담당교수: 서울대학교 문태섭 교수님
Supervised Deep learning
이미지 분별, 음성 인식, 기계학습과 같이 지도 딥러닝은 커다란 성장을 가져왔으나, 단순 신경망 -> resnet, densenet -> transformer 의 형태로 발전함에 따라 대용량 학습 데이터로부터 학습하는 모델구조가 점점 더 복잡해지고 이해하기 어려워짐. 결국 이러한 모델들이 어떻게 동작하는지는 잘 모르겠지만 입력을 집어넣으면 출력이 튀어나오는 하나의 블랙박스처럼 동작하게 된 것이다.
이러한 복잡한 모델을 응용분야에 적용할 때 단순한 예측결과만 있는 경우엔 큰 문제가 없지만 예측결과가 사람에게 직접 영향을 미칠 수 있는 경우 문제가 생길 수 있다(자율주행 자동차, 의료치료, 대출 승인, 인터뷰 등).
- 최근 대두되고 있는 AI모델의 편향성 문제
-> 이러한 편향성 바이어스를 고치기 위해 어떻게 해야 할지 등을 알아내기 위해 모델의 결과를 설명할 수 있는 설명 가능 인공지능이 반드시 필요하다.
Some Examples of Explainable AI
Reliability & Robustness - Pascal VOC 2007 classification
딥러닝 모델이 이미지를 받아들여서 예를 들어 말에 대한 사진이라고 분류를 하였는데 XAI 기법은 과연 이 모델이 이미지의 어느 부분을 보고 말이라고 했는지 빨간색으로 하이라이트를 해서 보여주는 방식이며 텍스트 워터마크에 기반 하여 말이라고 분류했기에 일반적인 상황에 적용할 수 있는 제대로된 말 분류기라고 할 수는 없다.
- 다만 이를 통해 XAI기법은 모델/데이터 셋의 오류 색출, 모델이 얼마나 편향되어 있는지 알 수 있다.
Fairness – COMPAS crime prediction
이 COMPAS에서는 흑인이 범죄를 저지르지 않았는데도 나중에 재범을 할 것이라고 예측하고 백인이 범죄를 다시 저질렀는데도 나중에 재범하지 않을 것이라고 잘못 인식
Critical systems – Self-driving car
XAI를 통해 사고의 책임소재를 찾고 향후 더욱 안전한 알고리즘을 만들 수 있다.
Critical systems – COVID19 classification
왜 알고리즘이 그런 예측 결과를 냈는지 설명하는 것을 듣고 신뢰 여부를 결정 할 수 있다.
What is Explainability / Interpretability?
- 사람이 그 이유를 이해할 수 있게 해주는 것
- 설명을 통해 모델의 결과를 예측할 수 있게 해주는 것
- 이유를 설명할 수 있게 해주는 것
-> 정확히 어떻게 하는 것이 그렇게 설명 가능성을 높이는 것인지에 대한 구체적인 답을 알기는 어렵다. 따라서 XAI연구 분야에서도 사람이 모델을 쓸 때 그 동작을 이해하고 신뢰할 수 있게 해주는 기계 학습 기술이라고만 되어 있다.
그러므로 본 강의에서는 주로 시각화를 통해서 모델의 예측 결과에 중요한 영향을 미친 특징이나 데이터를 하이라이트 해서 보여주는 방법들에 대해서 주로 살펴보고자 한다.
Taxonomy of XAI Methods
Local vs. Global
- local: 주어진 특정 데이터에 대한 예측 결과를 개별적으로 설명하려는 방법
- global: 개별 데이터에 대한 결과를 따로 설명하는 것이 아니라 전체 데이터 셋에서 모델의 전반적인 행동을 설명하고자 하는 방법
White-box vs. Black-box
- White-box: 모델의 내부 구조를 정확하게 알고 있는 상황에서 설명을 시도하는 방법
- Black-box: 모델의 내부 구조는 전혀 모르는 상태에서 단순히 모델의 입력과 출력만 가지고 설명을 시도하는 방법
Intrinsic vs. Post-hoc(내재적 vs 사후추론)
- Intrinsic: 모델의 복잡도를 훈련하기 이전부터 설명하기 용이하도록 제안한 뒤 학습을 시켜서 그 후 학습된 모델을 가지고 설명하는 방법
- Post-hoc: 임의 모델의 훈련이 끝난 뒤에 이 방법을 적용해서 그 모델의 행동을 설명 하는 방법
Model-specific vs. Model-agnostic
- Model-specific: 특정 모델 구조에만 적용이 가능
- Model-agnostic: 모델의 구조와 관계없이 어느 모델에도 항상 적용
Examples of Taxonomy of XAI Methods
- Linear model, Simple Decision Tree : Global, White-box, Intrinsic, Model-specific
데이터 전체로부터 학습된 모델을 설명하는 것이므로 글로벌한 설명, 모델의 정확한 구조를 알아야하기에 white-box 설명 방식이며, 학습되는 모델 자체가 간단하고 직접적으로 설명을 만들어내는 모델이라서 intrinsic하며, 선형 모델이라는 특정 모델에만 적용되는 설명이기에 model-specific한 설명 방법이다.
