
웹 로그 기반 조회수 예측 대회
대회 링크
코드 공유글 링크
수상자 인터뷰 링크
웹 로그 기반 조회수 예측 대회는 대출금액, 대출 기간, 소득, 주택 소유 상태 등 13개의 피쳐를 통해서 조회수를 예측하는 대회이다. 그중 4개의 피쳐는 수치형, 12개의 피쳐는 범주형으로 이루어져 있다.
EDA 및 데이터 처리 과정
EDA를 진행한 내용은 너무 자세하게 쓰기에는 실패한 방법도 많았고 내용도 너무 길어질 것 같아 대략적으로만 설명을 할 것이다.
먼저 이번 대회에서의 목표는 조회수를 예측하는 것이기 때문에 가장 중요한 조회수의 분포를 살펴보았다.
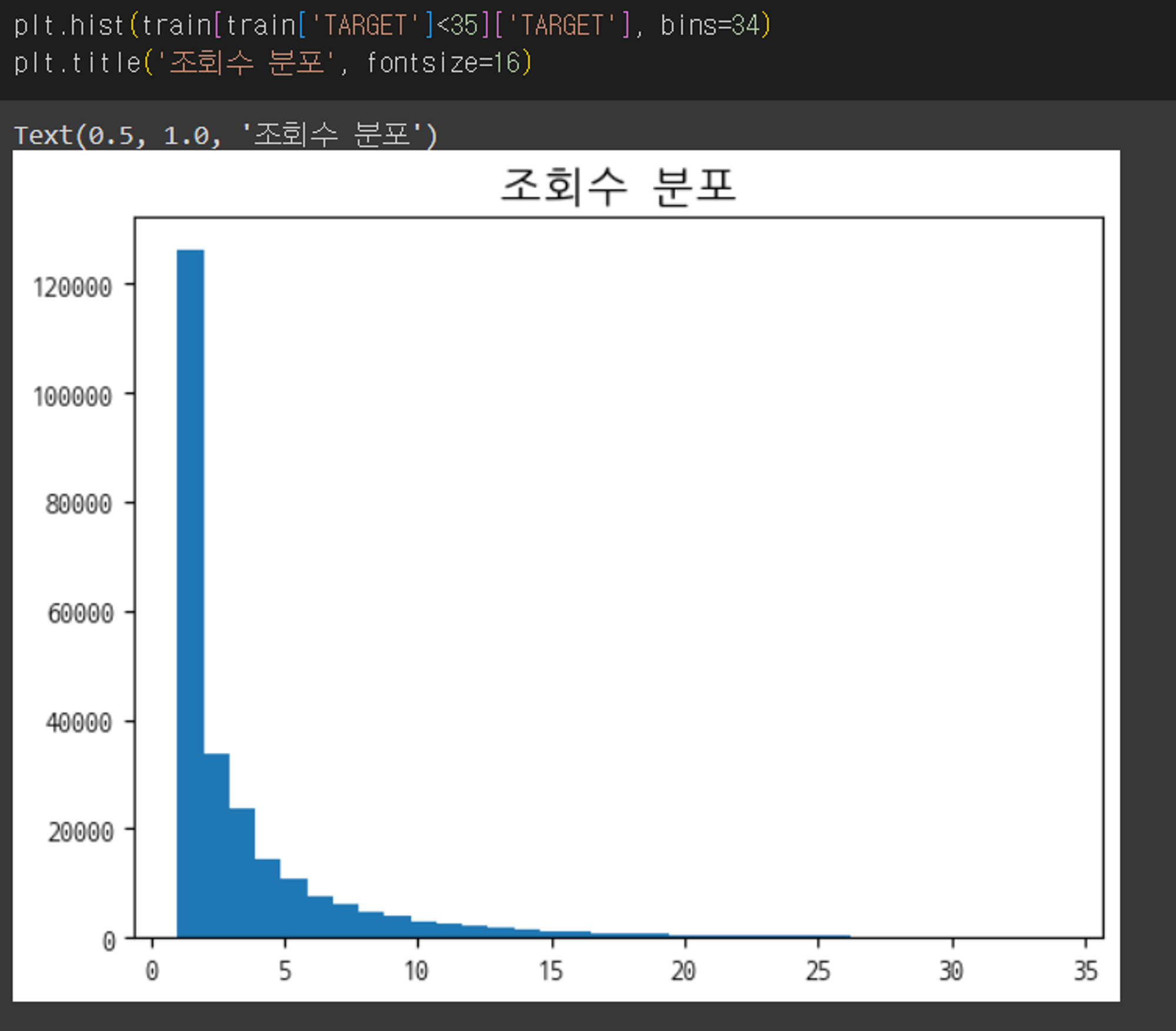 조회수가 과도하게 큰 값이 몇 개 정도 존재하여 시각화 과정에서는 제외를 한 뒤 분포를 살펴보았는데 대부분이 1에 존재하였고 뒤로 갈수록 매우 적어지는 분포를 보였다. 아직 데이터 분석에 대해 잘 알지는 못하지만, 데이터의 편향을 해결하는 것이 모델의 성능 향상을 이끌어낼 수 있다는 것은 들어봤기 때문에 로그 변환을 통해 편향을 줄이는 방법을 사용해 보았다.
