명령 프롬프트
- ⊞ Win+R를 누르세요. 그러면 실행 창이 열립니다.
- cmd를 입력하세요. 이는 명령 프롬프트를 여는 코드입니다.
- ↵ Enter를 누르세요. 그러면 일반 명령 프롬프트 창이 열립니다.

(*디렉터리 = 폴더)
코드 실행
- IDE 환경 (Integrated Development Environment)=> 제공하는 여러 개발도구를 활용해 개발. 실제 클라우드 자동화와 데이터 분석에 파이썬이 많이 활용되고 있습니다.
ex> VS code
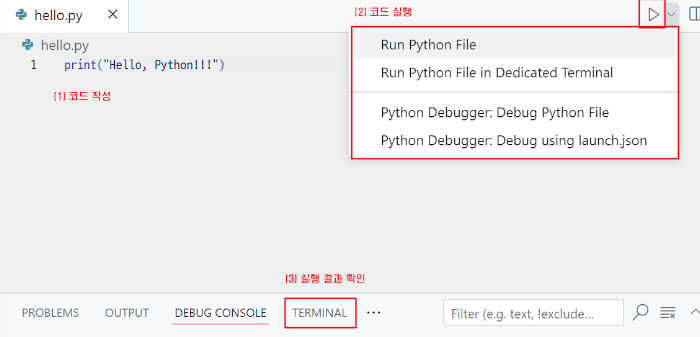
- CLI 환경 (Command Line Interface)=> 환경에서 파이썬 코드를 실행하면 바로 출력값이 나오므로 사용자와 상호작용 가능.
ex> cmd.exe
c:\python> python hello.py
Hello, Python!!!- 파이썬 대화형 인터프리터 (*cmd -> python shell)

가상환경
-파이썬 프로젝트는 종종 서로 다른 패키지 버전을 필요로 한다.
->But. 동일한 시스템에 여러 프로젝트를 설치할 경우, 하나의 프로젝트에서 요구하는 패키지 버전이 다른 여러 프로젝트에서 충돌을 일으킬 수 있습니다.
->>SO. 충돌을 방지하고 각 프로젝트의 독립성을 유지하기 위해 가상환경을 사용 합니다.
- 생성 ➤ 파이썬에 기본 내장 모듈
venv사용
c:\python> python -m venv myenv
~~~~~~~ ~~~~~
| |
| +-- 가상환경 이름 (사용자가 임의의 이름을 부여)
+-- venv 모듈(가상환경 기능을 제공하는 모듈)을 사용
⇒ 해당 디렉터리 아래에 가상환경 이름과 동일한 디렉터리가 생성되고, 가상환경과 관련한 파일들이 추가- 활성화 ➤ activate
c:\python> .\myenv\Scripts\activate ⇐ Mac 또는 Linux에서는 source myenv/bin/activate 명령으로 실행
(myenv) c:\python>
~~~~~~~
가상환경 쉘로 변경
- 비활성화 ➤ deactivate
(myenv) c:\python> deactivate
c:\python>
변수(variable)
: 데이터를 저장하기 위한 이름이 붙여진 저장소
type() 함수: 변수의 타입을 확인
<< 변수의 데이터 타입을 출력 >>
x = 10
print(type(x)) # <class 'int'>x = "Hello"
print(type(x)) # <class 'str'>
-int(integer): 정수 -str(string): 문자열, "~" -float: 실수형- strong typing(강력한 타입 시스템)-> 타입 자동변환x
EX.01
x = "123" # 문자열
y = 456 # 정수
print(x + y)
TypeError: can only concatenate str (not "int") to str
#~ ~ 문자열이 와야 하는 자리에 정수가 와서 오류가 발생
#|
#+-- 문자열 결합 연산자
<<오류 해결>>
str() 함수 -> 정수를 문자열로 변환
print(x + str(y)) # 123456int() 함수 -> 문자열을 정수로 변환
print(int(x) + y) # 579
- 변수 초기화 ➤ None ("값이 없음.")
x = None
print(x) # Nonea. 변수 초기화되어 None 설정된다. -> so.다른 값을 할당할 수 있다
b. 파이썬에서는 변수를 초기화하지 않고 선언할 수 없음명명 규칙(naming rule)
: 변수명, Class명, 함수명을 짓는 방식 rule
- 문자(A-Z, a-z), 숫자(0-9), 언더스코어(_)로 구성
- 숫자로 시작할 수 없음 // Ex. 'my_var1'(O) '1my_var'(X)
- 대소문자를 구분
a) CamelCase
-클래스를 표기할 때 사용한다.
