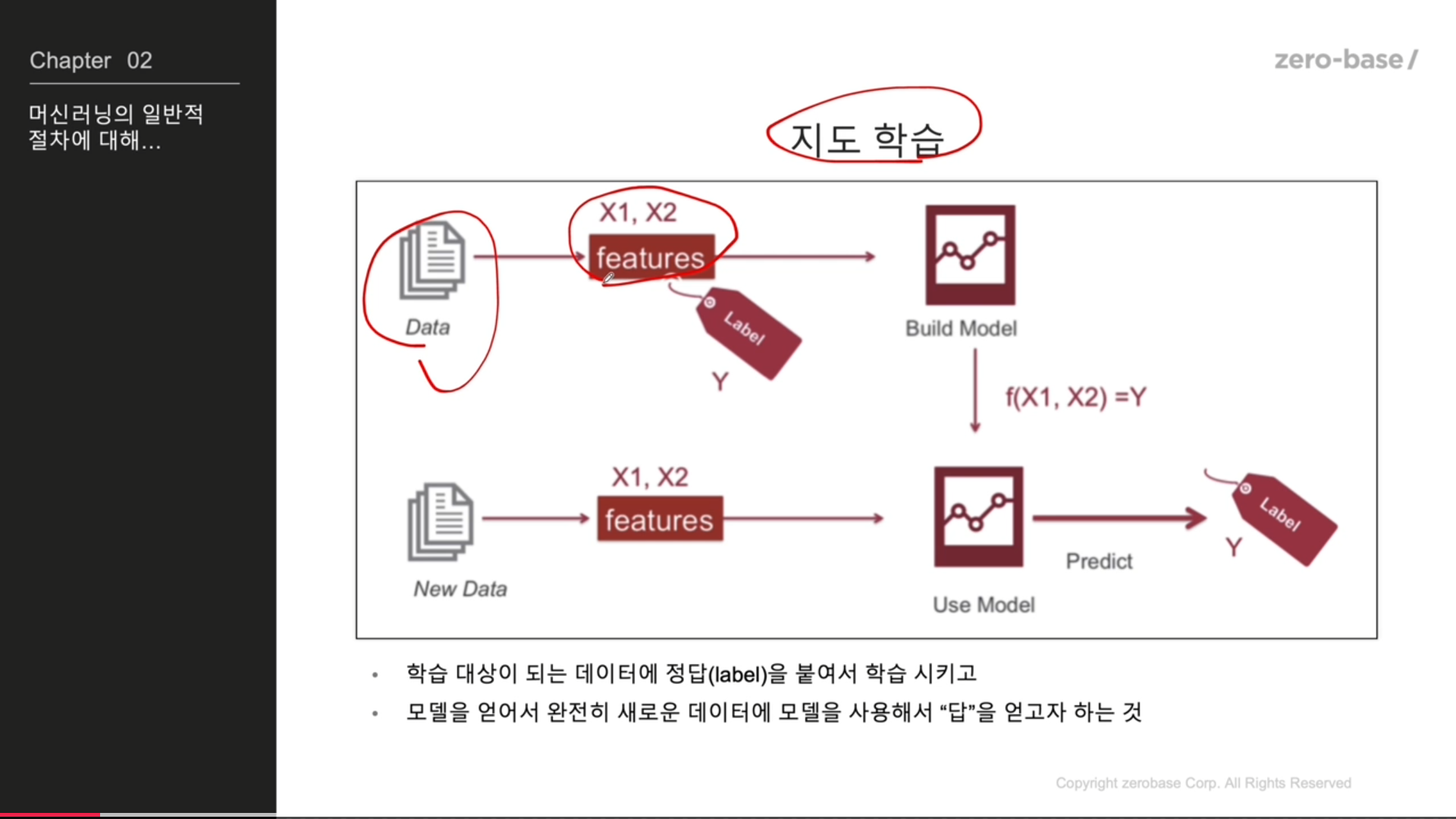
머신러닝이란?
명시적인 프로그램에 의해서가 아니라, 주어진 데이터를 통해 규칙을 찾는것
머신러닝 전 사람이 직접 해보자
데이터 관찰1
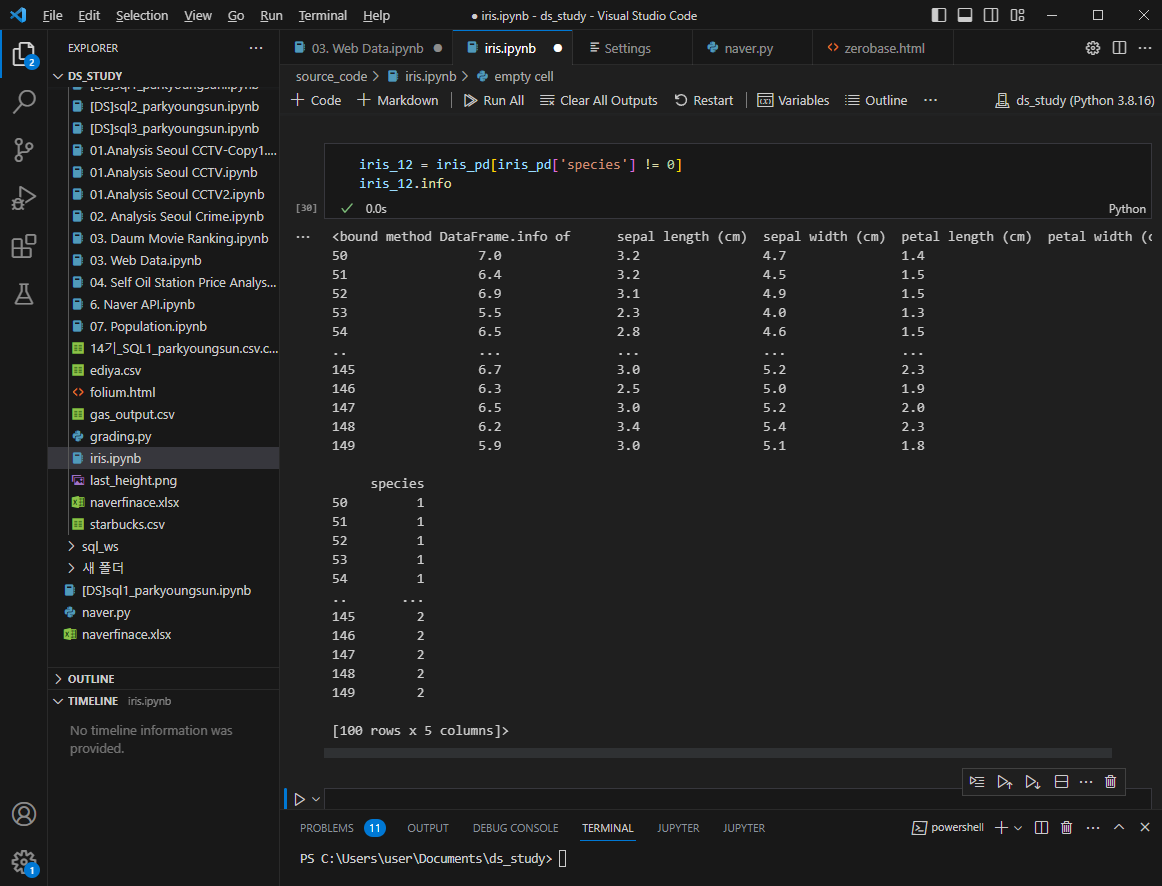
iris 데이터 분석하기
sklearn 설치 후
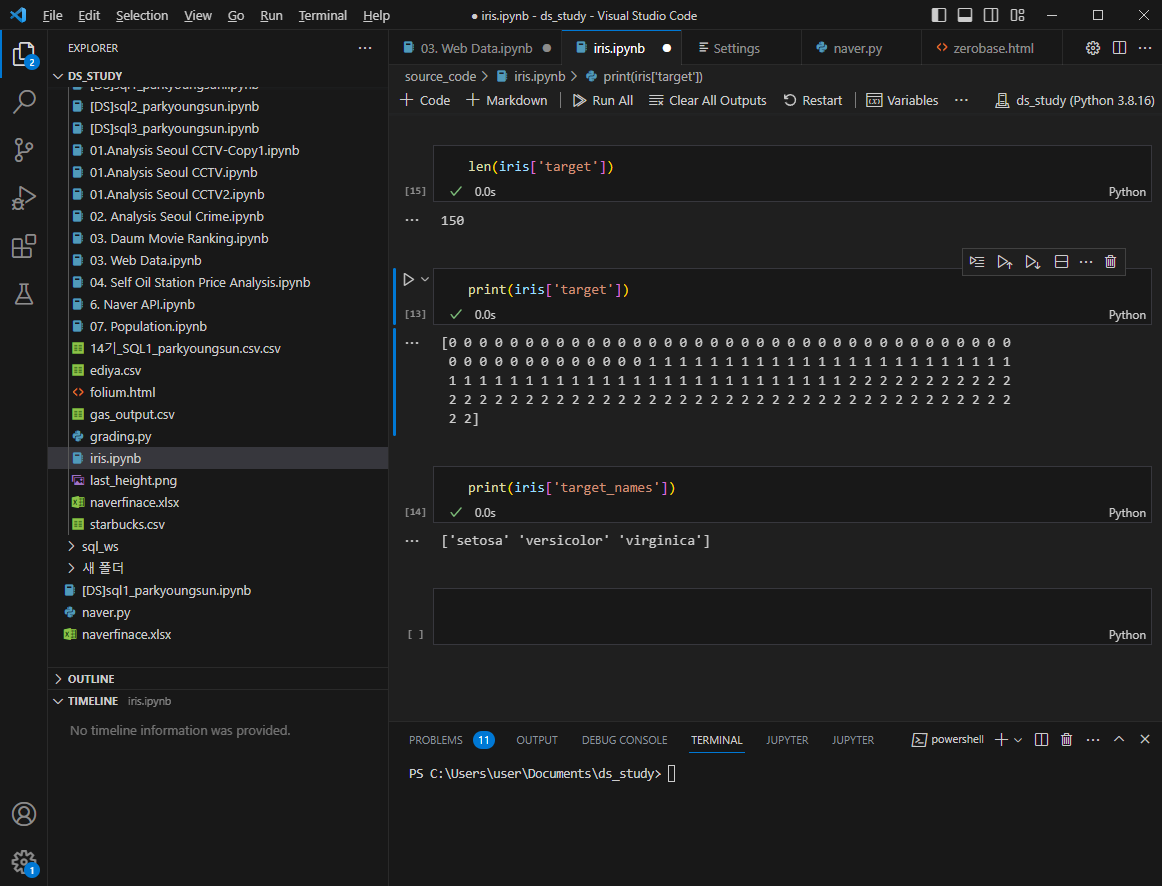
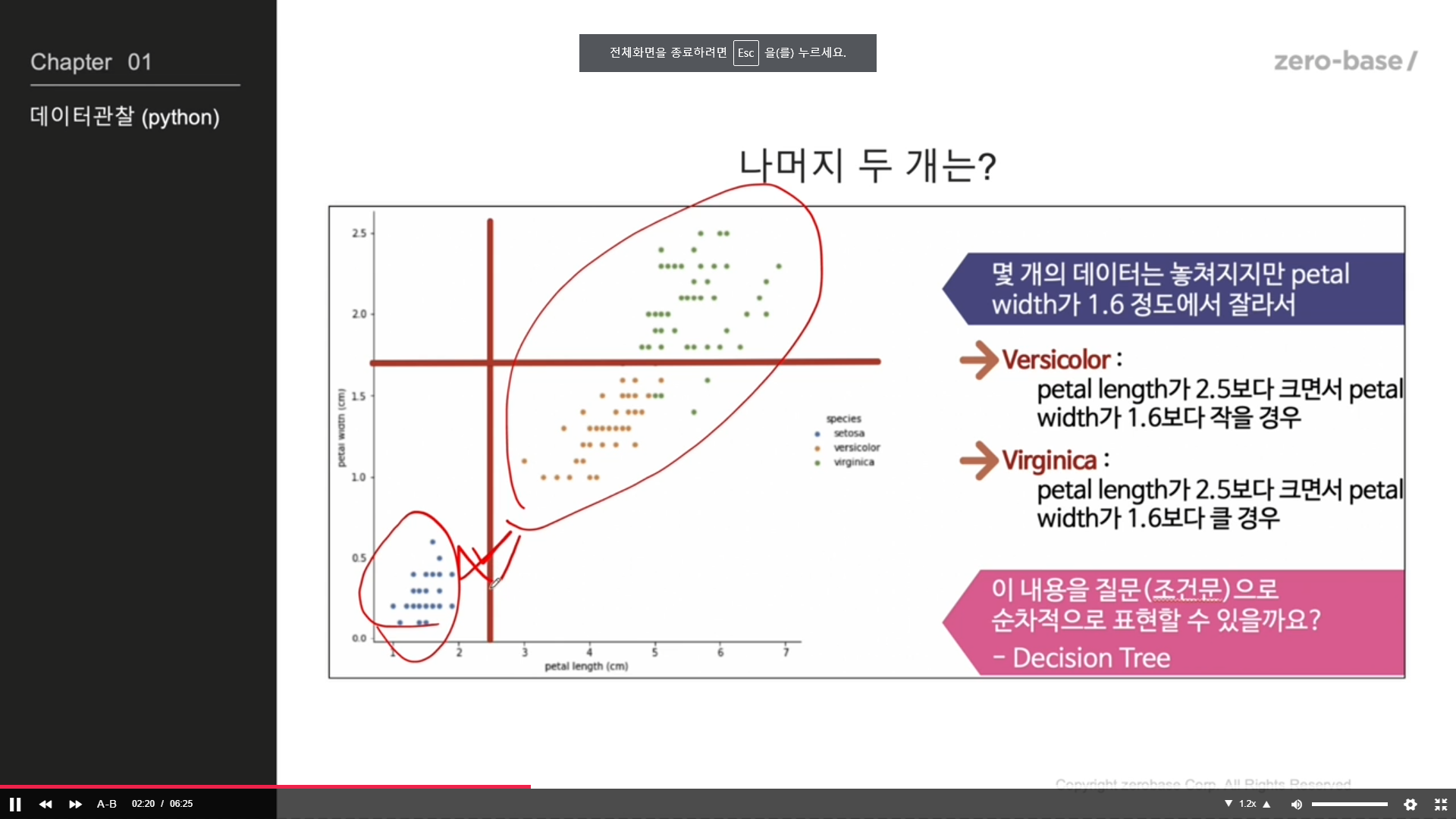
