1. Python 문법
파이썬 문법 내용중 이번주 강의 및 시행착오를 통해 새롭게 배운 내용들을 정리한다.
1-1. 자료형==객체
파이썬에서 어떤 자료형으로 변수를 선언한다는 것은 그 자료형의 객체를 하나 만든 다는 것을 의미한다. 이러한 특성으로 인해 우리는 list.append()와 같은 메서드들을 사용할 수 있는 것이다.
1-2. 객체와 클래스
객체는 메모리상에 공간을 할당받아 실제로 존재하는 소프트웨어적인 개념뭉치를 의미한다. 클래스는 이런 객체들을 만들어내기 위한 설계도와 같다. class에는 기능(method)와 데이터를 함께 묶을 수 있으며, 부모 클래스(혹은 super class)에 선언된 변수, 메서드를 그대로 가져와 사용가능하는 동시에 부모의 코드중 일부를 조금 변형해 사용할 수 있는 상속이 가능하다.
1-3. any, all
list나 tuplle등의 각 요소의 True/False여부에 따라 boolean으로 결과를 반환하는 함수들이다. any는 하나라도 참일때 참을 반환하고 all은 모두 참일때 참을 반환한다.
1-4. parameter, arguments
매개변수(파라미터)는 함수를 정의할 때 값을 넘겨받는 변수이다. 즉 f(x)=2*x에서의 x에 해당한다. 인자는 함수에 넘겨주는 값을 의미한다. 즉 f(x)=2*x, f(3)=6에서 3을 의미한다.
파라미터에는 기본값을 지정할 수 있다.
def sum_two_int(a=10,b=10):
return a+2*b함수에 인자는 기본적으로 순서대로 매개변수에 대입(positional arguments)되지만, keyword argument를 사용하면 순서에 상관없이 지정할 수 있다. 그러나 둘을 혼용할 때는 반드시 positional arguments가 먼저 와야한다. 함수를 정의할 때도 default argument가 적용된 파라미터는 뒤쪽으로 와야한다.
packing/unpacking
다음과 같이 함수의 매개변수 앞에 있는 *, ** 을 붙이면 받아오는 모든 인자를 튜플/딕셔너리 형태로 묶어서 가져온다.
def func(*args):
s=0
for i in args:
s+=i
return s
def get_kwargs(**kwargs):
print(f"{kwargs['name']} is {kwargs['age']} old.")이렇게 함수가 인자의 갯수에 제한을 두지 않고 받을 수 있게하는 것을 packing이라고 한다. packing 인자는 반드시 일반적인 positional arguments보다 뒤에 오도록한다.
1-5. decorator
데코레이터는 함수를 장식하여 함수가 실행될 때 함께 실행되도록 한다. 이를 이용해 함수의 실행시간을 측정하거나, 함수가 받는 인자를 한번 조작하여 실행하게 할 수 있다.
# 호출 할 함수를 인자로 받는다
def decorator_trackingfunc(func):
# 호출 할 함수를 감싸는 wrapper 함수
def wrapper(a,b):
# func.__name__: 호출 한 함수의 이름
print(f"{func.__name__} 시작:{time.time()}")
func(2*a,2*b) # 데코레이터에서 인자에 조작
print(f"{func.__name__} 종료:{time.time()}")
# wrapper 함수를 반환한다.
return wrapper
# 사용시에는 @[데코레이터 이름]
@decorator_trackingfunc
def decorator_func():
print("hello")1-6. file, json, csv
파이선에서는 외부 파일을 읽고 편집가능하다. 파일은 열고나서 반드시 닫아준다. with구문을 사용하면 자동으로 파일이 닫힌다.
# open 함수를 사용해 파일 열기
# 파일 경로, 모드(r:읽기/w:비우고 쓰기/a: 줄 추가), 인코딩 지정
f = open("file.txt", "w", encoding="utf-8")
f.write("hello world!")
# 파일닫기
f.close()
# with 구문:끝나면 자동으로 파일이 close
with open("file.txt", "a", encoding="utf-8") as w:
w.write("파이썬 내용 추가 테스트!")
