
데이콘 대회 참가
부캠이 끝나고 한동안 수학과 인공지능 이론, 코딩테스트 등을 공부하면서 시간을 보냈었다. 그래서 한동안 데이터를 만져볼 일이 없었는데 데이콘에 재밌어보이는 대회가 열린 것을 보았다. 약 반년 가까운 기간 동안 데이터를 만져보지 않고 지내다가 오랜만에 데이콘 대회에 참가를 해보게 되어서 재미있을 것 같았다. 비록 내가 가장 관심 있는 분야인 NLP 분야는 아니었지만, 다양한 데이터를 접해보는 것도 좋을 것 같아서 참가를 해보았다.
고객 대출등급 분류 해커톤
대회 링크
고객 대출등급 분류 해커톤은 고객의 대출금액, 대출 기간, 소득, 주택 소유 상태 등 13개의 피쳐를 통해서 대출등급을 분류하는 대회이다. 그중 9개의 피쳐는 수치형, 4개의 피쳐는 범주형으로 이루어져 있고 대출등급은 각각 A, B, C, D, E, F, G로 7개가 존재한다.
EDA 진행 과정
EDA를 진행한 내용을 대략적으로 약간만 설명해 보겠다.
먼저 대출등급의 분포를 살펴보았다.
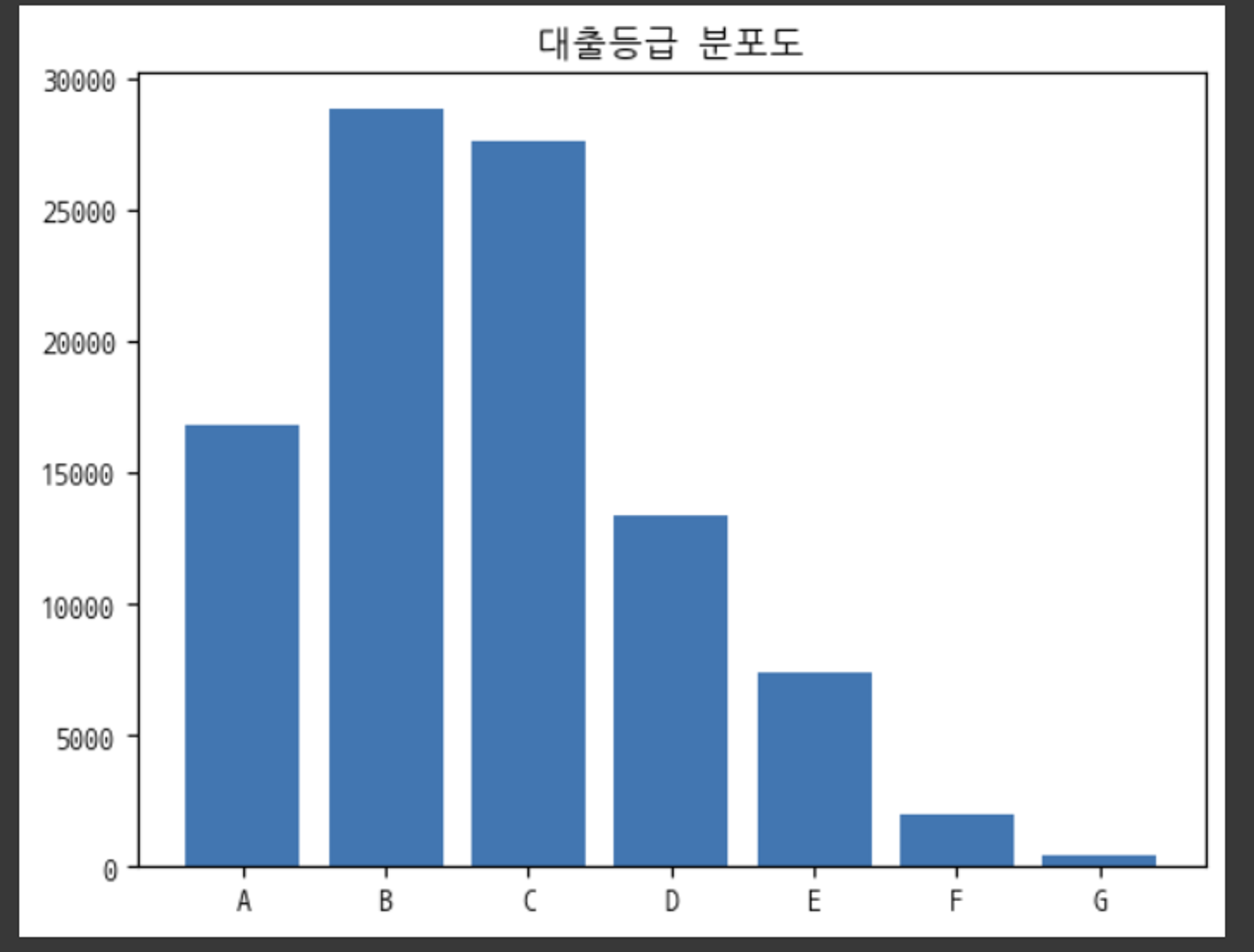 대출등급의 분포는 높은 등급에 분포가 몰려있고 낮은 등급은 별로 존재하지 않는 모습을 보여줬다. 특히 F, G등급은 거의 존재하지 않는 모습을 보여주었다.