150개 중 1 setosa가 50개 / 2 versicolor가 50개 / 3 virginica가 50개

pandas import
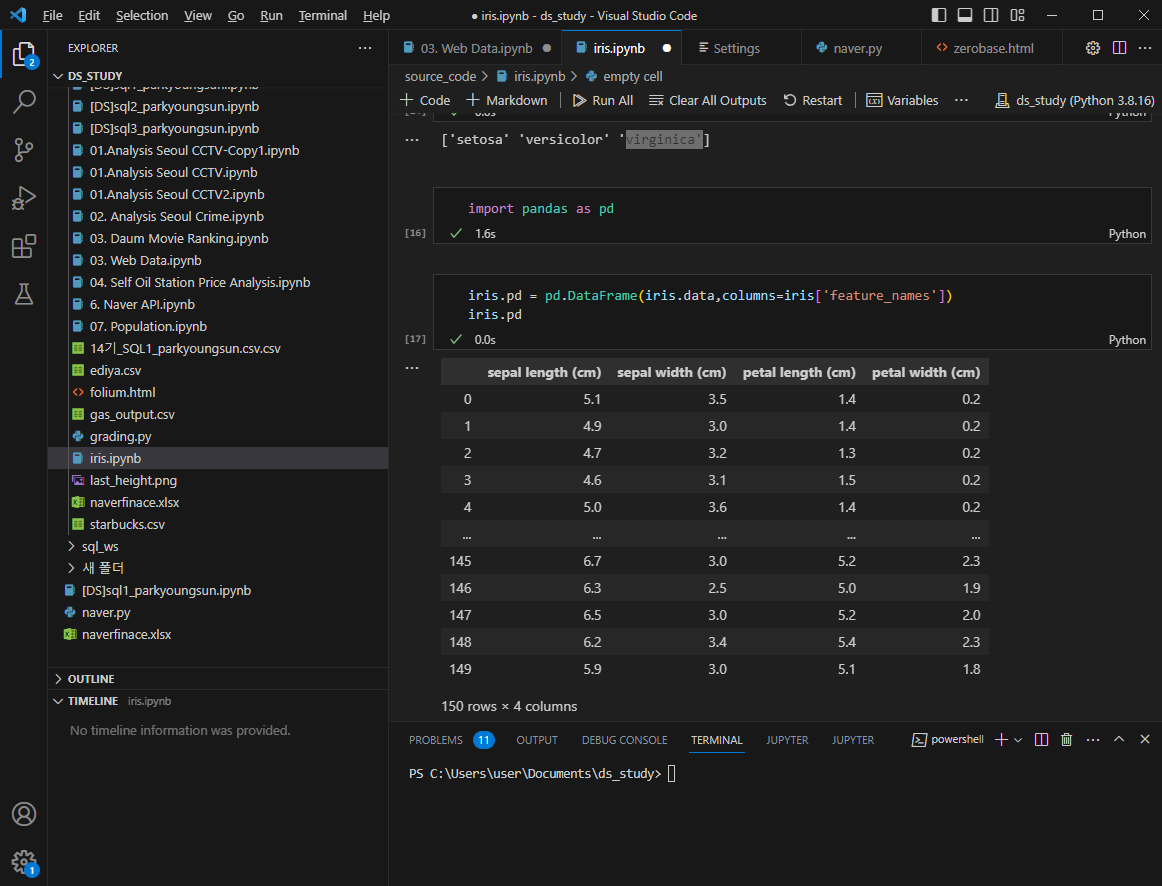
종 추가
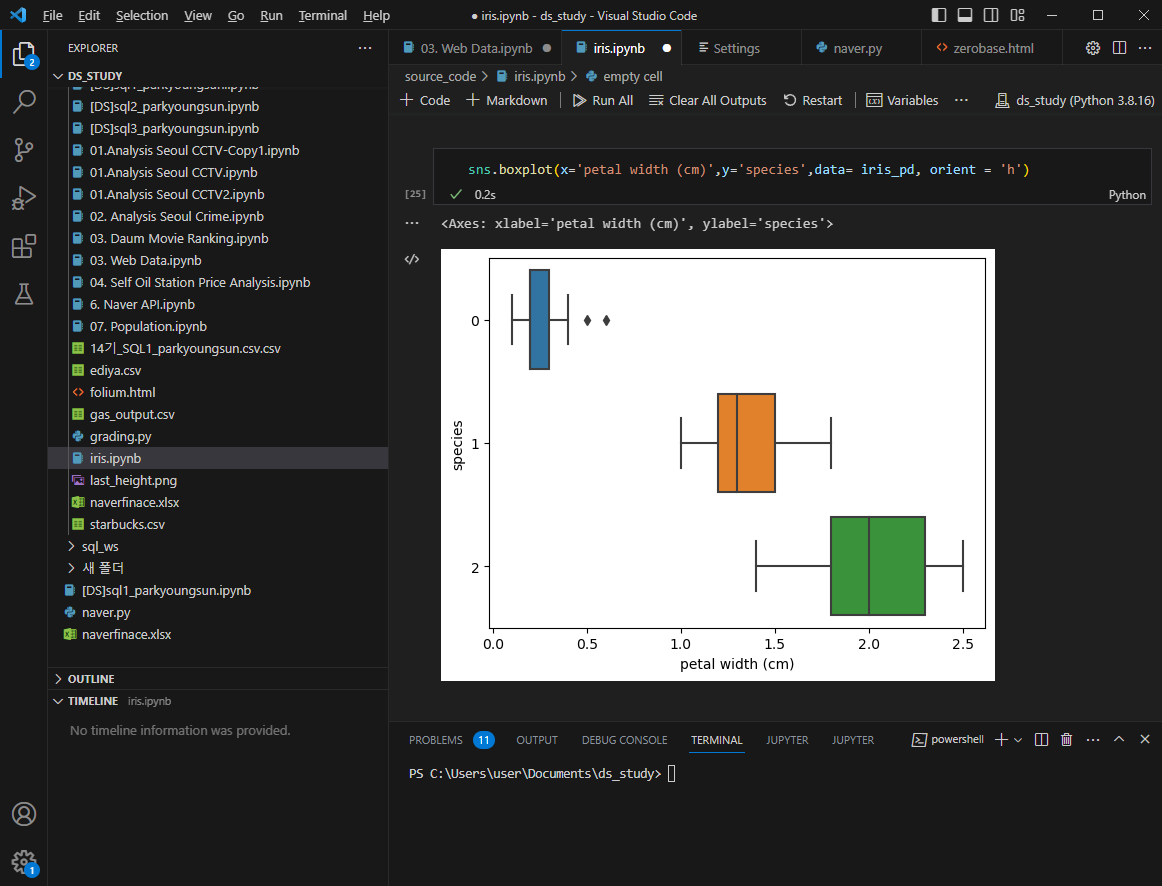
박스플롯
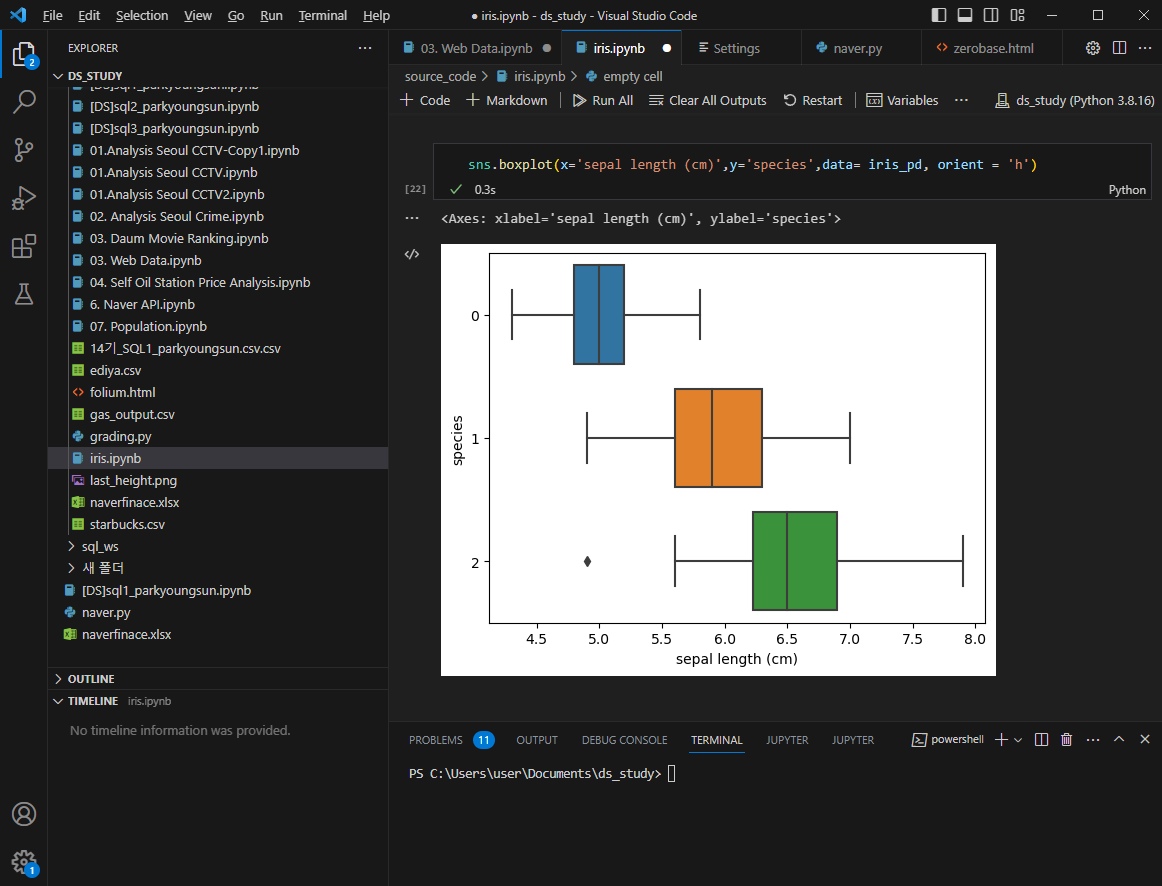
sepal length만 가지고는 3개 품종 구분이 어려운 것을 알 수 있다.
