0. Load Test 종류
Load test types | Grafana k6 documentation
포스트 내용에 앞서, 부하 테스트이 종류만 잠깐 언급하고 넘어가도록 하겠다.
각각의 목적에 따라 여러 테스트 방식이 존재한다.
Smoke test- 스크립트의 작동 및 적은 부하에서 시스템이 잘 작동하는지 검증하는 용도
Average-load test- 평균적인 조건에서 시스템이 어떻게 동작하는지 평가
Stress test- 예상된 범위를 벗어나 한계치에 도달했을 때 시스템이 어떻게 동작하는지 평가
Soak test- 장기간에 걸쳐 시스템의 안정성과 퍼포먼스를 평가
Spike test- 갑작스럽게 순간적으로 거대한 트래픽이 몰리는 상황에서 시스템의 동작이 멈추지 않는지 검증
Breakpoint test- 점진적으로 부하를 늘려, 시스템의 한계 성능을 테스트
1. 간단한 k6 breakpoint 부하 테스트 스크립트
간단히 잠깐 진행해본 breakpoint 부하 테스트 상세는 다음과 같다.
- 간단한 로그인 API 호출
- 에러의 비율은 1% 미만이어야 한다. 1%를 넘어가면 바로
abort하여 종료한다. p(99) < 1000즉 99%의 요청은 1초 이내로 수행되어야 한다sleep()을 따로 설정하지 않았다.
import http from 'k6/http';
import {check} from 'k6';
// define configuration
export const options = {
// define thresholds
thresholds: {
http_req_failed: [{threshold: 'rate<0.01', abortOnFail: true}], // http errors should be less than 1%, otherwise abort the test
http_req_duration: ['p(99)<1000'], // 99% of requests should be below 1s
},
scenarios: {
// arbitrary name of scenario
average_load: {
executor: 'ramping-vus',
startVUs: 0,
stages: [
// ramp up to average load of 20 virtual users
{duration: '10s', target: 20},
{duration: '50s', target: 20},
{duration: '50s', target: 40},
{duration: '50s', target: 60},
{duration: '50s', target: 80},
{duration: '50s', target: 100},
{duration: '50s', target: 120},
{duration: '50s', target: 140},
{duration: '50s', target: 160},
{duration: '50s', target: 180},
{duration: '50s', target: 200},
],
},
},
};
export default function () {
const url = 'http://{ip-address}:8080/api/v1/users/login';
const payload = JSON.stringify({
username: 'user',
password: 'pw',
});
const params = {
headers: {
'Content-Type': 'application/json',
},
};
// send a post request and save response as a variable
const res = http.post(url, payload, params);
// check that resopnse is 200
check(res, {
'response code was 200': (res) => res.status == 200,
});
}
2. DB 서버 메트릭 분석
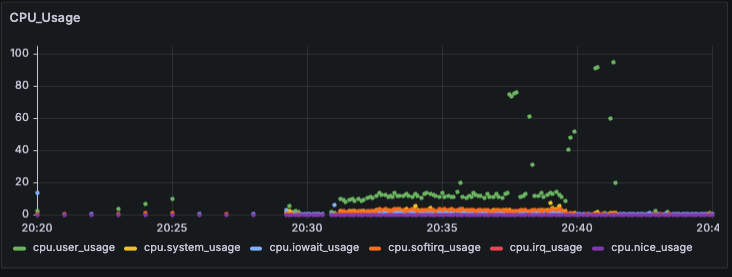
2-1. System CPU 점유율
단위는 총 점유율(%)을 나타낸다.
중간 중간 CPU 사용량이 100% 가까이 튀는 경우가 있는데, Grafana k6 대시보드에서 새로고침할 때 저렇게 스파이크가 일어난다.
대시보드를 새로고침하지 않을 때는 나머지 메트릭 포인트처럼 10~20%로 안정적인 모습을 보이는 것을 고려하면, k6에서 InfluxDB로 데이터를 전송하는 것의 오버헤드는 크게 작용하지 않는 것으로 판단된다.
대시보드를 시각화하는 그래픽 작업 비용이 꽤나 크게 작용하는 것이 아닐까?
그렇다면 대시보드를 부하 테스트 완료 후에 확인하면 해당 부하는 발생하기 않기 때문에 상관 없을 것 같다.