조회수가 과도하게 큰 값이 몇 개 정도 존재하여 시각화 과정에서는 제외를 한 뒤 분포를 살펴보았는데 대부분이 1에 존재하였고 뒤로 갈수록 매우 적어지는 분포를 보였다. 아직 데이터 분석에 대해 잘 알지는 못하지만, 데이터의 편향을 해결하는 것이 모델의 성능 향상을 이끌어낼 수 있다는 것은 들어봤기 때문에 로그 변환을 통해 편향을 줄이는 방법을 사용해 보았다. 그 후에는 일단 여러 범주형 피쳐들을 살펴보았는데 그중 가장 눈에 띄었던 것은 이탈 여부라는 피쳐였다. 아래의 그래프와 같이 이탈 여부가 'bounced'(원래는 0 또는 1의 값을 갖는 피쳐지만 내가 임의로 수정을 하였다.)인 경우 조회수가 무조건 1로 고정되어 있었다.
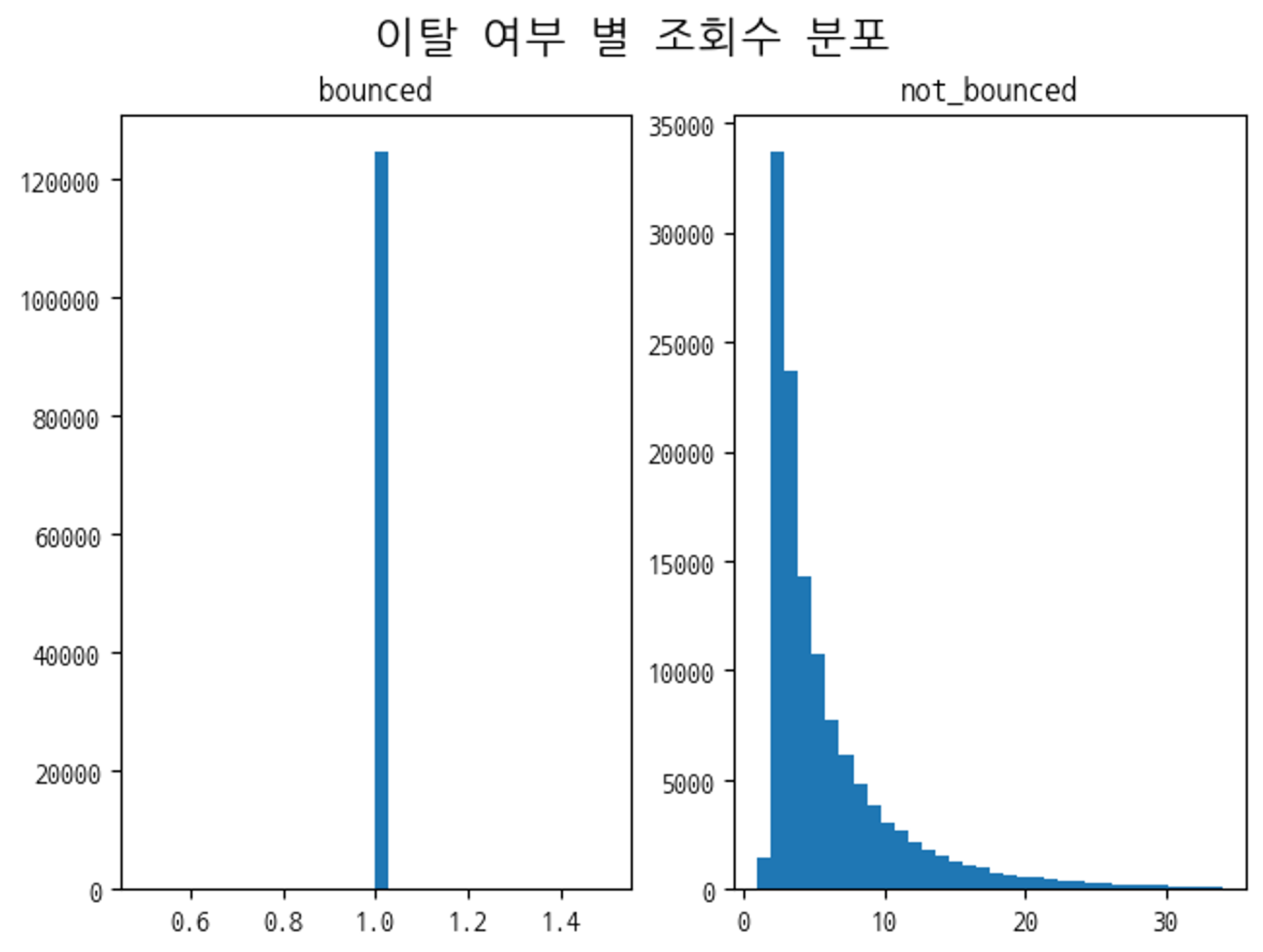 나는 이를 보고 이탈 여부가 'not_bounced'인 데이터들만 학습에 활용을 하고 이탈 여부가 'bounced'인 데이터들은 예측값을 1로 고정을 해주었다. 이 방법을 통해서 매우 큰 성능 상승 효과(2.59->2.53)를 보았고 이후의 EDA는 이탈 여부가 'not_bounced'인 데이터들만을 활용하여 진행하였다.