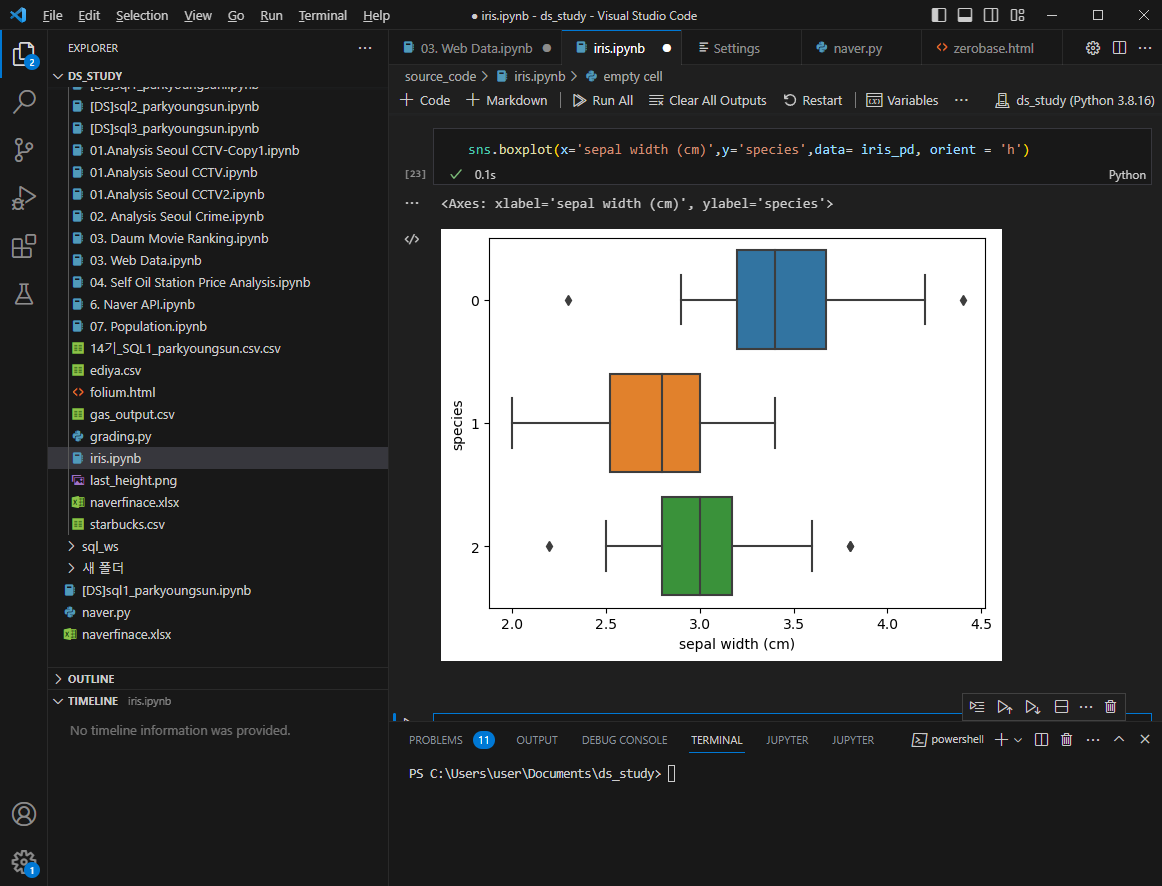
sepal width 역시 마찬가지
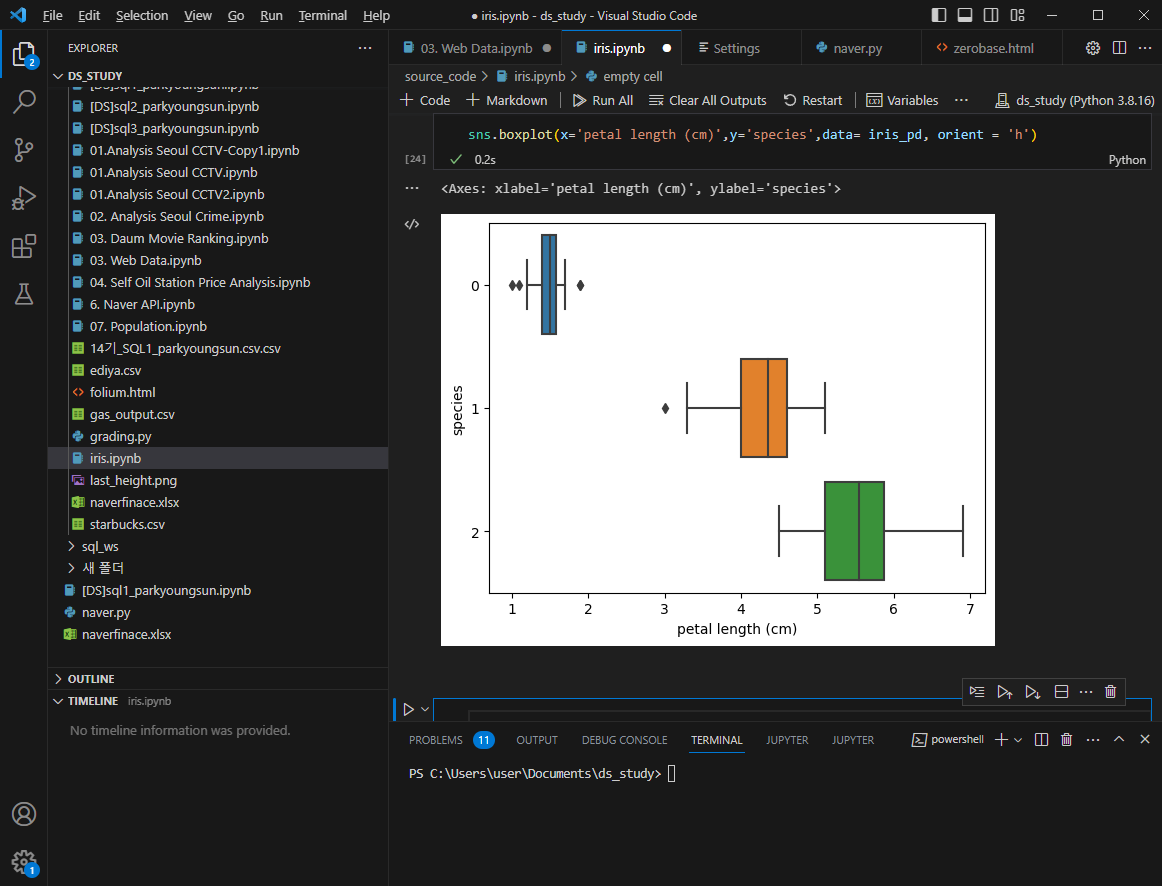
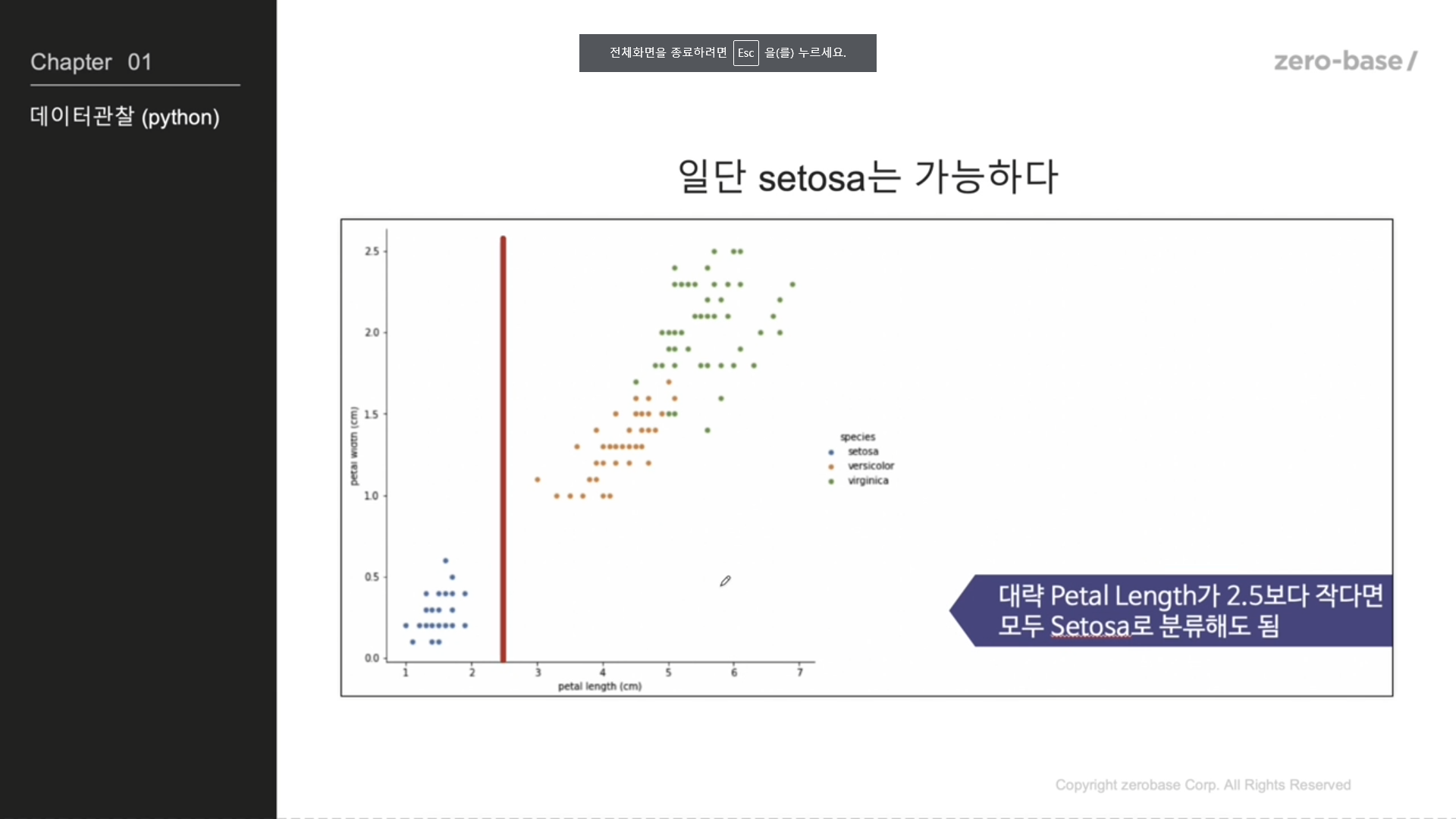
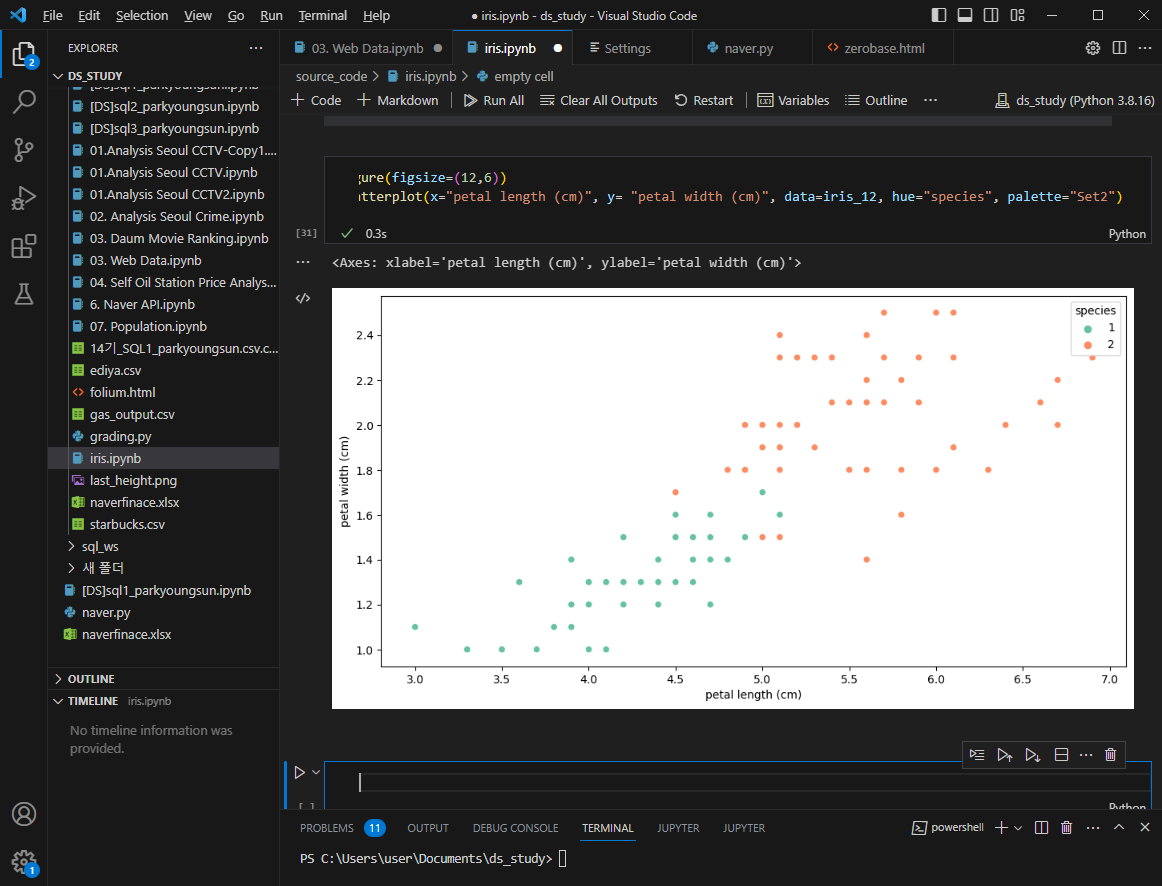
petal length로는 setosa는 구분 가능
petal width로도 setosa만 구분 가능
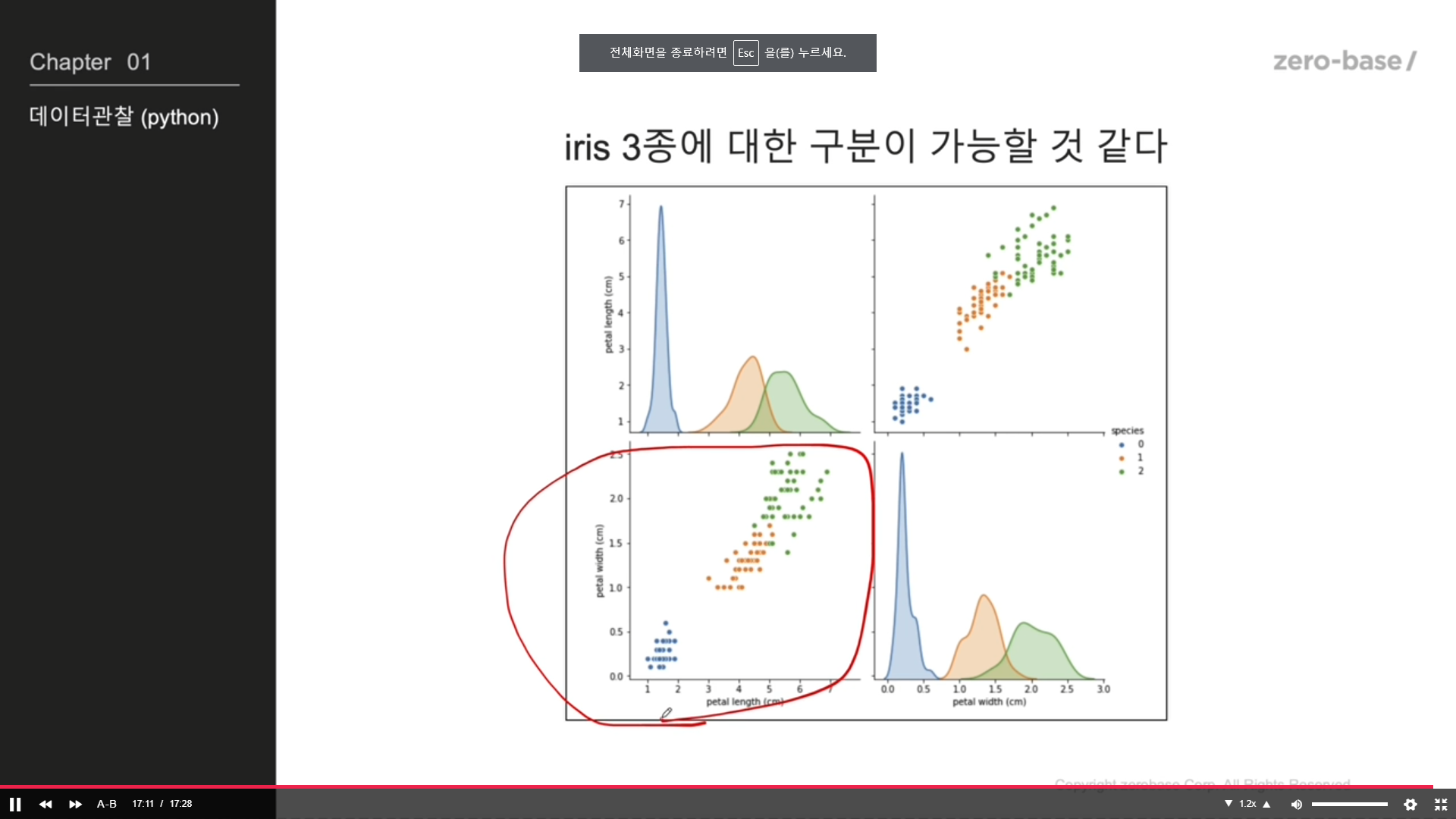
데이터 관찰2
decision tree
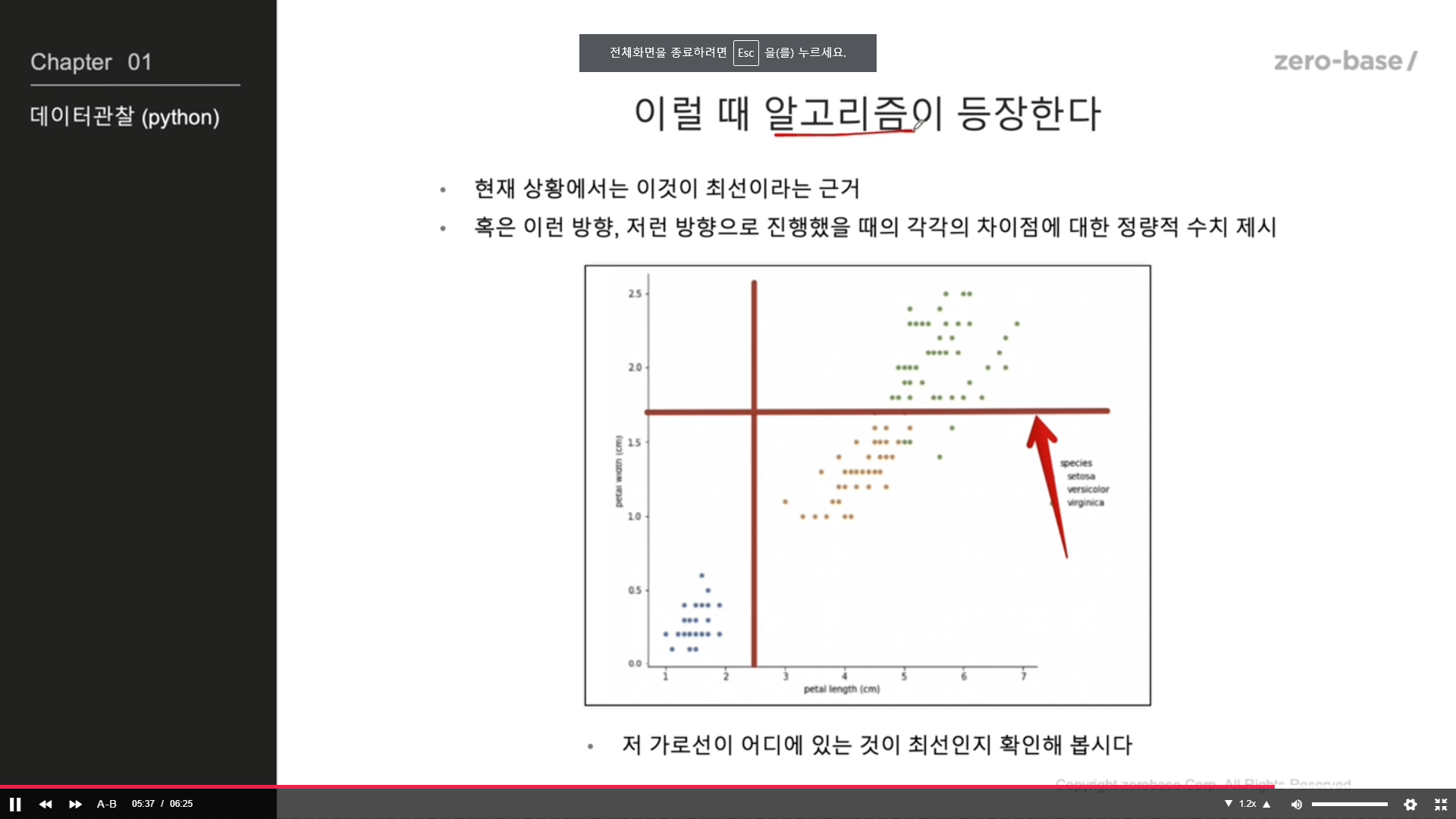
과연 그 근거가 있는가?
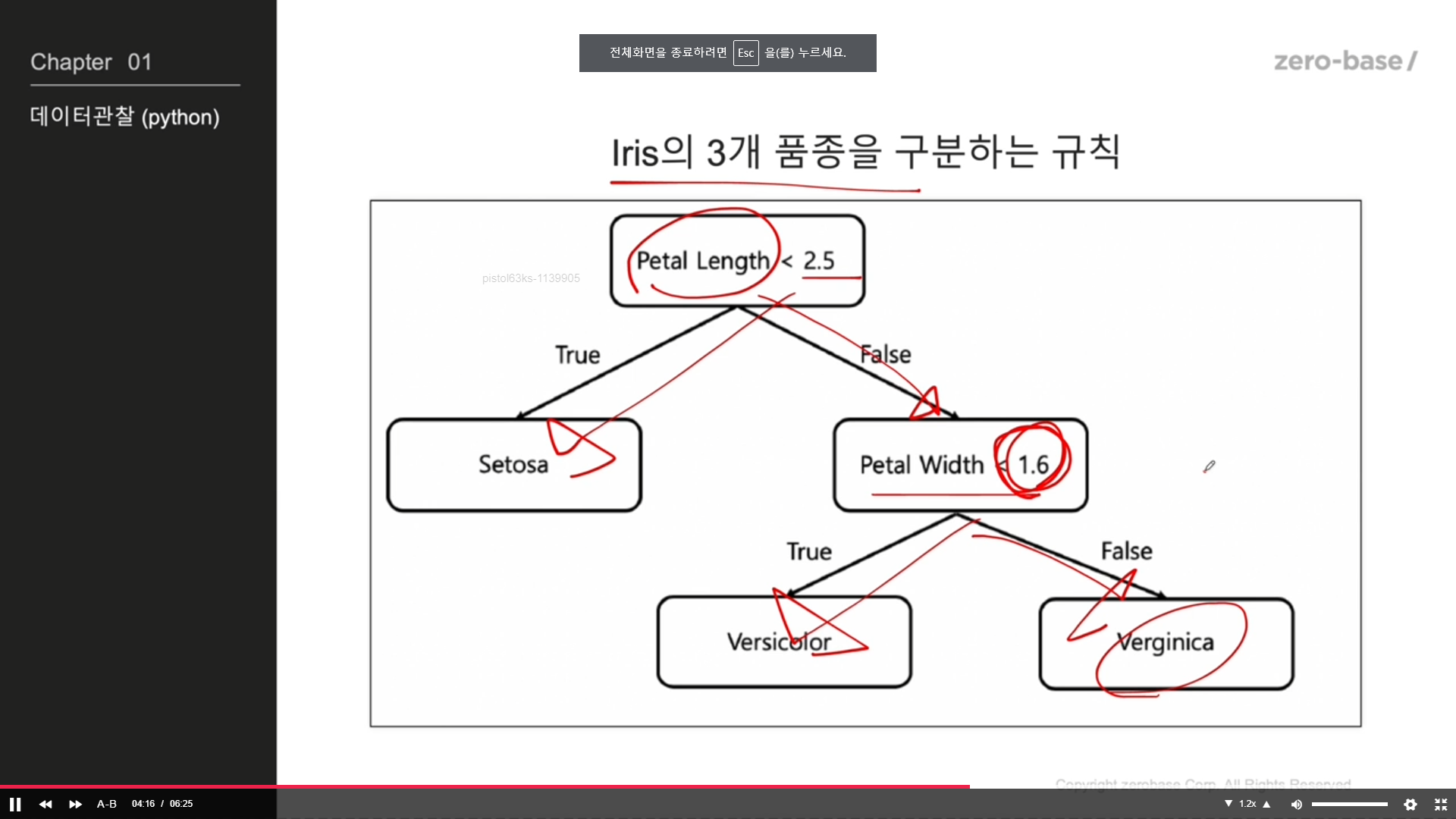
