
데이터베이스 적제
- USE > maridb ➔ 로컬 PC에 설치
- 데이터베이스 >
특징
- local 설치 > 방식
- 🚩 인스톨 (maridb)
- 도커
- 클라우드 설치
😻코랩에서 바로 진행 가능
Ex > 패키지 설치

Ex.01 > pandas 패키지 설치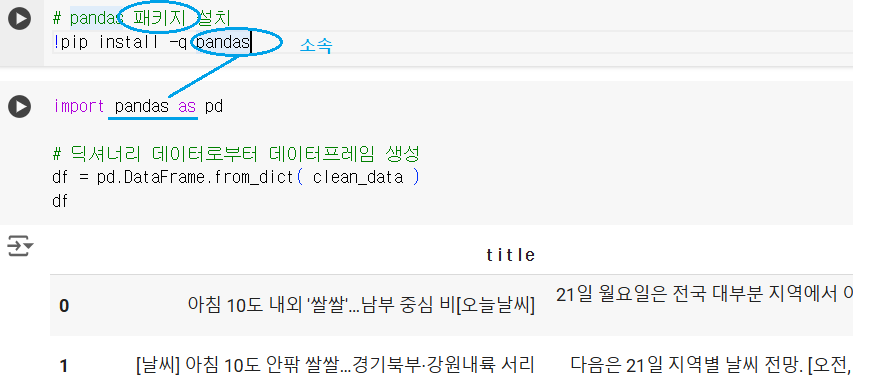
🔽🔽🔽Ex.02 > 데이터베이스 적제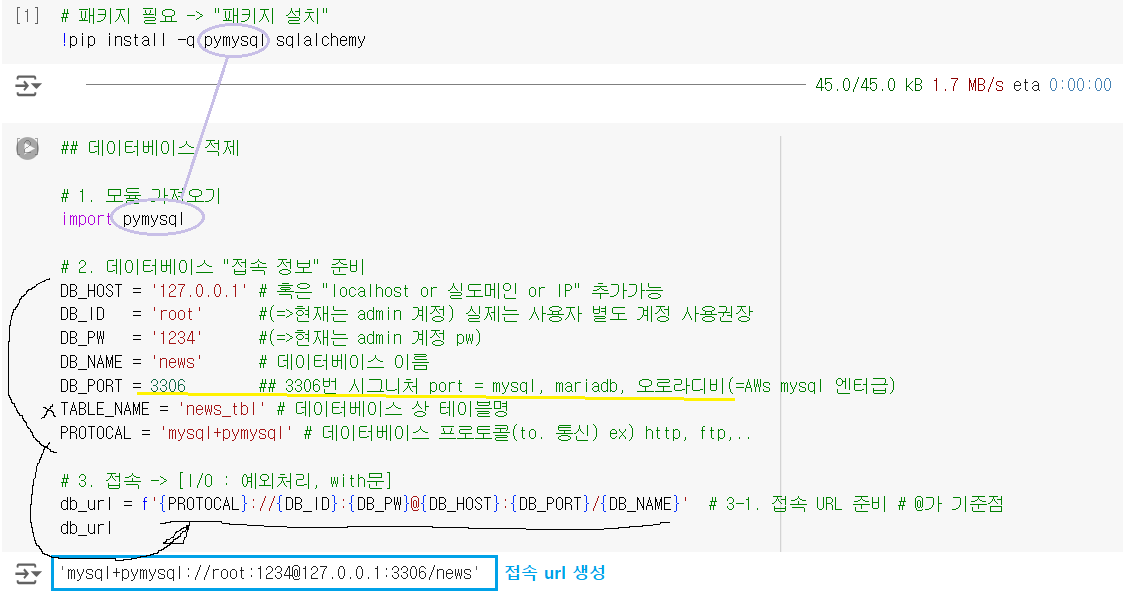
DB 연동 코드
<< 연동 흐름 >>
- 파이썬 🔁 pymysql(패키지) 🔁 sqlalchemy(패키지) 🔁 mariadb
- 데이터 관점
: list(dict, ..) ➜ DataFrame 로 변형 ➜ sql 변형 ➜ DB에 저장
Ex.01 > 실물 DB 존재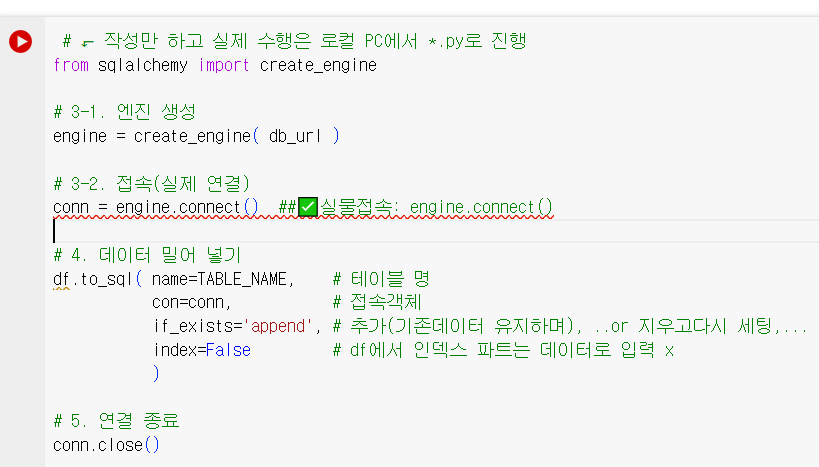
📚 참고

파이썬 덤프
- USE: vscode
- 파일: *.py
준비 > 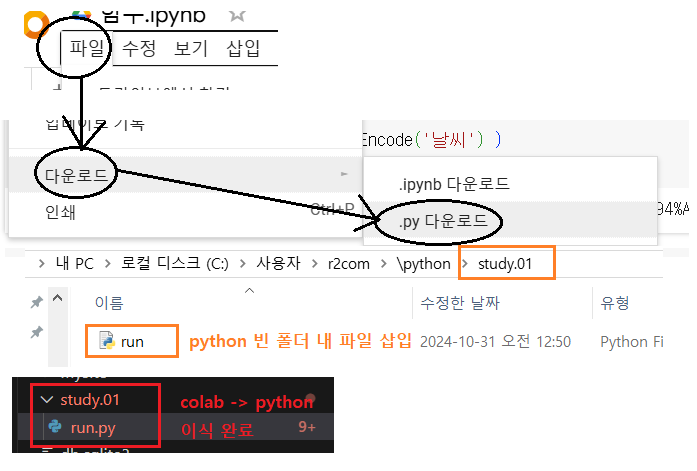
코드 정리 >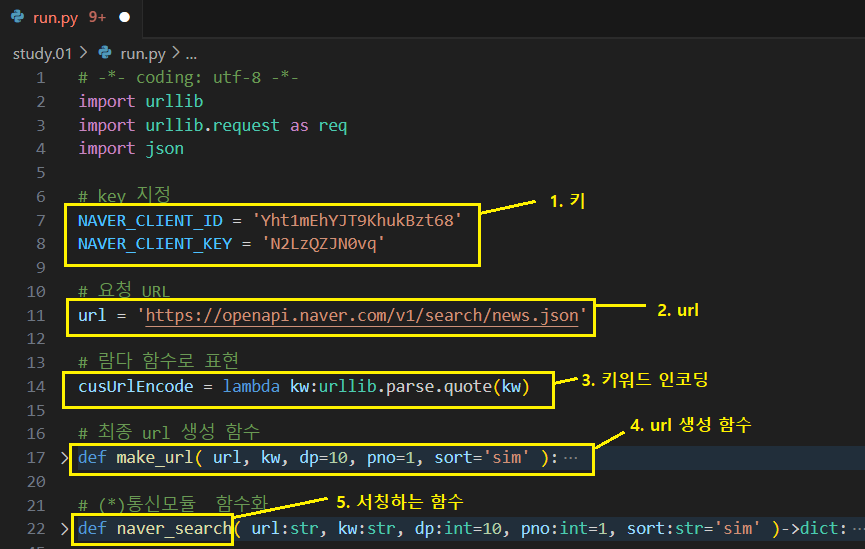
오류(빨간줄) 정리 >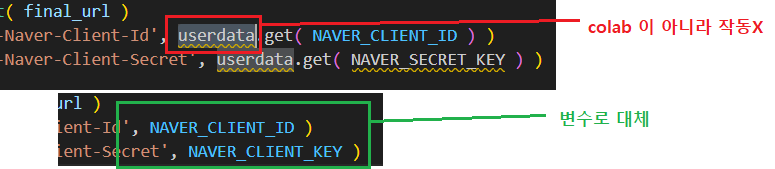
DB 세팅 >데이터베이스 만들기 (2방법): sql, tool
- sql로 만들기

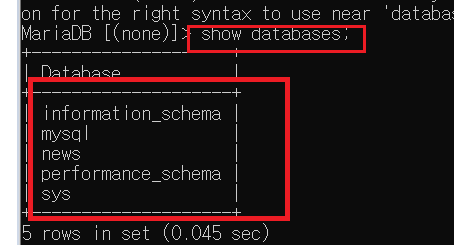
To. DB 결과 확인>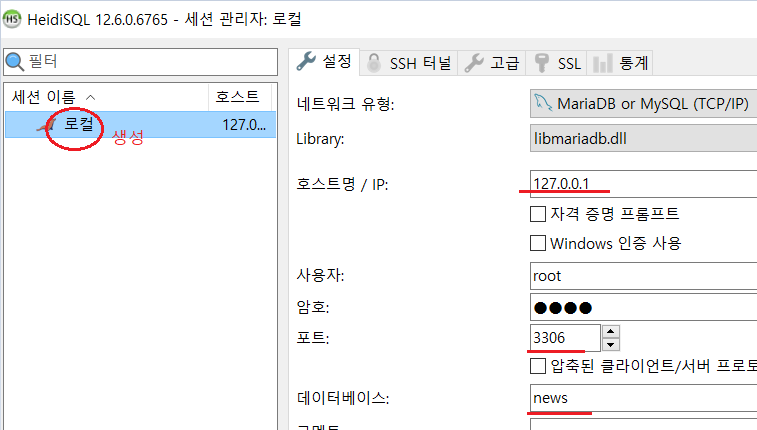
가상환경 생성 및 접속 >

