workflow
(A). Part1
= 사이트에 접속해서 웹문서를 긁어온다
▶ [[ 절차 ]]
1. 타겟 사이트 선정 및 분석
<<만족조건>>- 원하는 데이터가 API로 제공되지 않는다 (API 없음,)
- 특정 사이트에 접속만 하면 정보가 바로 확인된다 (별도 노력X)
접속
<<방법>>- 💥urlib.request
-순수 파이썬
-http의 method 방식은 주로 💥Get, Post도 가능 - urlib3
-써드파트 라이브러리 - Requests
-써드파트 라이브러리
웹문서를 긁어온다
= 응답 데이터를 준비 한다
<<응답 데이터>>-
웹문서 = html5 + css3 + js
⤷ 데이터: 👉html에 포함되어 있다 (*html: 문서의 구조와 콘텐츠(데이터)를 가지고 있다)
📚참고 > 데이터관점 분류
- 👉반정형 데이터: html, xml, json
- 정형데이터: 데이터베이스
- 비정형데이터 : 바이너리데이터, 이미지, 동영상, 음원...
(B). Part2
= raw 데이터에서 의미있는 데이터를 추출한다
▶ [[ 절차 ]]
1. html 문자열 -> 파싱
- 파싱[parsing]: html -> DOM으로 변환되는 과정
- To.파싱 작업 -> 도구필요 : 파서[parser]
- 파서[parser]
- html5lib 도구를 사용예정
- 처리속도는 상대적으로 느리지만, 큰 문서도 안정적으로 처리
(정보손실 X)
DOM[돔]/(문서객체모델) - 탐색(CSS selector xpath)
- To. 탐색
- CSS selector는 html 문서의 요소(엘리먼트)를 특정하는 표현식
데이터 추출
<<방법>>- bs4(beautiful soup) 사용