대출등급의 분포는 높은 등급에 분포가 몰려있고 낮은 등급은 별로 존재하지 않는 모습을 보여줬다. 특히 F, G등급은 거의 존재하지 않는 모습을 보여주었다.
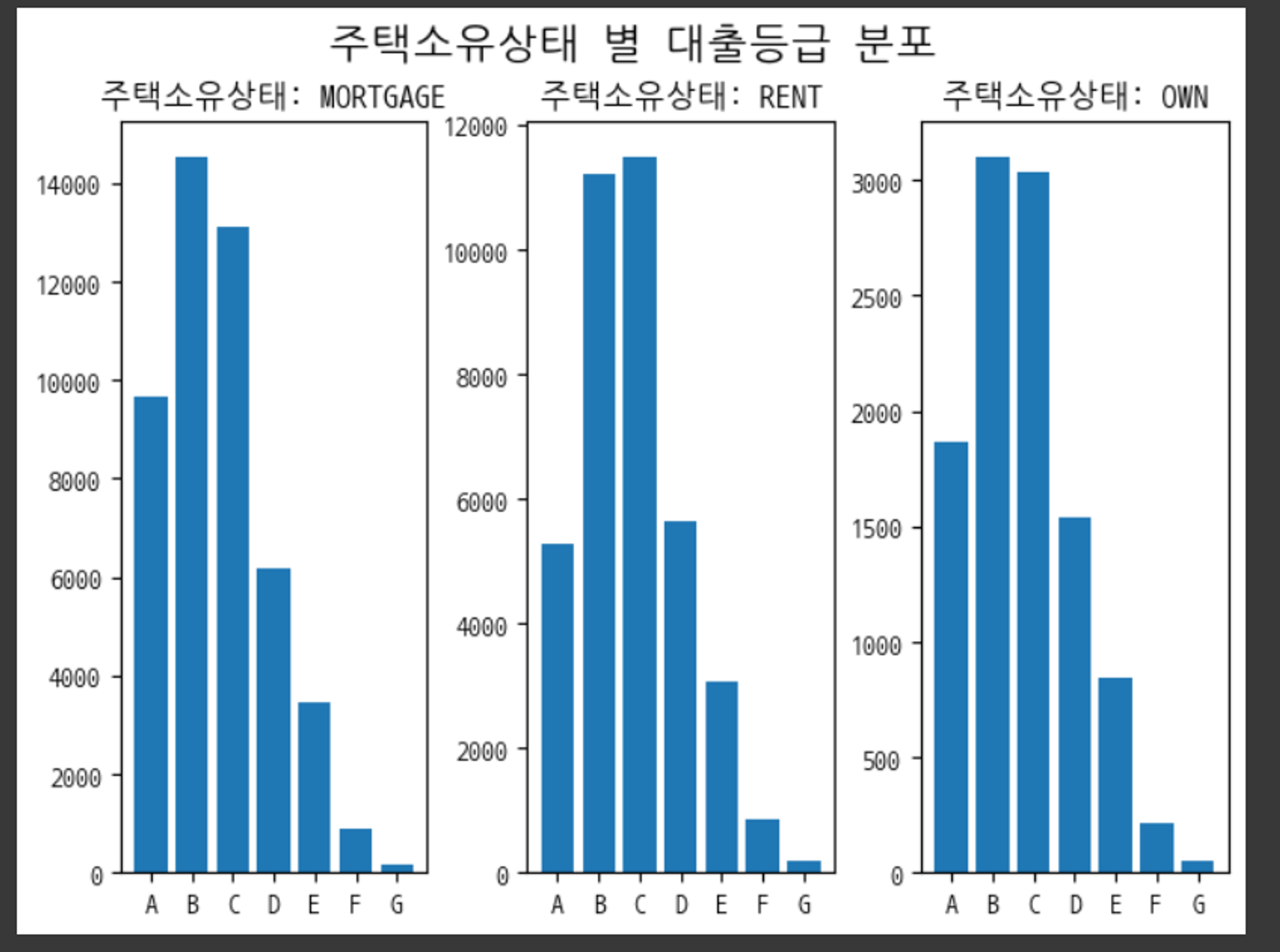
