들어가기 전에,
KMP / Rabin - Karp 알고리즘
문자열 찾기의 최악의 경우, O(MN)의 시간 복잡도가 나올 수 있는데, 위 알고리즘을 활용하면 O(N)으로 끝낼 수 있습니다. (N: 본 문자열의 길이, M: 서브 문자열의 길이)
KMP - 서브 문자열에서의 일정 패턴
본 문자열 : aaaaabb
서브 문자열 : aaab

a - b가 맞지 않았으므로, 서브 문자열을 오른쪽으로 한 칸 움직인 후 다시 비교.
이런 식으로 해나가면 O(MN)의 시간 복잡도를 갖습니다.
아래처럼 문자열 비교를 하기 전에, 서브 문자열을 분석하고 인덱스를 기록합니다.
그리고 서브 문자열에서, 미스매치가 된 곳의 한 칸 전의 인덱스 정보를 읽습니다.

즉, b 바로 직전 a의 인덱스 정보를 읽습니다.. idx = 2.
따라서 미스매치가 난 곳에서, 서브의 2번째 문자부터 비교해 나가면 됩니다.

또다른 예

미스매치 난 곳에서, 서브의 2번 문자부터 비교해나가면 됩니다.

또 미스매치가 났으므로, b의 인덱스 정보를 읽는다. 미스매치 난 곳에서 0번 문자부터 비교합니다.

이런 식으로 비교해나가는 방식이 KMP 알고리즘입니다. 다만, 미숙하면 급박한 상황에서 구현하기 어려울 수 있습니다.
더 쉬운 Rabin - Karp (Rolling - Hash) 방법을 사용할 수 있습니다. 이번 문제에서 제가 사용한 방법입니다.
준비물 : 서브 문자열의 길이(윈도우 크기), 서브 문자열의 해시값(HashCode로 손쉽게 구할 수 있습니다.)
본 문자열의 첫 번째 문자부터 윈도우를 적용하여 움직이는데, 윈도우가 본 문자열의 끝 문자를 넘어서지 않게 해야 합니다.
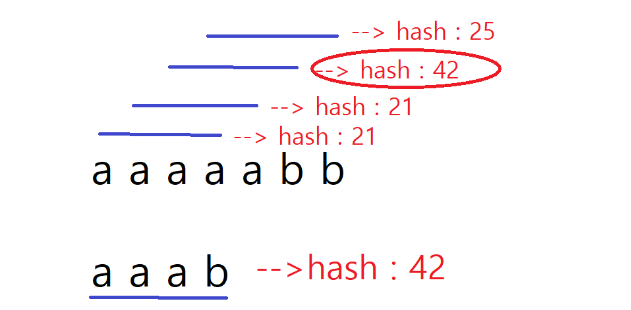
조건) 본 문자열에서 서브 문자열을 찾았으면, 새로운 윈도우는 이전 윈도우와 겹치면 안 됩니다.
즉,

위 그림의 빨간 윈도우는 카운트 되면 안 됩니다.
이를 위해서 만약 현재 윈도우에서 서브 문자열의 해시값과 동일한 값이 발생한다면,
그대로 윈도우 크기만큼 뒤로 물립니다. (start += finderLength)
본 문자열의 윈도우에 해당하는 문자들을 뽑아내야 하는데, 만약 윈도우가 본 문자열의 끄트머리를 넘어선 상황이라면, ArrayIndexOutOfBounds가 발생합니다.
따라서, 본 문자열 내를 가리키는 윈도우에 한해서만 해시값을 만들어야 합니다.
(i <= docsLength -1)
만약 윈도우가 본 문자열 바깥으로 삐져나갔다면, 절대 서브 문자열을 찾을 수 없습니다.
따라서 검색을 종료합니다. (docsLength < start + finderLength 혹은 stat가 왼쪽으로.)
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader bfr = new BufferedReader(new InputStreamReader(System.in));
char[] docs = bfr.readLine().toCharArray();
String finder = bfr.readLine();
int docsLength = docs.length;
int finderLength = finder.length();
int finderHash = finder.hashCode();
StringBuilder sb = new StringBuilder();
int start = 0;
int cnt = 0;
while (true) {
for (int i = start; i < start+finderLength; i++) {
if(i <= docsLength -1)
sb.append(docs[i]);
}
if (finderHash == sb.toString().hashCode()) {
start += finderLength;
cnt++;
} else {
start++;
}
if (docsLength - start < finderLength)
break;
sb.delete(0, sb.length());
}
System.out.println(cnt);
bfr.close();
}
}