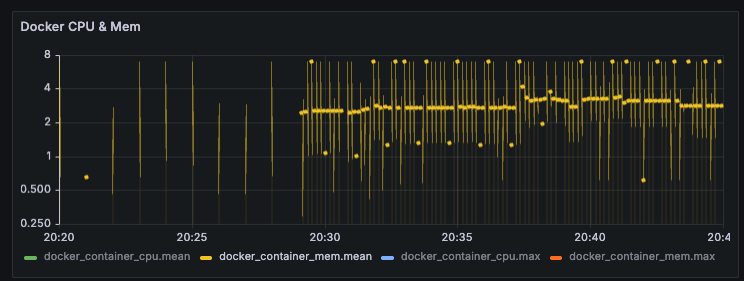
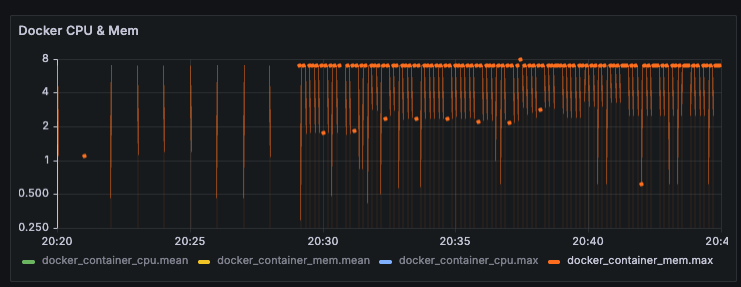
2-2. Docker Memory 사용량
메모리의 경우 GB 단위로 사용량을 나타난다. iMac은 총 8GB 메모리를 가지고 있다.
평균값도 종종 8까지 튀고, max값을 대부분의 경우 8로 고정되어 있다.
간단한 로그인 API를 호출하면서 VU가 0~200까지 점진적 증가하는 가벼운 breakpoint 테스트였는데, 역시 로직 자체가 조회 쿼리 1개만 날아가는 간단한 로직이어서 VU가 증가해도 매트릭에는 별 차이가 나타나지 않은 것 같다.
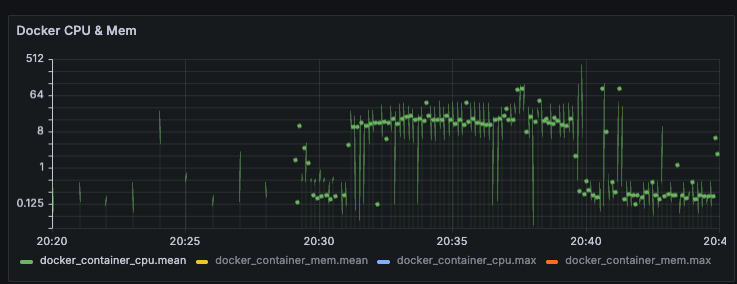
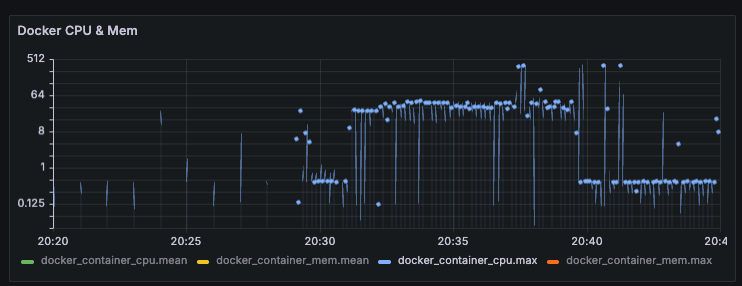
2-3. Docker CPU 점유율
시스템 CPU 메트릭과 도커 컨테이너의 CPU 메트릭을 각각 불러올 수 있길래, 유의미한 차이가 존재하는지 확인차 메트릭을 가져와 봤다.
일단 시스템 CPU 메트릭과 달리, CPU 1개당 0~100%로 계산하여 합산 점유율을 보여주는 것 같다. (iMac은 쿼드코어)
튀는 값을 제외하면 대부분 약 35% 정도의 값을 유지하고 있는데, 35% / 4 = 8.75%가 나온다.
즉 전체 CPU 리소스의 8.75% 점유율은 유지하는 것이다.
아마도 컨테이너 외 OS나 다른 점유율을 더한다면 위에서 살펴본 System CPU와 같은 점유율이 나올 것이라 생각된다.
3. K6 메트릭 분석
3-1. 메트릭 종류
http_req_blocked- 요청을 보내기 전, TCP 커넥션 슬롯을 얻기 위해 기다린 시간
http_req_connecting- 서버로의 TCP 연결을 establish하는 데 소요된 시간
http_req_duration- 서버에 요청을 보내고 응답을 받기까지의 총 시간
- http_req_sending + http_req_waiting + http_req_receiving 과 같음
- DNS lookup, connection 시간은 제외
http_req_failed- 실패 비율
http_req_receivinge- 원격 호스트로부터 응답 데이터를 받는데 소요되는 시간
http_req_sending- 원격 호스트에 데이터를 보내는데 소요되는 시간
http_req_tls_handshaking- TLS 세션 핸드셰이킹에 소요되는 시간
http_req_waiting- 원격 호스트로부터 응답을 받기까지 소요되는 시간
- 응답의 첫 바이트를 받을 때까지의 시간
http_reqs- k6가 요청한 총 HTTP 요청 개수
3-2. 각 메트릭 분석
VU, RPS
VU는 설정했던대로 0부터 200까지 올라가는 것을 확인할 수 있었다.
그리고 스크립트에서 따로 sleep() 함수로 유저의 RPS를 조정하지 않았었다.
그런데 VU가 30정도일 때부터 약 1000 RPS에 도달했고, 더이상 크게 오르지 않고 유지되는 양상을 띄었다.