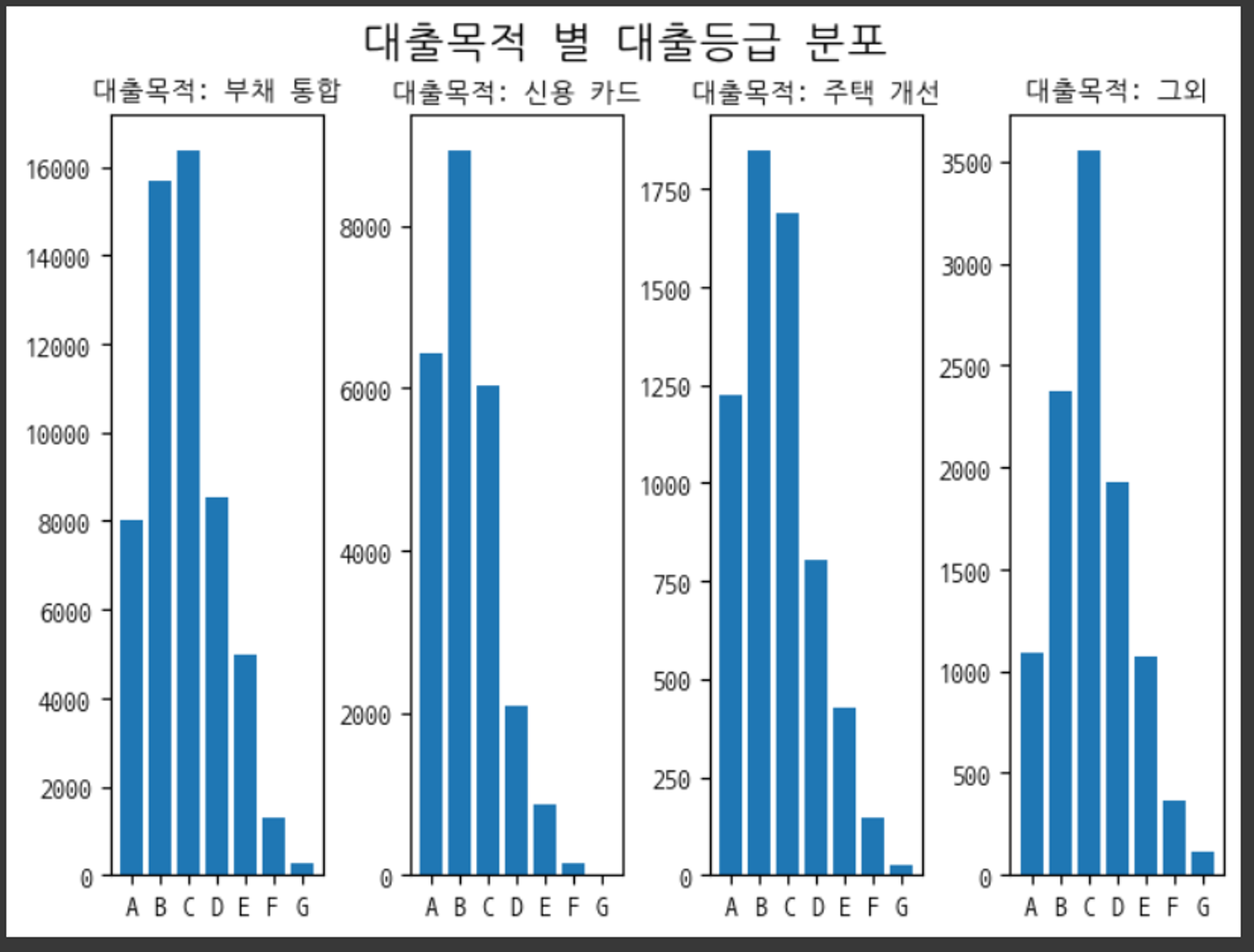
범주형 데이터들도 살펴보기 위해 대출목적과 주택 소유 상태에 대해서도 EDA를 해보았다. 그중에서 집중했던 것은 각 카테고리 별 대출등급의 분포였다.