-단어의 맨 앞글자가 대문자면서 띄어쓰기 부분이 대문자.
b) snake_case
-변수와 함수를 표기할 때 사용한다.
-단어마다 띄어쓰기 부분에 "__"를 추가"를 추가. - 변수 이름은 !, @, $, %와 같은 특수문자 사용X
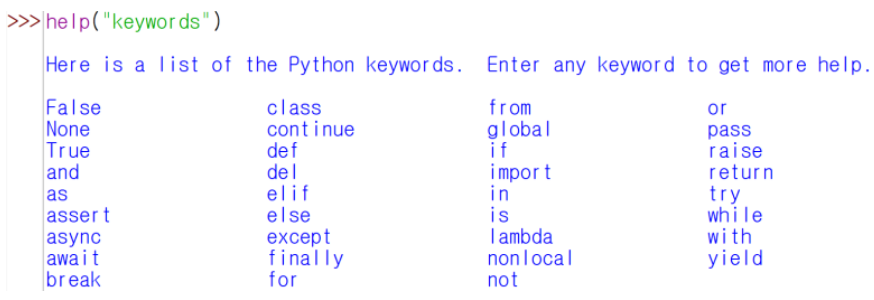
- 파이썬의 예약어(키워드)-> 변수 이름으로 사용X
지역변수 & 전역변수
-
지역 변수 (local_variable) 한정🔽
: 함수 내부에서 변수 선언 -> 해당 함수 내에서만 접근가능

 1)
1) 파이썬 함수만들기 :def 키워드를 사용하여 함수 정의.
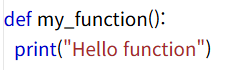
2) 함수호출 -> 함수이름과 괄호를 사용.

my_function()함수 호출되고, 함수 바디에 print() 구문 실행. -
전역 변수 (global_variable) 포괄🔼
: 함수 외부에서 변수 선언 -> 프로그램 전체에서 접근이 가능
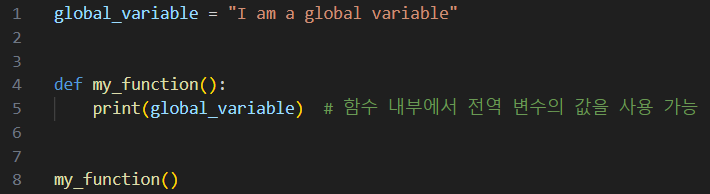

to.함수 내부에서 전역 변수의 값을 수정 ➤ global 키워드 사용
<A.case> global 키워드 없이 선언 ⇒ 함수 내부에서 지역 변수로 사용 및 정의!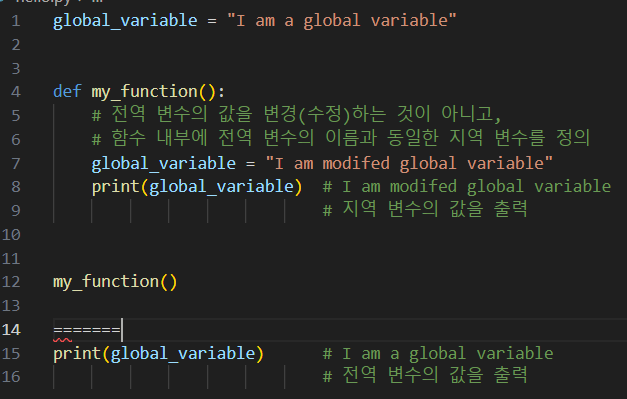 <B.case> global 키워드를 사용 ⇒ 함수 내부에서 전역 변수 수정이 가능