# r: 읽기모드
with open("file.txt", "r", encoding="utf-8") as f:
while True:
# 한 줄 씩 출력
line = f.readline()
# 파일 끝:반복중지
if not line:
break
# 줄바꿈 문자 제거
line = line.strip()
print(line)json은 dictionary와 형태가 유사하며 서로 변환하여 사용한다.
import json
response_content = json.loads(r.text) # text json to dict
...
json_output=json.dumps(response_content) # dict to jsoncsv는 쉼표로 필드를 구분하는 텍스트 형식의 데이터이다. 이런 특성으로 인해 python으로 간단하게 편집, 생성가능하다. csv.reader(불러올 파일 이름)은 리스트의 리스트 형식으로 불러오고 csv.DictReader(불러올 파일 이름)은 딕셔너리의 리스트 형식으로 불러온다. 편집하는 것은 csv.writer()를 생성하여 writer.writerow(리스트)로 줄을 추가할 수 있다.
1-7. 예외처리(try/except)
코드에서 에러가 발생해도 실행을 종료하지 않고 건너 뛰어 다음 줄을 실행할 수 있게 해준다. execpt 뒤에 에러 종류(KeyError 등)를 지정할 수 있으며 Exception은 모든 error를 처리한다. 여러종류의 예외처리를 if/elif/.../else처럼 처리할 수 있다. 디버깅 시 혼동스러우므로 남발하지 않는다. as를 사용해 에러메시지를 변수로 받아올 수 있다.