즉, saturation point일 수도 있고 아직 부하가 충분하지 못하여 모두 처리되고 있는 상황일 수도 있다.
이는 추후 제대로 부하 테스트를 하면서 확인해보도록 하겠다.

만약 병목이 발생한 것이라면, 어디서 병목이 발생했을까?
일단 k6 툴을 동작시키는 맥북은 성능이 월등히 높기 때문에 후보에서 제외할 수 있을 것 같다.
의심되는 곳은 스프링 서버인 AWS EC2 인데, 그 이유를 다음과 같다.
- 하드웨어 리소스가 CPU 1개, RAM 1GB로 너무나 열악하다.
- 메트릭 수집은 하지 못했지만 테스트를 진행하며
htop으로 직접 모니터링 했었고, 리소스를 거의 모두 사용하면서 동작하고 있었다. - 반면 DB서버는 InfluxDB 쿼리를 요청할 경우를 제외하면 CPU 점유율도 10~20%를 유지했고, 메모리도 총 8GB 중 3~4GB를 사용하면서 안정적이었다.
따라서, 추후에 있을 부하 테스트를 통해 Saturation point를 파악하면서, EC2 서버의 병목을 주의깊게 관찰할 필요가 있을 것 같다.
http_req_duration
http_req_duration은 서버에 요청을 보내고 응답을 받기까지의 총 시간이다.
따라서, 사용자가 실질적으로 느끼는 응답시간에 해당할 것 같다.
max- 각 시간대별 가장 높게 측정된 응답시간이다.
p95- 95%에 해당하는 응답시간의 정도?를 나타내는 백분위수 지표이다.
- p95이 408ms이라는 것은 100개중 95개가 408ms 이하이고, 5개는 408ms보다 오래걸린다는 의미이다.
- 보통 SLO(서비스 수준 목표)를 설정할 때 백분위수를 사용하기 때문에, 중요한 지표이다.
p90- 마찬가지로 백분위수를 나타내는 지표이다.
min- 각 시간대별 가장 낮게 측정된 응답시간이다.
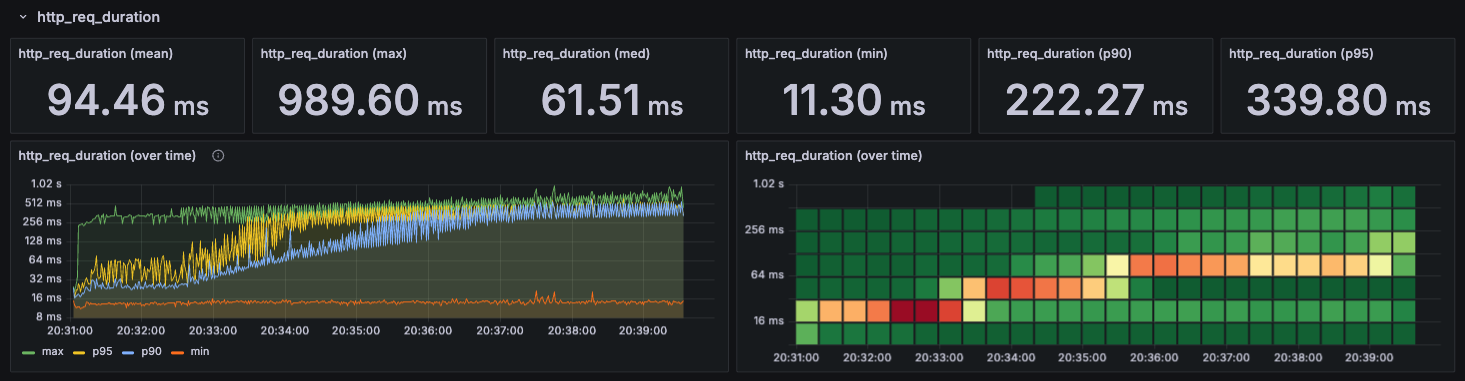
보다시피 min, max는 현재로써 유의미한 지표는 아니지만, 그래도 요청이 모두 1s 이내에 처리되었다는 것을 알 수 있다.
반면 p95, p90을 보면 점진적으로 증가하다가 300ms ~ 400ms 사이에서 유지되는 양상을 띤다.
이는 부하가 늘어나면서 점점 응답시간이 길어지는 것을 보여주는데, 무슨 이유에서인지 특정 지점부터는 증가하지 않고 유지되는 모습을 보인다.
현재 메트릭은 간단하게 돌려본 결과이기 때문에, 정확한 부하 테스트를 거친 결과로 나중에 다시 분석해보기로 하자.
