Proxy(프록시)
Member 객체가 Team 객체에 의존하고 있다고 해보자. 이때, Member를 조회한다면 Team도 함께 조회해야 할까? Member를 조회해서 Team을 사용하지 않을 경우에도 Team 객체를 조회하는 것은 비효율적인 방법이다. 기존에는 em.find를 하면 해당 객체에 맞는 엔티티를 DB에서 실제로 조회해서 가져왔는데, em.getReference()를 이용해서 객체를 가져오면 DB에서 조회하는 것을 미루고 가짜 엔티티를 가져온다. 여기서의 가짜 엔티티를 Proxy라고 한다.
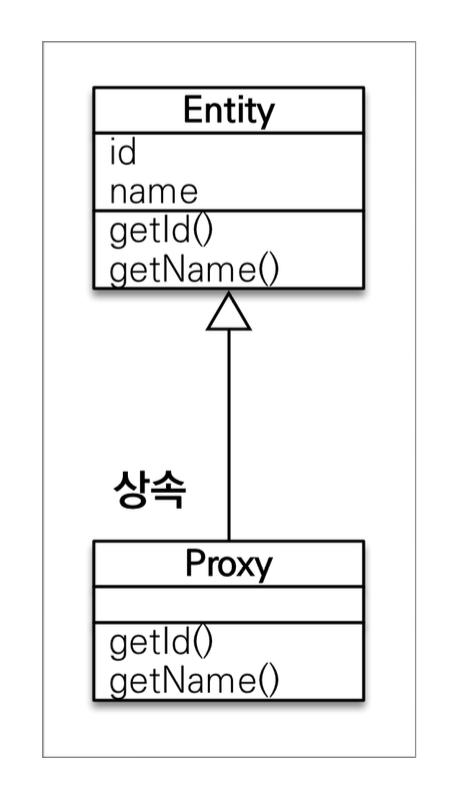
Proxy는 실제 클래스를 상속받아서 만들어지며, 겉모양이 같다. Proxy는 실제 객체의 메소드에 더해 실제 객체의 참조(target)을 보관한다. 그래서 프록시 객체를 호출하면 이 객체는 실제 객체로 가서 실제 객체의 메소드를 호출하게 된다.
사용자는 이론적으로 프록시 객체와 실제 객체를 구분하지 않고 사용하면 된다.
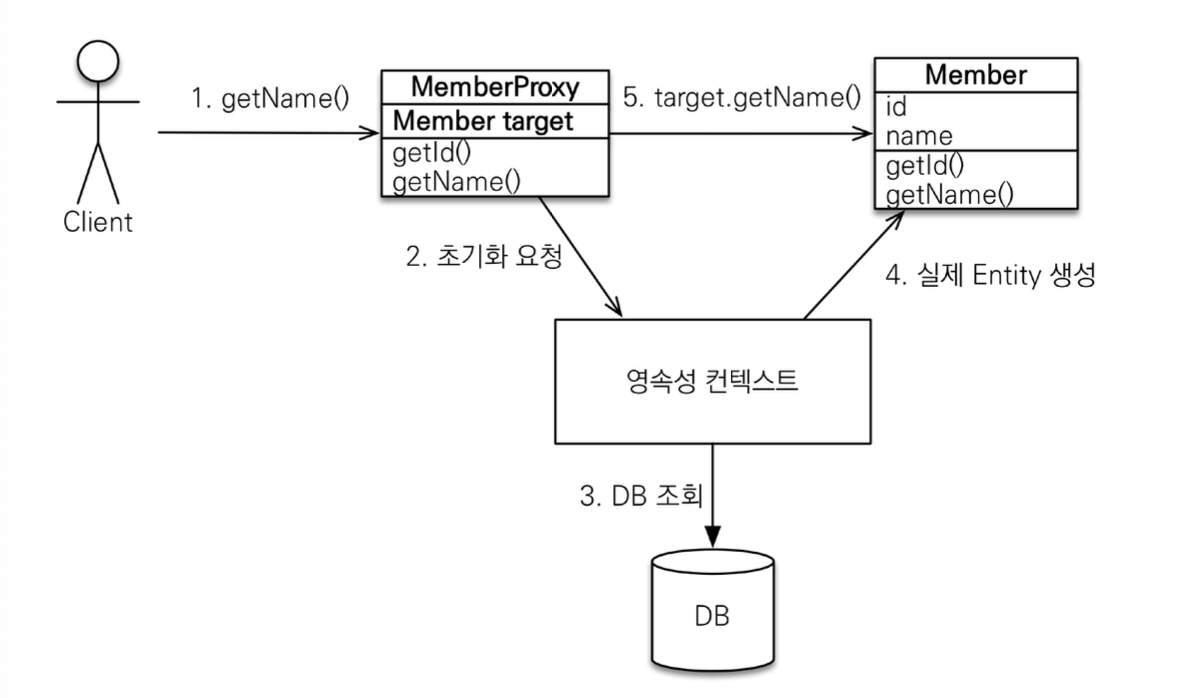
프록시 객체를 가져온 후, 메소드를 실행시키면 다음과 같은 절차를 밟는다. 초기 프록시 객체는 이 객체를 사용하기 전까지는 target이 NULL이다. 이 객체를 사용하는 순간 이 객체가 초기화되는데, 이때 DB에서 객체를 조회해와서 실제 엔티티에 대해 target이 참조할 수 있게 된다.
