n = input() print(n) -> hello hi hello hi hello hi hello hiinput()은 한 줄의 입력을 모두 저장한다
따라서 공백이 포함된 문자열도 한 줄에 넣어 입력할 수 있다
n = int(input()) print(n+4) 입력받은 값을 숫자로 인식하게 하려면 int()로 씌어줘야함
n = input.split() -> 123 456 ['123','456']공백을 기준으로 나눠서 리스트로 저장해줌
a,b = input().split() print(a) print(b) -> 2 8 2 8공백을 기준으로 알아서 a와b에 나누어 저장한다
이때 int(input().split()) 이런건 에러난다
int함수는 리스트에는 먹히지 않기 때문이다
map을 사용하면 된다
map(적용할 함수, 반복가능한 자료)a,b = map(int,input().split()) print(a + 2) print(b + 4) -> -1 1 1 5
배열
arr + 4byte x n 으로 메모리주소를 한 번에 계산을 해서 바로 접근하므로 탐색시간은 O(1)이다. 이렇게 바로 계산해서 접근하는 것을 임의접근(random access) 이라고 함
리스트
foods=["된장찌개","피자","파스타"]
random.choice( ["된장찌개","피자"])
foods.append("김밥") -> 리스트의 추가방법 (append 이용)
del foods[1] -> 1번 인덱스의 내용 삭제
반복문
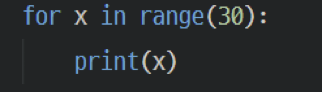
x는 0부터 29까지
내용은 들여쓰기를 기준으로 체크함
(두칸 들여쓰기)

foods 라는 리스트에 하나 씩 접근해서 x에 저장한다 그리고 x를 출력

딕셔너리에는 두가지 요소(key,value)씩 들어가 있으므로 x,y 로 해주고 .items() 를 붙여줘야 한다.
이렇게 되면 딕셔너리의 모든 요소에 접근 후 loop가 끝나므로 딕셔너리가 변경될 때 마다 for문을 수정 할 필요가 없어 편리하다는 장점이 있다.
출력방법
x="냉장고"
print(x)

- print의 숨은 기능 => 큰 따옴표로 여러개 출력가능
Dictionary
딕셔너리는 콜론을 기준으로 앞 부분은 key, 뒷부분은 value 라고 함
information = {"고향":"수원", "취미":"영화관람", "좋아하는 음식":"국수"}
print(information) -> 딕셔너리 전부 출력
print(information.get("취미")) ->취미에 해당하는 value를 출력 (get사용)
information["특기"] = "피아노" -
information["사는곳"] = "서울" ->딕셔너리에 추가하는 방법
del information["좋아하는 음식"] ->딕셔너리에서 삭제하는 방법
print(len(information)) ->딕셔너리의 length
information.clear() ->딕셔너리 비우기
집합(set)
집합은 중복되는 요소가 없다
리스트를 만들고 집합으로 만들어주는 과정이 필요
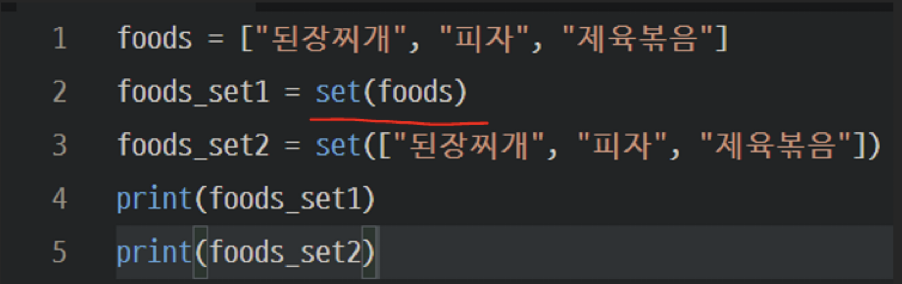
foods라는 리스트를 set(foods) 를 이용해 집합으로 만들어줌
합집합

교집합

차집합 (그냥 빼주면 됨)

<if 문>
if문 끝에 콜론 이랑 들여쓰기 주의

1.입력을 q를 하면 break (큰 따옴표를 쓰는 것 주의)
<사용자로부터 입력받는 법 input()>

- lunch라는 리스트에서 사용자로부터 입력을 받음 by input()
- 신기한건 input 안에 따옴표를 이용해 출력을 먼저하고 입력을 받을수가있음
- while True 하고 따옴표
<집합 주의할 점>