<B.case> global 키워드를 사용 ⇒ 함수 내부에서 전역 변수 수정이 가능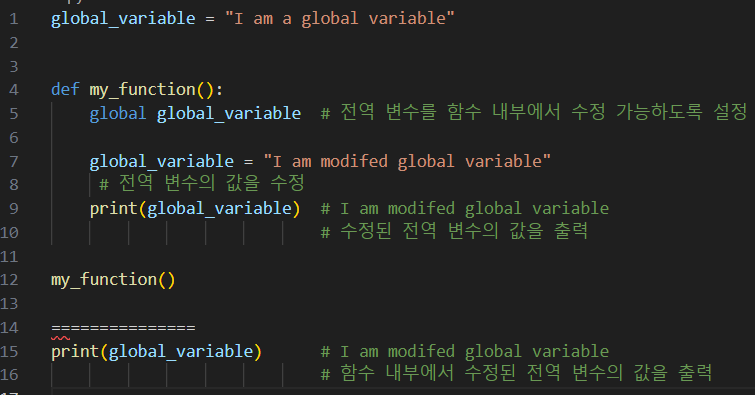
데이터 타입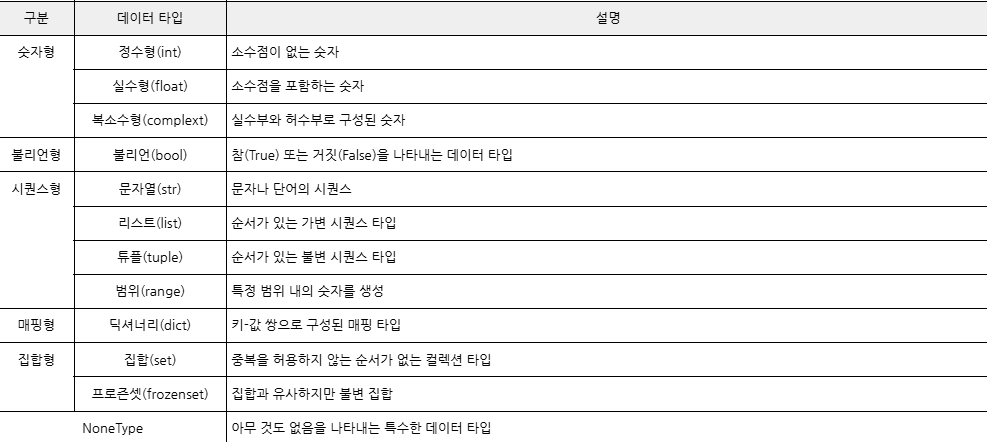
💙list[ ] tuple( ) dict{ }- 숫자형
- 정수형(int)
a = 10 # 양의 정수
b = -5 # 음의 정수
c = 1234567890 # 정수의 크기에 제한 없음
2. 실수형(float)
a = 3.14
b = -0.001
c = 2.5e3 # 2.5 * 10^3 = 2500.0
- 불리언(bool)
a = True
b = False- 시퀀스형
- 문자열(str)
-Ex>'That is Alice's cat.' 입력 => Alice 뒤에서 끝나고 나머지(s cat.')는
유효하지 않은 파이썬 코드.
-a. 큰따옴표
: 큰 따옴표( " )를 사용해서 문자열에 작은 따옴표 문자 포함가능.
>>> spam = "That is Alice's cat." -b. 이스케이프 문자
: 이스케이프 시퀀스를 따르는 문자들로서 다음 문자가 특수 문자임을 알리는
백슬래시(\)를 사용
<Ex>
a = 'Hello, "MY" \'MY\' world!'