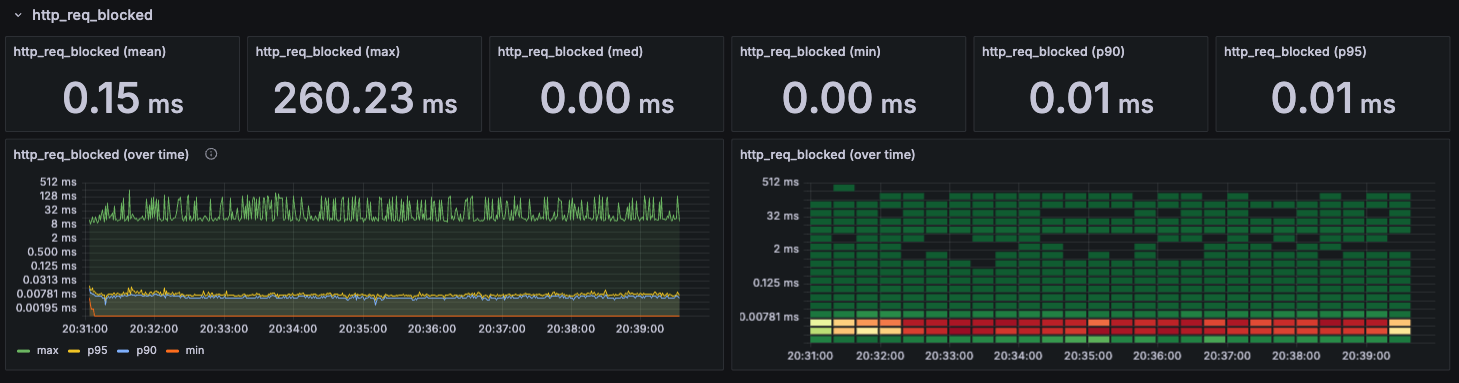
http_req_blocked
TCP 커넥션을 얻기 위해 대기하는 시간을 나타내며, 부하의 증가에도 일정하게 유지되는 것을 보아, 아직 병목 현상이 발생하지 않는 것을 확인할 수 있다.
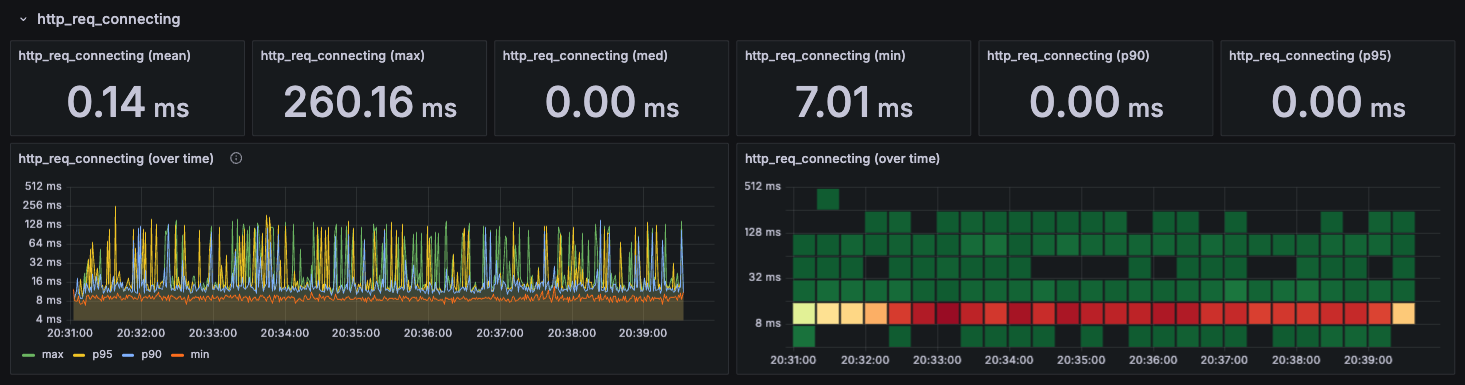
http_req_connecting
TCP 연결을 establish하는데 소요되는 시간이다.
종종 튀는 모습을 보이지만, 그래도 전체적으로 일정한 모습을 보이기 때문에 마찬가지로 병목이 발생하진 않는 것 같다.
http_req_looking_up
DNS에서 IP를 looking up하는 작업에서 소요되는 시간을 나타낸다.
DNS looking up 작업을 거치지 않기 때문에 데이터가 존재하지 않는다.
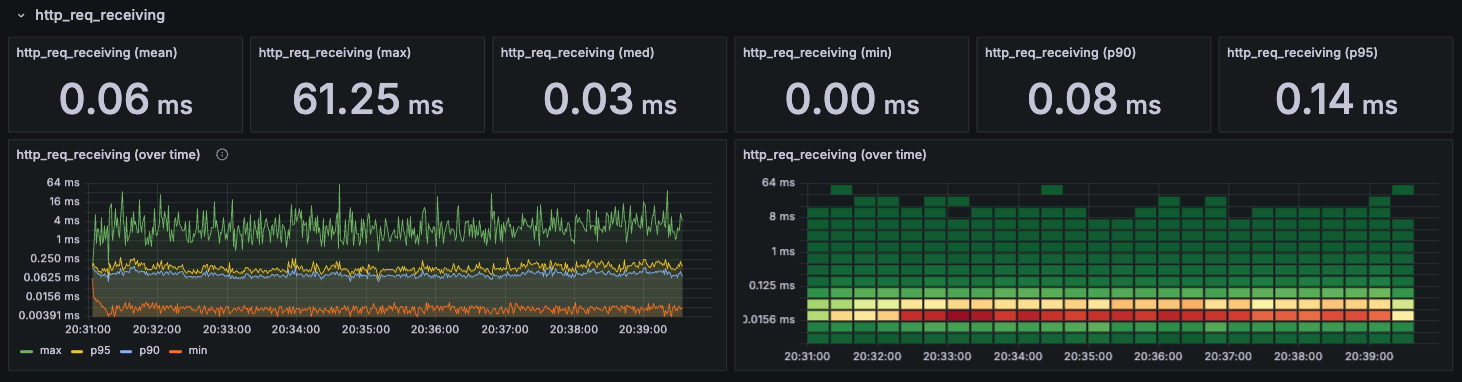
http_req_receiving
서버로부터 응답 데이터를 받는데 걸리는 시간이다.