1-8. 객체와 is
두 리스트 객체의 값을 비교하려다 오류가 발생하여 알게되었다. is는 두 대상이 메모리상에서 같은 객체를 가르키는 변수인지를 확인한다. ==는 이와 달리 두 대상이 가지고 있는 값을 비교한다.
a=10
b=10
print(a is b) # True>>> c = 100
>>> d = 100
>>> c == d
True
>>> c is d
True그러나 is의 동작은 가끔 일관성이 없어 보일 수 있는데 이는 작은 값의 int 객체들을 미리 caching하는 등의 코드상에서 명시되지 않는 동작이 원인일 수 있다. 따라서 컨벤션에서는 is는 다음과 같은 상황을 제외하면 사용이 권장되지 않는다.
- 두 대상이 같은 객체임을 확인하고 싶을 때 사용한다.
- None과같이 singletion객체와의 비교에 사용한다.
None은 singleton 객체중 하나이다. 싱글톤 객체는 메모리상에 단 하나의 인스턴스로 존재한다. 따라서 None과의 비교는 is를 써도 안전하다.
이 외에는 항상 ==를 쓰도록 한다.
1-9. 들여쓰기
코드를 편집하던 중, 올바르게 들여쓰기가 되어있음에도 계속해서 error가 있음을 나타낼 수 있다. 이때는 다음과 같이 들여쓰기가 같은 형식으로 되어있지 않은지 확인한다.

