JPA와 오해풀기
:: 쿼리 최적화가 안될 때
Q.
JPA 가 1차캐시(영속성 컨텍스트) 를 통해 필요없는 쿼리는 날라가지 않도록 쿼리를 최적화 해준다고 하는데…. 저는 최적화가 안되고 Insert, Delete 쿼리가 다 DB로 날라가는 로그가 찍히는데 왜그런건가요?A.
쿼리 최적화를 발생시키기 위해서는 아래 3가지를 확인
- 해당 함수나 클래스가 Transaction 안에 포함되고 있는지 확인
@Transactional으로 함께 감싸져 있어야만 쿼리 최적화가 동작한다.- Transaction 으로 포함되어있지 않으면 repository 메소드 내부에서만 Transcation 이 최적화된다.
- Transaction Propagation (전파) 전략 체크해봐야 한다. (심화 내용)
- 해당 엔티티의 ID 식별자 생성전략을
@GeneratedValue(strategy = GenerationType.IDENTITY)로 사용했는지 확인
GenerationType.IDENTITY로 키필드가 설정되어 있으면 데이터베이스에 실제로 저장을 해야 유일한 식별자를 구할 수 있으므로 Insert 쿼리가 즉시 데이터베이스에 전달된다.GenerationType.SEQUENCE로 설정 추천!!
이렇게하면 DB에select nextval('thread_seq')쿼리만 날아간다.GenerationType.AUTO로 설정해서 DB에서 선호하는 방식으로 자동적용시키는 방법도 있다.orphanRemoval()영속성 전이에 의해 자식의 삭제작업이 이루어지는건 아닌지 확인
- 이런경우 1차캐시 최적화가 아닌 삭제쿼리가 쓰기지연 저장소에 저장되어 동작하게 되므로 후처리로 발생하게 된다.
:: save() 를 수행했는데 Insert, Select 쿼리가...
Q.
나는 save() 만 수행했는데 Insert 쿼리전에 Select 쿼리가 자동으로 날라갔어요!!A.
ID(식별자 키)값이 존재하는 Entity를 save() 하면 업데이트할 필드가 있는지 확인하기 위해 Select 쿼리를 먼저 날려서 조회해온다.@Transactional @Override public <S extends T> S save(S entity) { Assert.notNull(entity, "Entity must not be null"); em.persist(entity); return entity; } else { return em.merge(entity); } }코드 실행 순서
- save(S) 메소드는 엔티티에 식별자 값이 없으면(null이면) 새로운 엔티티로 판단해서 EntityManager.persist를 호출하고,
- 2식별자 값이 있으면 이미 있는 엔티티로 판단해서 EntityManager.merge()를 호출
- EntityManager.merge() 를 수행할때 수정할 필드가 없는지 확인하기 위해 식별자 값을 가지고 Select 쿼리를 먼저 날려서 조회 해오고,
- 조회된 필드들을 엔티티와 비교해서 수정된 사항이 있으면 UPDATE 쿼리를 날리고, 모든 필드가 같으면 아무 쿼리도 날리지 않음
즉, save() 시 값 없으면 EntityManager.persist 값 있으면 EntityManager.merge()
merge() 시 수정할 필드 확인 위해 select 날려 조회,
비교 후 수정할 거 있으면 update 슝, 없으면 끝
:: Test 클래스에 @ 이 너무 많음..
Q.
JPA 테스트할때 Test 클래스에 붙이는 어노테이션들이 다 달라서 헷갈리고 이해가 안돼요.A.
JPA 관련 Test 클래스에 붙이는 어노테이션들은 크게 2가지 테스트 목적에 따라 다르다.Spring 통합 테스트 vs JPA 슬라이스 테스트
- JPA 슬라이스 테스트 추천
Spring 통합 테스트 단점
- 실제 구동되는 애플리케이션의 설정, 모든
Bean을 로드하기 때문에 시간이 오래걸리고 무겁다.- 테스트 단위가 크기 때문에 디버깅이 어려운 편이다.
- 결과적으로 웹을 실행시키지 않고 테스트 코드를 통해 빠른 피드백을 받을 수 있다는 장점이 희석된다.