Decision Tree
setosa 제외하고 나머지 구분해야할 데이터만 보자
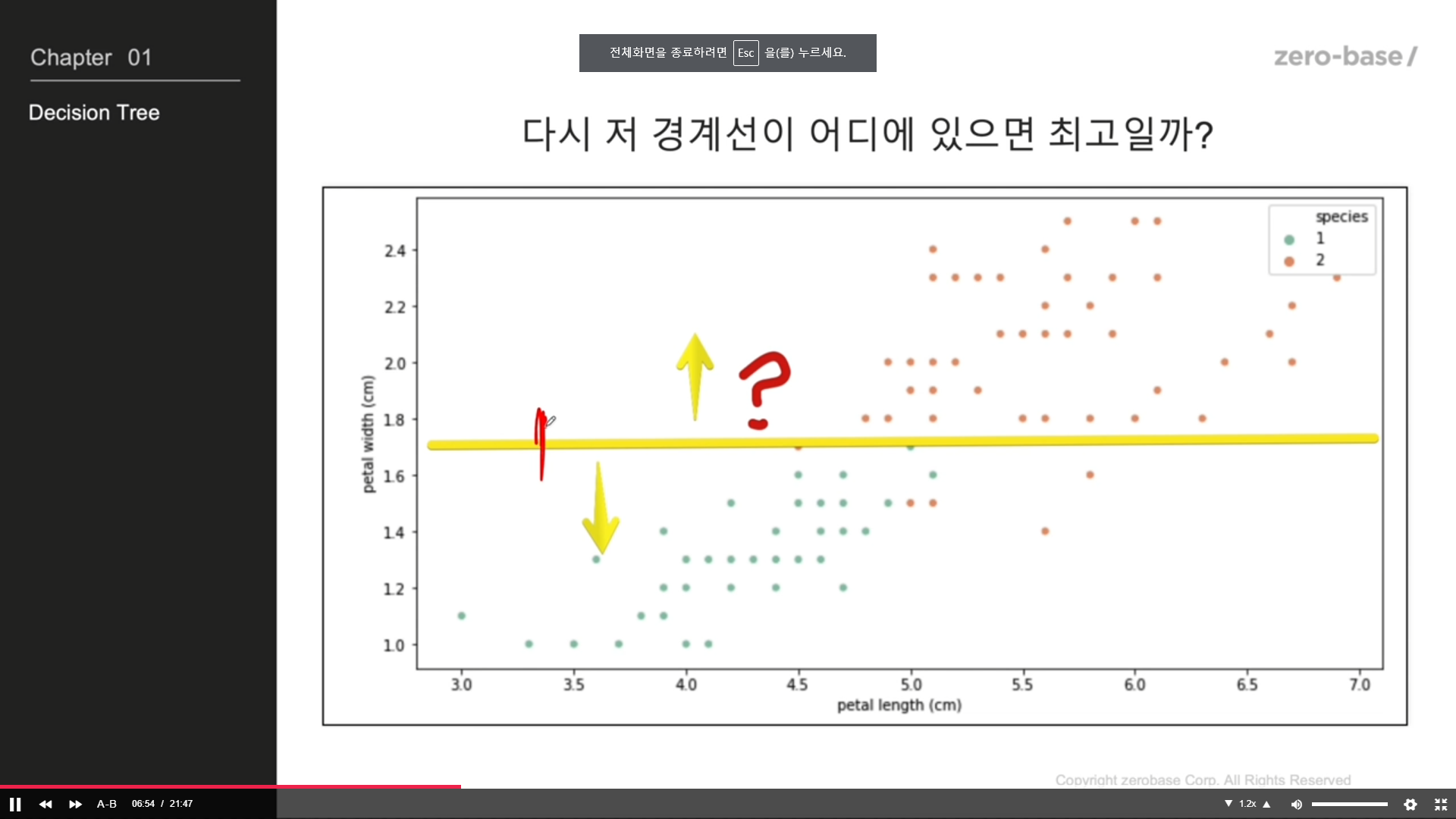
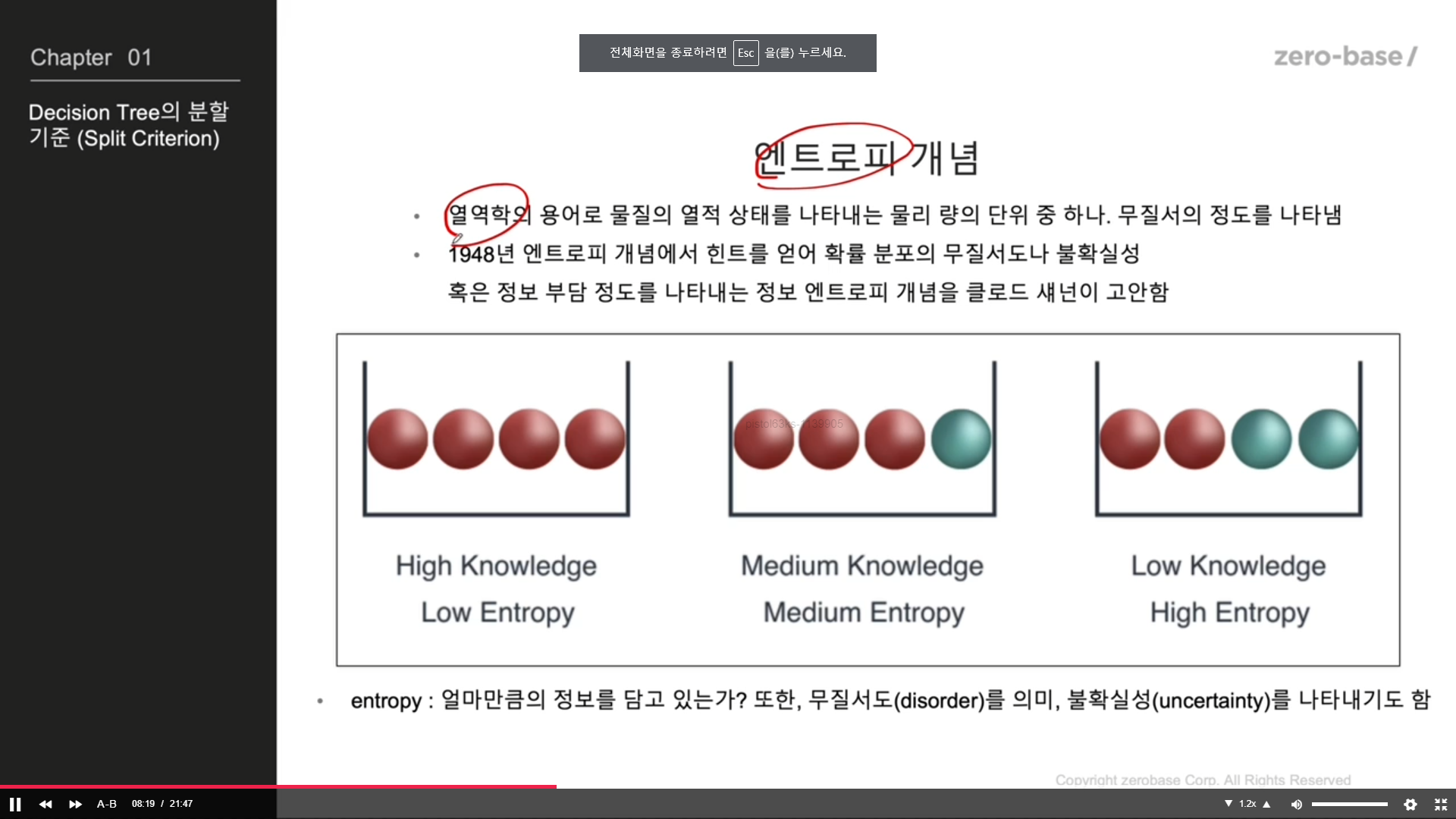
Decision Tree 의 분할 기준 (Split Criterion)
정보 획득 : 정보의 가치를 반환하는데 발생하는 사전의 확률이 작을수록
정보의 가치는 커진다
정보 이득 : 어떤 속성을 선택함으로 인해서 데이터를 더 잘 구분하게 되는것
엔트로피 연습

과거에는 코드로 다 짰던 것을 Frame Work로!
Scikit Learn
가장 유명한 기계학습 오픈 소스 라이브러리
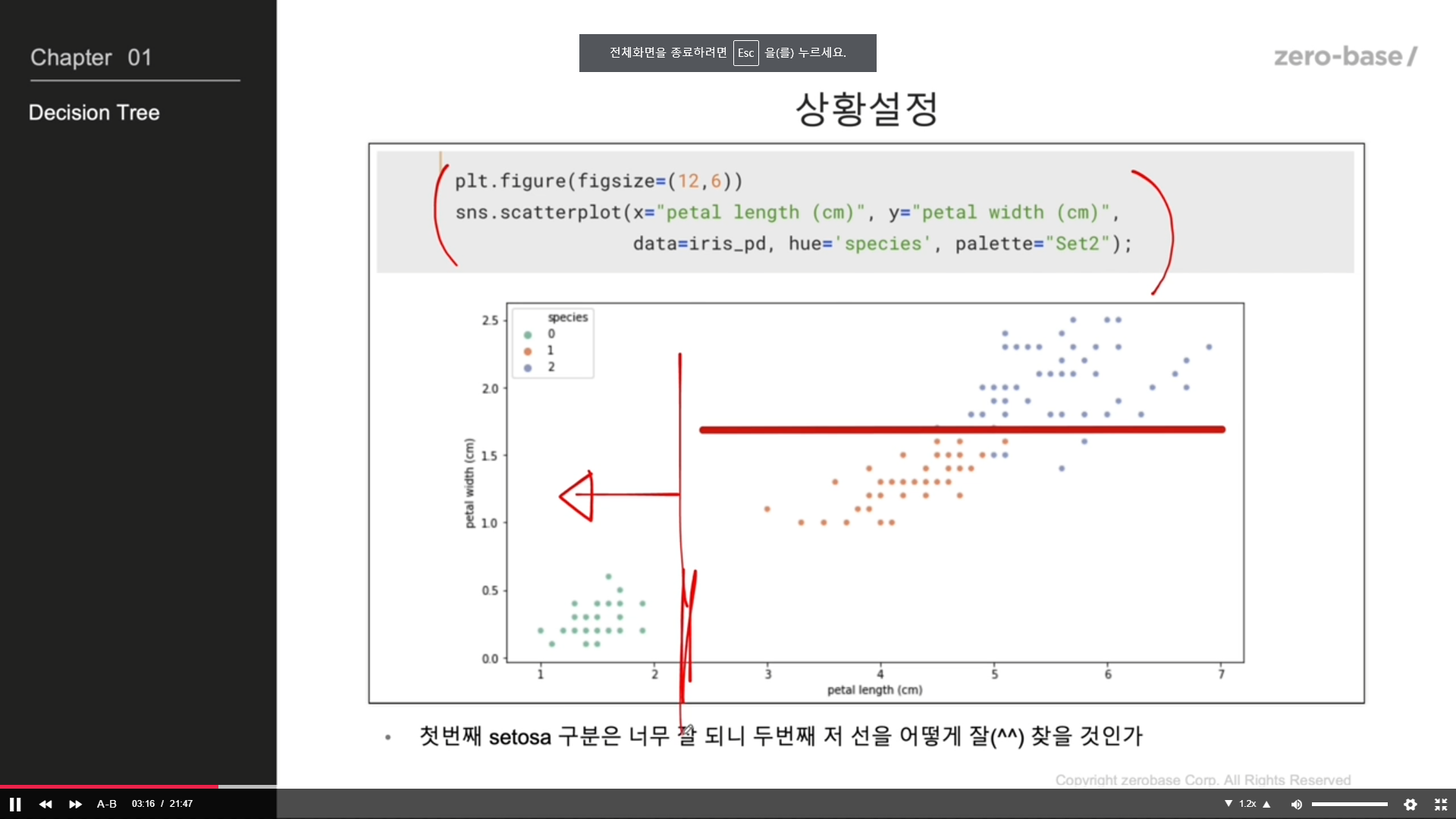