실제 엔티티로 프록시 객체가 변하는게 아니라 실제 엔티티를 참조할 뿐이다.
이때, 프록시는 처음 사용할 때 한번만 초기화된다. 초기화 후에는 프록시의 target 값이 존재하므로 초기화할 이유가 없기 때문이다.
주의할 점은 영속성 컨텍스트 내에서는 em.find로 실제 객체를 가져오고 em.getReference로 프록시 객체를 가져와서 == 비교한다면, 두 객체는 다른 타입의 객체지만 JPA는 다음과 같은 상황에서 동일성을 보장해야 하는 특징이 있기 때문에, em.find와 em.getReference 중 나중에 실행된 메소드가 이미 실행된 메소드에서 반환하는 타입을 가져간다. 예를 들어, find가 먼저 실행됐다면 getReference를 사용해도 실제 객체가 가져와진다는 것이다.
참고로 타입을 비교할 때, 영속성 컨텍스트에 없다면 위와 같은 사례에서 동일성을 보장하지 않기에 프록시 객체와 실제 객체를 비교하면 false가 발생한다. 그래서 ==으로 비교하지 않고 instanceof를 사용해서 타입을 비교해야 한다.
또한, 준영속상태(detached)나 em.clear로 영속성 컨텍스트를 끄는 경우에 프록시 객체를 초기화하면 두 경우 모두에서 에러가 발생하기 때문에 주의해야 한다.
지연 로딩과 즉시 로딩
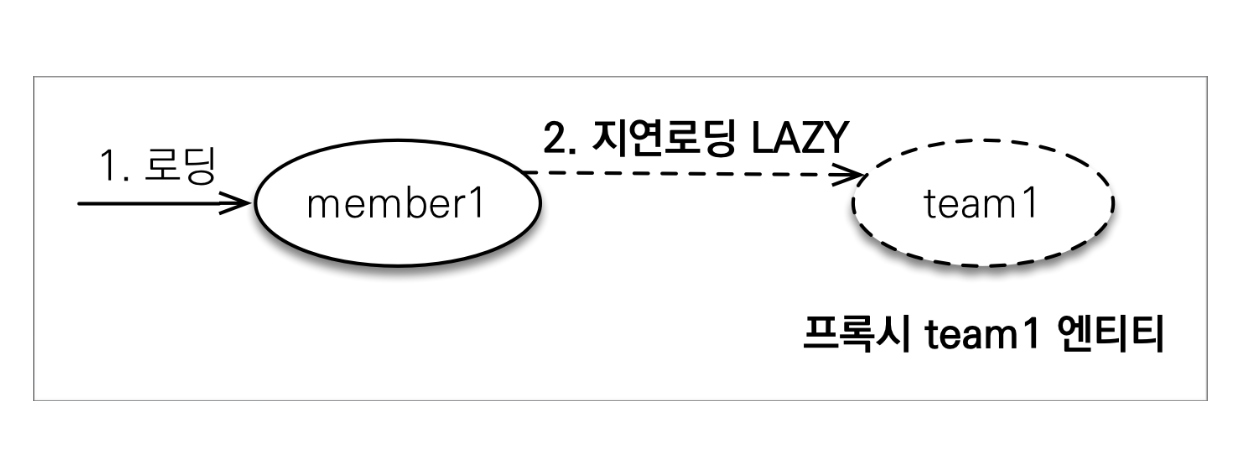
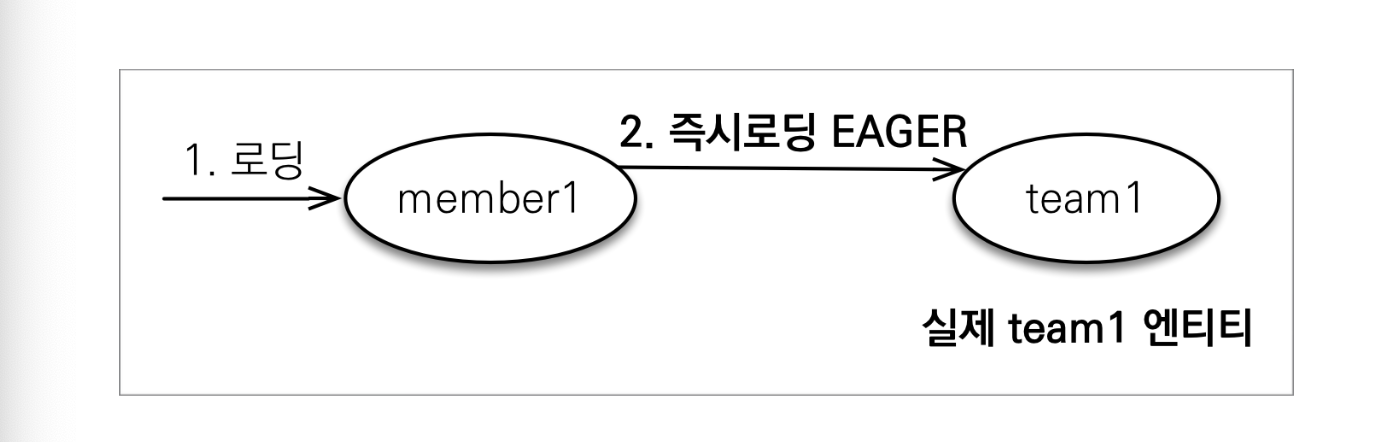
