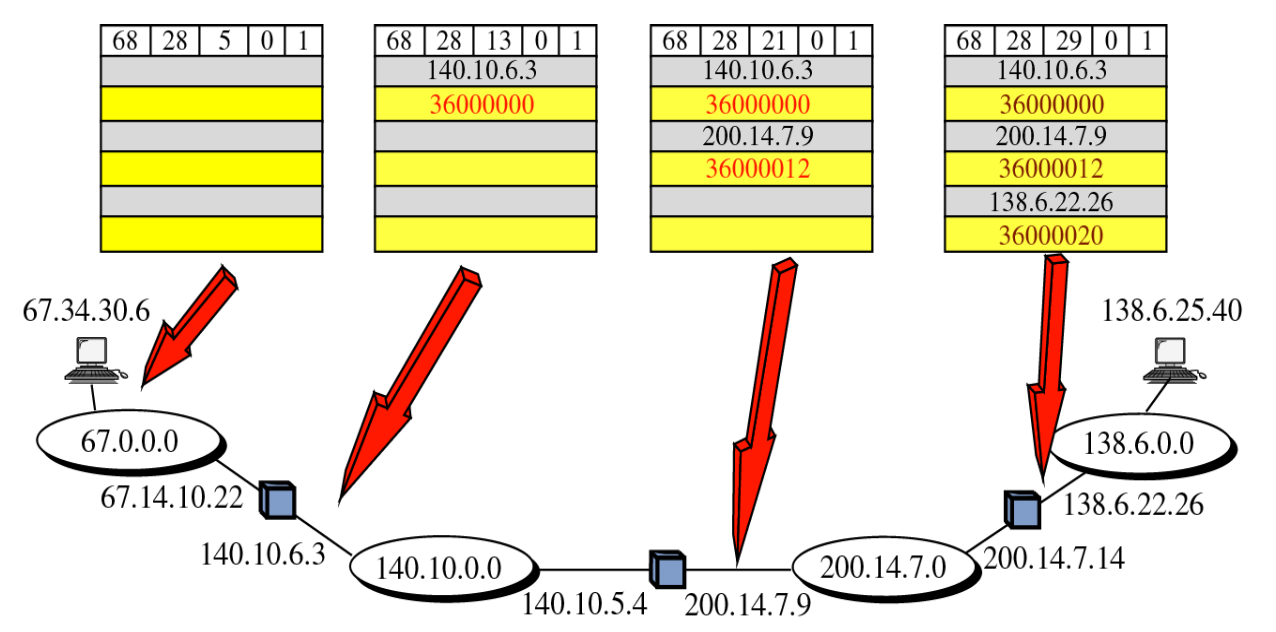
이 옵션은 거친 라우터의 주소와 도착한 시간까지 기록하는 방식으로 시간이 길어지면 문제가 발생했다라는 것을 인지할 수 있는 옵션이다.
Fragmentation
인터넷은 서로 다른 네트워크를 거치고 거쳐 Source에서 Destination까지 전달되는데, 이 각 네트워크마다 전송할 수 있는 최대 바이트의 개수가 다 다르다. 예를 들어, LAN의 경우에 이더넷 프레임 안에 들어갈 수 있는 최대 바이트의 개수는 1500개였는데, 다른 네트워크들은 이보다 더 작을 수도 있고 클 수도 있다.
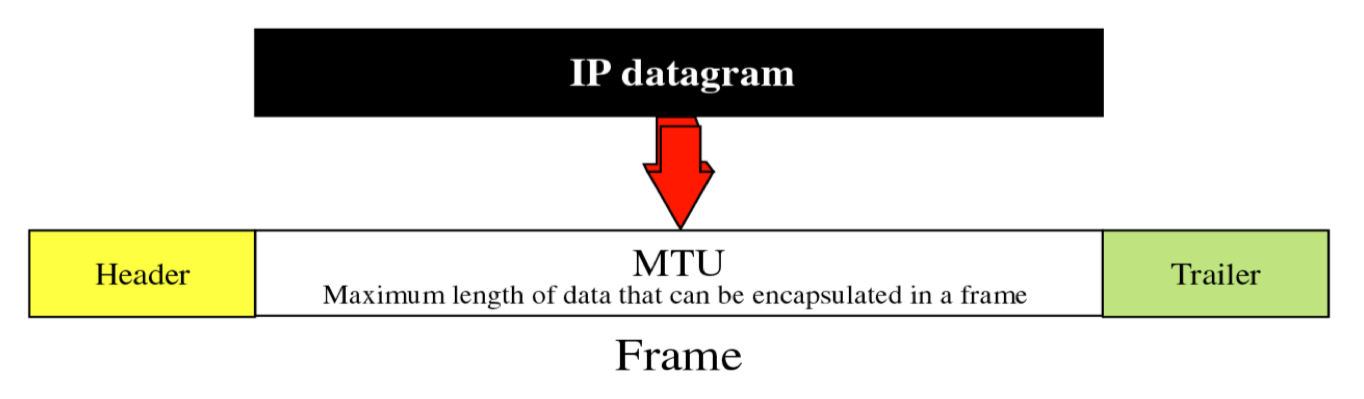
여기서 네트워크가 전송할 수 있는 최대 길이를 MTU(Maximum Transfer Unit)이라고 한다. 정확히 말하자면 Datalink 프레임 형식의 데이터 필드의 최대 길이를 의미한다.