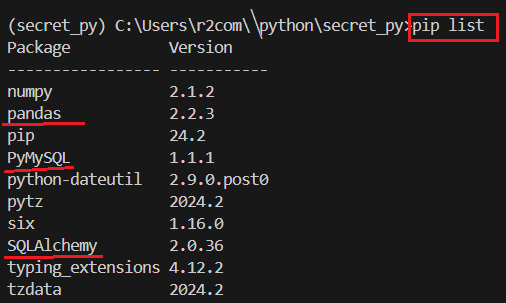
IN. 가상환경, 패키지(써드파트) 설치 > pandas, pymysql, sqlalchemy -3가지
import urllib
import urllib.request as req
import json
import html
import re
import pandas as pd
from sqlalchemy import create_engine
# 키 지정
NAVER_CLIENT_ID = '본인 ID값' <-입력하기
NAVER_SECRET_KEY = '본인 KEY값'
# 2. 요청 URL
url = 'https://openapi.naver.com/v1/search/news.json'
# 람다 함수로 표현
cusUrlEncode = lambda kw:urllib.parse.quote( kw )
def make_url( url, kw, dp=10, pno=1, sort='sim' ):
# 기본형 구현후 => 확장성 고려(다른 매개변수가 변경된다면?) => 함수 업그레이드 햇음
return f'{url}?query={kw}&display={dp}&start={pno}&sort={sort}'
"""#### (*)통신모듈 함수화"""
def naver_search( url:str, kw:str, dp:int=10, pno:int=1, sort:str='sim' )->dict:
'''
네이버 검색 API를 이용한 결과 획득 함수
Paramers:
...
Returns:
...
'''