어노테이션 비교 (통합 vs 슬라이스)
Spring 전체 빈 을 사용해야하는 Spring 통합 테스트
@SpringBootTest // SpringApplication 띄울때의 빈들을 모두 생성해줍니다. @Transactional // 테스트 메소드들이 모두 트랜잭션에 포함되어 최적화 되도록 합니다. // 테스트 대상 함수의 실행환경에서는 Transaction이 안걸려 있을 수 있으니 실무에 사용시 주의 @Rollback(value = false) // 테스트 데이터가 롤백되지 않고 실제 DB에 반영되도록 합니다.JPA 관련 빈 만 사용하는 JPA 슬라이스 테스트
@DataJpaTest // SpringDataJpa 테스트에 필요한 빈들만 생성해줍니다. @Transactional // 테스트 메소드들이 모두 트랜잭션에 포함되어 최적화 되도록 합니다. // 테스트 대상 함수의 실행환경에서는 Transaction이 안걸려 있을 수 있으니 실무에 사용시 주의 @AutoConfigureTestDatabase(replace = AutoConfigureTestDatabase.Replace.NONE) // 테스트 용 DB를 따로 설정하지 않고 main 환경 DB를 그대로 사용하도록 합니다. @Import(JPAConfiguration.class) // JPAQueryFactory와 같이 테스트시 필요한 빈들을 정의해놓은 Configuration 설정합니다. @Rollback(value = false) // 테스트 데이터가 롤백되지 않고 실제 DB에 반영되도록 합니다.