b = "My 'Python' \"Python\" Programming"
c = '''I'm
a
student.''' # docstring
d = """Python
is
"Very" 'very'
fun!""" # docstring
print(c)
print(d)
(*독스트링(docstring) : Python에서 함수, 클래스, 모듈 또는 메서드에 대한 설명을 작성하는 데 사용되는 문자열.)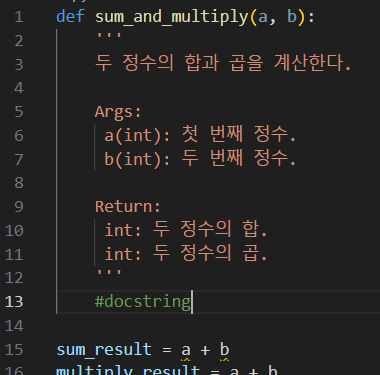
- 리스트(list) : 순서가 있는
가변시퀀스 타입
<구현>
d = list('hello')
print(d) #['h', 'e', 'l', 'l', 'o']-여러 데이터 타입을 혼합하여 저장할 수 있음mixed = [1, 'Hello', 3.14, True, [1, 2, 3], {'name': 'Alice'}]
💙[ ]사용 / 변수 값 변경가능가] 인덱싱(indexing):행렬의 한 요소 위치 지정 후 값 추출/수정
a. index.좌표값 ->indexing.좌표값 지정
b. 0부터 시작 / -1 거꾸로 시작, 마지막 값list = ['a', 'b', 'c', 'd'] print(list[2]) #c <중첩 리스트> a = [1,2,3,['a', 'b', 'c']] print(a[-1][1]) #b나] 슬라이싱(slicing):행렬의 2개 이상 요소 위치 지정 후 값 추출/수정
a.클론(:)사용 c. 0 시작/-1 거꾸로
b.[start-이상 : end-미만 : step-간격]list = [1,2,3,4,5,6,7,8] print(list[0:6:2]) #[1, 3, 5] numbers = [1,2,3,4,5,6,7,8] print(numbers[::-1]) #[8, 7, 6, 5, 4, 3, 2, 1] print(a[:]) # 처음부터 끝까지 <중첩 리스트> a = [1, 2, 3, ['a', 'b', 'c'], 4, 5] print(a[3][:2]) #['a', 'b']
✔️<<수정> a = [1, 2, 3] a[2] = 4 print(a) #[1,2,4] ✔️<<삭제> del 함수 a = [1, 2, 3, 4, 5] b = [1, 2, 3, 4, 5] del(a[1]) # 리스트 a의 1번 index 삭제 del(b[:4]) # 리스트 b의 0번 index부터 3번 index까지 삭제 print(a) print(b) #[1, 3, 4, 5][5]다]메서드(method)
list method
- 튜플(tuple) : 순서가 있는
불변시퀀스 타입
empty_tuple = ()
numbers = (1, 2, 3, 4, 5)
strings = ('Hello', 'World')-여러 데이터 타입을 혼합하여 저장할 수 있음mixed = (1, 'Hello', 3.14, True, [1, 2, 3], {'name': 'Alice'})-하나의 데이터만 가지는 튜플은 콤마(,)를 붙여야 함
⤷ why. "변수명 = (2), tuple = (2,)" 구분 위함.
int 타입(다른 데이터 타입)으로 인식 single = (1,)
print(type(single)) # <class 'tuple'>
💙( )사용 / 변경불가능(immutable): 요소 추가,삭제, 수정 등 값 변경X
▶️when. 파이썬에서 데이터를 보호하고 싶을 때 사용가]메서드(method)
tuple method
- 범위(range) :
불편시퀀스 타입
-리스트와 달리 시작/종료 단계(step) 값만 저장
-실제 값은 필요할 때마다 생성하는 방식
a = range(10) # 0부터 9까지의 범위
print(a) # range(0, 10)
print(list(a)) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
a = range(5, 10) # 5부터 9까지의 범위
print(a) # range(5, 10)
print(list(a)) # [5, 6, 7, 8, 9]
a = range(2, 10, 2) # 2부터 9까지의 범위, 단계는 2
print(a) # range(2, 10, 2)
print(list(a)) # [2, 4, 6, 8]- 매핑형
- 딕셔너리(dict)
💙{ }, dict함수
-{key-키 : value-값}으로 구성된 매핑 자료형↪️ key= 불변 데이터 타입(문자열 or 숫자) value= 어떤 데이터 타입 가능
<dict 선언> - dict() 함수
my_information = dict({'name': 'Boyeon', 'age': 29, 'location': 'Seoul'})
print(my_information)
#{'name': 'Boyeon', 'age': 29, 'location': 'Seoul'}가]메서드. method
dict - function & method
a. len( ): 사전의 총 길이 (total length of Dictionary)⤷ 인수로 전달된 객체의 총 길이 = '키-값' 총 개수my_information = {'name': 'Dionysia', 'age': 28, 'location': 'Athens'} print(len(my_information)) #3✔️<<추가>> info = dict({'name': 'Boyeon', 'age': 29, 'location': 'Seoul'}) info['삼성전자'] = "005930" print(info) #{'name': 'Boyeon', 'age': 29, 'location': 'Seoul', '삼성전자': '005930'} ✔️<<삭제>> del 함수 info = dict({'name': 'Boyeon', 'age': 29, 'location': 'Seoul'}) del info['name'] print(info) #{'age': 29, 'location': 'Seoul'}
- 집합형
- 집합(set)
💙{ }, set함수
-교집합, 합집합, 차집합 등 다양한 집합 연산 지원.