final_url = make_url( url, cusUrlEncode(kw), dp, pno, sort )
request = req.Request( final_url )
# 아이디와 키 세팅부분 조정
request.add_header( 'X-Naver-Client-Id', NAVER_CLIENT_ID )
request.add_header( 'X-Naver-Client-Secret', NAVER_SECRET_KEY )
try:
response = req.urlopen( request ) # I/O -> 예외처리
if response.getcode() == 200:
# 만약, 응답데이터에서 인코딩오류가 발생한다면 => 인코딩처리후 반환
return json.load( response )
else:
print( '통신 오류' )
return {}
except Exception as e:
print( e )
return {}
"""#### (*)파싱모듈 함수화"""
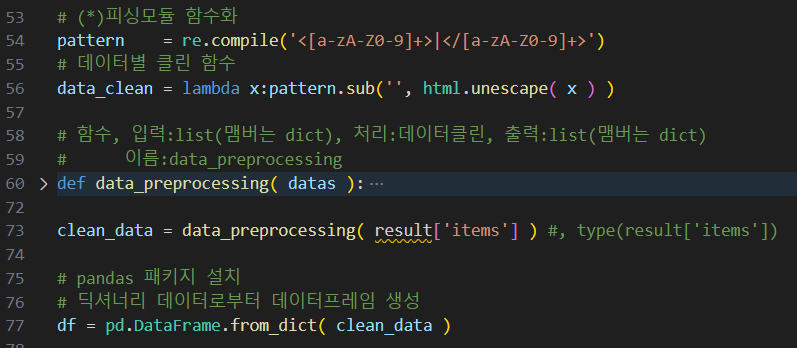
# 정규식 패턴 (html 태그 체크)
pattern = re.compile('<[a-zA-Z0-9]+>|</[a-zA-Z0-9]+>')
# 데이터별 클린 함수
data_clean = lambda x:pattern.sub('', html.unescape( x ) )
# 함수, 입력:list(맴버는 dict), 처리:데이터클린, 출력:list(맴버는 dict)
# 이름:data_preprocessing
def data_preprocessing( datas ):
results = list()
