프림 알고리즘
가중치가 있는 무방향 그래프에서 최소 비용 신장 트리(= 최소 스패닝 트리; MST, Minimum Spanning Tree)를 구하는 그리디 알고리즘.
우선순위 큐(힙)를 사용하며, 다익스트라 알고리즘과 구현 방식이 유사함.
새로운 정점을 연결할 때마다 새로운 정점에서 갈 수 있는 아직 연결되지 않은 정점들에 대한 간선을 추가해줘야 함.
작동 방식
1) 임의의 정점을 선택하여 하나의 정점을 갖는 최초의 트리를 구성함.
2) 트리에 포함된 정점과 트리에 포함되지 않은 정점 간의 간선 중 가장 작은 가중치를 가지는 간선을 선택하여 트리에 추가함.
3) 모든 정점이 트리에 포함될 때까지 2를 반복함.
예제
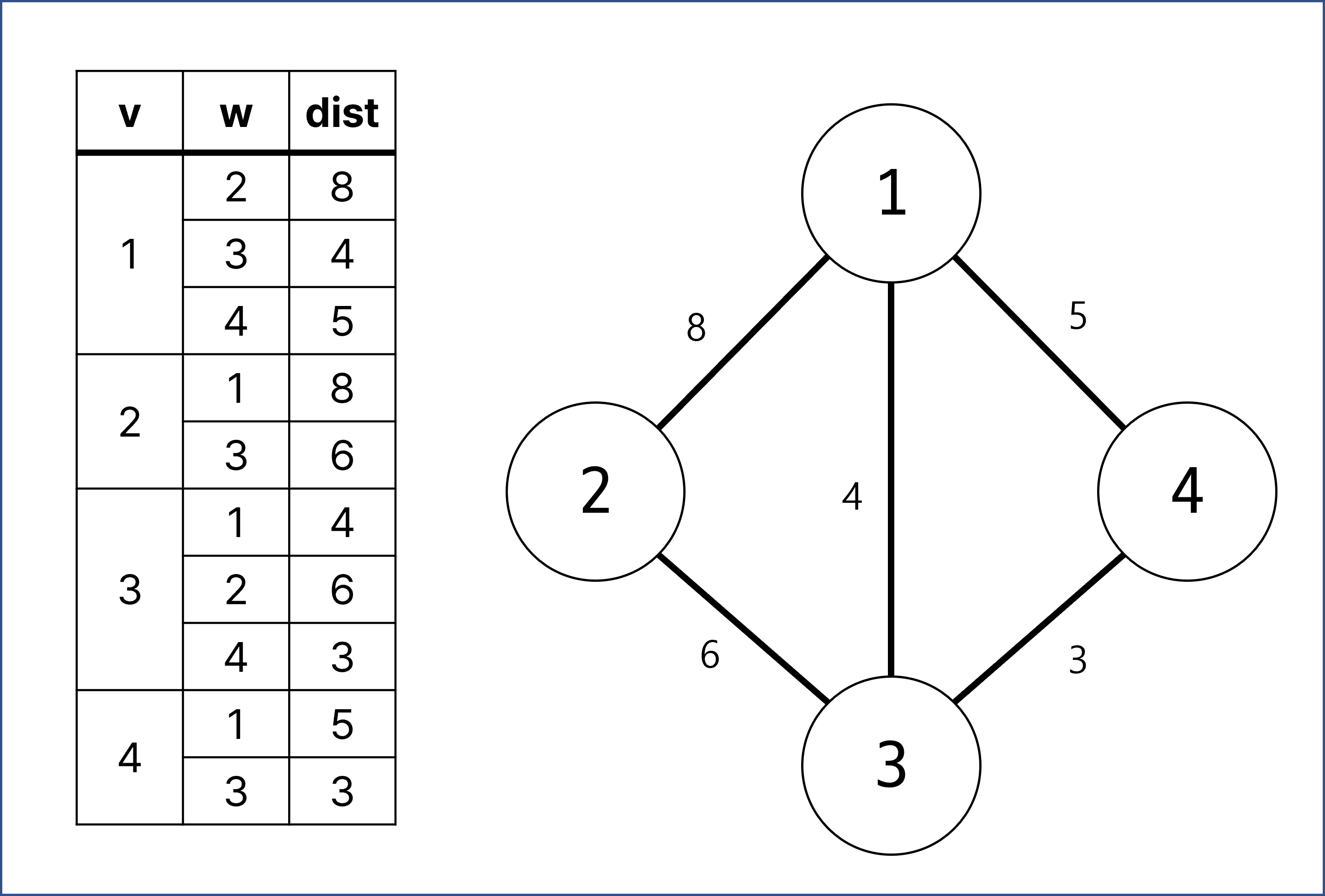
예를 들어 다음과 같은 가중치가 있는 무방향 그래프가 있다고 하자.