:: JpaRepository<>는 상속받은 인터페이스의 구현체를 만들어서 DI되는게 맞나요?
Q.
지금 리파지토리를 원하는 기능을 추가해서 사용하는 부분을 다시 보고 있는데요
여기도 보시면 MyRepository를 인터페이스로 만들고 메소드를 정의해 놓은 상태에서
MyRepositoryImpl 만들어 인터페이스를 구현해서 엔티티 매니저 객체를 통해 persist(), remove()등이 이뤄지잖아요!
이걸로 봤을 때 현재 저희가 사용하는 extends JpaRepository<>는 @SpringBootAplication을 통해 상속받은 인터페이스의 구현체를 만들어서 DI되는게 맞나요?근본적인 궁금증이 어떻게 JpaRepository<>를 상속한 인터페이스 Repsitory하나만으로 Persist(), flush(), remove()
A.
JpaRepository 의 모든 기능들은 Spring-Data-Jpa 의존성을 추가한 상태에서 @SpringBootAplication 이 해당 라이브러리를 인식하고 인터페이스에 선언된 메소드들이 구현된 클래스 빈을 주입시켜 줍니다.
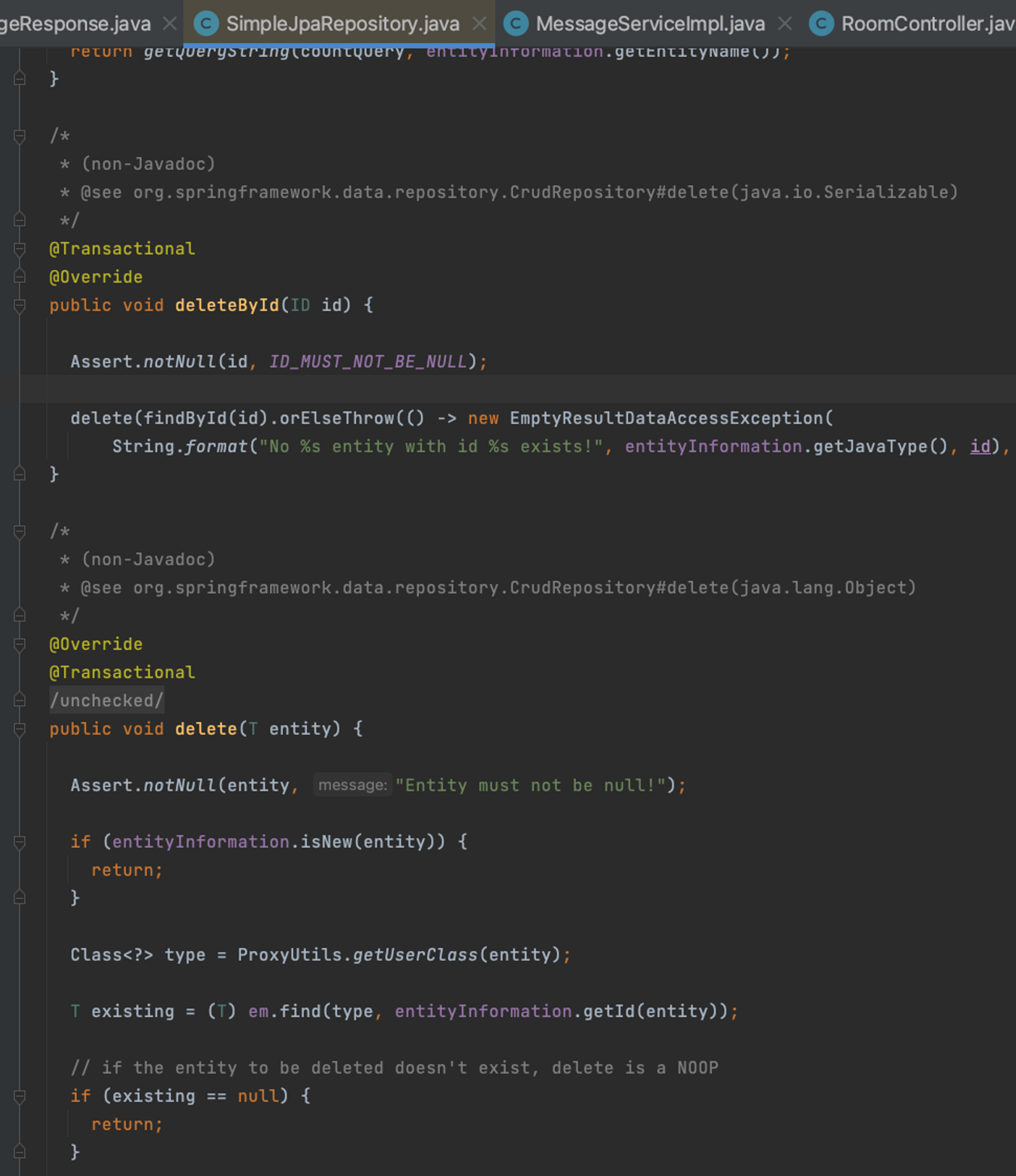
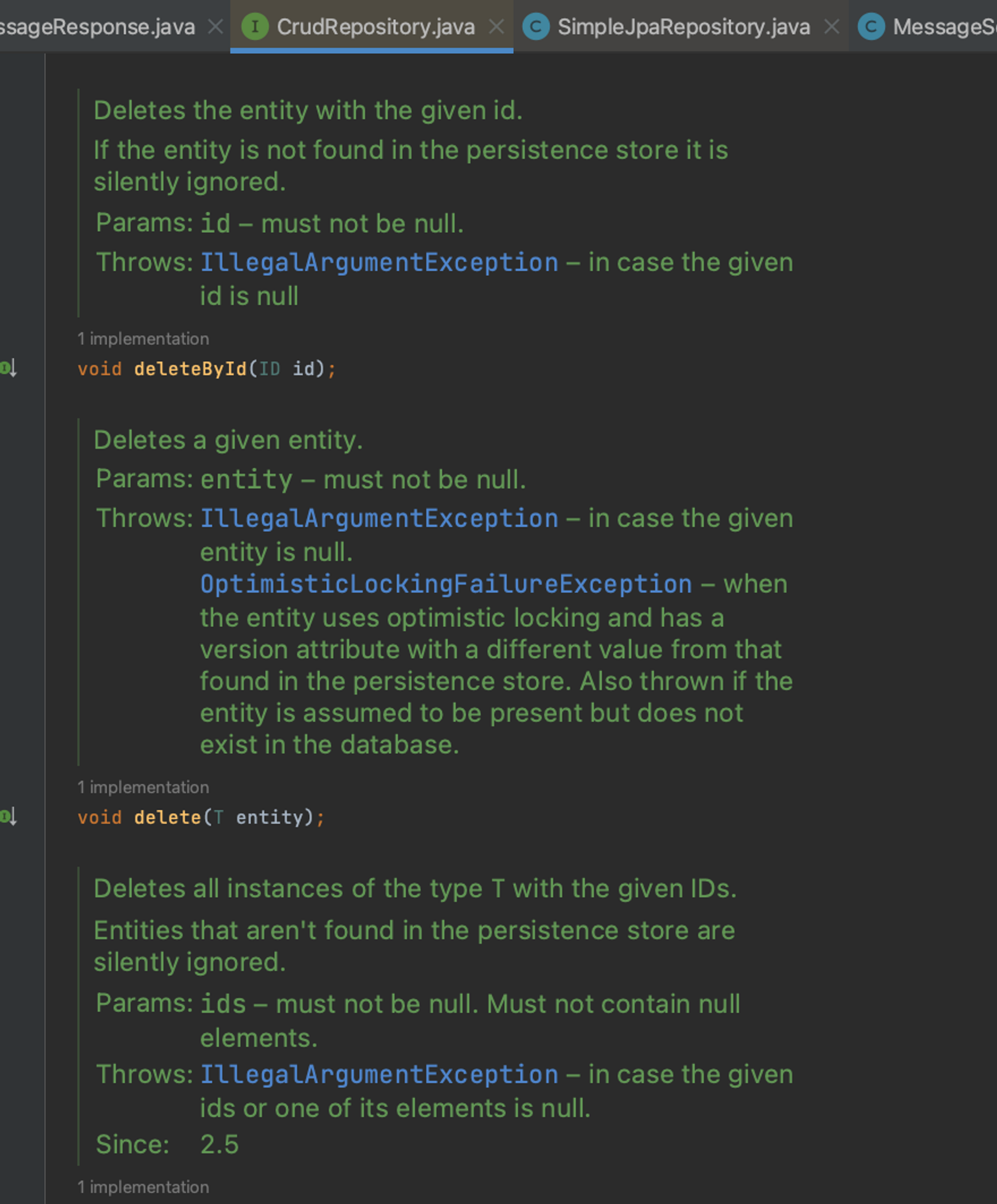
- persist() , flush(), remove() JpaRepository