위와 같이 프록시를 사용해서 실제로 객체를 사용할 때까지 조회를 미루는 방식이 지연 로딩이고, 객체를 조회할 때 바로 DB에서 조회해오는 방식이 즉시 로딩이다.
지연 로딩
즉시 로딩
이 둘은 @ManyToOne과 같은 매핑 어노테이션에 fetch = FetchType.LAZY 혹은 fetch = FetchType.EAGER로 설정할 수 있다.
그러나, 가급적이면 지연 로딩만 사용하는 것이 좋다. 즉시 로딩을 사용하면 예상하지 못한 SQL이 발생할 수 있다는 단점과 JPQL 등에서 N+1 문제가 일어날 수 있기 때문이다. 즉시 로딩을 사용하고 싶은 경우에도 EAGER가 아닌 LAZY로 설정한 후, fetch join을 사용해서 가져오는 것이 좋다.
특히, @ManyToOne과 @OneToOne에서는 Default값이 EAGER이기 때문에 LAZY로 설정하는 것을 권장한다.
N+1 문제
N+1 문제는 ORM 기술에서 특정 객체를 대상으로 수행한 쿼리가 해당 객체가 가지고 있는 연관관계 또한 조회하게 되면서 N번의 추가적인 쿼리가 발생하는 문제이다. 예를 들어, 1개의 게시글이 10개의 댓글을 가지고 있다고 했을 때, 게시글을 조회하면 댓글들도 다 가져와야 하므로 총 11번의 select 문이 나가게 된다. 이런 문제를 N+1이라고 한다.
이런 문제를 해결하기 위해 Fetch join을 사용할 수 있다.