단순한 로그인 API를 호출하기 때문에 받는 데이터도 크지 않다. 때문에 낮은 응답시간을 전체적으로 유지하는 모습을 확인할 수 있다.
receiving은 duration에 포함된다고 했었는데, 부하 증가에도 응답시간을 일정하게 유지하기 때문에 병목에 해당되지 않는다.
그렇다면 sending과 waiting 중에 병목이 존재할 것이라고 예상할 수 있다.
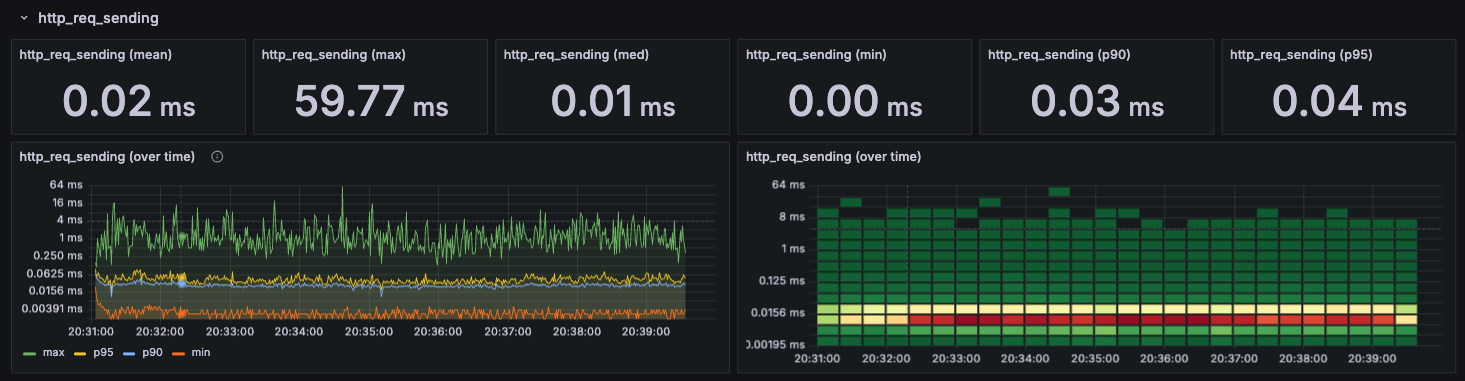
http_req_sending
요청 데이터를 보내는데 걸리는 시간이다.
receiving과 마찬가지로 낮은 응답시간과 전체적으로 일정한 모습을 확인할 수 있다.
따라서 여기도 병목이 아니다.
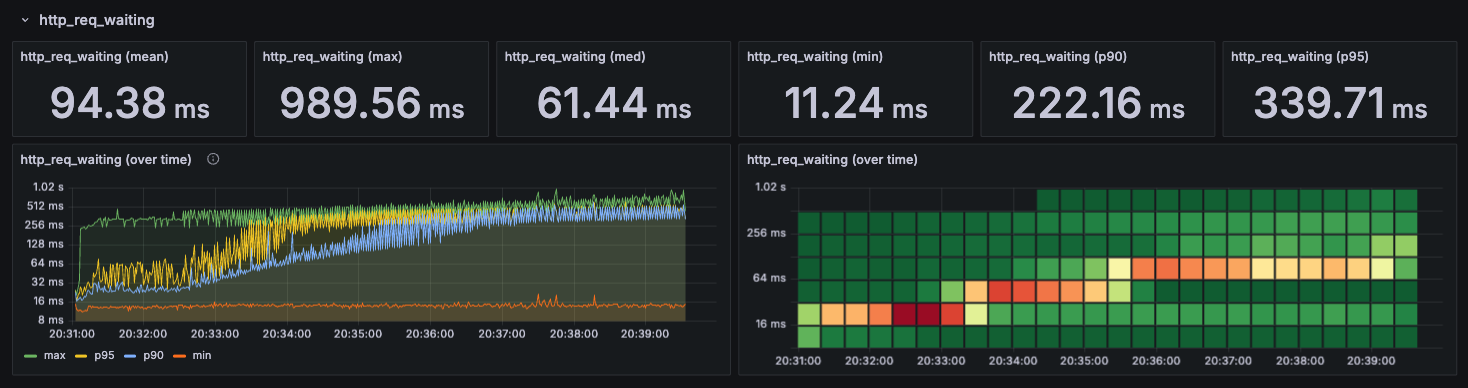
http_req_waiting
서버로 요청 전송을 완료한 시점부터 응답을 받기 시작한 시점까지의 대기 시간이다.