- findAll(), delete() CRUDRepsoitory
:: 쿼리dsl을 갑작스럽게 사용을 중지 해야 한다던가 마이바티스로 전환해야 할 경우
Q.
이 질문의 시발점은 쿼리 dsl공부하다가 만약 쿼리dsl을 갑작스럽게 사용을 중지 해야 한다던가 마이바티스로 전환해야 할 경우를 생각 했는데요. 승민튜터님은 내가 개발할땐 최대한 그렇게 개발중이고 다른사람들한테도 이걸 최대한 써달라라고 말씀을 드리고 있다고 하셔서 보여주셨는데(어댑터패턴) 그렇게되면 저희가 외부라이브러리를 쓰는 편리함과 코드의 가독성 ? 쓰는데 활용되는 자원절약등이 있지만 분명 제일 중요한 안정성을 버린다고 생각을 했습니다. 그래서 분명 기업에선 제일중요한 안정성을 버리면 안되지만 그렇다고 일어나기 희박한 일들까지 너무 신경쓰면 죽도밥도 안되니 그 타협점이 어딜까 생각을 하게 됐습니다.A.
실제로도 많은 회사들이 지금도 하고 있는 고민이기도 하구
개발리더들이 그런 최종결정을 해주는게 그들의 역할이라고 생각하지만
물론 개발리더가 아닌 개발자라도 그런 고민을 하는 팀이 성공하는 팀이라고 생각합니다.먼저 가장 좋은건 예방!
1. 그 기술의 사용이 갑자기 중지될 가능성이 있는지에 대해서 확률적으로 가정적 예측할 수 있어야 한다.
2. 요거는 그 기술의 내부동작을 히스토리를 얼마나 잘 이해하고 있느냐에 따라 확률이 올라감그다음은 이슈가 발생했을때 빠른 전환이 중요!!