나는 이를 보고 이탈 여부가 'not_bounced'인 데이터들만 학습에 활용을 하고 이탈 여부가 'bounced'인 데이터들은 예측값을 1로 고정을 해주었다. 이 방법을 통해서 매우 큰 성능 상승 효과(2.59->2.53)를 보았고 이후의 EDA는 이탈 여부가 'not_bounced'인 데이터들만을 활용하여 진행하였다.다음 과정으로 나는 수치형 피쳐에 비해 종류가 많은 범주형 피쳐에 집중을 하였다. 범주형 피쳐들의 종류에는 사용 브라우저, OS, 지역(대륙, 하위대륙, 국가), 트래픽 관련 정보(트래픽 소스, 매체, 키워드)가 있었다. 나는 이 피쳐들중 지역과 트래픽 관련 정보에 집중을 하였다. 이 피쳐들은 같은 카테고리 내의 피쳐들끼리 서로 관계를 가진다고 생각했기 때문에 이 관계를 정리해서 피쳐의 개수를 줄이면 더 좋은 성능을 얻을 수 있을 것이라고 생각했다. 그래서 지역 관련 피쳐들 중 일부만 학습에 사용을 해보기도 하고 트래픽 관련 정보들의 데이터들을 통합하는 방법도 활용해 보았지만, 성능은 전혀 오르지 않았다.
범주형 피쳐 처리 과정에서 전혀 소득을 거두지 못한 나는 마지막으로 수치형 데이터들을 살펴보았다.