우선 우선 순위 큐에 w = 1, dist = 0 값을 넣어 값이 1인 정점부터 시작하도록 함.
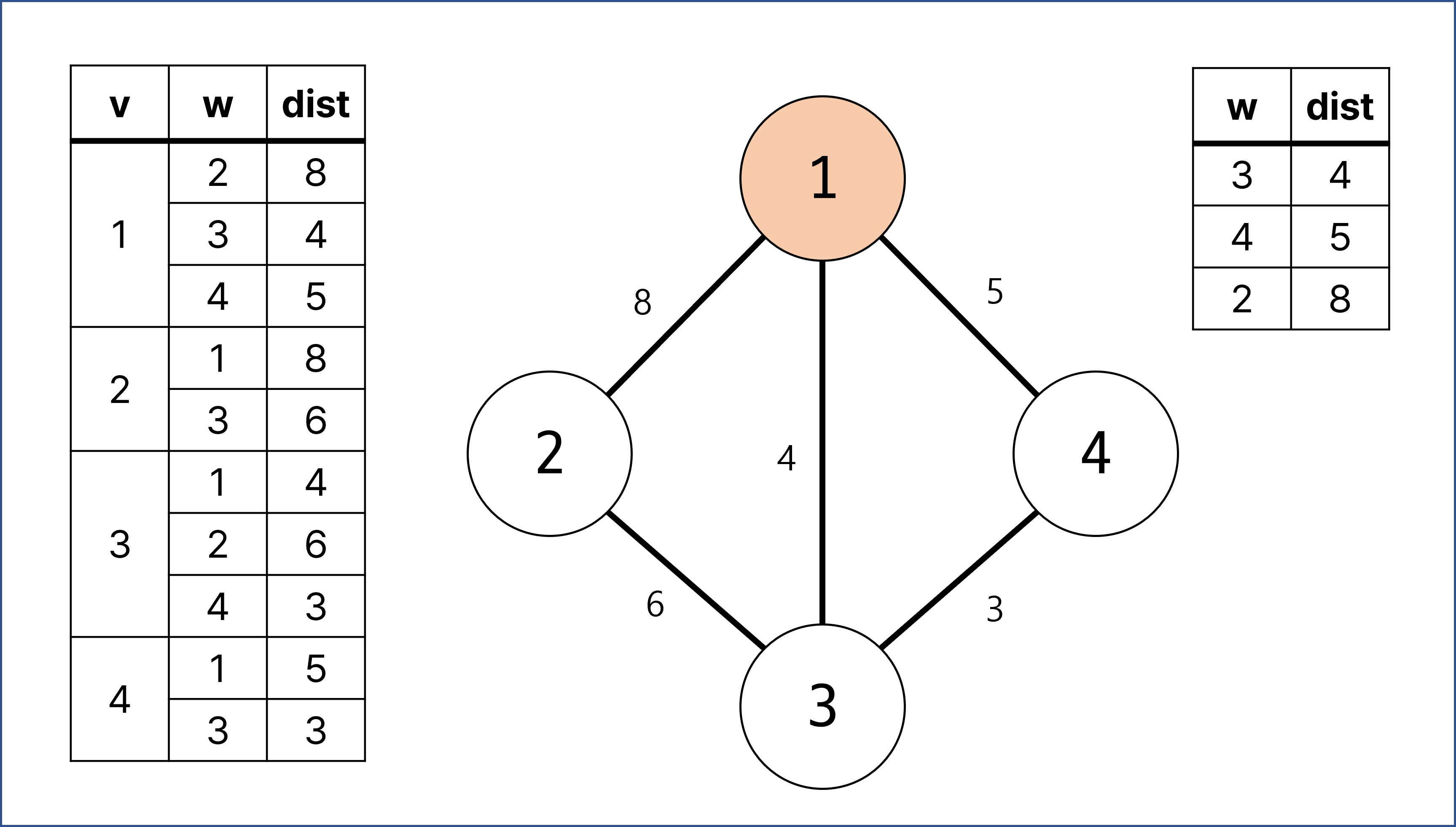
시작하는 정점에 방문 체크를 하고 난 후에 간선 검사를 실시함.