: html을 문서(스프)에 넣고 필요한 데이터를 뽑아낸다
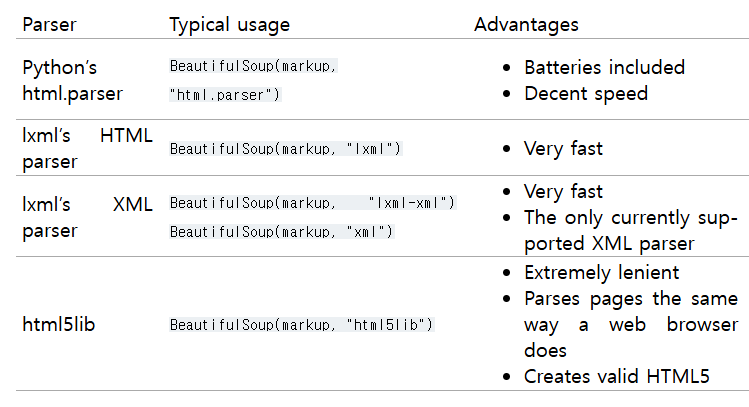 Parser
Parser(*모든 파싱도구에는 Parser에 대한 표현이 나온다.)
(C). 이후(생략)
- 최종결과물 뽑아내기
[
{
'컬럼명':값
,...
}
,...
]
- df 구성
- DB 저장
- 자동화 처리
(d). 특이 스타일
- 사이트 난이도에 따라서 웹 크롤링방식아 혼용하여 작업 가능
Ex-1 > Dev Tools = ctrl + shift + J / 우클릭 + 검사 / F12
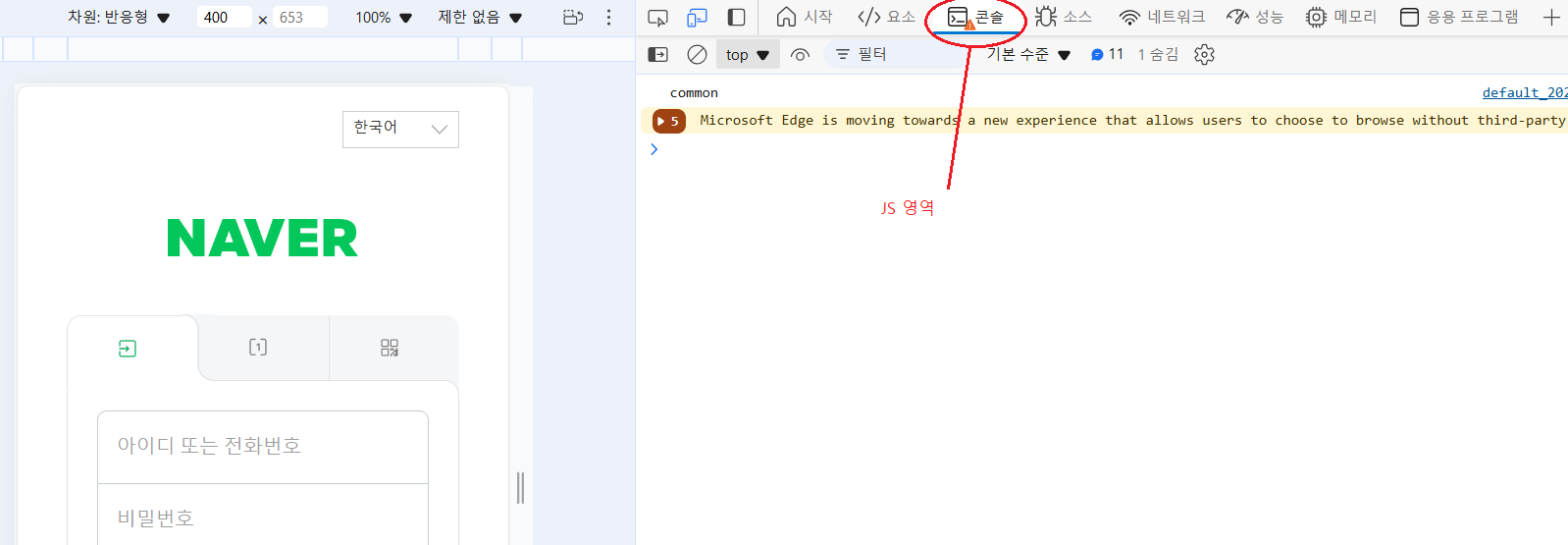
Ex-2 > 요소[element] = ctrl + shift + I
- 프론트엔드 담당
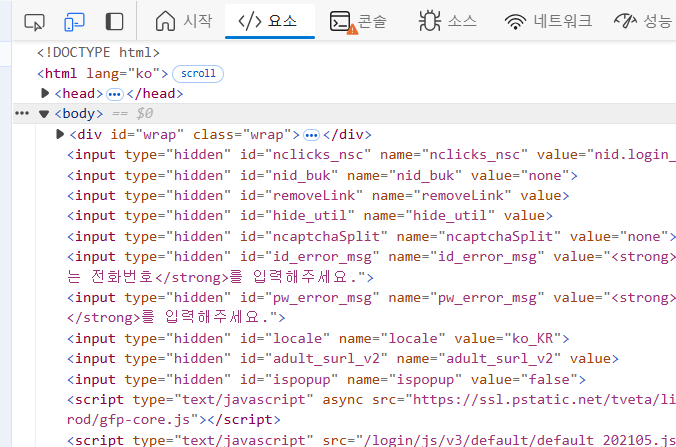