# ...
for news in datas:
# 원래 뉴스 데이터 -> 전처리 -> 다시 세팅
# 필요한 데이터만 세팅, 이름 조정
results.append({
'title' : data_clean( news['title'] ),
'desc' : data_clean( news['description'] ),
'pubDate': data_clean( news['pubDate'] )
})
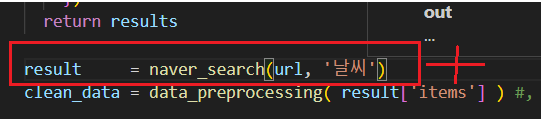
return results
# 조치2 -> 통신오류 나는 경우, 아래코드 추가
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
result = naver_search( url, '뉴스')
print(result) # {}
clean_data = data_preprocessing( result['items'] ) #, type(result['items'])
# pandas 패키지 설치
# 딕셔너리 데이터로부터 데이터프레임 생성
df = pd.DataFrame.from_dict( clean_data )
# 패키지 설치
# 1. 모듈 가져오기
# import pymysql
# 2. 데이터베이스 접속 정보 준비
DB_HOST = '127.0.0.1' # 혹은 localhost, 실도메인(IP)
DB_ID = 'root' # admin 계정이라 실제는 별도 계정 사용권장
DB_PW = '****' # <- admin 계정의 비밀번호 입력하기
DB_NAME = 'news' # 사용할 데이터베이스 이름
DB_PORT = 3306 # mysql, mariadb, 오로라디비(AWs mysql 엔터급)
TABLE_NAME = 'news_tbl' # 데이터베이스상 테이블명
PROTOCAL = 'mysql+pymysql' # 데이터베이스 프로토콜 ex) http, ftp,..
# 3. 접속 -> I/O : 예외처리, with문
# 3-1. 접속 URL 준비
db_url = f'{PROTOCAL}://{DB_ID}:{DB_PW}@{DB_HOST}:{DB_PORT}/{DB_NAME}'
# 3-2. 엔진 생성
engine = create_engine( db_url )
# 3-3. 접속(실제 연결)
conn = engine.connect()
# 4. 데이터 밀어 넣기
df.to_sql( name=TABLE_NAME, # 테이블명
con=conn, # 접속객체
if_exists='append', # 추가(기존데이터유지), ..지우고다시 세팅,...