VSC는 코딩을 편리하게 도와주는 여러 들여쓰기 관련 설정을 가지고 있으며 파일별로 들여쓰기 설정이 가능하다.
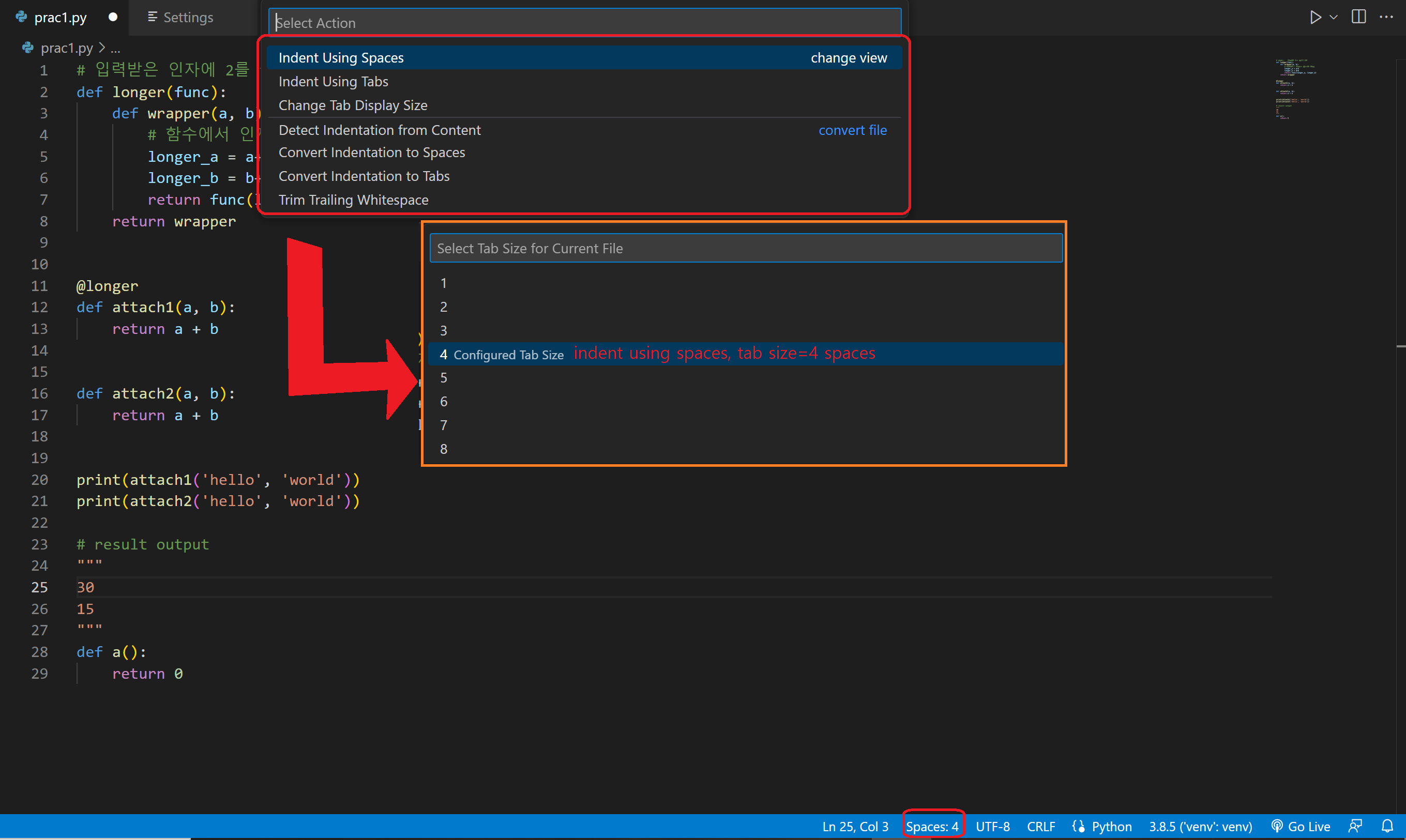
오른쪽아래의 spaces:4를 클릭하면 현재 파일에서의 들여쓰기 설정을 만질 수 있다. pep8에 따르면 indent using spaces, tab size 4 가 권장된다. tab키를 누르면 4개의 spaces가 입력된다.
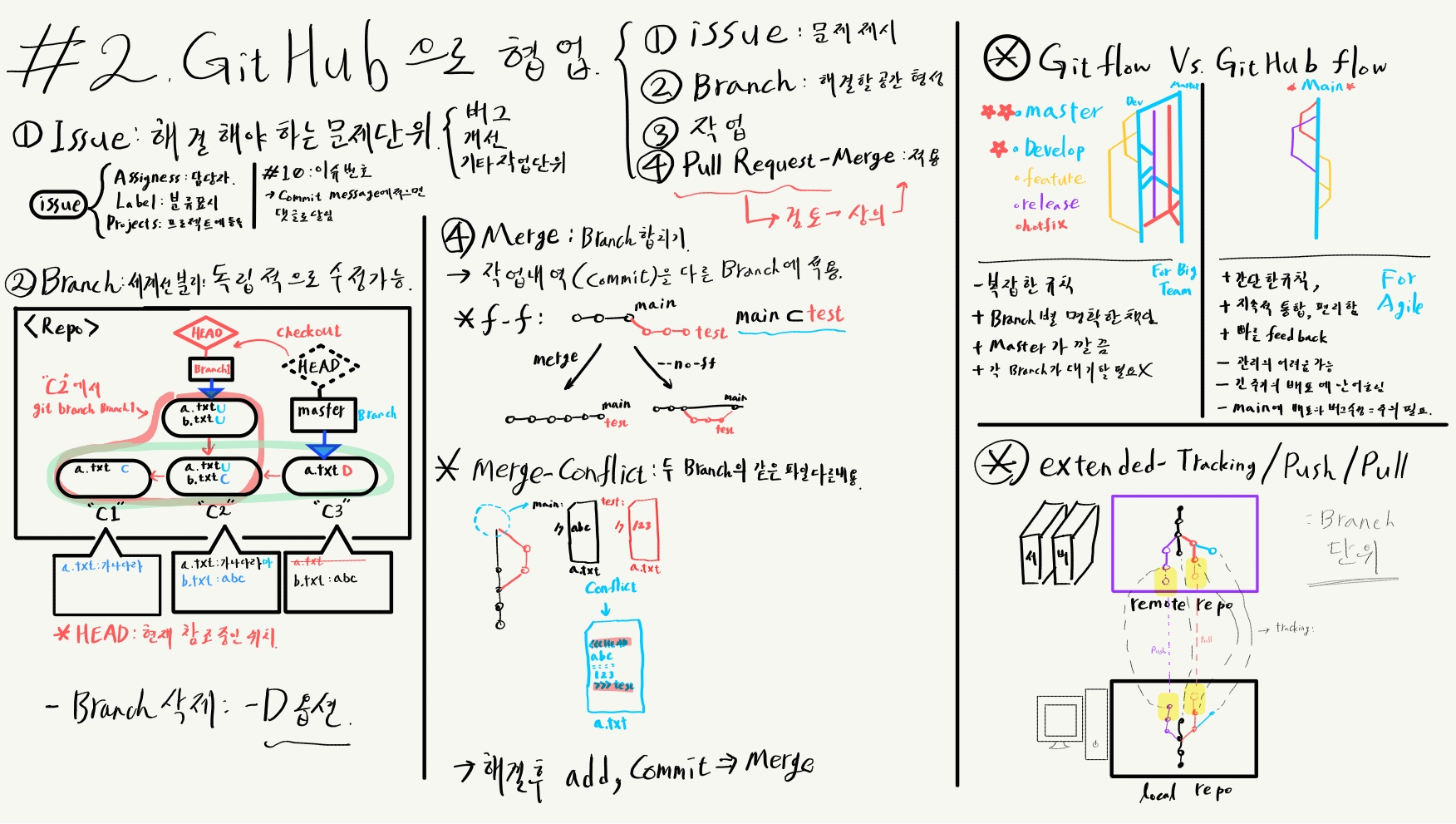
2. git 협업-issue/branch/merge
issue
이슈는 프로젝트에서 해결해야할 문제들을 말한다. 버그, 기능추가등의 개선사항, 버그와 개선을 위한 작업 단위들을 포함한다.
GitHub issue 등록하고 관리하기
Repo의 issue 탭에 들어가서 new issue를 누르고 내용을 작성한다.
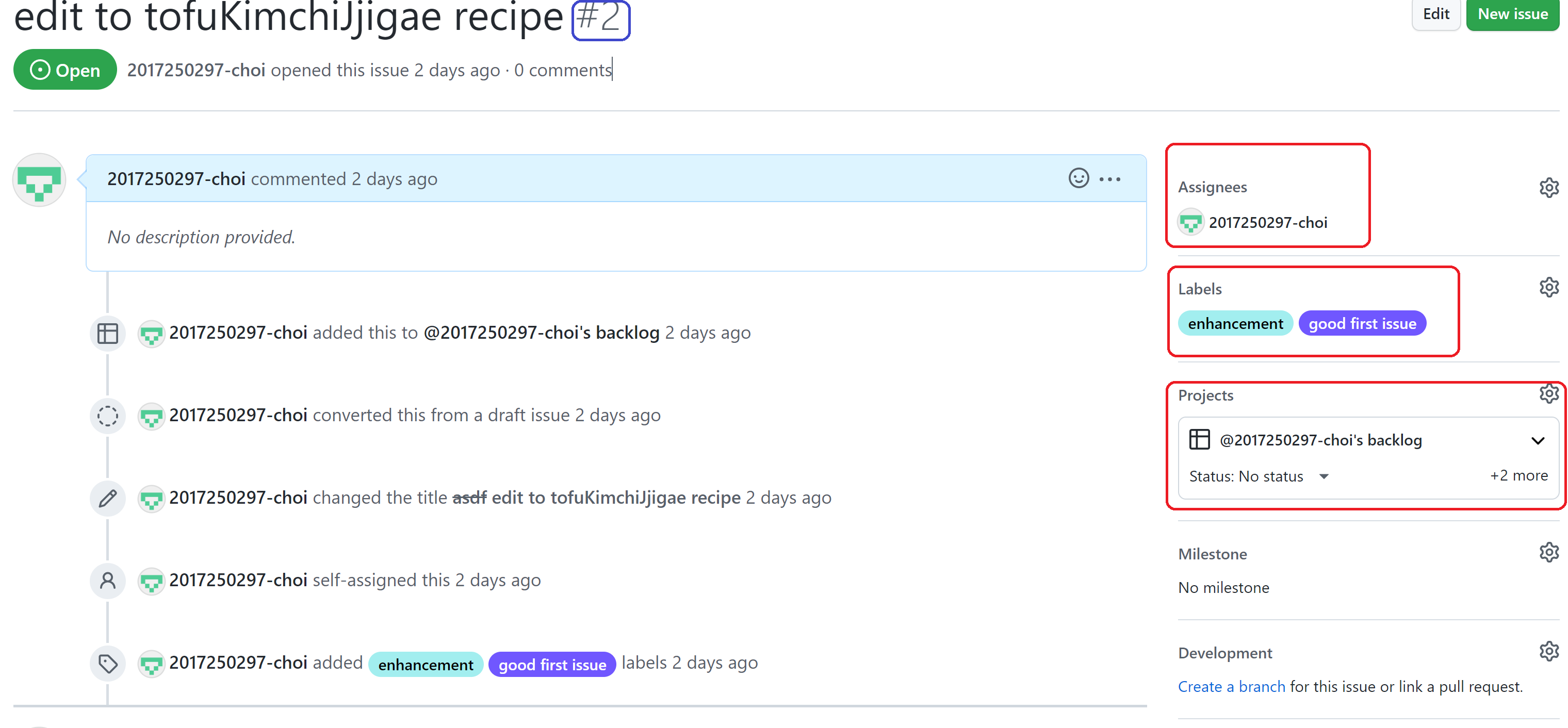
commit message에 issue 번호를 넣으면 해당 이슈와 관련된 commit으로 판별되며 issue 댓글란에 추가된다.
Branch
Branch는 원래 코드와는 상관없이 독립적으로 개발을 진행할 수 있게 해준다. git의 브랜치는 매우 가벼우므로 브랜치를 만들어 작업하고 merge하는 것을 공식적으로 권장하는 매우 중요한 기능이다.
git branch: 브랜치 생성 후 작업
git branch <브랜치 이름>을 입력하여 브랜치를 생성한다.
브랜치 이름은 종류/이슈번호_원하는이름와 같이 짓는다. (예: feature/2_login)
새 branch에 commit을 하려면 해당 branch로 checkout한다: git checkout <branch명>
git branch -D: 브랜치 삭제
git branch -D <branch명>을 입력하여 브랜치를 삭제한다. 커밋들은 삭제되지 않고 남아있으며(git checkout 으로 조회 가능) commit들이 이루는 tree의 leaf를 가리키던 branch 포인터가 사라지는 것이다.
브랜치 merge
현재 branch에 다른 branch의 commit내역을 모두 반영한다.
실제 프로젝트에서는 flow 방식에 따라 1개이상의 기준이 되는 branch를 정하고 그곳에 merge한다.
git merge --no-ff:
기준이 될 branch(main)으로 checkout 한 뒤 git branch merge <branch명>을 입력하면 merge를 진행한다. 이때 --no-ff옵션을 사용해주면 좋다.
fast-forward
fast-forward는 두 branch의 관계에 따른다. 병합하고자 하는 branch의 commit history 내에 현재 branch의 commit history가 포함되는 관계를 fast-forward라고 한다. 이 경우 --no-ff 옵션을 사용하지 않으면 모든 commit이 기준이 되는 branch에 합쳐진다.
