Jupyter Notebook에서 파이썬으로 시각화 실습!
작곡하느라 바쁜 주말에도 놓치지 않을 거예요~
시간 내서 빠르게 혼자 실습 문제 만들고 풀어보겠습니다!
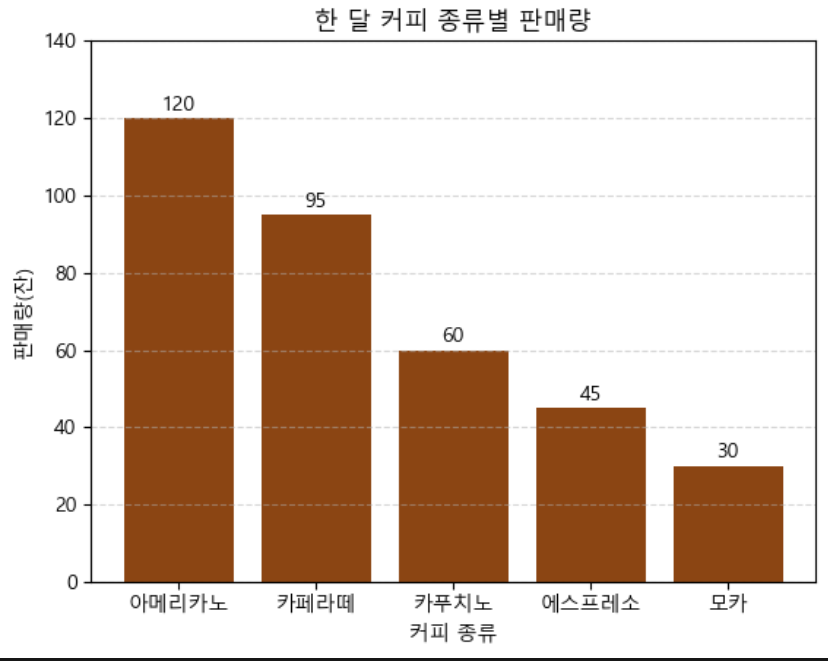
Bar chart 시각화
모집단 기준: 한 달 동안 카페에서 판매된 모든 커피 잔 수
카테고리별 집단 아메리카노, 카페라떼, 카푸치노, 에스프레소, 모카
시각화 기준: x축: 커피 종류(범주형), y축: 판매량(숫자)
막대 그래프를 사용해 각 커피 종류별 판매량 직관적 비교
시각적 이해 높이기 (막대 위 값 표시, 색상, 격자선)
그래프 특징
1. Bar 구조:
- 막대 간격 균등 배치. 각 카테고리 명확히 구분
2. 시각 강조
- 막대 색상 갈색 계열으로 설정
- 시각적 집중을 높여 막대가 눈에 띌 수 있도록 함
3. 값 표시
- 각 막대 위 실제 판매량 숫자 표시
ha='center'로 가운데 정렬, 시각적으로 깔끔하도록.
4. 격자
- y축에 격자선 추가 ->
-- - 판매량 비교할 때 기준점 역할
alpha=0.5로 투명도 낮춰 배경 방해하지 않도록.