정점 1과 연결되어 있는 정점 2, 정점 3, 정점 4에 대한 간선을 우선 순위 큐에 넣음.
우선 순위 큐는 dist에 대해 오름차순으로 정렬되도록 해야 함.
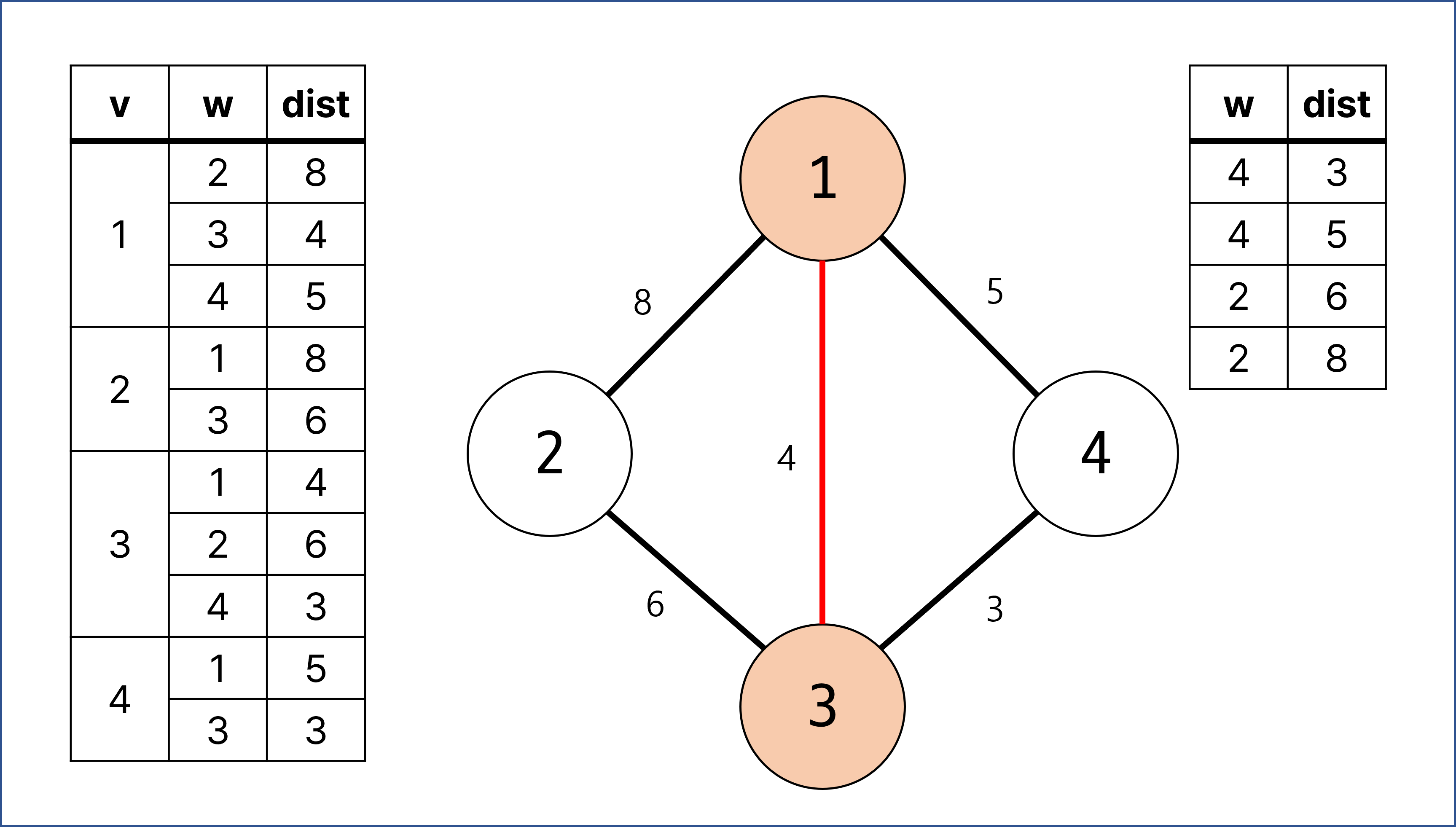
우선 순위 큐의 첫 번째에 있던 w = 3, dist = 4에 대한 계산이 이루어짐.