딱봐도 duration과 거의 동일한 모양의 그래프를 확인할 수 있다. 즉 병목은 서버에서 발생한다.
이미 예상했던 결과지만, 적어도 k6를 실행하는 맥북에서는 병목이 존재하지 않는다는 것은 확실해졌다.
서버에서 병목이 발생하는 것까지는 알겠는데, 그렇다면 스프링 서버와 DB 서버 중 어느 곳에서 병목이 발생할까?
아직 어떻게 확인할 수 있을지 확신이 들지는 않는다.
일단은 추후에 DBMS 메트릭을 수집해서 유의미한 지표를 찾아보는 것이 좋을 것 같다.
4. 스프링 서버(EC2) 리소스 사용률 저하 원인 분석
EC2는 기본적으로 몇가지 메트릭을 제공해주기도 하고 컴퓨팅 리소스도 열악한 관계로, 따로 Telegraf를 설치하지 않기로 했다.
AWS에서 제공해주는 모니터링 결과는 다음과 같다.
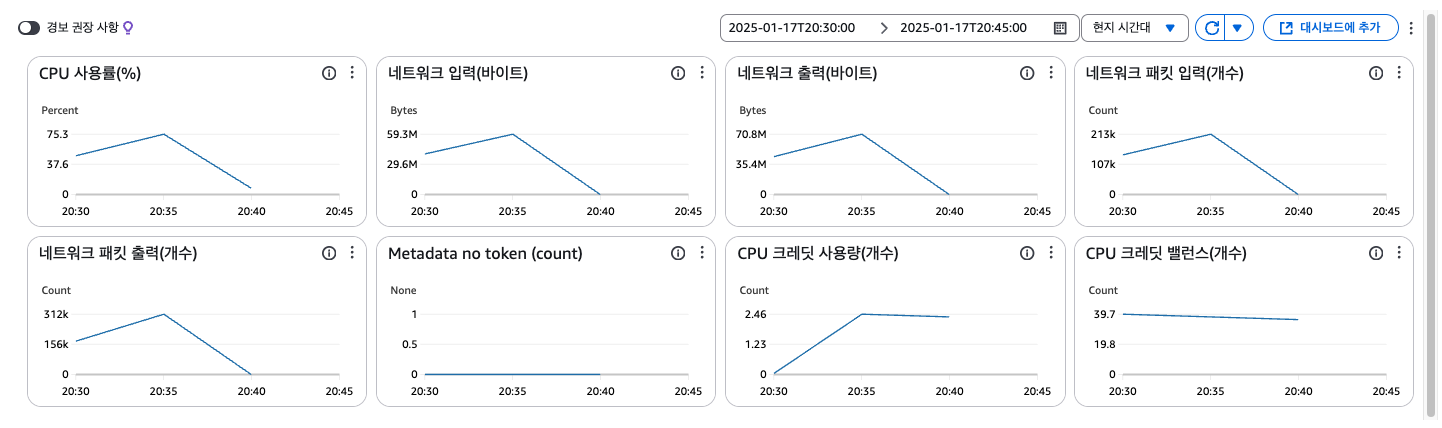
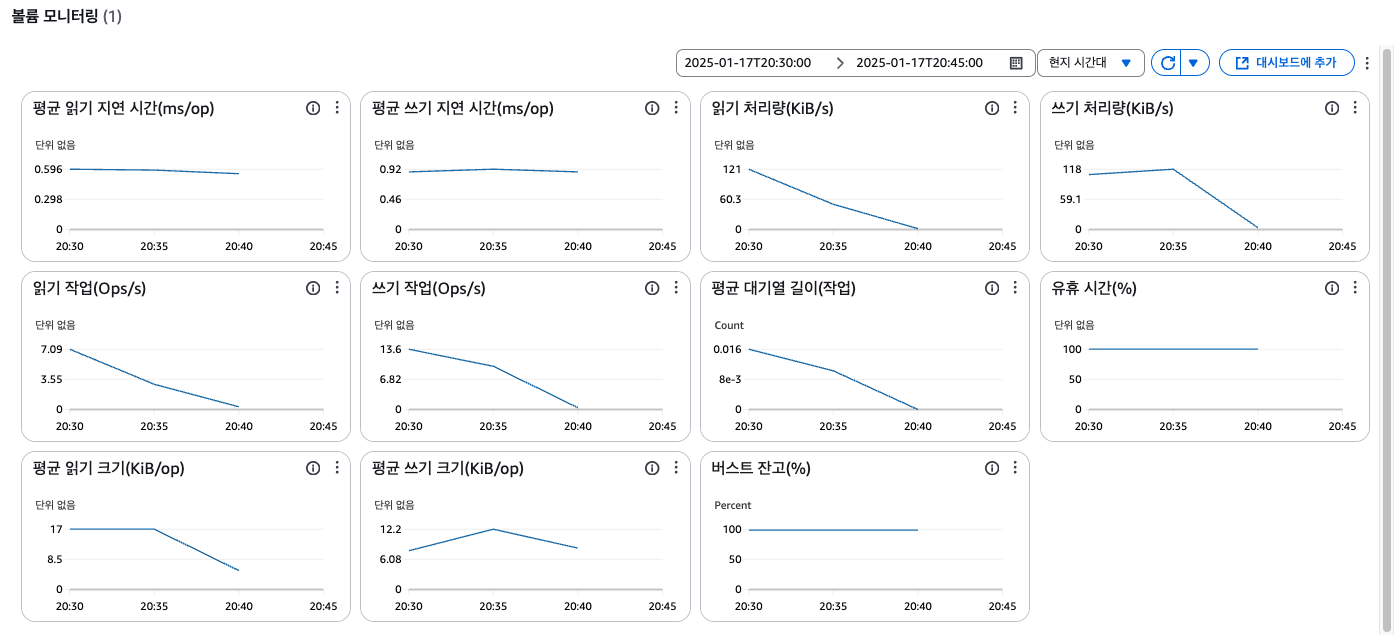
표에는 CPU 크레딧이라는 처음보는 메트릭이 존재했다.