 |  |
|---|
대출목적과 주택 소유 상태별로 대출등급의 분포에 차이가 있음을 볼 수 있었다. 이 점에 착안하여 주택 소유 상태나 대출목적별로 별개의 모델을 생성하여 학습하는 방법도 사용을 해보았는데 성능이 좋지 못하였다.
범주형 데이터 중 대출기간에 따른 대출등급의 분포에도 큰 차이가 존재하여 대출기간별로 별개의 모델을
생성하는 방법도 고려해 보았으나 성능이 좋지 못하였고 나는 수치형 데이터들에도 관심을 가져보았다.
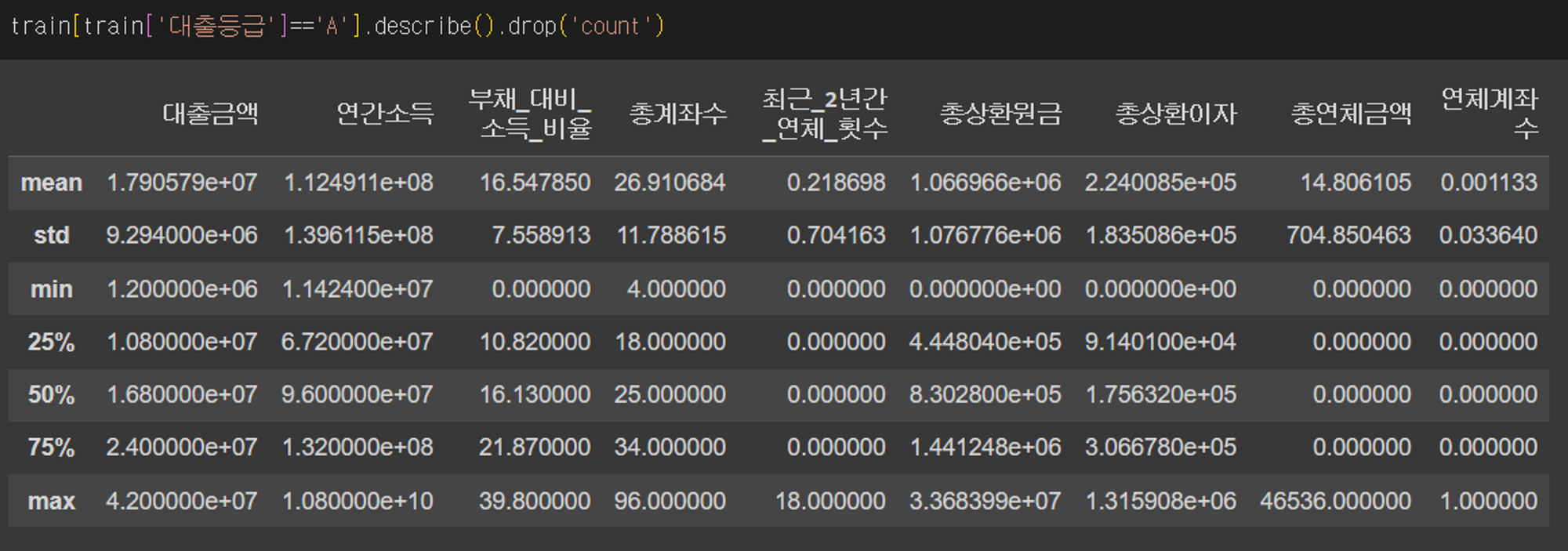
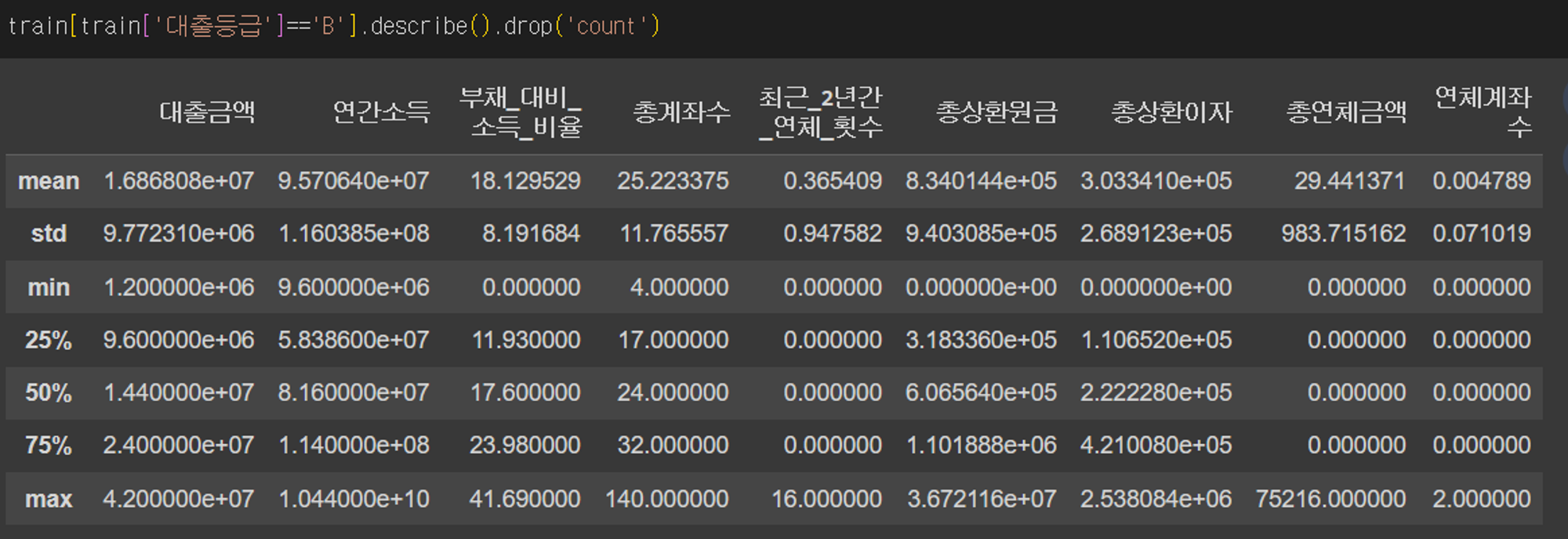
수치형 데이터는 일단 각 대출등급별로 요약을 해보았고 대출등급별로 차이가 나는 피쳐가 어떤 것인지 살펴보았다.