정점 3은 방문 체크를 해주고 3과 연결되어 있으면서 한 번도 방문하지 않은 간선 (2, 6), (4, 3)을 우선 순위 큐에 추가해줌.
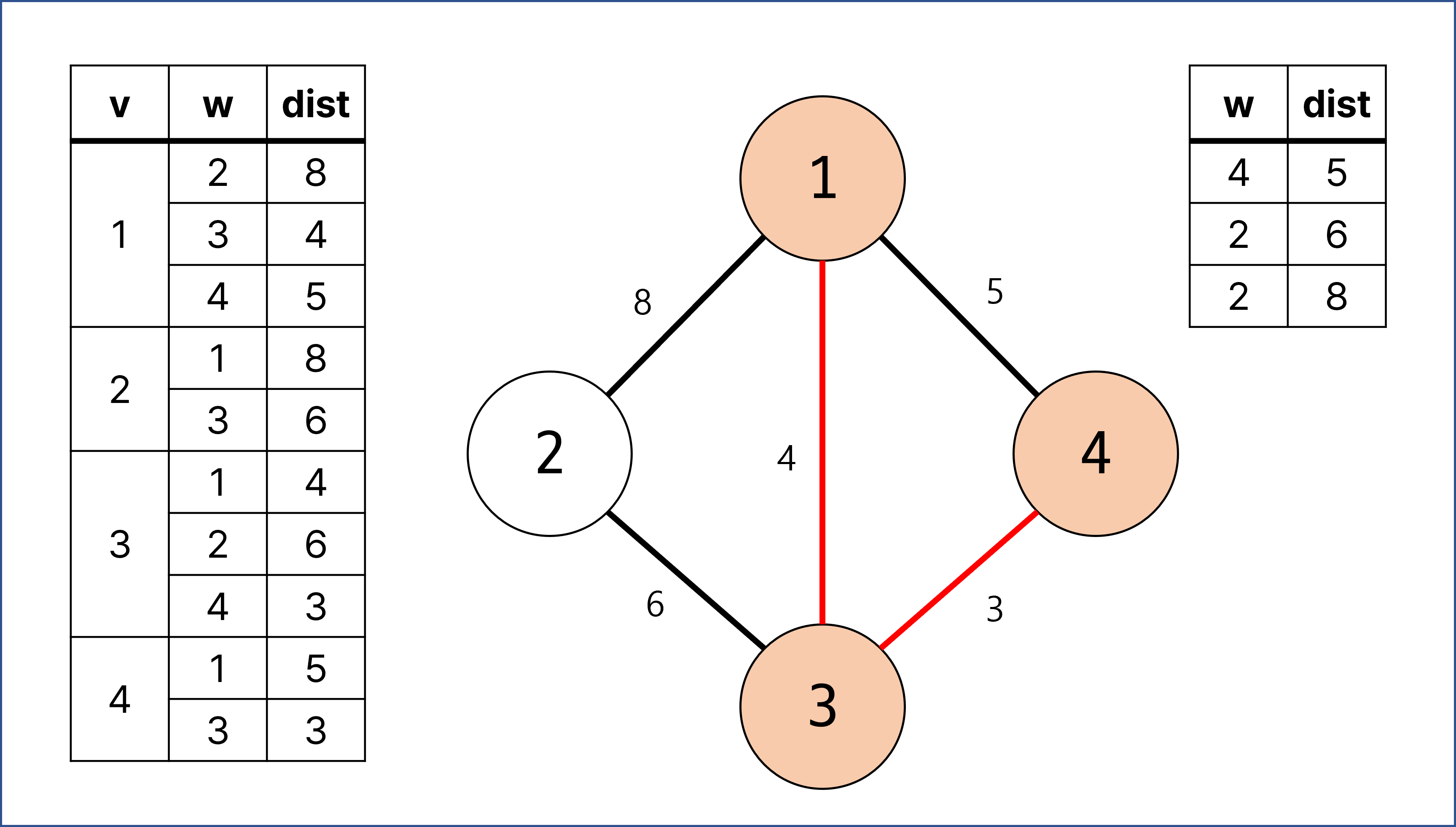
우선 순위 큐의 첫 번째에 있던 w = 4, dist = 3에 대한 계산이 이루어짐.