- 집합을 저렇게 만들어도 된다. ( [] 가 리스트임을 기억)
- item=”자장면” 은 그냥 문자열이므로 차집합연산이 안먹임
- []로 묶어서 일단 리스트로 만들고 set이라고 붙여서 집합으로 만들어주면됨
<빈 딕셔너리 만들고 사용자로부터 입력받아 채우기>
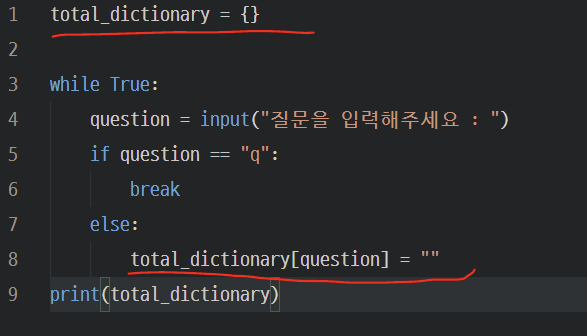
<key 먼저 채우기>
이렇게 되면 key 값에만 질문들이 들어가고 value는 빈 상태 ( value 는 “ “ 임)
그리고 if 문에서 조건 걸 때 괄호가 없어도 되네
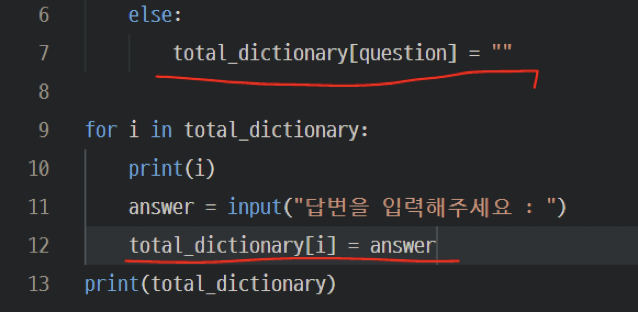
<그 다음value 채우기>
그니까 딕셔너리에서 key 는 약간 배열의 인덱스 개념으로 생각하면 되겠네
두 번째 빨간줄은 딕셔너리에 value를 넣어주는거임 ( answer로 입력을 받아서)
< 리스트안에 딕셔너리가 있는 형태 ( line 1 보면 위와 다르게 list 형태임)>

크게 보면 while 문으로 질문을 입력받고 for문으로 답변을 입력받는 형태
line 8 을 보면 list의 추가방법인 append를 입력해서 질문은 question으로 받아서 넣고 답변은 공백상태로 일단 받는것으로 볼 수 있음
line 10 은 토탈리스트의 모든 항목이 나올때까지 for문이 돌아가는 것이고
line 11은 리스트 내에 딕셔너리가 있는데 그 중에서 key에 해당하는 “질문” 만 출력하는것임
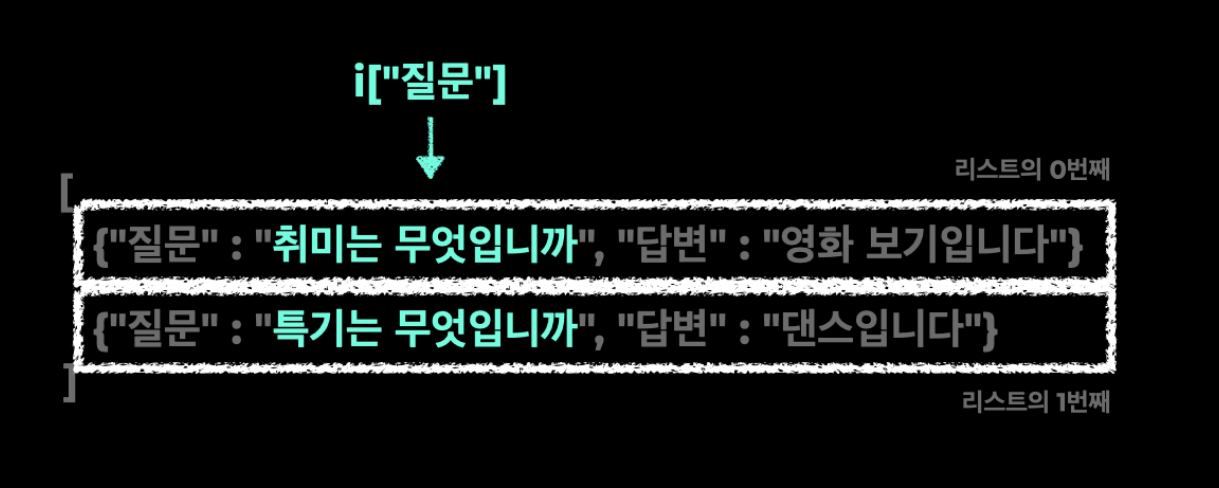
<line11 설명>

그럼 이렇게 나옴
<함수>

함수는 앞에 def 써주고 끝에 콜론 : 주의
그리고 함수 정의는 들여쓰기 해주고 써주면 됨
