
들어가기 앞서
실무의 데이터는 지저분하다
주어진 데이터를 유의미한 정보로 만들기 위해서는 많은 전처리 과정이 필요하다. SQL에는 이를 위한 여러 유용한 기능들이 존재한다.
query 작성시 마음가짐
subquery, with, case등을 사용하면 query문이 많이 복잡해질 수 있다. 언제나 query문을 작성할 때, 더 간단하고 알아보기 쉽게 작성할 수 있는지 고민해보는 자세가 필요하다.
0. SubQuery
서브 쿼리는 하나의 쿼리문 안에 또다른 쿼리문이 있는 것을 말한다. 예를 들면 다음과 같다.
select * from users u1
where u1.user_id in (select user_id from orders where email like '%gmail.com')위의 쿼리는 orders 테이블에서 보았을 때 gamil.com을 사용하는 사용자의 user_id의 목록을 뽑아내고 users 테이블 중 user_id가 그 목록에 있는 record만을 골라 조회한다. 이는 아래의 쿼리와 의미적으로는 동일하다.
select * from users u1 inner join orders o on u1.user_id=o.user_id
where o.email like '%gmail.com' subquery를 이용해 작성한 query와 아래의 쿼리는 결과에서 차이가 발생할 수 있다. 예를들어 users table에서는 하나뿐인 user_id와 일치하는 orders table의 record가 두개 이상 있을 수 있는데, subquery와
subquery를 이용해 작성한 query와 아래의 쿼리는 결과에서 차이가 발생할 수 있다. 예를들어 users table에서는 하나뿐인 user_id와 일치하는 orders table의 record가 두개 이상 있을 수 있는데, subquery와 where ~ in ()을 이용한 쿼리는 상관없이 하나의 record만을 조회하고, join을 사용하는 쿼리는 user_id가 같은 두개 이상의 record를 생성하므로 전체 조회된 record의 갯수가 다르게 된다.
이러한 결과의 차이와 sql문의 간결함, 직관성등을 고려하여 subquery를 이용한다.
1. where에 subquery 쓰기
subquery의 결과를 조건에 활용할 수 있다.
where (필드명,필드명, ...) in (subquery)subquery의 결과 field 수가 조건문의 field수와 같은 수일 때, 쿼리에서 해당 subquery의 결과 안에 있는 값을 가진 record 들만을 조회하도록 조건을 건다. 예를 들어 0. SubQuery 에서 사용된 다음 쿼리와 같이 사용한다.
select * from users u1 inner join orders o on u1.user_id=o.user_id
where o.email like '%gmail.com'실행 순서: from → subquery → where ... in → select문 종료
2. select에 subquery 쓰기
subquery를 이용해 기존 테이블에 함께 보고 싶은 통계 데이터를 가져다 붙일 수 있다.
select 필드명1, 필드명2, (subquery) from ...subquery의 결과가 단일 field, 단일 record일 때 상위 쿼리의 각 record마다 해당하는 record 값을 가져다 붙인 새 field를 생성한다.
예시:
select c.checkin_id, c.user_id, c.likes,
(select avg(likes) from checkins c2
where c2.user_id = c.user_id) as avg_like_user
from checkins c;위의 쿼리는 각 유저당 checkin의 like 수의 평균을 checkins 테이블에 붙이기 위한 쿼리이다. subquery는 상위쿼리의 c.user_id와 일치하는 record 들만 추려 like의 평균을 계산한다.
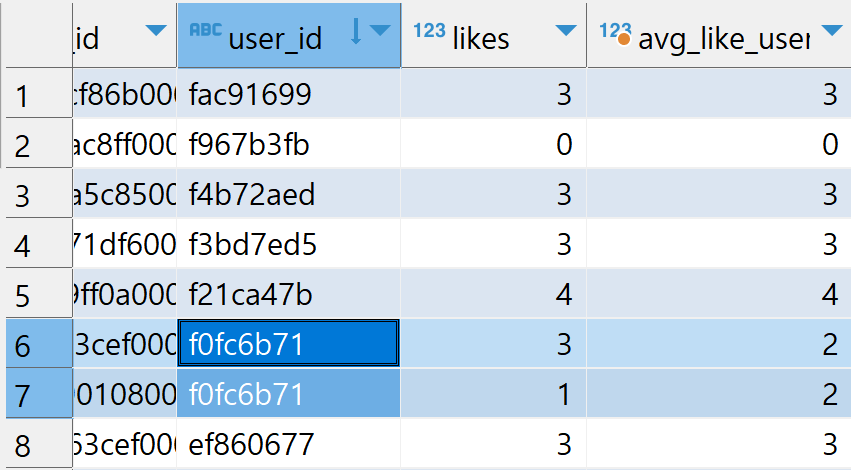
실행 순서: from → select문: 각 레코드 마다 subquery 반복 → 종료
3. from에 subquery 쓰기
내가 만든 select query 결과(subquery)와 이미 있는 table을 join할 때, 혹은 내가 만든 쿼리 결과를 이용해 새로운 query를 만들 때 사용할 수 있다. 가장 많이 쓰이는 유형이다.