정점 4은 방문 체크를 해줌.
하지만 정점 4와 연결되어 있으면서 한 번도 방문하지 않았던 정점과도 연결되어 있는 간선이 없으므로 우선 순위 큐에 따로 집어 넣지 않고 끝냄.
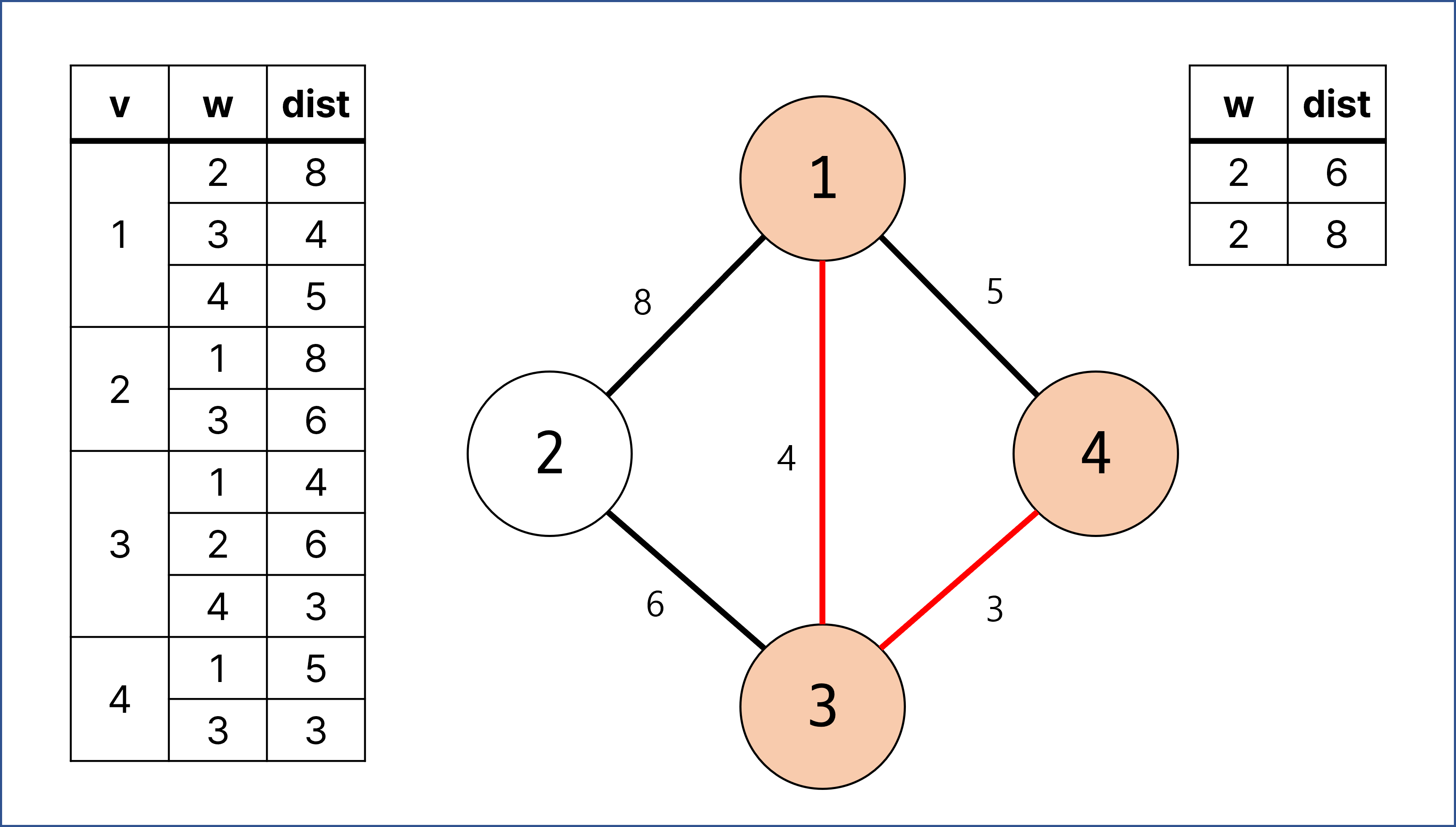
우선 순위 큐의 첫 번째에 있던 w = 4, dist = 5에 대한 계산이 이루어짐.