-중복된 값을 허용하지 않고, 순서가 없는 자료형⤷ Ex. {1,3,3,2} => {1,2,3} 저장됨.
<<IF.중복>>
set01 = {1,2,3,4,5}
print('set01 = ',set01) #set01 = {1, 2, 3, 4, 5}
set02 = {1,3,3,2,2}
print('set02 = ', set02) #set02 = {1, 2, 3}
<<생성>>
◼️ 중괄호를 사용하여 집합 생성
fruits = {"apple", "banana", "cherry"}
print(fruits) #{'apple', 'banana', 'cherry'}
◼️ set() 함수를 사용하여 집합 생성
numbers = set([1, 2, 3, 4, 4, 5])
print(numbers) #{1, 2, 3, 4, 5}
<<집합 연산>>
set1 = {1, 2, 3}
set2 = {3, 4, 5}
◼️ 합집합 ➰( | ) (union 함수)➰
> print(set1.union(set2)) #{1, 2, 3, 4, 5}
> print(set1 | set2) #{1, 2, 3, 4, 5}
◼️ 교집합 ➰( & ) (intersection 함수)➰
> print(set1.intersection(set2)) #{3}
> print(set1 & set2) #{3}
◼️ 차집합 ➰( - ) (difference 함수)➰
> print(set1.difference(set2)) #{1, 2}
> print(set1 - set2) #{1, 2}
◼️ 대상 차집합 : 합집합 - 교집합 ➰(^)(symmetric 함수)➰
>print(set1.symmetric_difference(set2)) #{1, 2, 4, 5}
>print(set1^set2) #{1, 2, 4, 5}
가] 메서드.method
set method
1. add( ) - 단일 데이터 추가s = set([1,2,3,4]) s. add(10) print(s) #{1, 2, 3, 4, 10}
- update( ) - 여러 데이터 추가
s = set([1,2,3,4]) s.update([6,6,7,9,5,0]) print(s) #{0, 1, 2, 3, 4, 5, 6, 7, 9}
- remove( ) - 단일 데이터 삭제
s = set([1,2,3,4]) s.remove(2) print(s) #{1, 3, 4}
- clear( ) - 전체 삭제
s = set([1,2,3,4]) s.clear() print(s) #set()
- 프로즌셋(frozenset) :
불변집합
-중복 허용X, 순서 제멋대로 출력.
-구조 비슷 ≒ 'set' ≠ 추가 및 제거X
x = frozenset([1, 5, '고정', (3.3, 4.4)])
print(x) #frozenset({(3.3, 4.4), 1, '고정', 5})- NoneType - 데이터 값 없음.