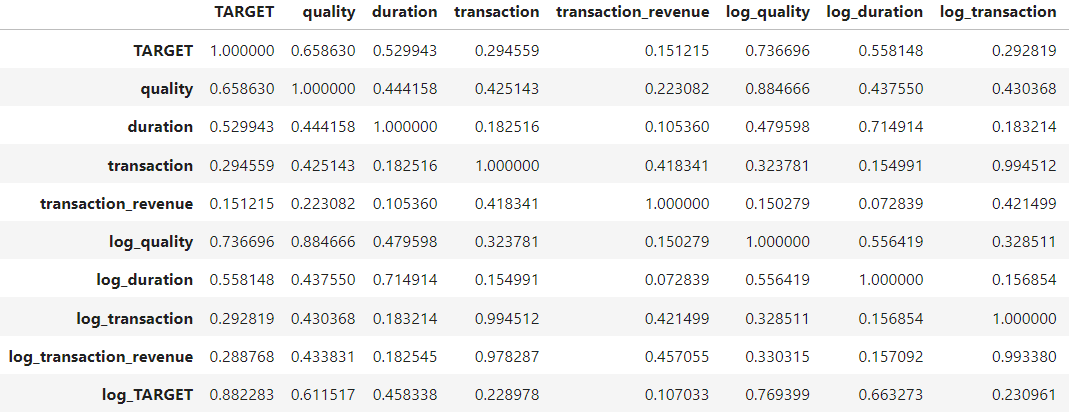
가장 먼저 각 피쳐들의 분포들을 살펴보는 것으로 시작을 했는데 아래의 표에 나오는 것처럼 모든 데이터들이 좌측으로 매우 편향되어 있었다.
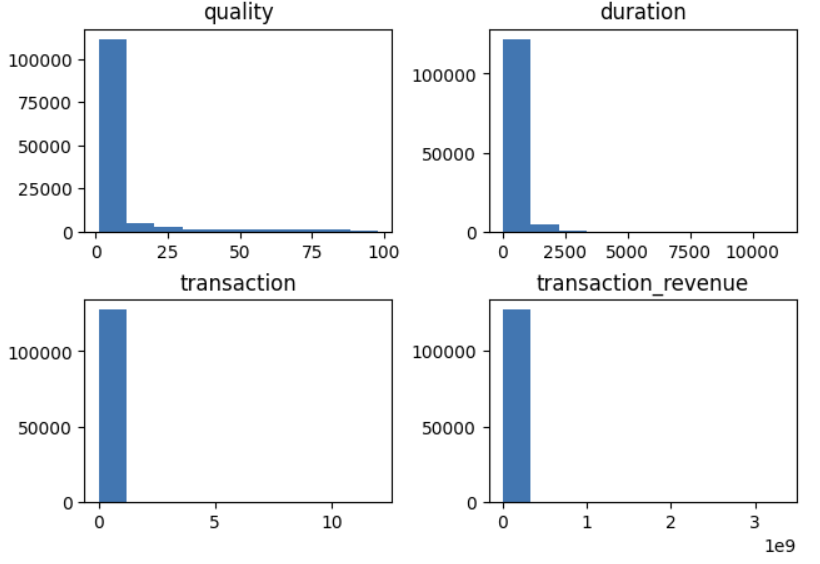
이런 편향을 해결하기 위해 모든 수치형 데이터들에 로그 변환을 적용해 보았고 아래와 같은 분포로 만들어주었다.
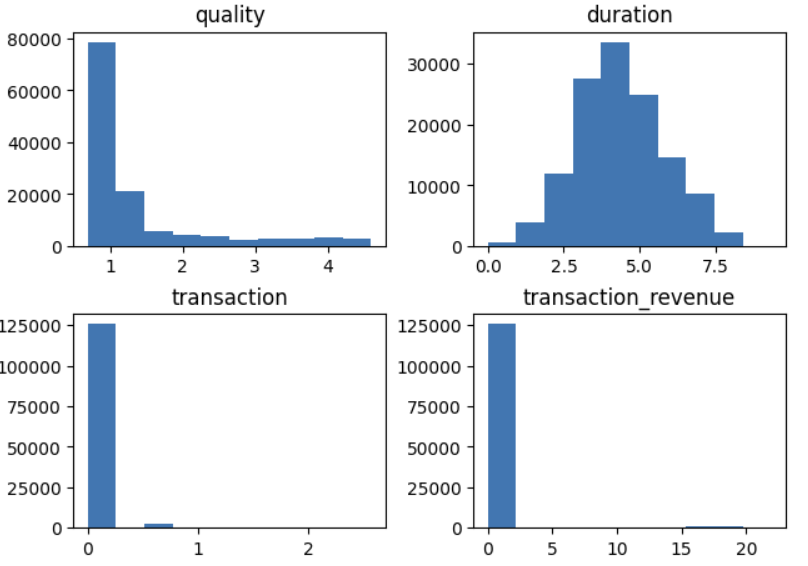 transaction 과 transaction_revenue의 편향은 거의 해결되지 않았지만, quality는 어느 정도 분포에 변화가 생겼고 duration은 정규 분포에 매우 가까워졌다.