- Grad-CAM : Local, White-box, Post-hoc, Model-agnostic
개별 이미지마다 그 예측 결과를 설명할 수 있는 방법이기 때문에 local한 설명이고, 마찬가지로 모델의 정확한 구조와 계수들을 모두 알아야 구할 수 있는 설명이기 때문에 white-box설명이며 또 모델이 학습이 되고 난 후 적용해서 설명을 제공하는 post-hoc 설명 방법이고, 딥러닝 모델의 구조와 상관없이 항상 적용할 수 있는 방법이기 때문에 딥러닝 모델에 대해서는 model-agnostic 설명 방법에 해당한다.
Outline
Saliency Map-based
하나의 이미지샘플이 모델의 입력으로 들어가게 되면 그 샘플에 대한 예측 결과에 대한 설명을 히트맵과 같이 이미지에서 중요하게 작용한 부분을 하이라이트해서 보여줌으로써 설명을 제공하는 방법이다.
• Simple Gradient method: 입력에 대한 모델의 gradient로 설명을 제공
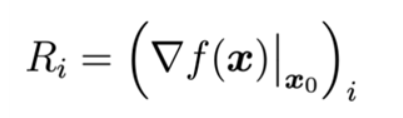
즉 x0라는 이미지가 f라는 함수에 입력으로 들어가서 출력이 되었을 때 그 출력값의 입력 이미지의 각 픽셀에 대한 gradient를 구해서 그 값을 각 픽셀의 중요도로 해석하는 것
(input gradient는 딥러닝 모델의 경우 back-propagation이라는 효율적인 방법으로 쉽게 계산할 수 있기에 구현상으로도 간단히 구현할 수 있는 이점이 있다.)
Examples : The gradient maps are visualized for the highest-scoring class
- 장점 : 간단한 gradient에 기반한 설명 방법은 계산하기가 아주 쉬움, 어느 정도 정확한 설명을 만들어 낼 수 있음
- 단점 : 구한 설명들이 noisy할 확률이 높다. -> SmoothGrad: 이러한 단점을 극복하기 위해 제시된 것
SmoothGrad
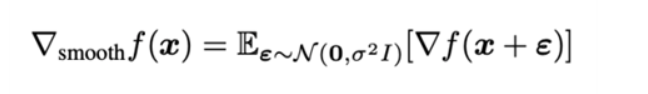
x라는 이미지가 주어졌을 때 작은 Dependent Gaussian Noise Epsilon을 섞어준 뒤 노이즈가 섞인 이미지의 입력 gradient를 구하는 과정을 여러 번 수행해서 그 gradient들의 평균으로 설명을 제시하는 방법
Typical heuristics
Expectation is approximated with Monte-Carlo (around 50 runs)
𝜎 is set to be 10~20% of 𝑥𝑚𝑎𝑥 − 𝑥𝑚𝑖n
- noisy한 gradient들을 많이 제거 가능
- 평균적으로 남는 데이터들이 더욱 깨끗한 설명을 제공
Examples : SmoothGrad seems to work better for uniform background
배경이 균일한 경우 더 깨끗하게 smoothgrad가 잘 설명하며 즉, 중요한 픽셀들을 잘 잡아낼 수 있다.
장점 : 간단한 평균을 내는 과정을 통해 훨씬 깨끗한 설명을 생성해낼 수 있다, 간단한 gradient 방법만이 아닌 대부분의 saliency-map 기반 방법들에도 동일하게 쉽게 적용 가능하다.
단점 : noise를 섞어주는 횟수만큼 어떤 딥러닝 모델의 forward-backward propagation을 해야 하기 때문에 계산 복잡도가 높다.
