Kafka
- 고성능 분산 이벤트 스트리밍 플랫폼
- pub-sub 모델의 메시지 큐 형태로 동작
- 모든 이벤트 / 데이터의 흐름을 중앙에서 관리
- 새로운 서비스 / 시스템 추가되도 카프카가 제공하는 표준 포맷으로 연결하면 됨 (확장성과 신뢰성 증가)
- 각 서비스간의 연결이 아닌, 서비스들의 비느니스 로직에 집중이 가능해짐
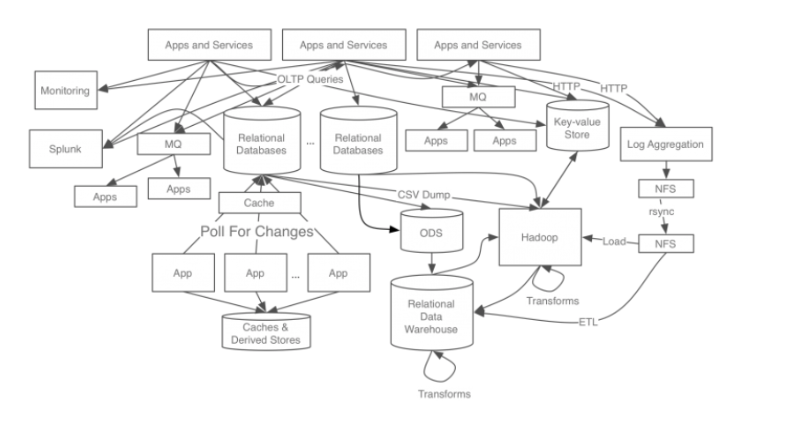
카프카 적용 전 데이터 처리 시스템
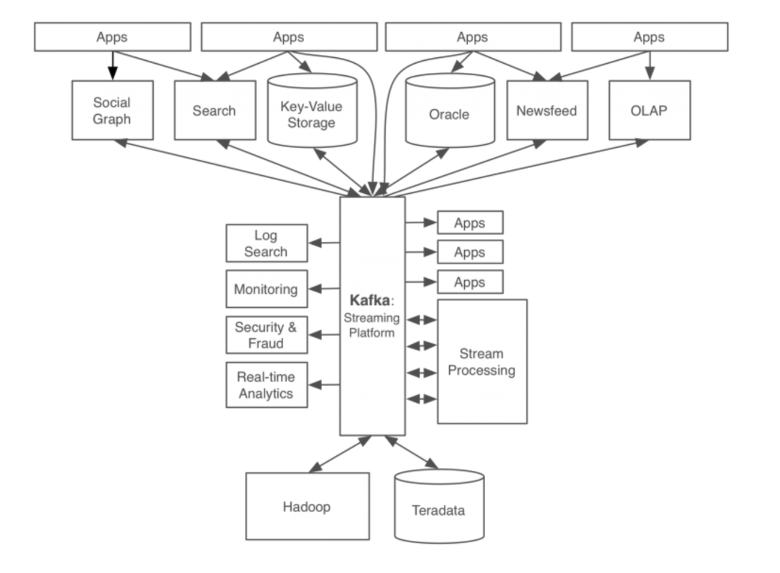
카프카 적용 후 데이터 처리 시스템
Kafka를 활용하는 경우
- 서비스 결합도를 낮추기 위해
- 모든 데이터를 한곳에 집중할 때 유리
ex) 로그통합, 실시간 접속 분석, 서버 모니터링- 실시간 스트리밍 서비스에 적합
ex) 알림 전송- 대규모 서비스와 배치 시스템에 적합
- 트래픽의 변화가 큰 곳에서 유용
동작 방식 및 특징
- 메시지 큐 형태로 동작
- 메시지 큐 (Message Queue, MQ) : 프로세스 간의 데이터 교환할 때 사용하는 기술
- 디스크에 메시지 저장하여 영속성을 보장
- producer 와 consumer 모두 배치 처리 가능해 네트워크 오버헤드 줄일 수 있음
- 높은 성능과 고가용성, 확장성
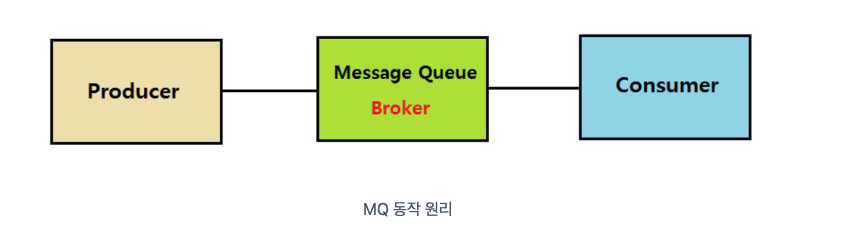
- producer : 정보 제공자
- consumer : 정보 제공받아 사용하는 자
- Queue : producer의 데이터를 임시 저장 및 consumer에 제공
MQ에서 메시지는 Endpoint 간에 직접 통신이 아닌 중간에 Queue를 통해 중개된다.