index=False # df에서 인덱스 파트는 데이터로 입력 x
)
# 5. 연결 종료
conn.close() 🔽🔽🔽
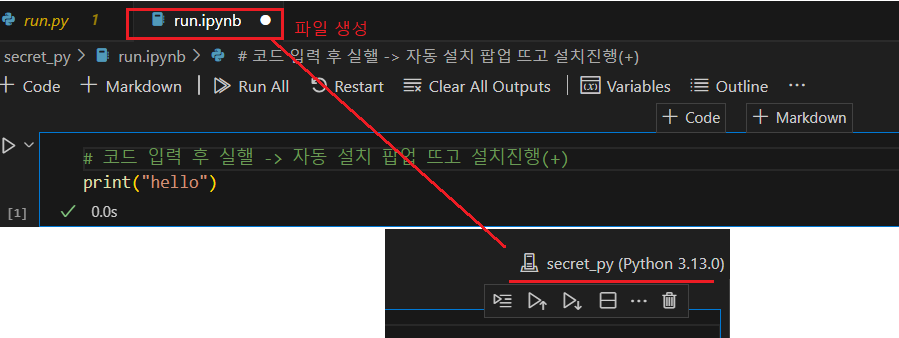
data tablet 생성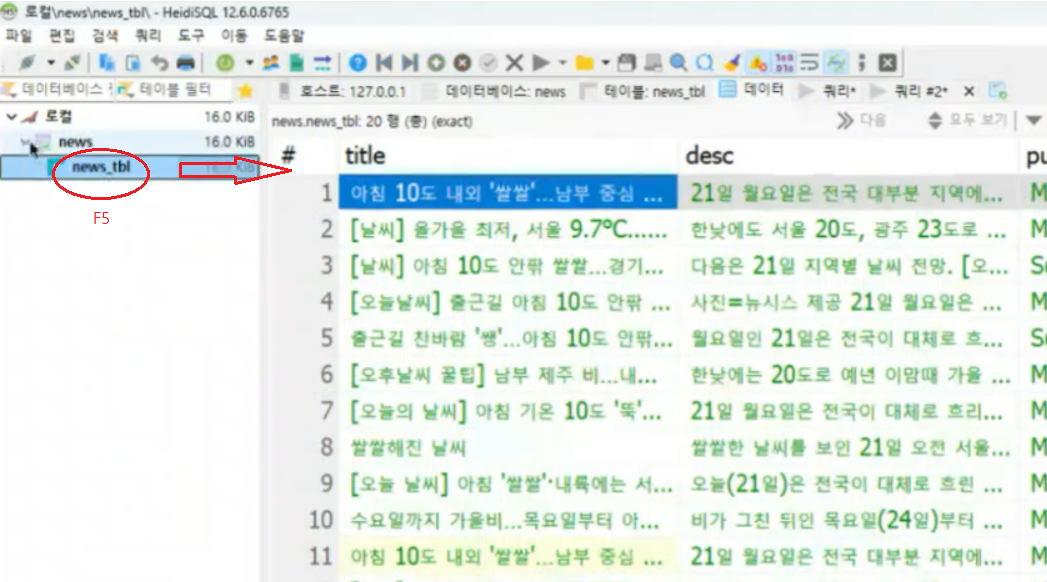
📚 mysql <<명령어>>
- DB 목록보기 : show databases;
- 새로운 DB 목록 만들기 : create database DB명;
- 나가기 : exit;
자동화
- USE
- 💥윈도우:
작업스케줄러<< 절차 >>
- 윈도우 하단 [스케줄러] 검색 > 실행
- 우측 작업 만들기 > 새작업 만들기
- 일반 탭
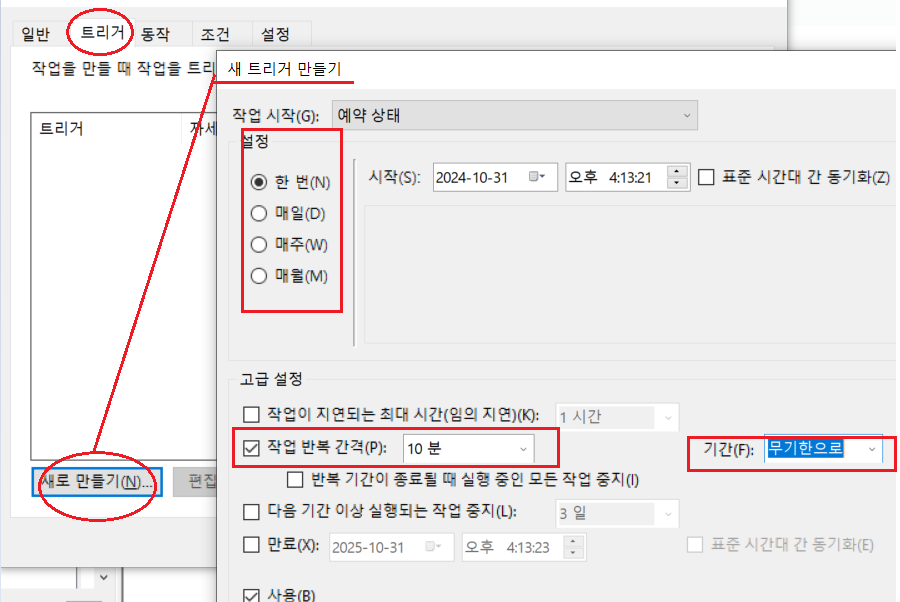
-이름, 설명 - 트리거 (= 작업동작 시간 설정)
-Ex.고급: 작업반복시간 -10분 / 무제한 - 동작
-트리거 스케줄에 맞추어 파이썬 파일을 작동한다.