이 MTU가 네트워크마다 다르다는 것이 문제라는 것이다. 만약, A 네트워크는 1500바이트까지 전송할 수 있는데, B 네트워크는 800바이트까지를 보낼 수 있다고 해보자. 이러면, A에서 B로 데이터를 보내면 온전한 데이터를 보낼 수 없게 된다. 이를 위해 A와 B 사이의 라우터에서 이 데이터를 쪼갠 후, 나중에 Destination에서 다시 데이터를 붙이는 방식을 Fragmentation이라고 한다.
Fragmentation으로 패킷을 쪼개는 것은 라우터에서도 가능하고 Source에서도 가능하다. 쪼개진 패킷들은 마치 독립된 데이터그램처럼 전달된다. 이 쪼개진 데이터그램들은 Destination에서 취합하여 다시 합친다.
ID
16bit로 구성되어 Source host에서 데이터를 보낼 때마다 데이터그램에 할당하는 값이다. 1씩 증가하는 식으로 Id를 부여할 수 있다.
Flags

3bit로 구성되어 있는 부분으로 첫 비트는 미래를 위해 남겨둔 부분이고 그 다음 비트는 D(Do not fragment), M(More fragments)의 의미를 가진다.
📌 D : Do not fragment라는 뜻으로 Source host가 이 패킷을 절대 fragmentation하지 말라고 설정하는 것이다. 이 D가 1로 설정되어 있는데, MTU가 달라 데이터를 보내지 못하는 상황이 생기면 Router는 이 패킷을 그냥 Discard 시켜버린다.
📌 M : More fragments라는 뜻으로 이 값이 0이면 해당 패킷은 fragmentation되지 않았거나, 이 패킷이 쪼개진 가장 마지막 부분의 패킷이다라는 의미이고, 이 값이 1이면 해당 패킷은 쪼개진 패킷의 마지막 부분은 아니다라는 의미이다.
Fragmentation offset

13bit로 구성되어 있고, 이 값은 전체 패킷에서 이 Fragmentation 조각의 상대적인 위치를 8의 배수로 나타내는 값이다. 예시 그림의 경우를 통해 살펴보자.
20byte를 옵션없이 헤더로 사용하고, 4000Byte의 데이터 부분이 존재한다고 하면 fragmentation이 되기 전 상황은 Id는 813이라고 임의로 배정받았고, Flag의 M값은 0, fo값은 0/8 = 0이다. 이걸 1400, 1400, 1200으로 쪼개면 각 frag들은 기존 패킷과 id는 813으로 동일하다.
그러나, 앞의 두 1400짜리 패킷들은 M값이 1이 될 것이고 마지막 패킷만 M값이 0이 된다. 또한, fo값은 가장 처음 frag는 0/8 = 0, 두 번째 frag는 1400/8 = 175, 세 번째 frag는 2800/8 = 350이 된다.
이때, 아까 헤더는 20Byte를 사용한다고 했으니 각 frag의 TL값은 1420, 1420, 820이 된다.