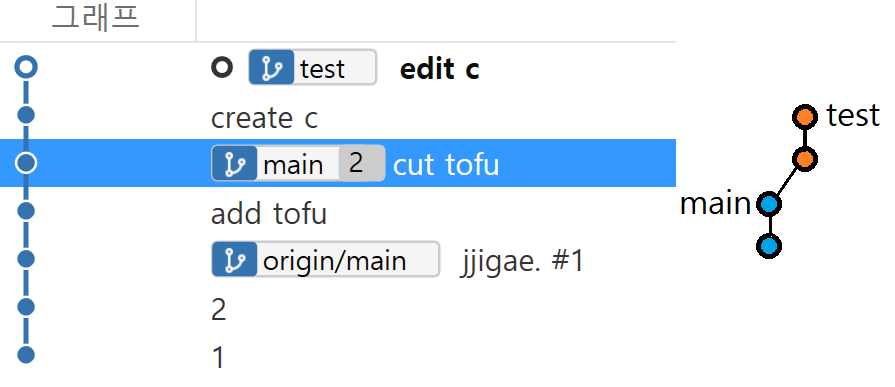 merge 전
merge 전
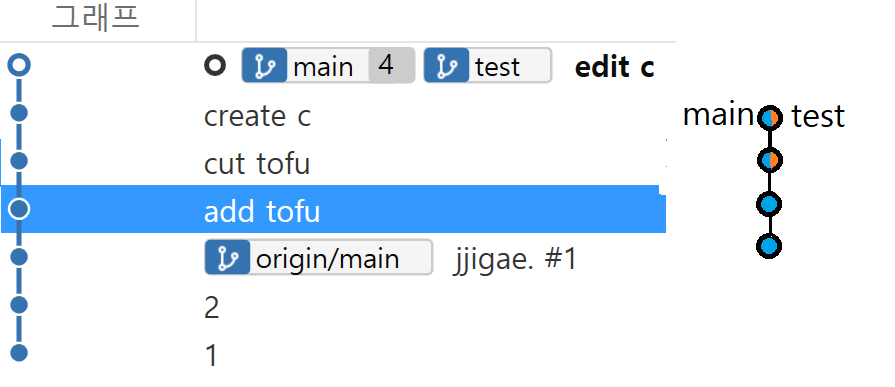 merge 후
merge 후
--no-ff옵션을 사용하면 fast-forward가 가능한 상태여도 그렇지 않은 것 처럼 merge commit을 새로 만든다.
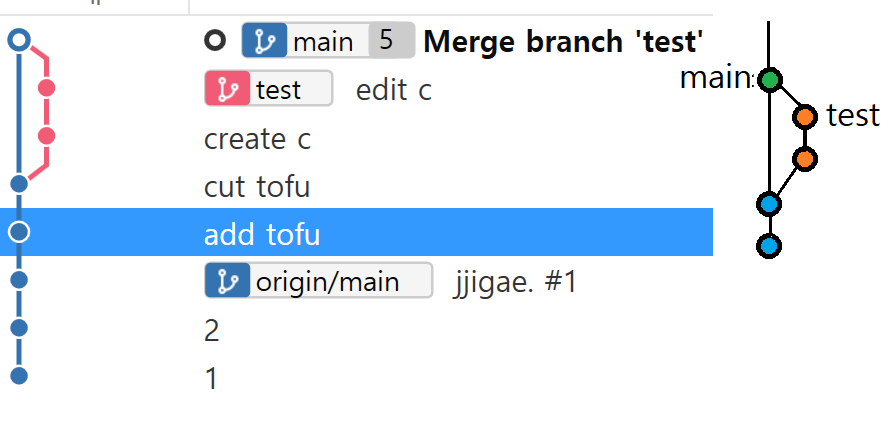
merge-conflict
merge시 같은 파일의 같은 부분의 수정사항이 다를 시, conflict가 발생할 수 있다. merge conflict가 발생하면 해당 파일의 해당 부분에 다음과 같은 변화가 생긴다.
<<<<<<< HEAD
{현재 브랜치 내용}
=======
{충돌 브랜치, commit에서의 내용}
>>>>>>> 충돌 브랜치명 or commmit 아이디재량껏 수정하되, <<<<<<< HEAD와 >>>>>>> cftest만 없어지면 git은 충돌이 해결된 것으로 판단한다.
이후 git add <파일명>을 하고 git commit을 하면 merge가 완료된다.
tracking, Push / Pull 개념 재정의
tracking은 단순히 로컬 repo와 원격 repo의 연결이 아니라, 원격 repo의 한 branch와 로컬 repo의 한 branch 간의 연결관계를 의미한다. 따라서 실제로 push/pull을 할때는 어떤 branch를 대상으로 할지 정해야한다. --set-upstream옵션을 통해 설정할 수 있다.
git push --set-upstream <원격repo이름(origin)> <원격branch명>push시에는 해당 이름의 원격 branch가 없을 때에는 새로 만들어서 tracking을 한다.
Push와 Pull은 모두 브랜치 단위로 이루어지는 것이다.
한번에 모든 branch를 push하고 싶다면 --all 옵션을 사용한다.