scikit learn을 통한 Decision tree 만들기
from sklearn.tree import DecisionTreeClassifier
iris_tree = DecisionTreeClassifier()iris_tree.fit(iris.data[:,2:],iris.target)이것이 학습 시키는 코드
fit이 학습해라 라는 뜻이고, 뒤에 iris.target으로 정답을 알려줘서 학습을 시킴
from sklearn.metrics import accuracy_score
y_pred_tr = iris_tree.predict(iris.data[:,2:])
y_pred_tr이것은 예측해보라는 코드, 따라서 정답을 가르쳐주지 않고 예측만 시킴
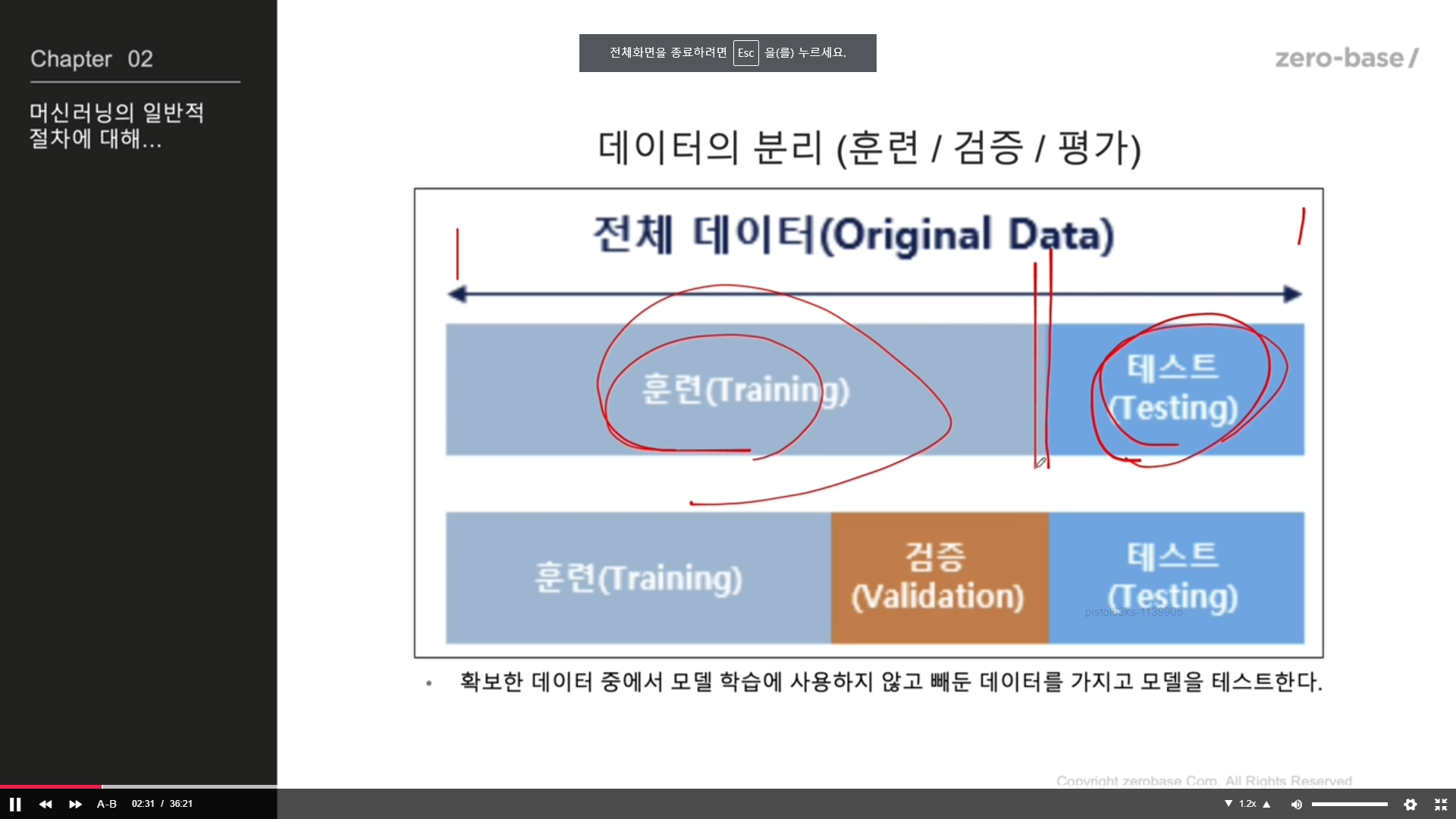