정체가 무엇인지 설명도 읽고 찾아본결과, 기준 CPU 사용률 이상이 되면 보유한 크레딧을 소진할 때까지만 사용이 가능하고, 크레딧을 모두 소진하면 기준 사용률까지만 CPU를 사용할 수 있다고 한다.
모니터링을 시도해보면서 새로운 지식이 추가되는 순간이었다.
성능 테스트 모니터링에 있어서 CPU 크레딧이 중요하게 작용할 것이 분명하기 때문에, 따로 정리하면서 포스팅으로 남겨놓겠다.
진행했던 k6 부하 테스트는 20시 30분쯤 부터 8~9분정도 지속했다.
따라서, 적어도 32분~37분 사이는 부하가 증가하는 것이 확실한데, 메트릭을 보면 35분부터 확 꺾이는 모습을 보인다.
이해할 수 없는 이 현상을 파악하기 위해 몇가지 가설을 세워보았다.
- 성능 부족에 의해 k6 툴이 제대로 동작하지 않은 경우
- 로컬 캐싱에 의해 CPU 사용량이 줄어들었을 경우
- 내가 CPU 크레딧에 대해 잘못 이해하고 있을 경우
- 두 서버의 메트릭 데이터 시간이 상이한 경우
이제 각 가설에 대한 나의 결론을 정리해보겠다.
- 1번 가설 (X)
- DB 서버에서는 정확한 시간대에 부하가 들어온 것을 Grafana를 통해 확인할 수 있다.
- k6 툴을 작동시킨 맥북은 DB서버, 스프링 서버에 비해 성능이 월등히 높다.
- 이정도 이유만 해도 k6의 문제가 아니란 것은 알 수 있다.
- 2번 가설 (X)
- 현재 나의 지식으로는 로컬 캐싱에 의해 disk I/O 가 감소하면, CPU가 task 하나를 처리하는 속도가 증가하기 때문에 CPU 사용률이 감소할 수 있다고 생각한다.
- 그러나 네트워크 입출력은 감소할 이유가 전혀 없다. 캐시 hit가 발생하든 안하든 서버와의 요청과 응답은 바뀔리 없고, 데이터의 크기가 감소할리도 없다.
- 따라서, 로컬 캐싱에 의해 CPU 사용률이 감소할 순 있지만 이것이 주된 원인은 아니란 것이다. 그리고 저렇게 극단적으로 감소할리도 없다고 생각한다.
- 3번 가설 (X)
- 메트릭 종류를 살펴보면서 CPU 크레딧의 존재를 처음 인지했기 때문에, 크레딧 활용 미숙으로 CPU를 최대로 사용하지 못했을 수도 있다고 생각했다.
- 하지만 사용 가능한 크레딧 개수를 나타내는 CPU 크레딧 밸런스는 39에서 약간 감소했을 뿐, 모두 소진되지 않았다.
- 즉, 크레딧은 충분했기 때문에 CPU 사용률은 높게 유지할 수 있었을 것이다.
- CPU 크레딧 사용량이 35분부터 일정해진 것도 크레딧이 모두 소진 되어서가 아니라, 그냥 사용하지 않기 때문이었다. (사용률이 10% 이하였기 때문에)
- 4번 가설 (O)
- 나의 최종 결론은 DB + k6 메트릭과 스프링 서버의 메트릭 시간이 상이하다는 것이다.
- 두 서버에서
date명령어로 시간대를 확인했을 때는 동일했기에 설마했었는데, 이 문제가 아니면 설명이 되지 않는다. - 또한, 시간 범위를 늘려서 메트릭 그래프를 확인해보니 아래와 같은 양상을 띠었다.