데이터 타입 변환
- 암시적 형 변환(implicit type conversion)
: 파이썬 인터프리터가자동수행하는 type 변환
- 변환시점
가] 정수 & 실수의 연산
나] bool & 정수의 연산 (>>a = 5 b = 2.0 result = a + b print(result) # 7.0 (⇒ 실수로 변환됨)True = 1, False = 0변환)a = True b = False sum_result = a + 5 product_result = b * 10 print("a + 5 =", sum_result) #a + 5 = 6 print("b * 10 =", product_result) #b * 10 = 0
- 명시적 형 변환(explicit type conversion)
: 프로그래머가직접지정하는 type 변환 +숫자형 타입만 OK
- 정수형 -> 실수형
x = 10
y = float(x)
print(y) # 10.0
print(type(y)) # <class 'float'>
- 실수형 -> 정수형
x = 10.5
y = int(x)
print(y) # 10
print(type(y)) # <class 'int'>- 문자열 -> 정수형 ( * 형식에 맞는
숫자만가능 )
x = "10"
y = int(x)
print(y) # 10
print(type(y)) # <class 'int'>- 정수형 -> 문자열
x = 123
y = str(x)
print(y) # 123
print(type(y)) # <class 'str'>
산술 연산자
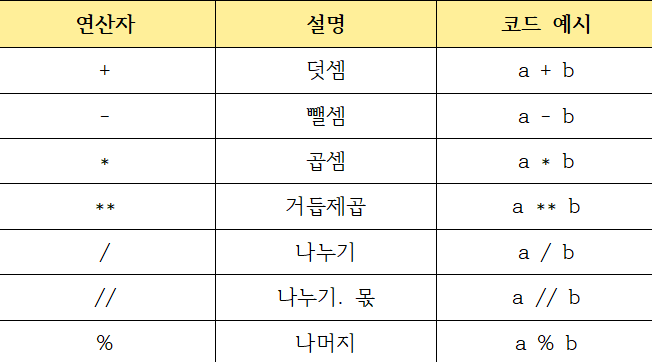
1. +. 덧셈
a = 10
b = 20
c = a + b
>print(c) # 30
a = 10.0
b = 20.0
c = a + b
>print(c) # 30.0-, 빼기
a = 10
b = 3
c = a - b
>print(c) #7*, 곱셈
a = 2
b = 5
c = a*b
>print(c) #10
/, 나누기, ➔ 결과로실수형반환
a = 10
b = 20
d = b / a
>print(d) # 2.0//, 나누기-몫 ➔ 결과로정수형반환
a = 10
b = 20
e = b // a
>print(e) # 2%, 나머지 ➔정수형반환
a = 10
b = 20
f = b % a
print(f) # 0**, 거듭제곱
a = 2
b = 3
g = a ** b
print(g) #8 단항 연산자
: 하나의 *피연산자만 사용하는 연산자
(*연산자가 계산 및 작업을 수행할 때 사용되는 값/변수)a = 5 b = -3 c = True
- 양수 (+)
xy = +b print("xy =", xy) #xy = -3
- 음수 (-)
xy = -a print("xy =",xy) #xy = -5
- 논리 부정 (not)
xy = not c print("xy =",xy) #xy = False
비교 연산자
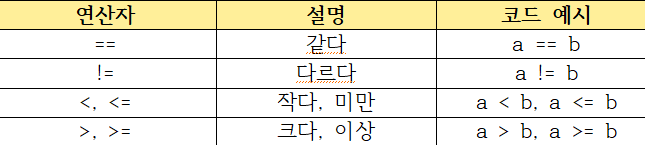 1.
1. >, 크다
a = 10
b = 5
xi = (a > b)
print("a > b:", xi) #a > b: True<, 작다
less_than = (a < b)
print("a < b:", less_than) #a < b: False==,is, 같다 ≠!=,is not, 다르다

가] == (동치관계) ≠ !=⤷ (+) 객체 고유값 동일
<< = >>
l1 = [1, 2, 3]
l2 = l1
l3 = [1, 2, 3]
print(l1 == l2) #True
print(l1 == l3) #True
<< != >>
print(l1 != l2) #False
print(l2 != l3) #False나] is (동일관계) ▶️ id( ) ≠ is not
<<is>>
l1 = [1, 2, 3]
l2 = l1
l3 = [1, 2, 3]
print(l1 is l2) #True
print(l1 is l3) #False
#객체 고유값 확인
print(id(l1)) #2216383766656
print(id(l2)) #2216383766656
print(id(l3)) #2216383914944
<<is not>>
list1 = [1, 2, 3]
list2 = [1, 2, 3]
list3 = list1
print(list1 is not list2) #True
print(list1 is not list3) #False
#객체 고유값 확인
print(id(list1)) #2851323666560
print(id(list2)) #2851323814848
print(id(list3)) #2851323666560