데이터 나누기
Decision Tree를 이용한 Iris 분류 - 과적합
지도 학습
mlxtend 설치
from mlxtend.plotting import plot_decision_regions
plt.figure(figsize=(14,8))
plot_decision_regions(X=iris.data[:,2:], y= iris.target, clf= iris_tree, legend=2)
plt.show()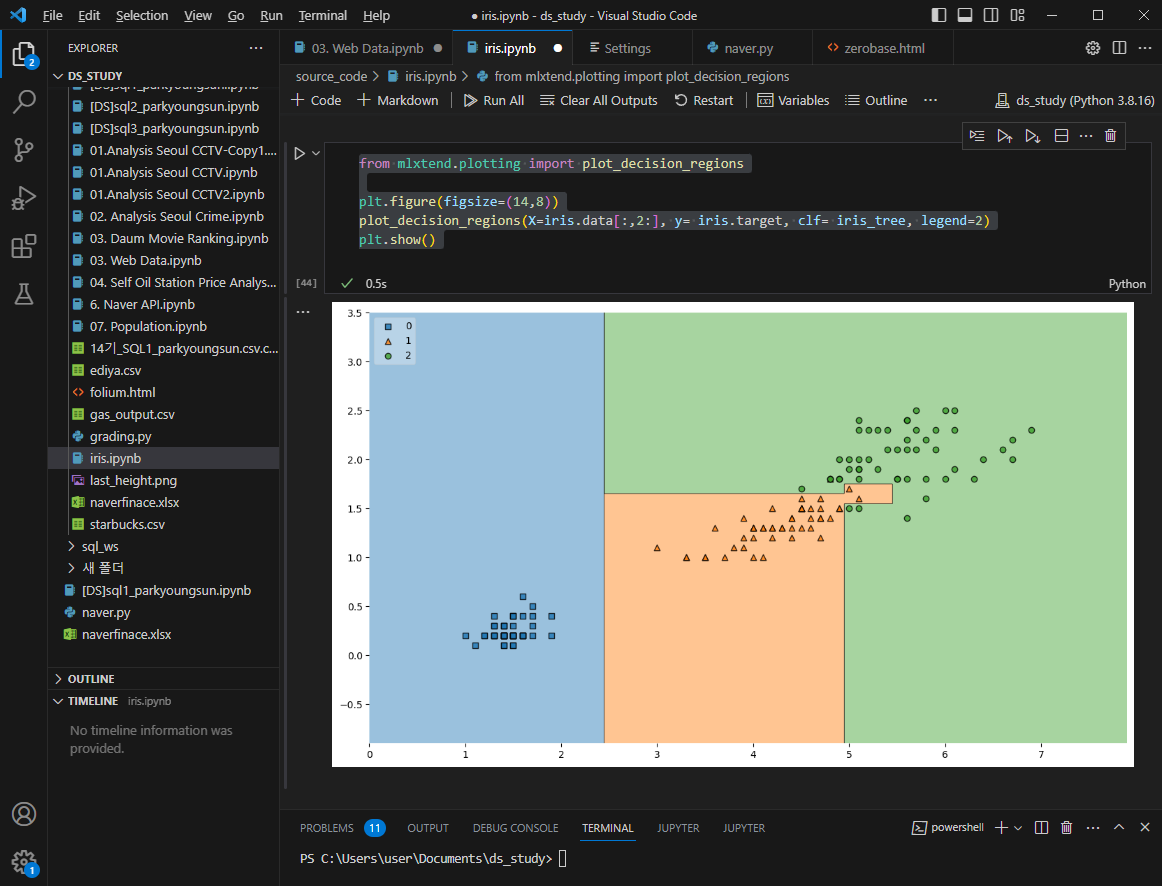
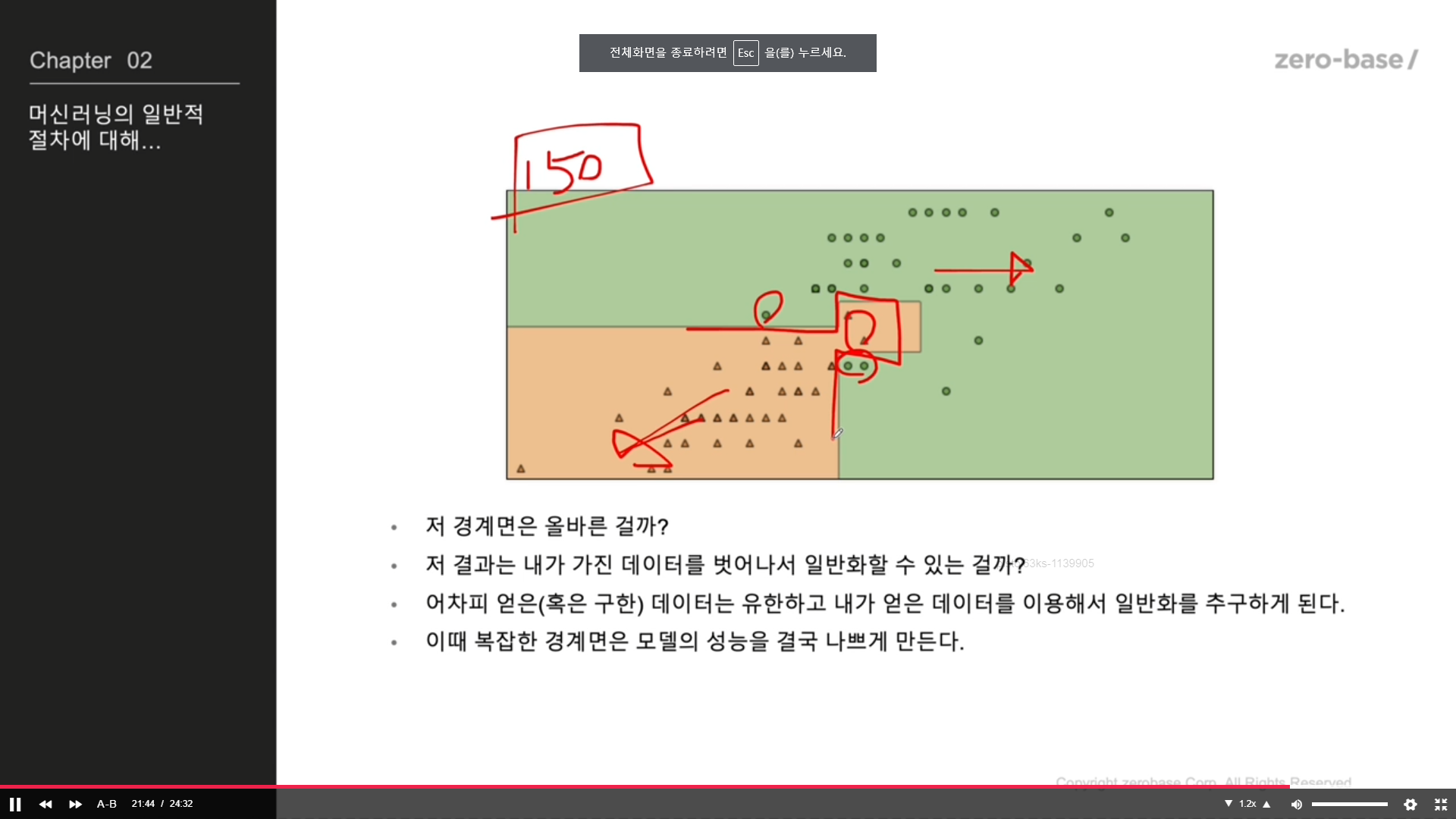
내가 가진 데이터에만 너무 적합해지면, 일반적 성능을 가질 수 없게됨
이것이 과적합
데이터나누기2
Decision Tree를 이용한 Iris 분류 - 데이터나누기