transaction 과 transaction_revenue의 편향은 거의 해결되지 않았지만, quality는 어느 정도 분포에 변화가 생겼고 duration은 정규 분포에 매우 가까워졌다.
위의 과정을 통해 데이터들의 편향을 어느 정도 해결하고 변수들간의 상관관계를 보니 조회수와 매우 높은 상관관계를 가지는 변수들이 발견되었고 모델 학습 결과 성능면에서도 효과(2.536->2.518)를 보았다.
모델 실험 과정
모델 선정 과정에서는 데이터가 범주형 피쳐들을 많이 포함하고 있다는 점에 착안하여 범주형 피쳐들을 모델에서 자체적으로 처리해 주는 CatBoost를 활용하였다. 내 추측이지만 위의 데이터 처리 과정에서 범주형 피쳐들을 처리했을 때 큰 효과가 없었던 이유가 CatBoost의 범주형 피쳐 자체 처리 기능 때문은 아닐지 생각이 된다.
모델 선정을 완료한 후에는 위에서 설명한 방법들 이외에도 다양한 방법들을 시도해 보며 성능을 테스트하였고 실험을 마무리한 다음에는 KFold와 앙상블을 활용해서 성능을 좀 더 끌어올렸다.
앙상블 과정에서는 과적합 방지와 모델 특성의 다양화를 위해 로그 변환을 적용한 데이터를 통해 학습한 모델과 로그 변환을 적용하지 않은 데이터를 통해 학습한 모델들을 조합해보았다.
대회 결과
PUBLIC 기준 60등

PRIVATE 기준 2등?
 리더보드 기준 361명이 참가한 대회에서 최종 순위 2등으로 수상에 성공을 했다. 퍼블릭 리더보드 기준으로 수상권과 많은 차이가 있어서 전혀 기대를 하지 않았었는데 프라이빗에서 2위라는 성적을 거두었다. Shake-up 현상이 이렇게까지 크게 일어날 줄은 몰랐는데 결과를 확인하고 매우 놀랐었다. 퍼블릭 리더보드에 집착하지 않고 자체 실험 결과에 집중을 했던 것이 효과가 있었던 것 같다.
리더보드 기준 361명이 참가한 대회에서 최종 순위 2등으로 수상에 성공을 했다. 퍼블릭 리더보드 기준으로 수상권과 많은 차이가 있어서 전혀 기대를 하지 않았었는데 프라이빗에서 2위라는 성적을 거두었다. Shake-up 현상이 이렇게까지 크게 일어날 줄은 몰랐는데 결과를 확인하고 매우 놀랐었다. 퍼블릭 리더보드에 집착하지 않고 자체 실험 결과에 집중을 했던 것이 효과가 있었던 것 같다.
대회 후기
내 예상보다 너무 좋은 성적을 거두어서 도대체 어떻게 했지라는 생각이 든다. 비록 큰 대회는 아니지만 약 반년 만의 수상이자 올해 첫 수상으로 오랜만에 나름의 성과를 낸 것 같다는 생각이 들어 기분이 좋았다.
앞으로도 종종 데이콘이나 공모전에 참가를 할 예정인데 이번 수상이 단지 초심자의 행운에 그치지 않도록 나의 실력을 키워서 앞으로도 성과를 낼 수 있도록 하고 싶다.
ps. 현재 데이콘에서 다른 해커톤에도 참가하고 있는 중인데 딥러닝은 정말 GPU 없이는 하기 힘든 것 같다. 내 개인 GPU가 너무 가지고 싶다.

고생하셨습니다.호일룬님 같이 대회해봐여 잼쓸거같아요