 |  |
|---|---|
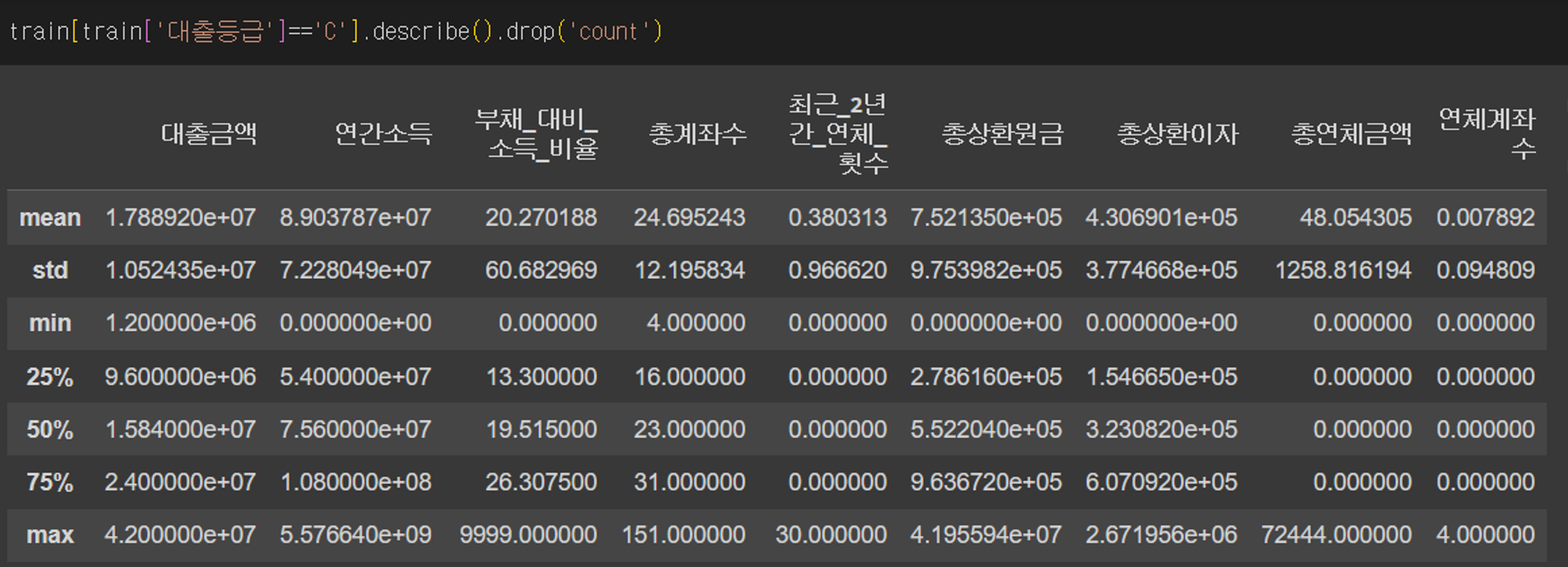 | 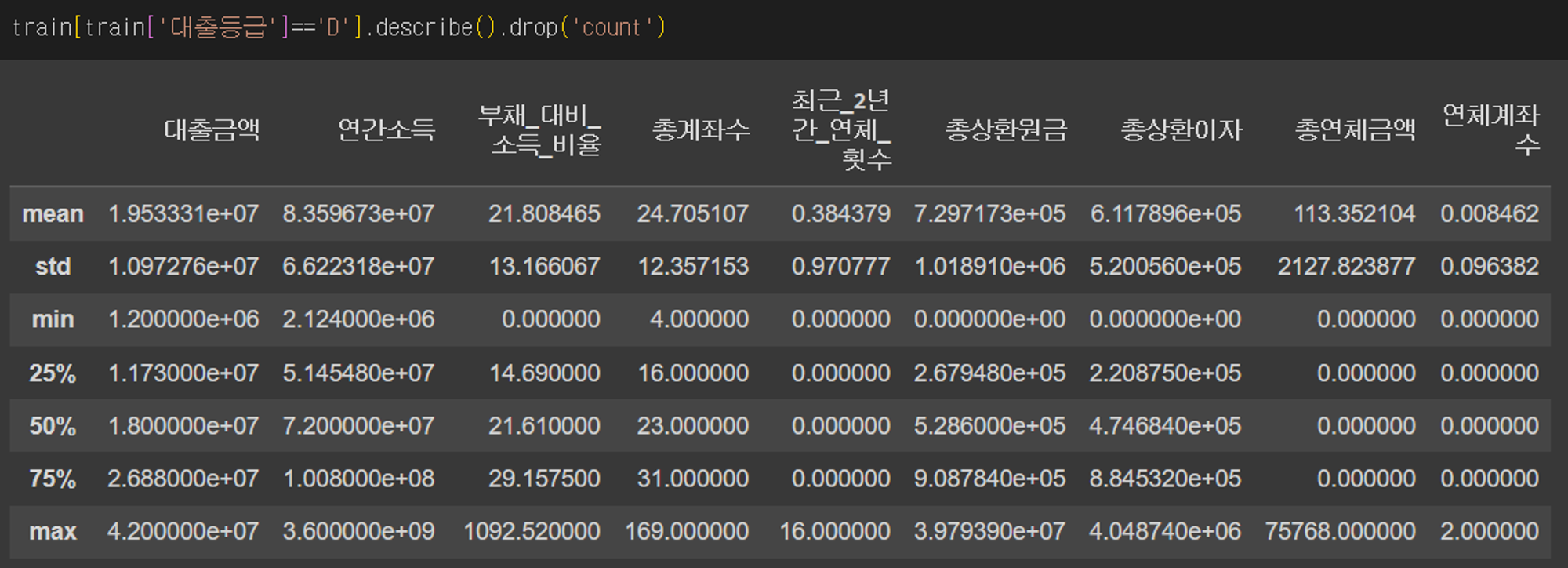 |
위 사진들은 대출등급이 각각 A, B, C, D일 때 수치형 피쳐들을 요약한 것이다. 각 등급별로 분포가 달라지는 피쳐가 어떤 것들인지 알아보았는데 총연체금액과 연체계좌수는 등급이 낮아질 때마다 커지기는 하지만 대부분의 값이 0이었기 때문에 유의미한 지표로 보기 힘들 것 같아 제외를 하였다.