5. 측 범위 및 라벨
- y축 범위: 데이터 최대값보다 약간 높게 설정
max(sales)+20 - x축 라벨: 커피 종류
- y축 라벨: 판매량
- 제목: 한 달 커피 종류별 판매량
- 전체 그래프 의미를 쉽게 볼 수 있도록
6. 한글 지원
font.family = 'Malgun Gothic'
한글 텍스트가 깨지지 않음
코드
import matplotlib.pyplot as plt
from matplotlib import rcParams
# 한글 폰트 설정 (Windows 기준)
rcParams['font.family'] = 'Malgun Gothic' # 맑은 고딕
# 데이터 준비
coffee_types = ['아메리카노', '카페라떼', '카푸치노', '에스프레소', '모카']
sales = [120, 95, 60, 45, 30] # 한 달 동안 판매된 잔 수
# 막대 그래프 그리기
plt.bar(coffee_types, sales, color='saddlebrown')
plt.title('한 달 커피 종류별 판매량')
plt.xlabel('커피 종류')
plt.ylabel('판매량(잔)')
plt.ylim(0, max(sales) + 20)
plt.grid(axis='y', linestyle='--', alpha=0.5)
# 막대 위에 값 표시
for i, v in enumerate(sales):
plt.text(i, v + 2, str(v), ha='center', fontsize=10)
plt.show()결과
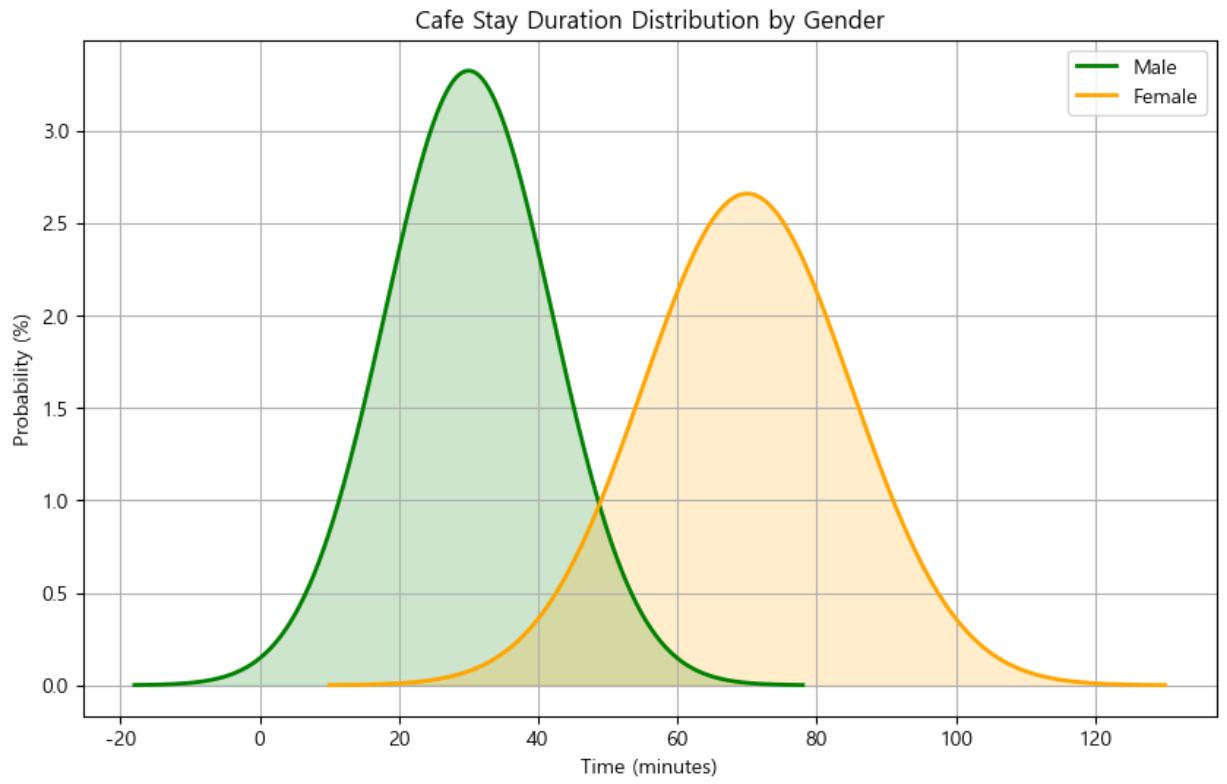
Line + Filled Area Chart 시각화
모집단 기준: 하루 동안 카페에서 머문 남녀 고객의 체류 시간
시각화 기준: x축: 체류 시간(분, 연속형), y축: 확률(%)
선 그래프와 색칠 영역을 사용해 남녀 체류 시간 분포 직관적 비교 시각적 이해 높이기 (선 색상, 채우기, 격자선)
그래프 특징
1. 선 구조:
- 남성, 여성 각각 선 그래프 표시
- 연속형 데이터 분포 직관적으로 비교 가능
2. 색상 강조:
- 남성: 녹색 계열, 여성: 주황 계열
- 채우기 영역
fill_between으로 분포 영역 강조
3. 값 표현:
- y축을 확률 밀도 → %로 변환하여 직관적으로 이해
- 각 구간 확률 밀도가 높을수록 선과 채우기 영역 높게 표시
- 격자:
- y축 격자선 추가 →
-- - alpha=0.5로 투명도 낮춰 배경 방해 최소화
- 축 범위 및 라벨:
y축 범위:0~최대 확률 밀도 값 ×100 (확률 %)x축 라벨:체류 시간(분)y축 라벨:확률(%)제목:남녀 체류 시간 분포 비교- 전체 그래프 의미를 쉽게 이해 가능
코드
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
# 모집단 기준 (카페 체류 시간)
male_mean = 30
male_std = 12
female_mean = 70
female_std = 15
# x축 범위 설정
x_m = np.linspace(male_mean - 4*male_std, male_mean + 4*male_std, 1000)
x_f = np.linspace(female_mean - 4*female_std, female_mean + 4*female_std, 1000)
# 정규분포 확률 밀도
y_m = norm.pdf(x_m, male_mean, male_std)
y_f = norm.pdf(x_f, female_mean, female_std)
# 그래프 그리기 (선 + 색칠 영역)
plt.figure(figsize=(10,6))
plt.plot(x_m, y_m*100, color='green', lw=2, label='Male')
plt.fill_between(x_m, 0, y_m*100, color='green', alpha=0.2)
plt.plot(x_f, y_f*100, color='orange', lw=2, label='Female')
plt.fill_between(x_f, 0, y_f*100, color='orange', alpha=0.2)
plt.title('Cafe Stay Duration Distribution by Gender')
plt.xlabel('Time (minutes)')
plt.ylabel('Probability (%)')
plt.legend()
plt.grid(True)
plt.show()결과
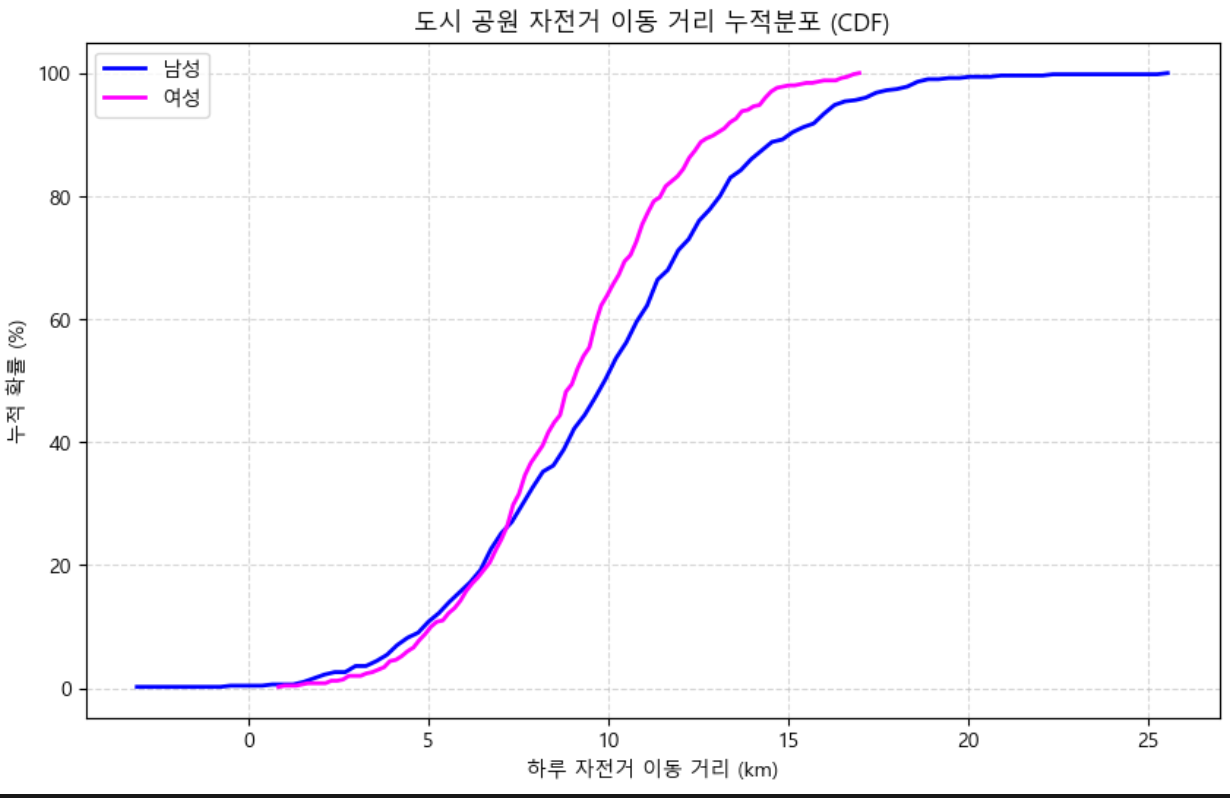
CDF 시각화
모집단 기준: 도시 공원에서 하루 동안 남녀가 자전거로 이동한 거리 (km)
시각화 기준: x축: 하루 이동 거리(연속형), y축: 누적 확률(%)
CDF를 사용해 남성과 여성 이동 거리 비교 직관적 확인
시각적 이해 높이기 (선 색상, 격자선, % 표시)
그래프 특징
1. CDF 구조:
남성, 여성 각각 누적분포 선 그래프 표시
각 x값까지의 누적 확률을 직관적으로 보여줌
2. 색상 강조:
남성: 파랑 계열, 여성: 마젠타 계열
시각적 집중을 높여 두 집단 비교 쉽게 함
3. 값 표현:
y축을 누적 확률(%)로 변환
“몇 km 이하 이동한 사람이 몇 %인지” 직관적으로 표시
4. 격자:
y축 격자선 추가 → --
alpha=0.5로 투명도 낮춰 배경 방해 최소화
5. 축 범위 및 라벨:
x축: 하루 이동 거리 (km)
y축: 누적 확률 (%)
제목: 하루 자전거 이동 거리 누적분포 (CDF)
전체 그래프 의미를 쉽게 이해 가능
6. 한글 지원:
font.family = 'Malgun Gothic'
한글 제목, 라벨 문제 없이 표시
코드
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import cumfreq
# 한글 폰트 설정
plt.rcParams['font.family'] = 'Malgun Gothic'
# 하루 자전거 이동 거리 가상 데이터
np.random.seed(42)
men_distance = np.random.normal(10, 4, 500) # 남성 평균 10km, 표준편차 4
women_distance = np.random.normal(9, 3, 500) # 여성 평균 9km, 표준편차 3
# 남성
res_m = cumfreq(men_distance, numbins=100)
x_m = res_m.lowerlimit + np.linspace(0, res_m.binsize*res_m.cumcount.size, res_m.cumcount.size)
cdf_m = res_m.cumcount / len(men_distance) * 100
# 여성
res_w = cumfreq(women_distance, numbins=100)
x_w = res_w.lowerlimit + np.linspace(0, res_w.binsize*res_w.cumcount.size, res_w.cumcount.size)
cdf_w = res_w.cumcount / len(women_distance) * 100
plt.figure(figsize=(10,6))
plt.plot(x_m, cdf_m, color='blue', lw=2, label='남성')
plt.plot(x_w, cdf_w, color='magenta', lw=2, label='여성')
plt.xlabel('하루 자전거 이동 거리 (km)')
plt.ylabel('누적 확률 (%)')
plt.title('도시 공원 자전거 이동 거리 누적분포 (CDF)')
plt.legend()
plt.grid(True, linestyle='--', alpha=0.5)
plt.show()결과