분리하기
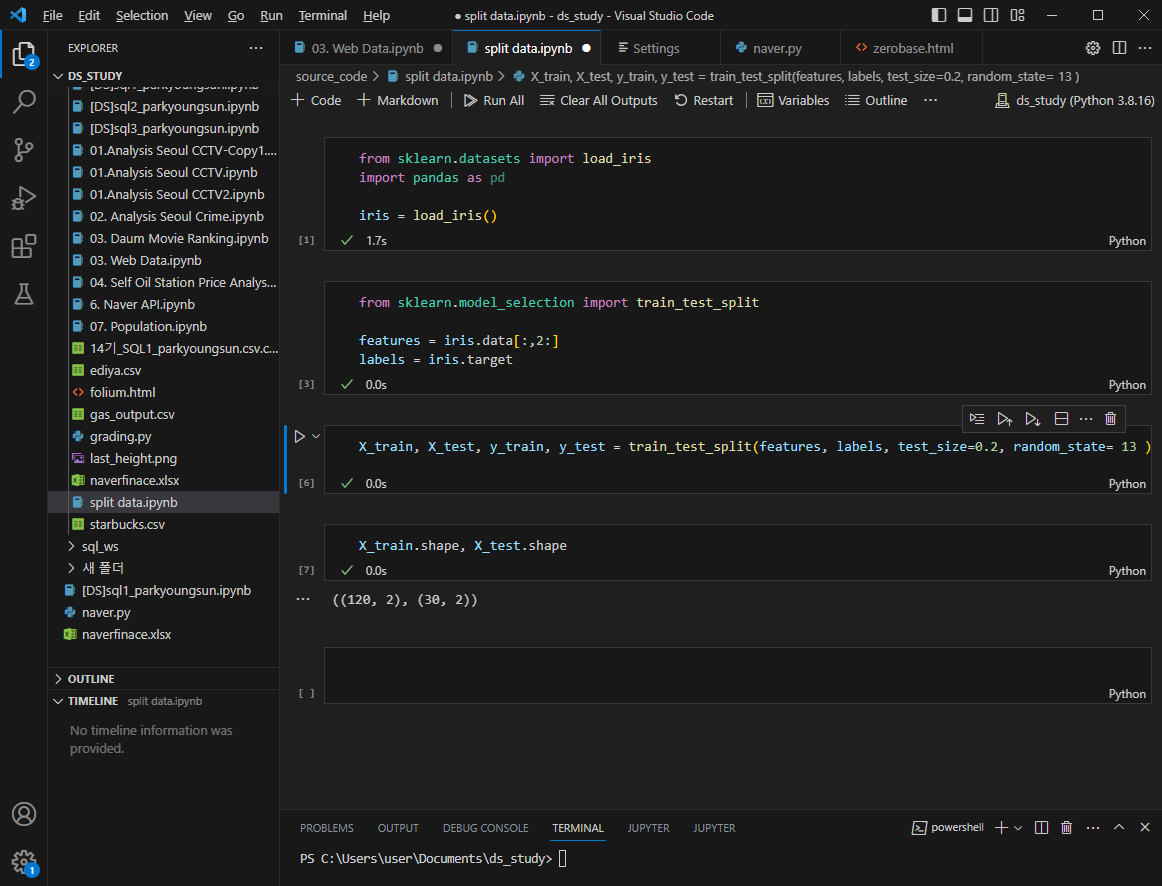
검증하기
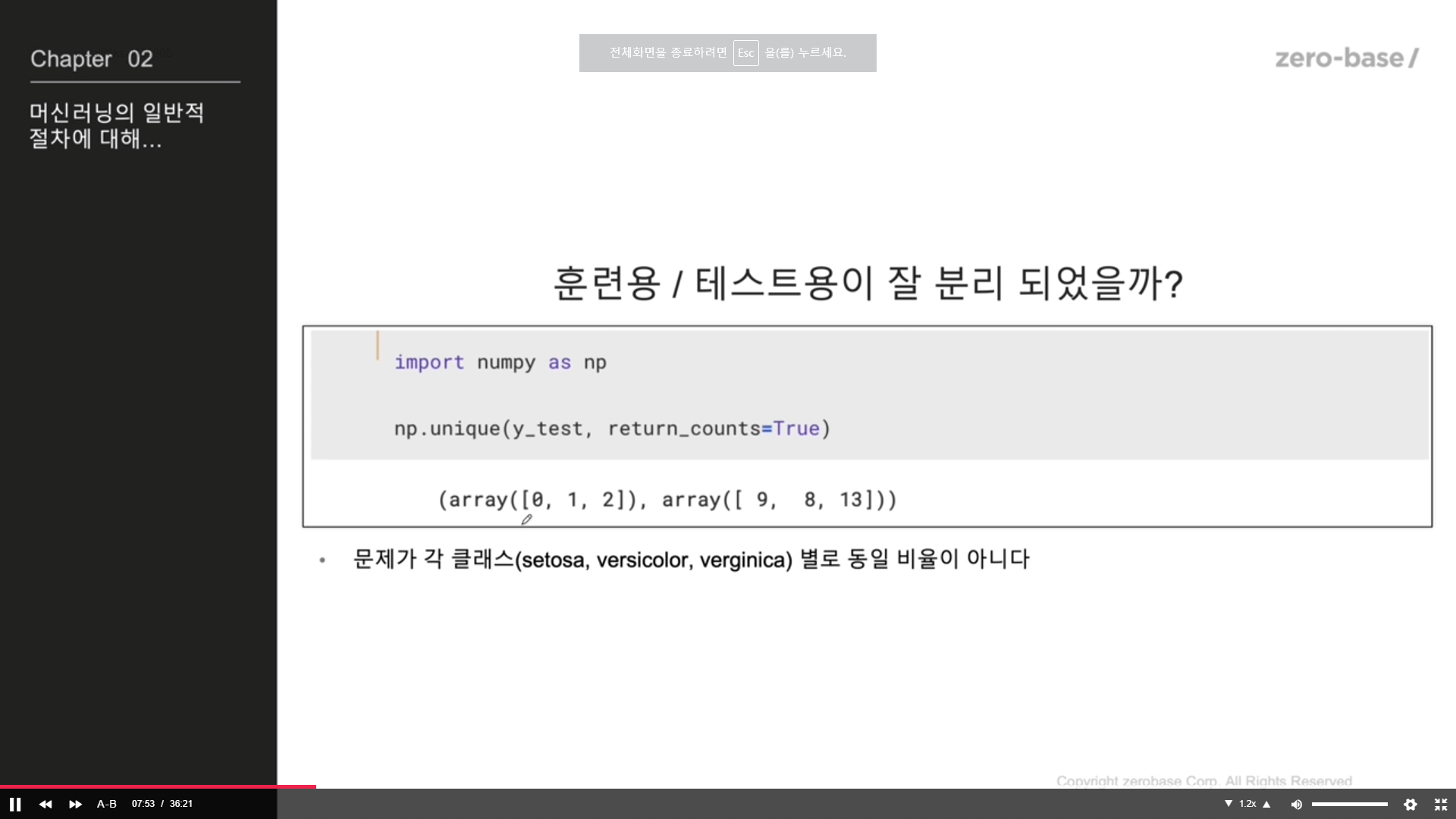
검증을 위해 stratify추가
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, stratify = labels,random_state= 13 )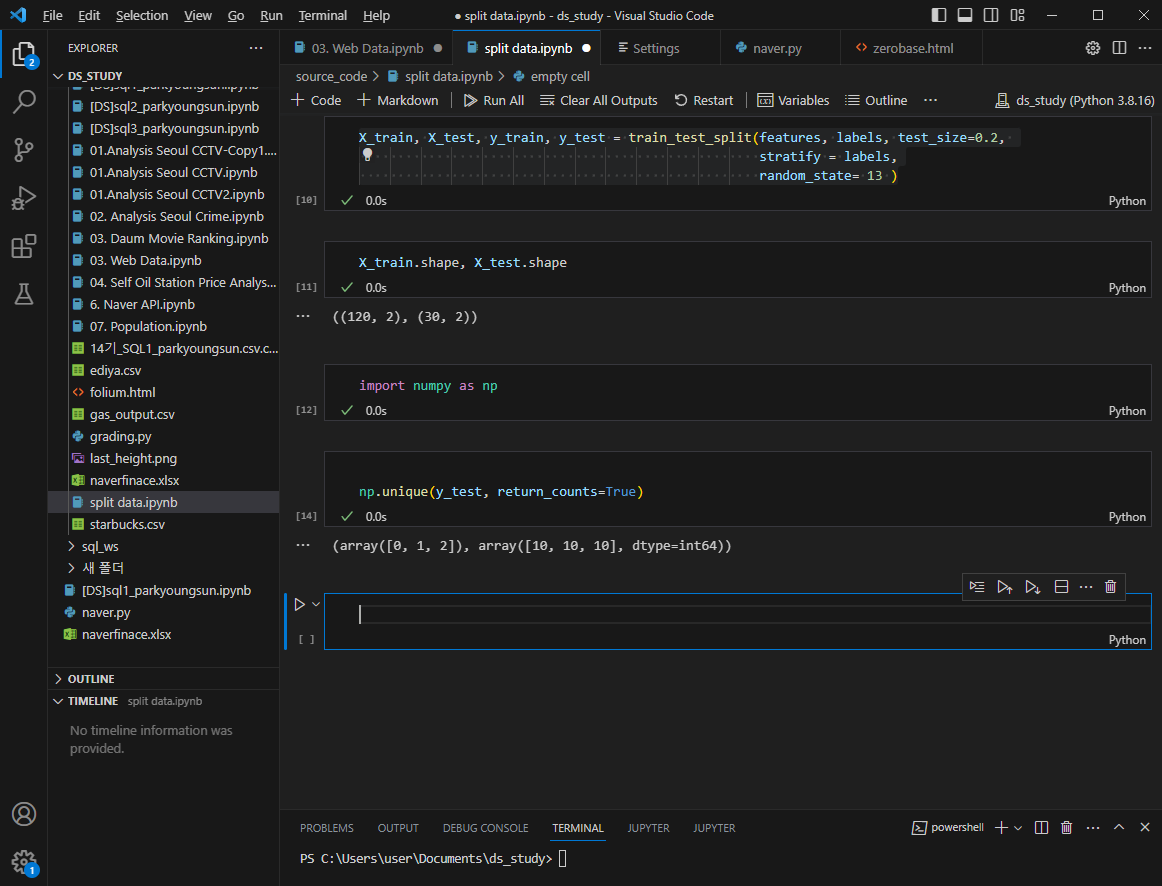
과적합되지 않도록 모델 성능에 제한을 거는 셈
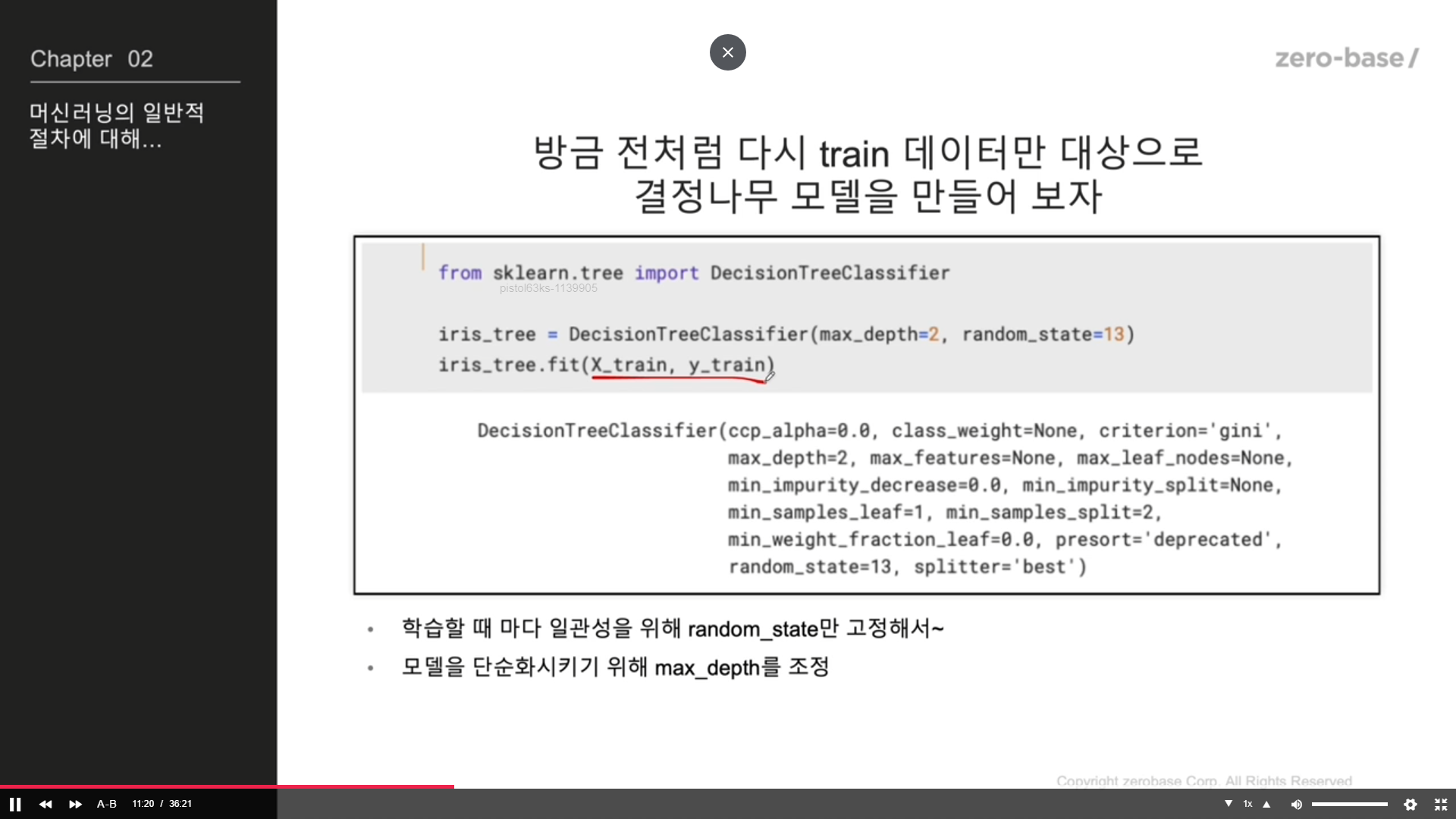
학습시키기
from sklearn.tree import DecisionTreeClassifier