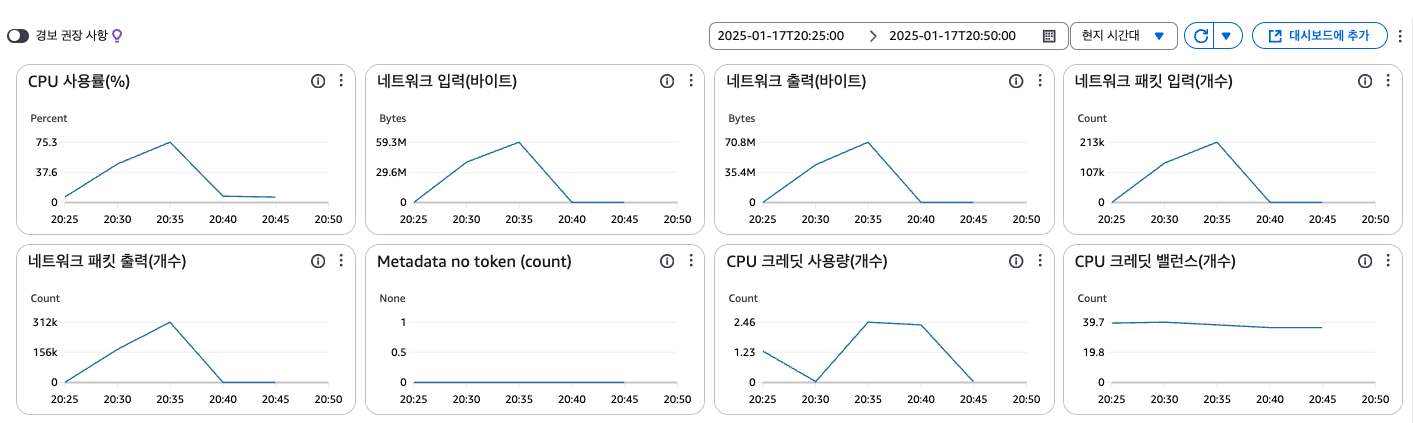
그러면 왜 처음부터 저 그래프 모양을 보고 의심하지 않았냐? 라고 한다면,
모니터링 경험의 부족도 이유일 수 있지만, EC2에 서버를 띄우는 동시에 바로 테스트를 진행하느라 서버를 띄우면서 발생했던 부하였을 것이라고 단정지었던 것이 문제라고 생각된다.
당연히 시간이 상이할 것이라 예상하지 못했기 때문에 20시 30분 이전의 메트릭은 그래프 범위에서 제외했었는데, 다시 확인해보니 서버 가동 시에 발생한 부하는 20시 15분 ~20시 24분 사이에 나타나 있었다.
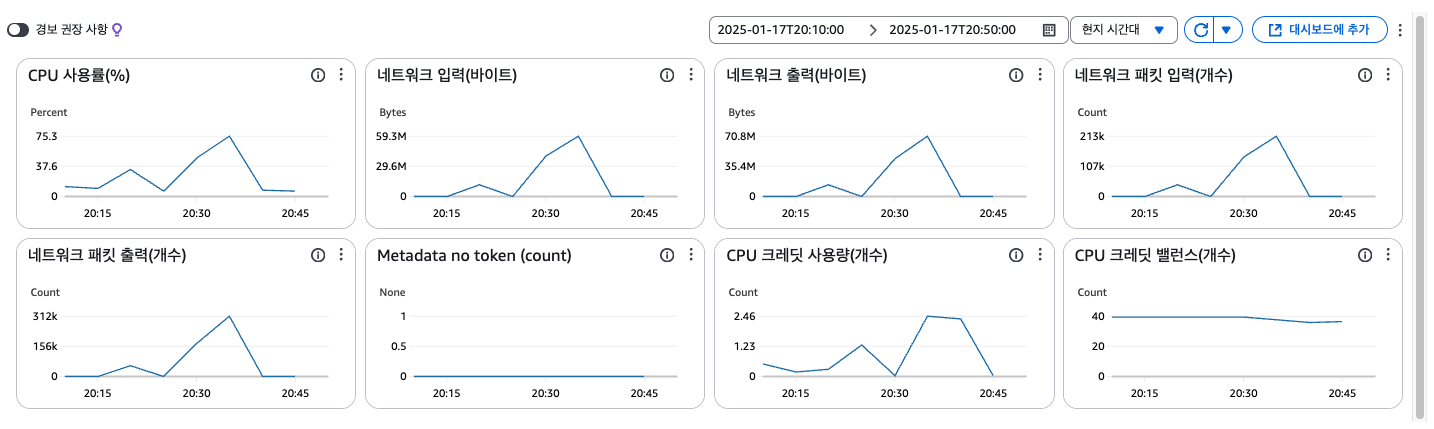
결국 두 메트릭의 시간이 다르다는 어이없는 문제가 원인이라는 나름 합리적인 의심으로 문제 상황을 해소했다.
(물론 내가 잘못 파악했을 수도 있다는 여지는 남겨둔 채 추후 모니터링을 할 예정이다.)
이제부터 제대로된 k6 스크립트를 작성하고 부하 테스트를 해보도록 하겠다.