브랜치 단위가 아닌 전체 저장소를 업데이트 하고 싶다면 git clone을 이용하면 된다.
개념도
한번에 여러 branch pull하기
clone 이후 로컬 레포에 메인브랜치만 가져와 진 경우나, 여러 로컬브랜치들이 여러 원격 브랜치들을 추적중일 때 한번에 pull하고 싶을 수 있다. 그러나 pull은 사실 fetch와 merge를 함께 실행하는 것으로, 충돌 발생시 파일을 편집할 수 있어야 하므로 반드시 해당 브랜치의 working directory를 확보해야하고 따라서 지금 checkout하고 있는 branch만 pull할 수 있다.
이를 해결하기 위해서는 다음과 같이 반복문을 사용하여 checkout-pull하는 방식을 사용할 수 있다.
for branch in `git branch -r`; do
git checkout -b ${branch#origin/} $branch;
done3. 알고리즘: 재귀vs반복, BFS
어떤 문제를 풀던 중 이진 트리를 모두 조회하기 위한 방법으로 재귀함수를 사용하였다. 이때 재귀함수를 사용하자 프로그래머스 환경상에서는 런타임 에러(재귀 한계 초과)와 시간초과가 나타났다.
재귀함수는 이진 트리의 특성상 적용하기 직관적이고 이해하기 좋다는 장점이 있으나, 이렇게 일부 환경에서는 오버플로우나 오버헤드로 인해 실행이 어려울 수 있다.
이를 해결하기 위해 BFS를 응용한 반복문형태의 알고리즘을 사용하였다.
def is_orphan(bit_list):
sub_lists = [bit_list]
while len(sub_lists[0]) != 1:
sub_list = sub_lists.pop(0)
mid = len(sub_list)//2
l_root = int(sub_list[mid//2])
r_root = int(sub_list[mid + 1 + mid//2])
if (not int(sub_list[mid])) and (l_root or r_root):
return True
sub_lists.append(sub_list[:mid])
sub_lists.append(sub_list[mid+1:])
return False
BFS는 broad first search로, edge에 가중치가 없는 graph에서 한 상태에서 다른 상태로의 이동횟수가 가장 적은 경로를 찾기위해 tree형태로 graph를 재해석하여 한층한층 탐색하는 알고리즘이다.
sub_lists는 앞으로 탐사해야할 노드들을 담는 queue의 역할을 한다. 또한 탐색할 graph가 tree형태이므로 visited list는 필요없다.
subtree의 root를 len(sub_list)를 통해 찾아내는 것으로 다음에 방문한 노드 후보들을 추가한다.
goal check는 해당 노드가 존재하지 않고 해당 노드의 subtree의 root들이 존재하는지 체크하는 것이 대신한다.
이렇게 하여 더 간결하게 tree를 탐색하는 코드를 만들 수 있었다.
차주 목표
- 알고리즘/자료구조 강의 완강
- 개인과제와 팀 과제를 git을 이용해 성공적으로 마무리하기
- 코딩 테스트 1일 1개 이상 풀고 TIL에 체계적으로 정리하기
- 좀더 체계적으로 TIL 작성하기: 강의 내용은 따로 묶어 저장하고, 그 외적으로 배운 것을 TIL로 짧고 굵게 정리하자.
- 생각의 흐름을 최대한 많이 기록하여 놓치는 것 없이 배운 것을 기록하도록 한다.
금주 반성
- 새로운 python문법 익히기
반복문, 재귀함수등 이미 알고 있으며 어느정도 활용가능한 문법들을 더 능숙하게 사용할 수 있게 되었다. 또한 클래스와 객체의 개념을 더 명확히 이해하고 클래스의 기초적인 사용에 익숙해졌다. - gitHub사용법 숙달하기
git 강의를 모두 수강하여 git hub의 사용에 더 능숙해졌다. - 코딩 테스트 3문제 이상 풀기
개인적으로 3문제 이상 풀었고, 동기들과 함께 파이썬을 숙달하기 위한 문제들을 2~3문제 풀어보았다. 앞으로도 개인적으로 코딩테스트를 조금씩이라도 풀어보자. - 잘 못한것: 풀고 나서 정리하기
아직도 TIL을 어떻게 정리해서 작성해야할지 감이 잘 오지 않았다. 다음주 부터는 좀 더 체계적이고 구체적으로 작성하도록 노력해보자.