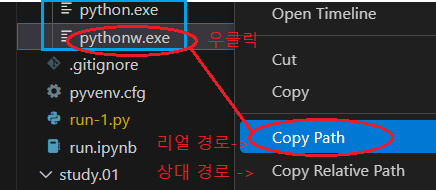
-재료: 작업 디렉토리, 파이썬 파일명, python.exe|pythonw.exe
-python.exe|pythonw.exe= 가상환경에 존재하는 파일로 세팅
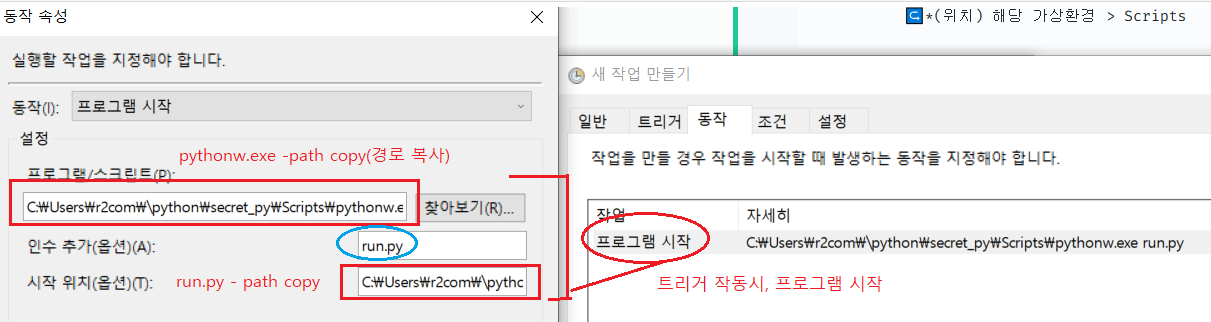
🔹(1) 가상환경 사용↪️*(위치) 해당 가상환경 > Scripts
C:\Users\r2com\⧹python\secret_py\Scripts\pythonw.exe🔹(2) OS에 설치된 파이썬 사용자 (환경변수에 classpath가 잡혔다면)
pythonw.exe-인수추가 : Ex > run.py
-시작위치 : Ex > C:\Users\r2com\⧹python\secret_py - 리눅스: cron (*참고)
 ↪️C:\Users\r2com\⧹python\secret_py\Scripts\pythonw.exe
↪️C:\Users\r2com\⧹python\secret_py\Scripts\pythonw.exe
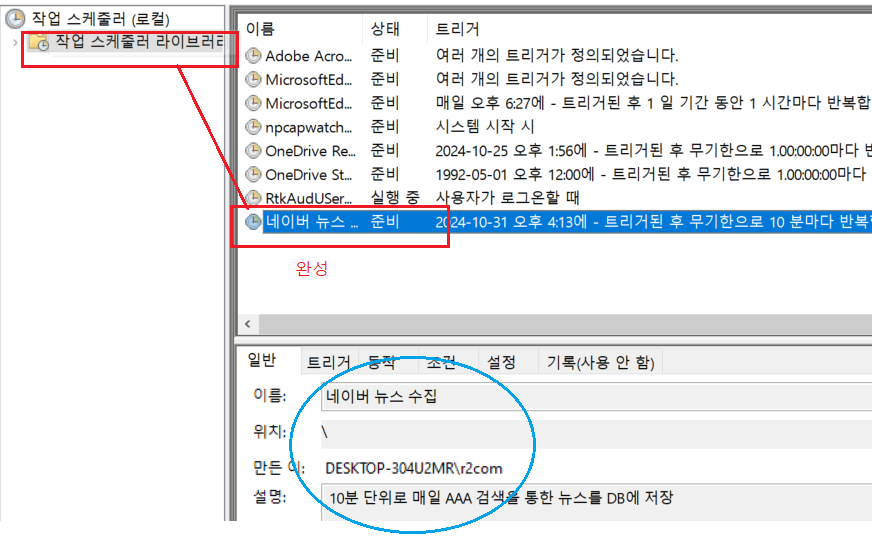
작동 확인 >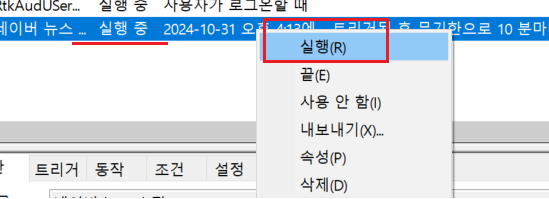
- 💥윈도우:
📚 마무리 정리