Ex-3 > CSS selector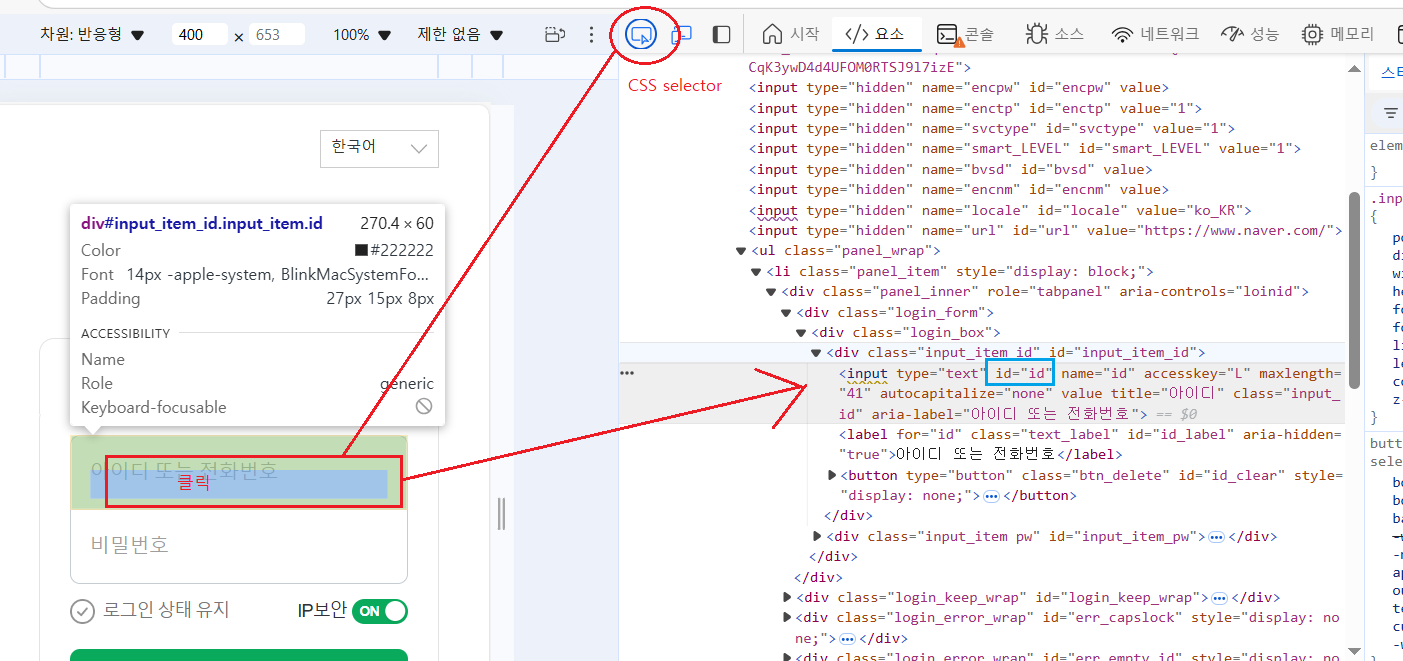
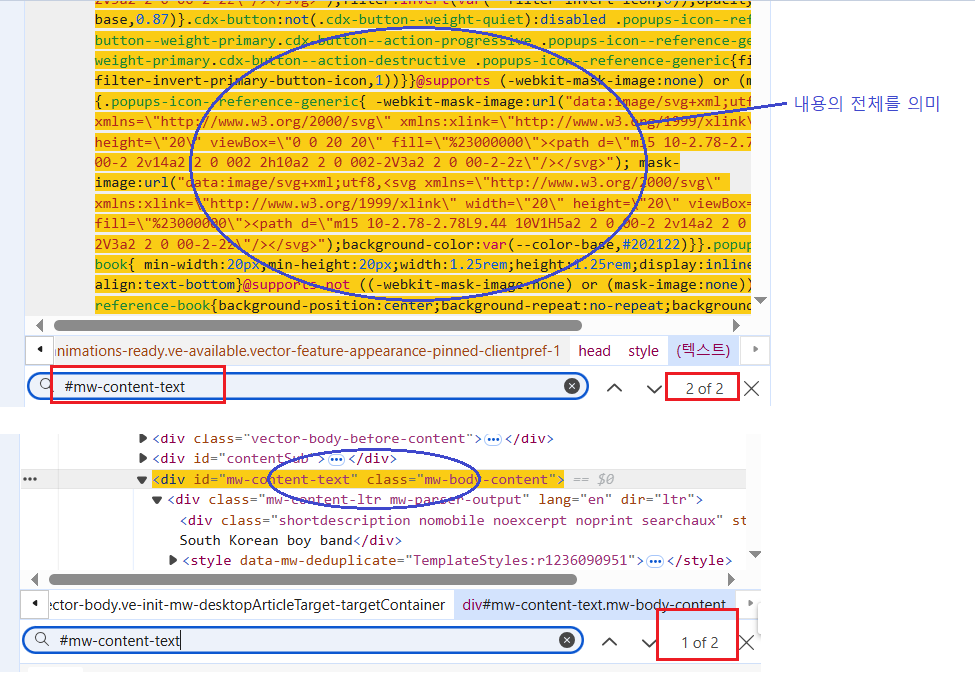
Ex-3-1 > 탐색기(str/selector/xpath) =ctrl + F
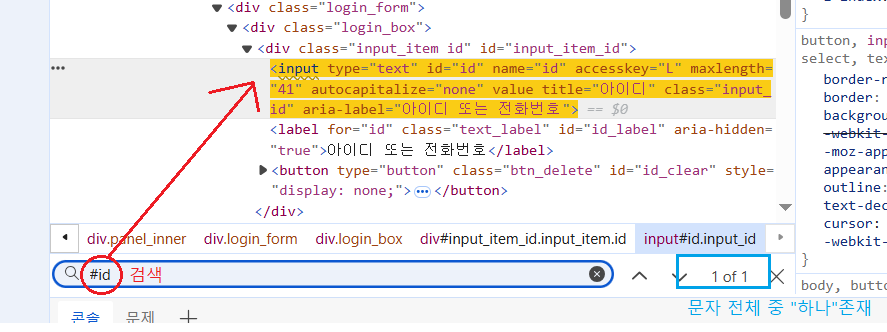
Ex-4 > pw값 탐색↪️ css selector = "#id"로 문자하나를 특정한다.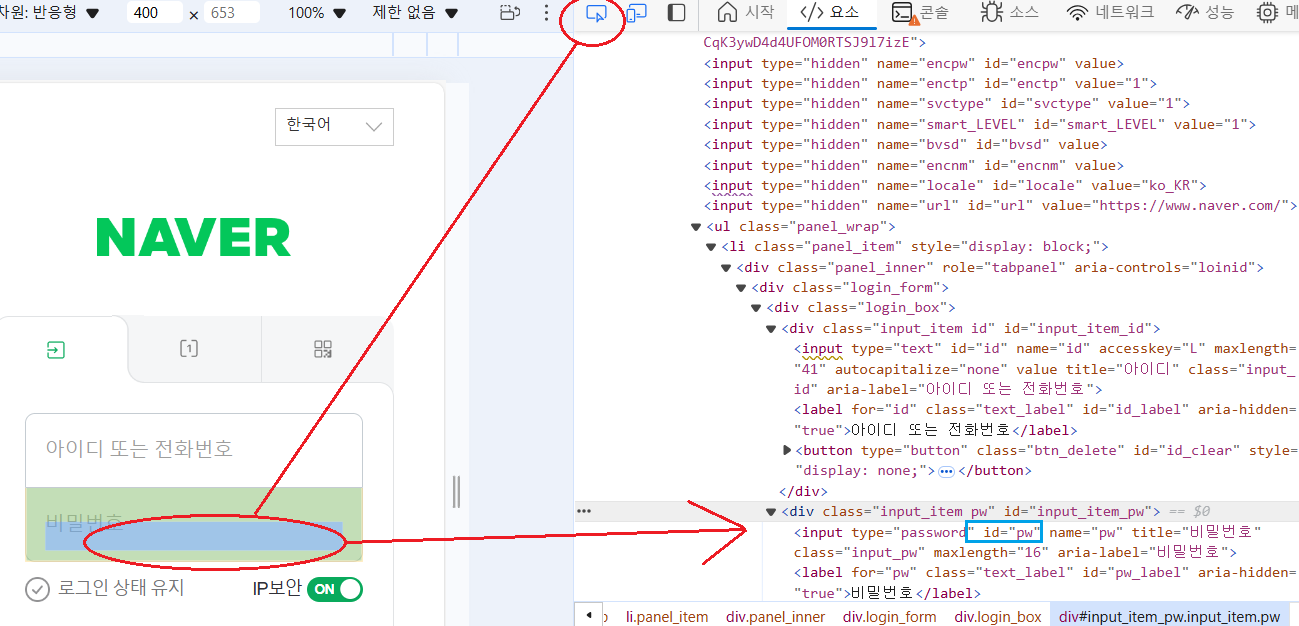
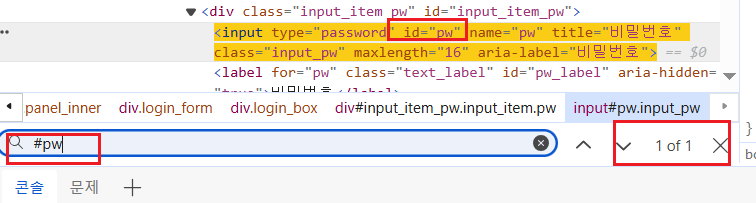
Ex-A > 텍스트 내용만 긁기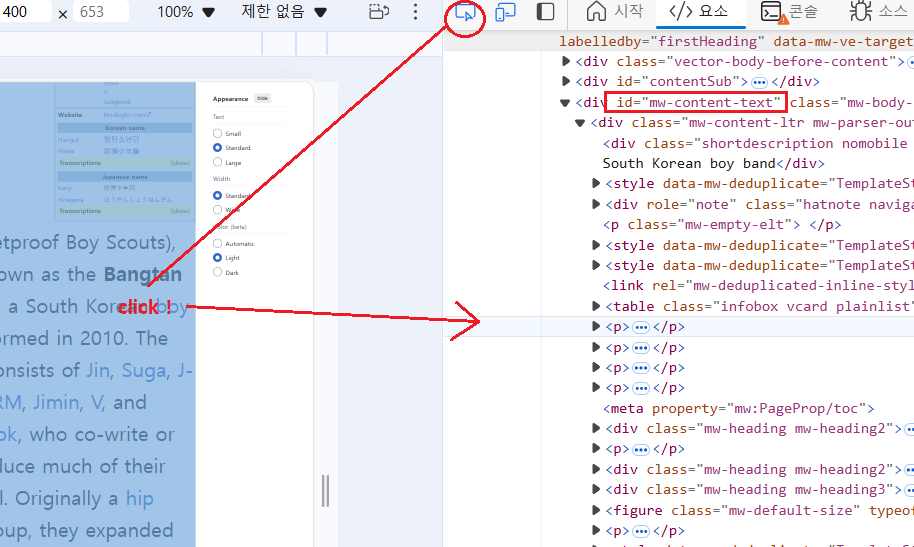
각 텍스트(말풍선) -p🔽🔽🔽