1. 그 기술의 사용이 중지되었을때 대체할 수 있는 기술을 빠르게 찾아서 대체할 수 있어야 합니다.
2. 요거는 내가쓰는 기술외에도 다른 대체재 기술에 대해서도 비교분석할 수 있느냐에 따라 전환시간이 단축된다.결론
- 프로젝트에서 기술을 적용할때는 내부동작을 이해하고 어떤 리스크가 있는지 인지한 상태에서 최선의 선택으로 적용해야하며
- 프로젝트에서 사용중인 기술의 대체재 기술에 대해서 같이 공부하고 검토할 줄 알아야 한다.
:: @EntityGraph 외 join을 사용할 시 fetch join을 사용하나요?
Q.
@EntityGraph은 left join로 나가던데 실무에서는 간단한 left join 사용시에만 @EntityGraph를 사용하고 그 외 join을 사용할 시 fetch join을 사용하나요?A.
Message → Inboxes. 구조일때 (FetchType=LAZY)List<Message> findByMessageId(); // Inboxes 가 LAZY 상태 @EntityGraph(attributes={"inboxes"}) List<Message> findWithInboxesByMessageId() // Inboxes 조인되어서 받아온다.그외에 fetch join 을 사용하는데 대부분의 케이스에서 사용한다면 fetchType=EAGER 로
:: em.merge() 호출시 어떤 일이 일어나나요?
Q.
entity를 업데이트 시 기본적으로 dirty checking으로 업데이트를 하는데 여기서 save() 메소드를 호출하면 isNew()가 아니므로 em.merge()를 호출하게 됩니다. 그러면 어떤 일이 일어나나요?(update 시 save를 사용하면 발생하는 문제점?)A.
ID로 DB 조회해와서 필드값들을 비교한다음 변경사항이 있으면 update 하고 없으면 아무동작이 수행되지 않는다.
트랜잭션의 격리 수준(isolation Level)이란?
:: 그 외 질문
Q.
심화반 강의 자료에"아래의 행위를 해주지 않는다면 db에 쿼리가 날라가지 않아 db에 반영이 바로 되지 않음을 꼭 기억!
- entityManager에서 flush를 해준다. (XXXrepository.save() , saveAndFlush )"
라고 되어있는데 saveAndFlush()는 내부에서 em.flush()를 호출하지만 save()는 flush()를 호출하지 않는데 예시에 포함되지 않는게 맞지 않나요?
Q.
@Repository는 @Component + 여러 Data Access 예외를 스프링 공통 예외로 변경해주는 기능이 추가되어 있는 것으로 알고 있습니다. @EnableJpaRepositories로 스캔해서 빈으로 등록을 해주는 것은 알겠는데 예외 변환 기능은 어떻게 처리해주는지 궁금합니다.
Q.
JpaRepository 부터 상위 인터페이스를 보면@NoRepositoryBean이 붙어 있는데 이 어노테이션의 정확한 역할이 궁금합니다.(-> 스프링 부트에 디폴트로 설정되어있는 @EnableJpaRepositories의 JpaRepositoriesRegisterar가 JpaRepository 및 JpaRepository를 구현한 인터페이스를 스캔하여 SimpleRepository와 같은 객체를 프록시로 동적 생성해서 빈으로 등록해 주는데 예를 들어 @NoRepositoryBean가 없을 경우 JpaRepository를 상속 받으면 내가 생성한 Repository + JpaRepository까지 빈으로 등록하려 하기 때문에 불필요한 빈 등록을 막으려고 사용한다?->public interface TeamRepository<T, ID> extends JpaRepository<T, ID>public interface TeamRepositoryExtends extends TeamRepository<Team, Long>와 같이 사용하면 BeanCreationException: Error creating bean with name 'teamRepository'-> 예외가 왜 터지는지 모르겠습니다..-> @NoRepositoryBean을 붙여주면 정상 동작)Q. MySQL은 Sequence를 지원하지 않고 기본 키 전략이 Identity이다. Sequence를 지원하는 타 DB에 비해서 insert 성능이 떨어질 것 같은데 실무에서는 어떤 방식을 사용하나요? Table 방식을 사용하나요?