해당 간선의 경우 한 번도 방문되지 않던 정점이 아니며, 다음 간선이 포함될 경우 1, 3, 4의 사이클이 형성되므로 해당 간선에 대한 계산은 건너 뜀.
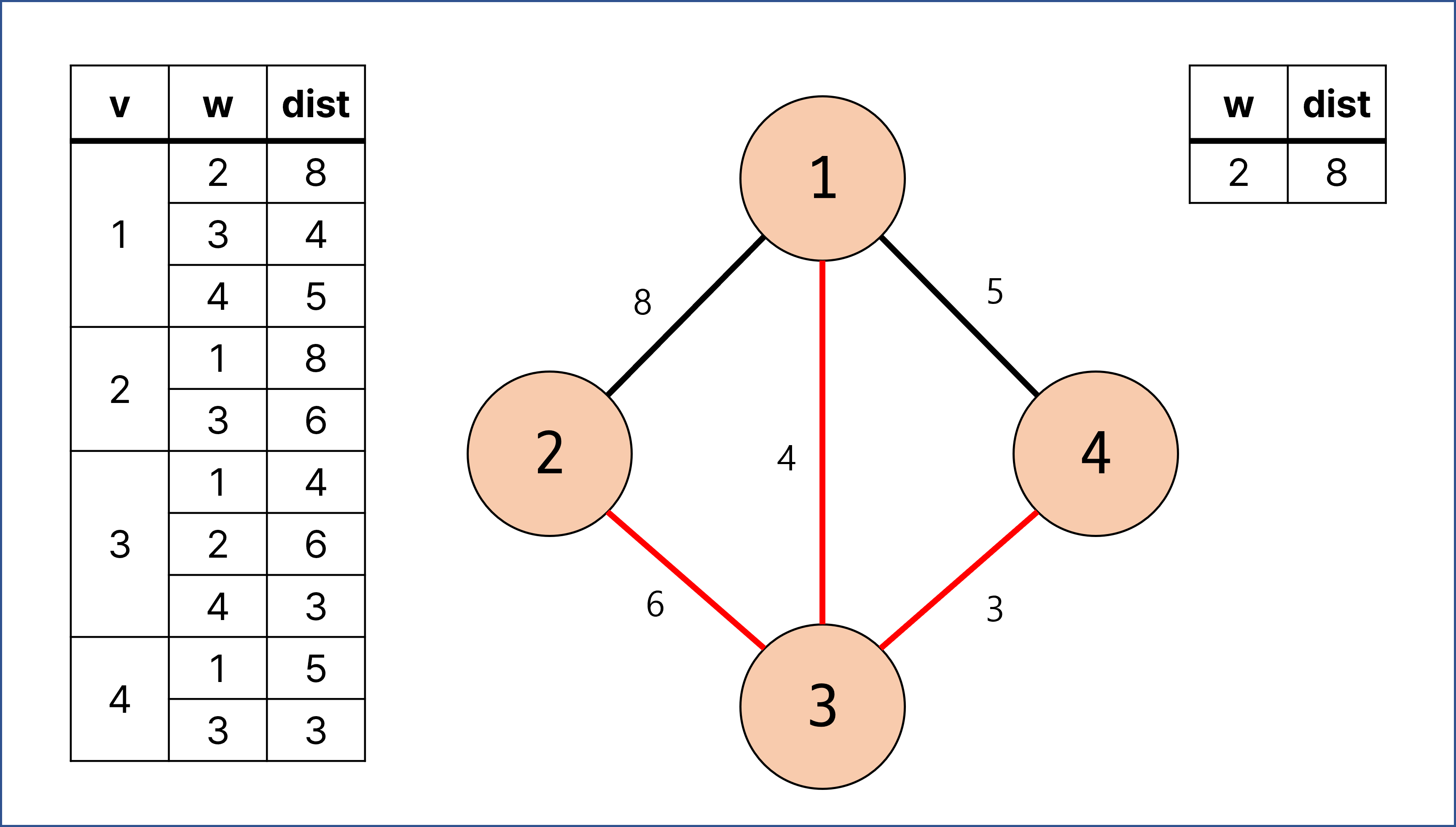
우선 순위 큐의 첫 번째에 있던 w = 2, dist = 6에 대한 계산이 이루어짐.