select *
from 테이블1 inner join (subquery) [별칭] on ...예시:
select pu.user_id, a.avg_like, pu.point from point_users pu
inner join (
select user_id, round(avg(likes),1) as avg_like from checkins
group by user_id
) a on pu.user_id = a.user_id유저별 포인트와 like 수치를 비교하여 상관관계를 파악하고자 할 때, subquery를 이용해 user_id별 like 수 table을 만들고 이를 point_users 테이블과 join한다.
실행 순서: from → subquery: 테이블처럼 사용 → select문 종료
4. with
with문법을 사용하여 subquery를 더 깔끔하게 작성 할 수 있다.
with table1 as (s
ubquery1
), table2 as (
subquery2
)
select ...select문 위에 with문법을 작성하여 subquery로 만든 table을 지정한다.
5. 문자열 조작
실제 Data를 다룰 때에는 문자열 데이터를 원하는 형태로 정리해야하는 경우가 많다. 강의에서는 이를 위해 몇가지 함수를 소개하였다.
SUBSTRING_INDEX
문자열 data에서 어떤 특정 문자를 지정하여 그것을 기준으로 문자열을 자른다. 이후 번호를 지정하여 문자열 조각을 선택한다. 번호는 앞에서 부터 1, 2, 3, ..., -1 과 같은 식으로 지정된다.
예시: email주소에서 도메인만 분리하기
select user_id, email, SUBSTRING_INDEX(email, '@', -1) from usersSUBSTRING
문자열 data에서 시작지점과 길이를 지정하여 일부만 잘라온다.
예시: 시간 data에서 날짜만 가져오기
select substring(created_at,1,10) as date from orders6. case
select문에 사용하여 경우에 따라 원하는 값을 새 필드에 출력할 수 있다. 다음과 같이 사용한다.
select 필드명, 필드명,
case
when 조건문_1 then 출력_1
when 조건문_2 then 출력_2
else 출력_3
END as '별칭'
from ...예시: 포인트 1만점,5천점을 기준으로 user들을 분류하고 각 분류별 인원수를 구한다.
select level, count(*) as cnt from (
select pu.point_user_id, pu.point,
case
when pu.point >= 10000 then '1만 이상'
when pu.point >= 5000 then '5천 이상'
else '5천 미만'
END as level
from point_users pu
) a
group by level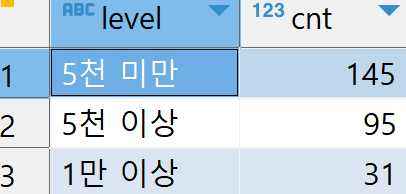 subquery에서 case문을 이용해 분류를 위한 새로운 field인 level을 만든다. 이 쿼리의 결과를 이용해 상위 쿼리에서 level별로 묶어 집계한다.
subquery에서 case문을 이용해 분류를 위한 새로운 field인 level을 만든다. 이 쿼리의 결과를 이용해 상위 쿼리에서 level별로 묶어 집계한다.
번외. 더나은 query 짜기
수강등록정보(enrolled_id)별 전체 강의 수와 들은 강의의 수(done = 1)를 출력하는 query를 작성한다고 할 때,
subquery를 이용해 들은 강의의 수는 조건문(where done = 1)을 건 subquery로 만들고 join으로 이어붙일 수 있다.
with lecture_done as (
select enrolled_id, count(*) as cnt_done from enrolleds_detail ed
where done = 1
group by enrolled_id
), lecture_total as (
select enrolled_id, count(*) as cnt_total from enrolleds_detail ed
group by enrolled_id
)
select a.enrolled_id, a.cnt_done, b.cnt_total from lecture_done a
inner join lecture_total b on a.enrolled_id = b.enrolled_id그러나 done = 1 인 경우의 수만 count하면 되고, done의 값이 0과 1만 있다는 것을 고려할 때, 다음과 같이 더 간단하게 작성할 수 있다.
select enrolled_id,
sum(done) as cnt_done,
count(*) as cnt_total
from enrolleds_detail ed
group by enrolled_id더 좋은 쿼리를 작성할 때는 전체적인 데이터 형태를 관망하는 것이 도움이 된다. 이를 위해 EDA(Exploratory Data Analysis, 탐색적 데이터 분석)를 하는 습관을 들이는 것이 좋다.