구성요소
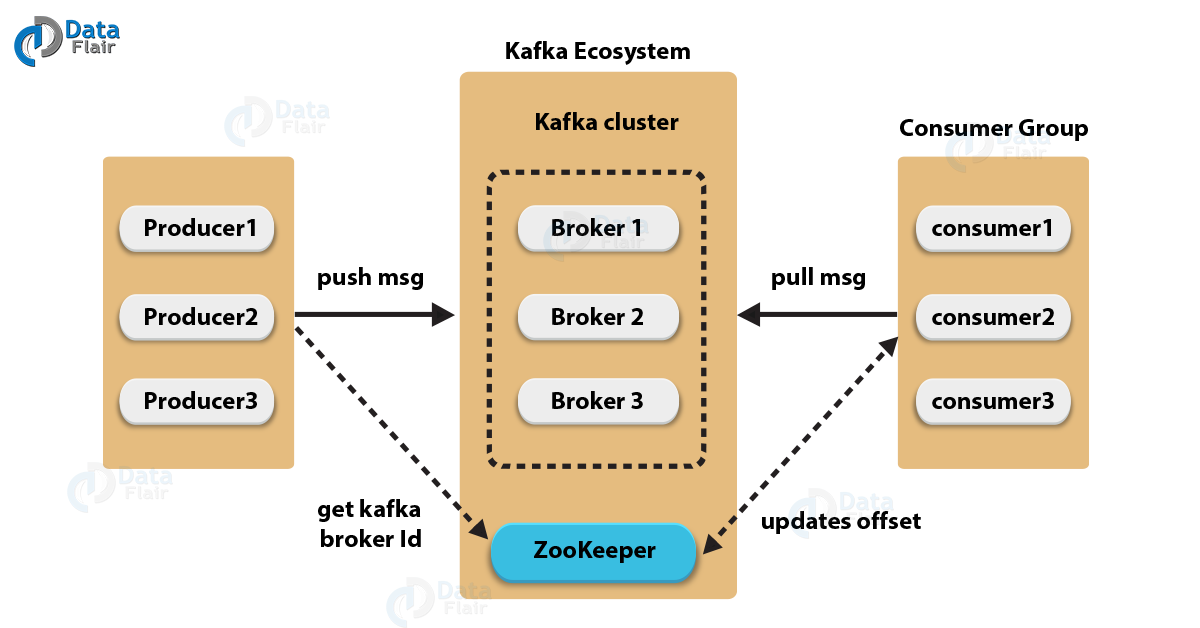
-
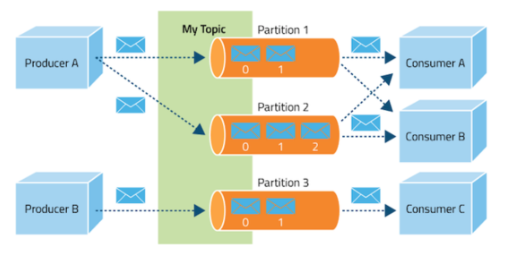
Topic
- 메시지 목적에 맞게 구분할 때 사용
- 메시지 전송 또는 소비할 때 Topic 반드시 입력
- consumer는 자신이 담당하는 topic의 메시지를 처리
- 하나의 토픽은 하나 이상의 파티션으로 구성
-
Partition
- 분산 처리
- topic 생성 시 partition 개수 지정 가능
(파티션 개수 변경 가능. 추가만) - 파티션 1개라면 모든 메시지에 대해 순서 보장
- 파티션 내부에서 메시지는 고유번호(offset)로 구분
- 여러개의 브로커에 걸쳐서 저장
- 파티션이 여러개라면 순서 보장 x
- 파티션이 많을수록 처리량은 좋지만 장애 복구 시간은 늘어남
-
Producer
- 메시지 만들어 카프카 클러스터에 전송
- 메시지 전송 시 batch 처리 가능
- key 값을 지정하여 특정 파티션으로만 전송 가능
- 전송 acks 값 설정하여 효율성 높일 수 있음
-
Consumer
- 카프카 클러스터에서 메시지 읽어서 처리
- 메시지를 batch 처리 할 수 있음
- 하나의 컨슈머는 여러개의 토픽 처리 가능
- 메시지를 소비하여도 삭제는 하지 않음
- 한번 저장된 메시지 여러번 소비 가능
- 컨슈머는 컨슈머 그룹에 속함
- 하나의 파티션은 같은 컨슈머그룹의 여러개의 컨슈머에서 연결할 수 없음
-
Broker
- 실행된 카프카 서버
- 브로커 == 카프카
- 서버 내부에 메시지 저장하고 관리
- 실행된 카프카 서버
-
Zookeeper
- 분산 애플리케이션 관리를 위한 코디네이션 시스템
- 중앙에서 관리하는 역할