정점 2는 방문 체크를 해줌.
정점 2와 연결되어 있으면서 한 번도 방문하지 않았던 정점과도 연결되어 있는 간선이 없으므로 우선 순위 큐에 따로 집어 넣지 않고 끝냄.
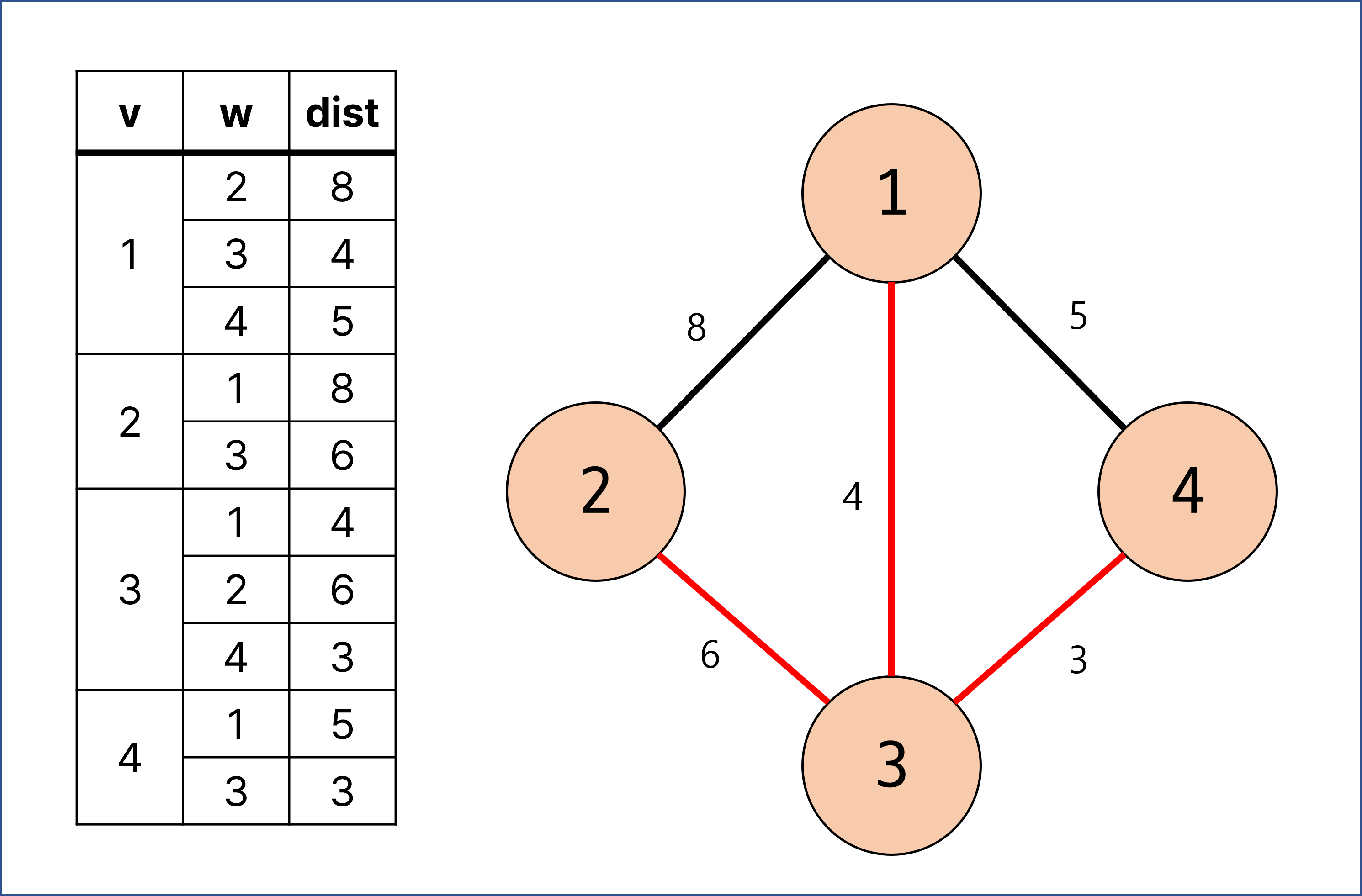
w = 2, dist = 8의 경우는 w = 4, dist = 5와 같은 이유로 건너 뛰게 되며, 계산이 완료됨.