iris_tree = DecisionTreeClassifier
(max_depth =2, random_state= 13)
iris_tree.fit(X_train, y_train)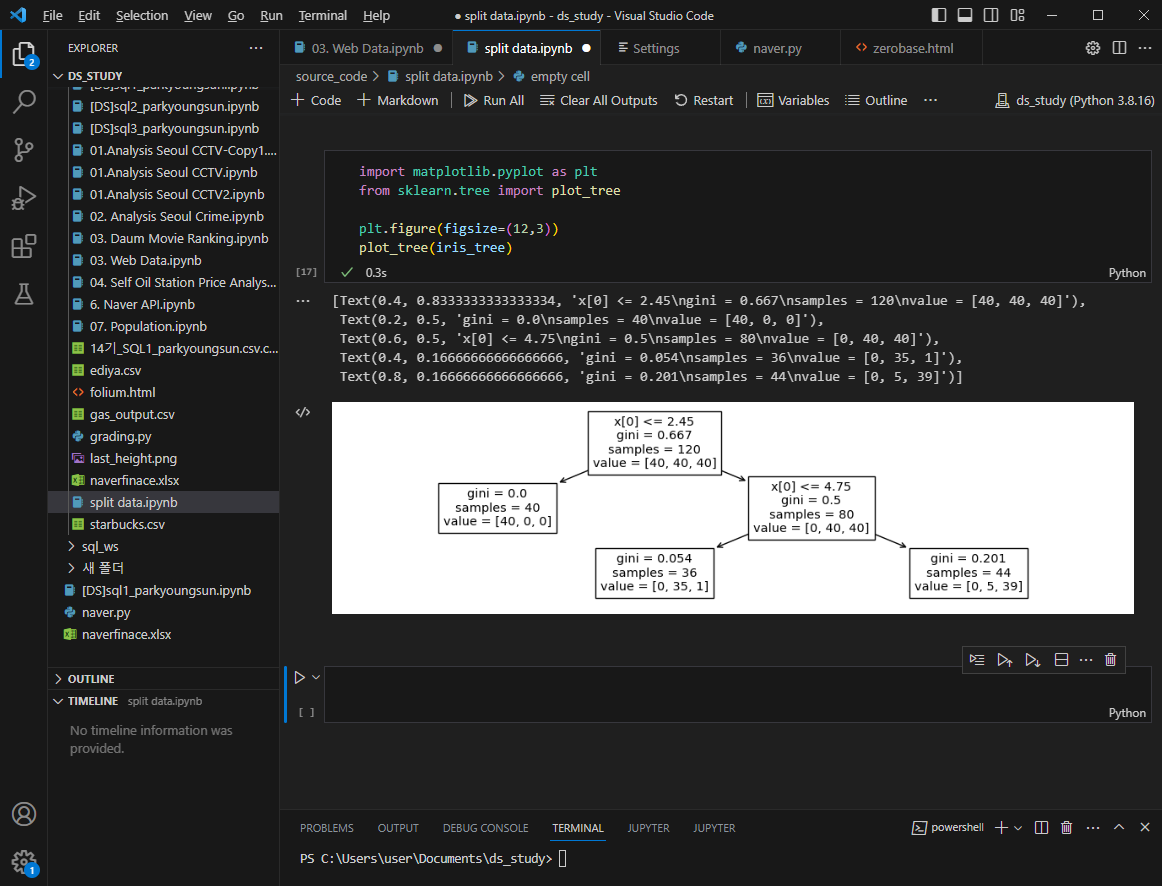
accuracy 계산

데이터 나누기 전보다 accuracy 가 떨어진 것을 확인 가능
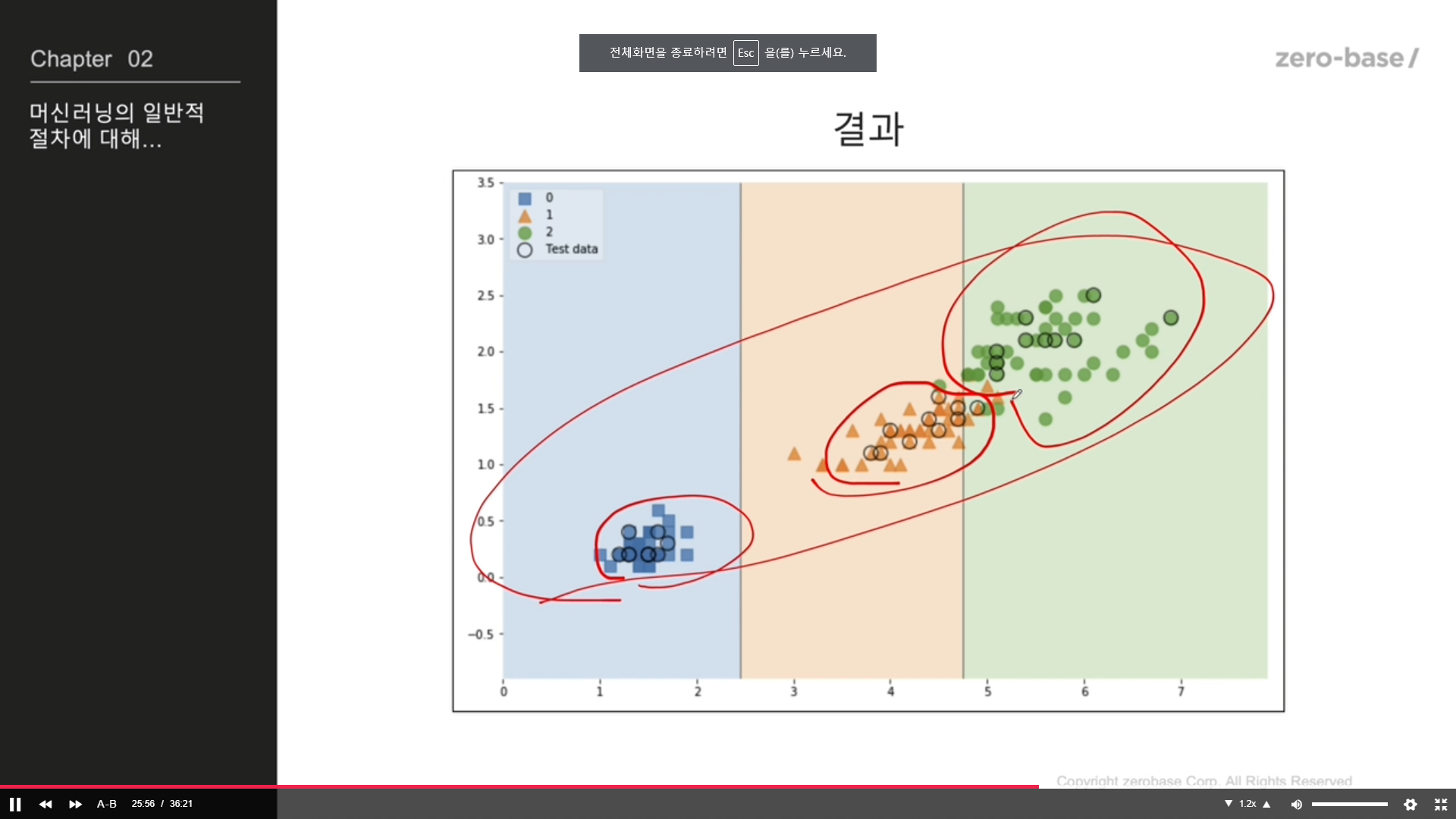
결정경계

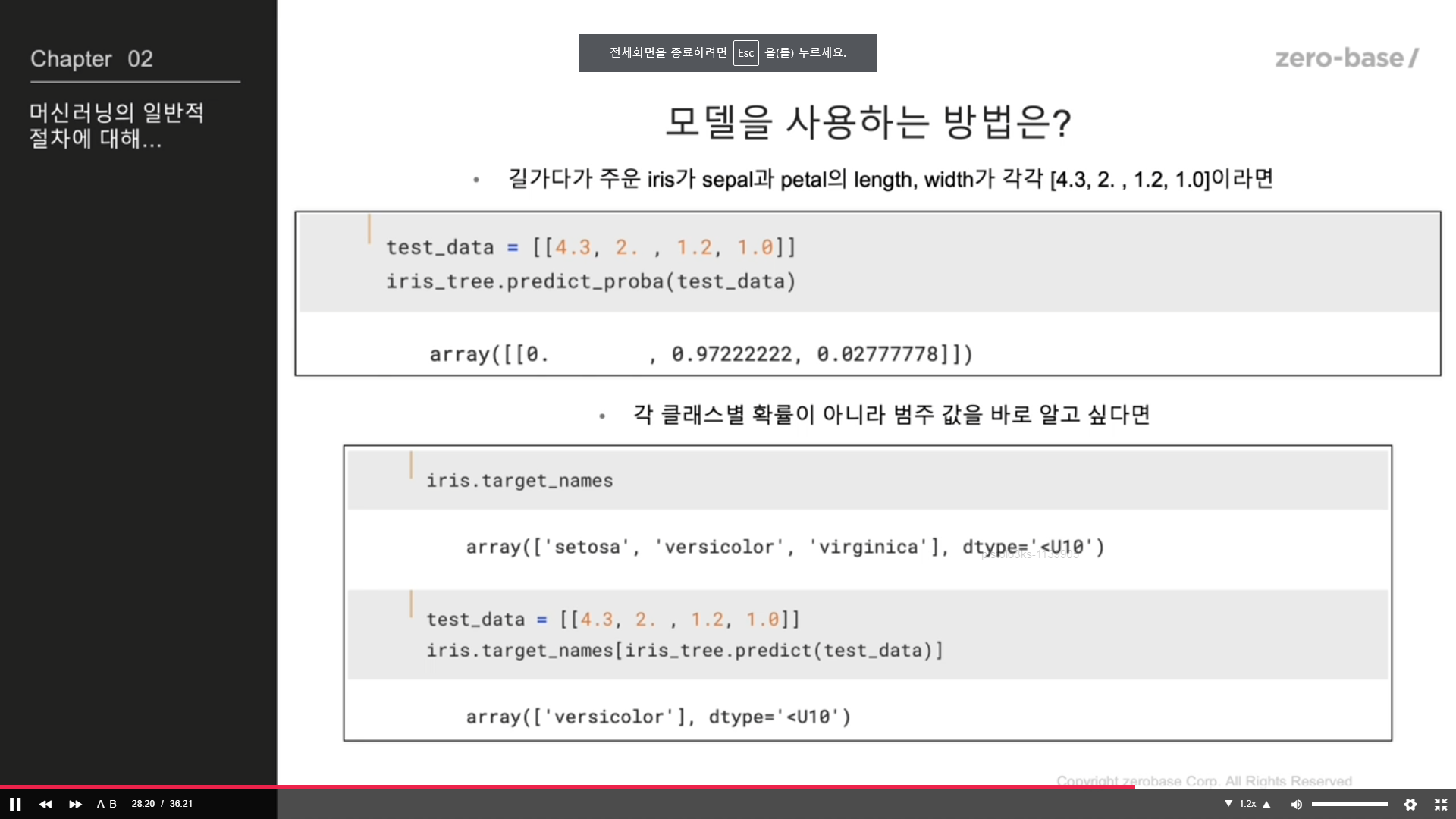
모델을 사용하는 방법?
데이터나누기3
Decision Tree를 이용한 Iris 분류 - 간단한 zip과 언패킹
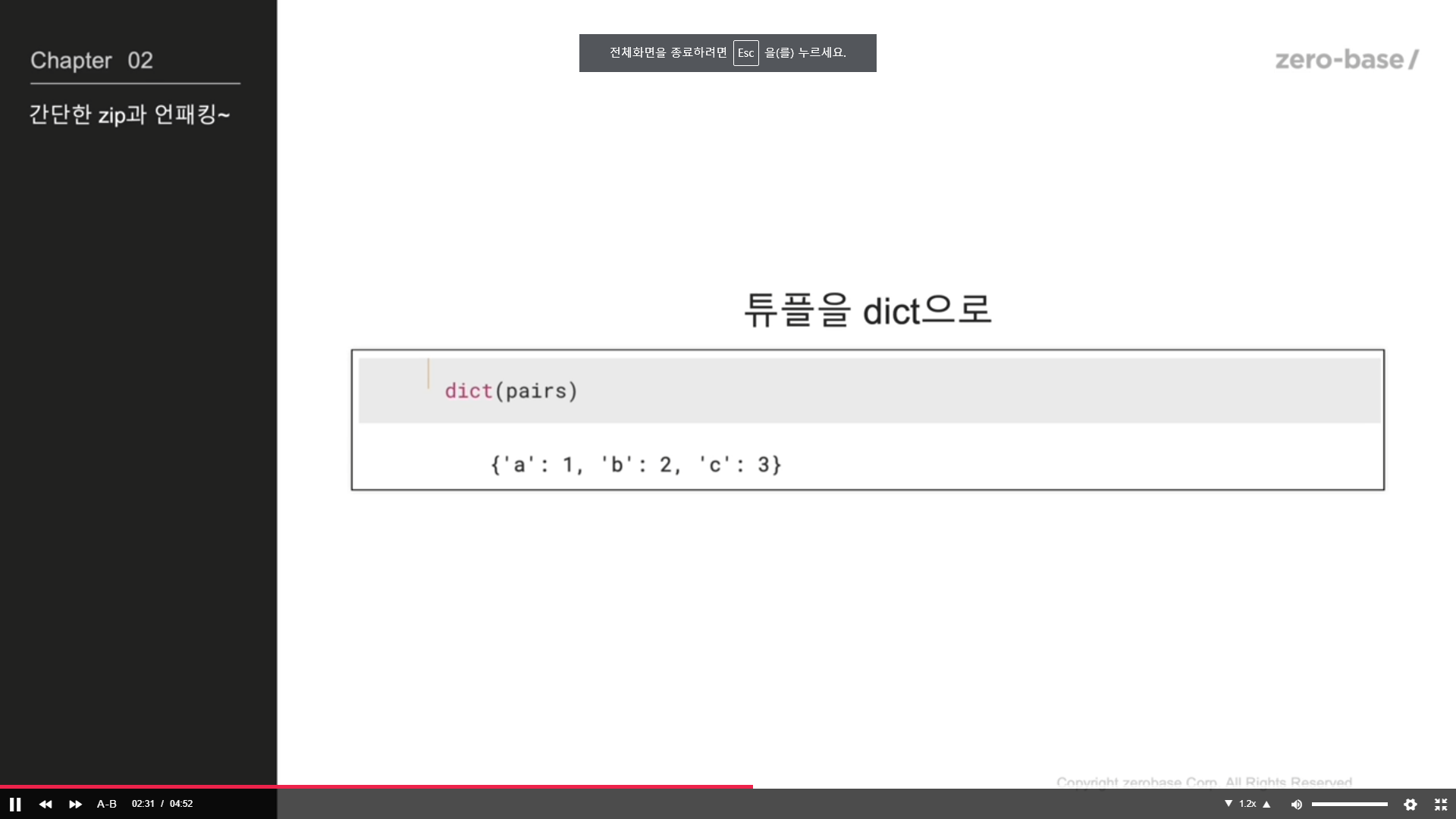
리스트를 튜플로 만드는 zip

튜플을 dict으로