나는 총상환연금과 총상환이자에 집중을 하였는데 등급이 높을수록 총상환연금은 높고 총상환이자는 낮았기 때문이다. 내 나름대로의 가설을 세워보며 원금을 갚아갈 만한 여유가 있는 사람들이 높은 대출등급을 부여받고 상대적으로 낮은 이율을 적용받을 것이라고 추측하였다. 다른 상위권 유저들의 코드를 보니 이 예측이 어느 정도는 맞았던 것 같다는 생각이 들었다.
모델 실험 과정
먼저 모델 선정 과정에서는 XGBoost와 CatBoost, LightGBM을 테스트해 보았고 XGBoost가 유일하게 0.8점을 넘기면서 XGBoost 위주로 실험을 진행하였다. 3가지 모델 모두 머신러닝 대회에서 굉장히 많이 사용되는 모델로 많은 캐글러들이나 데이커들이 사용하는 것으로 알고 있다. 지금은 이 모델들에 잘 몰라서 그냥 성능으로만 비교를 하였지만 다음번에 기회가 된다면 저 모델들에 대해 알아보고 주어진 데이터의 특성에 맞게 활용해 보아야겠다.
모델 선정이 끝난 다음에는 레이블 분포가 불균형하다는 점을 고려하여 class_weight를 사용하였고 여러 컬럼들을 제거하거나 스케일링, 레이블링을 적용하며 모델의 성능을 높이기 위해서 실험을 진행하였다.
또 혼동행렬을 통해서 어떤 레이블에서 정답률이 높고 낮은지를 살펴보기도 하였다.
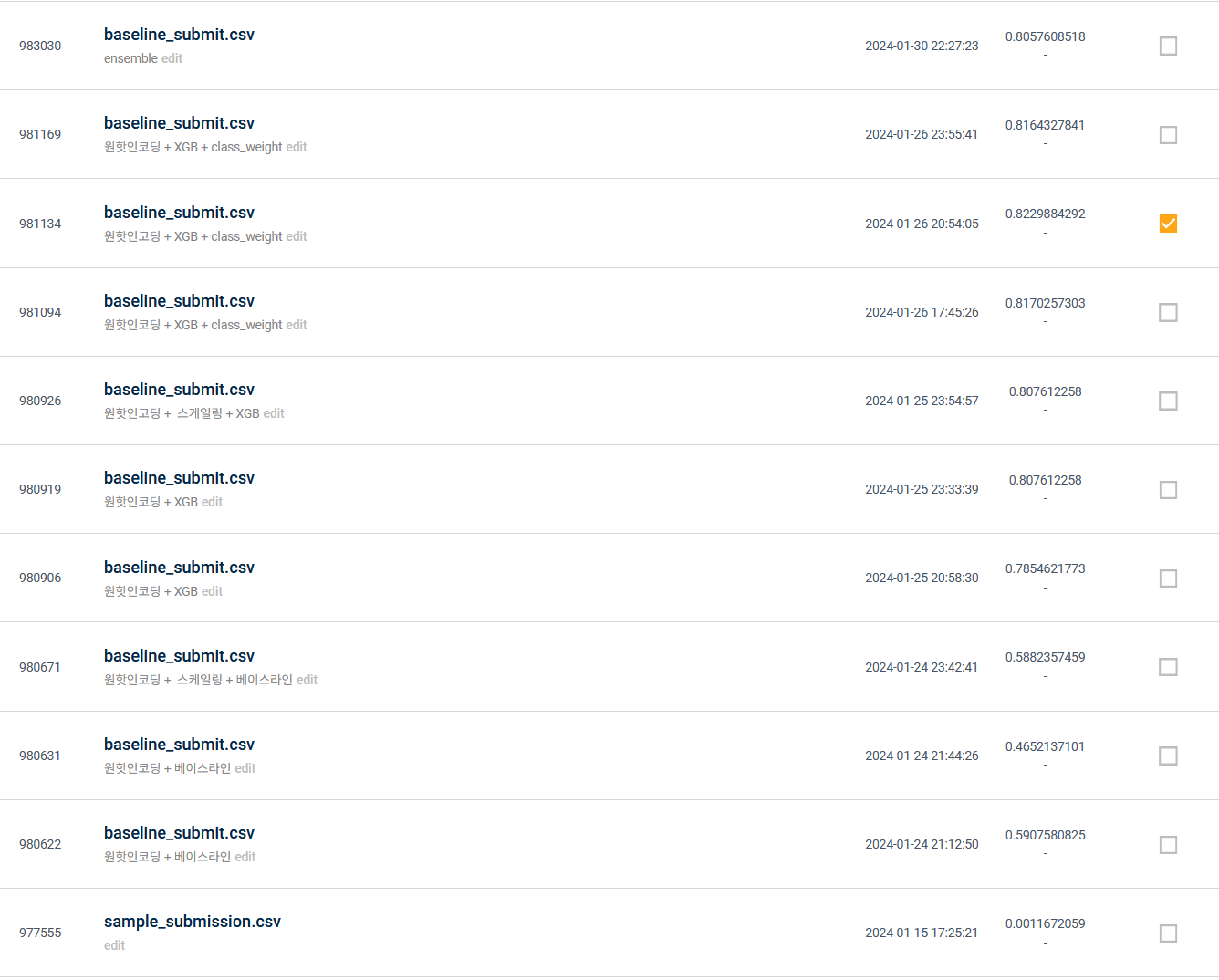