코드
해당 코드는 1197 최소 스패닝 트리의 코드와도 같음.
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.util.ArrayList;
import java.util.List;
import java.util.PriorityQueue;
import java.util.StringTokenizer;
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
StringTokenizer st = new StringTokenizer(br.readLine());
int v = Integer.parseInt(st.nextToken());
int e = Integer.parseInt(st.nextToken());
boolean[] visited = new boolean[v + 1];
List<Node>[] adjList = new ArrayList[v + 1];
for (int i = 1; i <= v; i++)
adjList[i] = new ArrayList<>();
for (int i = 0; i < e; i++) {
st = new StringTokenizer(br.readLine());
int from = Integer.parseInt(st.nextToken());
int to = Integer.parseInt(st.nextToken());
int dist = Integer.parseInt(st.nextToken());
adjList[from].add(new Node(to, dist));
adjList[to].add(new Node(from, dist));
}
PriorityQueue<Node> pq = new PriorityQueue<>();
pq.offer(new Node(1, 0));
int answer = 0;
while (!pq.isEmpty()) {
Node n = pq.poll();
int to = n.to;
int dist = n.dist;
if (visited[to]) continue;
visited[to] = true;
answer += dist;
for (Node nxt : adjList[to])
pq.offer(nxt);
}
bw.write(answer + "");
br.close();
bw.flush();
bw.close();
}
}
class Node implements Comparable<Node> {
int to, dist;
public Node(int to, int dist) {
this.to = to;
this.dist = dist;
}
@Override
public int compareTo(Node o) {
return this.dist - o.dist;
}
}
/*
입력
4 5
1 2 8
1 3 4
1 4 5
2 3 6
3 4 3
출력
13
*/vs 크루스칼 알고리즘
크루스칼의 경우 분리 집합 알고리즘임.
크루스칼은 프림과는 다르게 가중치가 작은 간선부터 차례로 그래프로 형성함.
그래서 크루스칼의 시간 복잡도는 O(ElogE)가 나옴.
프림의 경우는 O(ElogV)가 나오기 때문에 간선이 많은 경우에 유리함.
// 크루스칼 알고리즘
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.util.Arrays;
import java.util.StringTokenizer;
public class Main {
private static int[] parent;
private static Node[] adjList;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
StringTokenizer st = new StringTokenizer(br.readLine());
int v = Integer.parseInt(st.nextToken());
int e = Integer.parseInt(st.nextToken());
parent = new int[v + 1];
adjList = new Node[e];
for (int i = 0; i < e; i++) {
st = new StringTokenizer(br.readLine());
int from = Integer.parseInt(st.nextToken());
int to = Integer.parseInt(st.nextToken());
int dist = Integer.parseInt(st.nextToken());
adjList[i] = new Node(from, to, dist);
}
Arrays.sort(adjList);
for (int i = 1; i <= v; i++)
parent[i] = i;
int sum = 0;
int count = 0;
for (Node n : adjList) {
if (union(n.from, n.to)) {
sum += n.dist;
count++;
if (count == v - 1) break;
}
}
bw.write(sum + "");
br.close();
bw.flush();
bw.close();
}
private static boolean union(int from, int to) {
int f = findSet(from);
int t = findSet(to);
if (f == t) return false;
parent[t] = f;
return true;
}
private static int findSet(int node) {
if (parent[node] == node) return node;
return parent[node] = findSet(parent[node]);
}
}
class Node implements Comparable<Node> {
int from, to, dist;
public Node(int from, int to, int dist) {
this.from = from;
this.to = to;
this.dist = dist;
}
@Override
public int compareTo(Node o) {
return this.dist - o.dist;
}
}참고 링크
https://velog.io/@chosj1526/알고리즘-프림-알고리즘-Prims-Algorithm
https://namu.wiki/w/프림 알고리즘

잘 읽었습니다. 좋은 정보 감사드립니다.