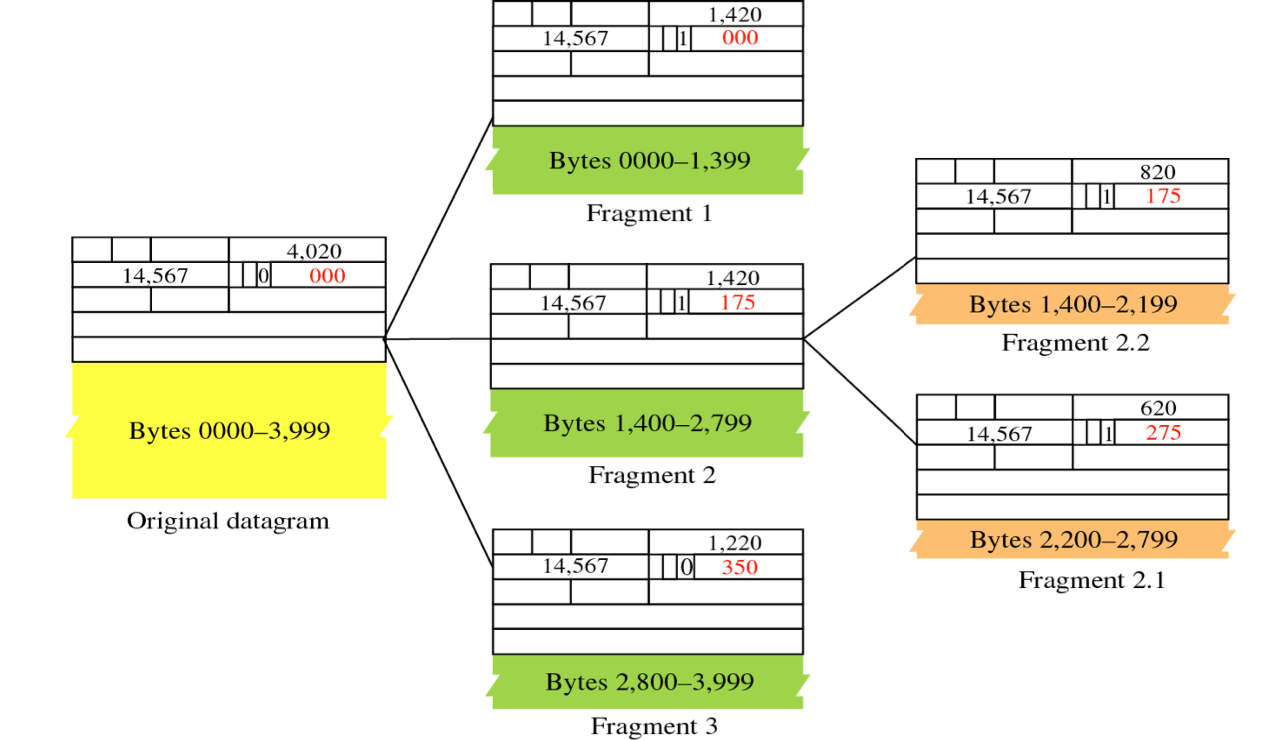
이 fragment는 계속 더 쪼갤 수 있다. 그러나, 예를 들어, Fragment 2를 2.1과 2.2 두 부분으로 쪼갠다고 해도, fo값과 M값은 원래 데이터그램을 기준으로 하기 때문에 fo 값은 1400/8 = 175와 2200/8=275이 되고, M값은 모두 1이 된다. Fragment 3를 두 개로 나눈다고 해도 fo 값은 위와 같이 계산하고 M값은 나눈 두 fragment 중 가장 마지막 부분이 M=0이 되고 다른 한 부분은 M=1이다.
이 Fragmentation offset값은 Destination에서 Fragment들을 합칠 때 사용하는 값이다. 예를 들어, 들어온 패킷에서 fo 값이 275라면 이 패킷 앞에 몇 Byte가 있는 지는 알 수 있지만 전체 frag가 몇 개가 있는 지는 알 수가 없다. 운 좋게 M=0인 값이 들어온다고 해도 fo 값이 0이 아니면 전체가 몇 바이트로 이루어진 패킷이 쪼개진거구나는 알 수 있지만, 그 앞에 몇 개의 fragment들로 쪼개진건지는 모른다.
이 frag들을 도착할 때까지 마냥 기다리고 있을 수는 없다. 도중에 frag가 도착하지 않는 경우가 생긴다면 계속 기다릴 순 없으니 말이다. 이를 위해 Destination은 가장 처음 들어온 Fragment가 도착했을 때부터 타이머를 구동시키고, 이 타이머가 끝날 때까지 전체 fragment들이 도착하지 않았다면 그냥 받았던 걸 모두 Discard 시킨다. 타이머가 끝날 때까지 다 잘 들어왔다면 타이머를 종료시키고 상위 레이어로 데이터를 조합해 올려보낸다.