이런 과정들을 통해 성능을 약 0.82까지 올릴 수 있었다. 다른 사람들의 후기를 보니 기존의 피쳐들을 활용하여 새로운 피쳐를 생성하는 방식으로 성능을 끌어올렸던데 나는 그런 과정을 진행하지 못하였기 때문에 많이 아쉬웠다. 데이터에 대해 많이 공부를 해보아야 할 것 같고 다음 대회부터는 해당 주제의 도메인에 대해서도 다양한 탐구를 진행해 보아야 할 것 같다.
대회 결과
PUBLIC 기준 220등
 PRIVATE 기준 204등
PRIVATE 기준 204등

리더보드 기준 784명이 참가한 대회에서 최종 순위 204등으로 상위 29% 정도의 성적을 거두었다. 좋은 성적은 아니지만 처음이기도 하고 다른 일들도 병행하면서 하였기 때문에 나름 만족하고 다음번에는 더 좋은 성적을 거두어야겠다.
대회 후기
이전에 부캠에서 진행하였던 대회에서는 기본적으로 베이스라인 코드가 모두 제공이 되었기 때문에 내가 베이스라인 코드를 짤 일이 없었는데 이번 대회에서는 직접 베이스라인 코드를 만들어 보았다. 처음으로 만든 베이스라인이라 많이 허술하였지만 만들어보았다는 데 의의를 두고 싶다.
또 이전에 부캠 대회들과는 달리 이번 데이터는 정형 데이터 대회였는데 정형데이터는 처음으로 만져보는 거라 많이 헤맸다. 다른 사람들의 코드를 보니 다양한 방식으로 피쳐 엔지니어링을 진행한 것을 알 수 있었다. 나는 그런 부분에서 굉장히 부족했었던 것 같다. 앞으로도 종종 대회에 참가하면서 벽에 부딪혀보고 다른 사람들의 자료들을 참고해 가면서 실력을 쌓아가야 할 것 같다.
부스트캠프에서 제공했던 GPU 서버가 그리워진다. 나도 좋은 그래픽 카드를 가지고 싶다.
ps. 별거 없지만 저의 코드는 여기로 가면 보실 수 있습니다.
