
유형별 파이썬 알고리즘을 풀어보며 간략하게 정리를 해봤습니다 👩🏻💻😁
저의 복습에도 도움이 되고 여러분의 학습에도 도움이 되길 바랍니다 ㅎㅎ
그리디 알고리즘 (탐욕법)
지금 당장 가장 좋은 것을 고르는 알고리즘
-> 그리디 알고리즘이 출제되면 그리디로 얻은 답이 최적의 결과를 가짐
그리디 예시 문제
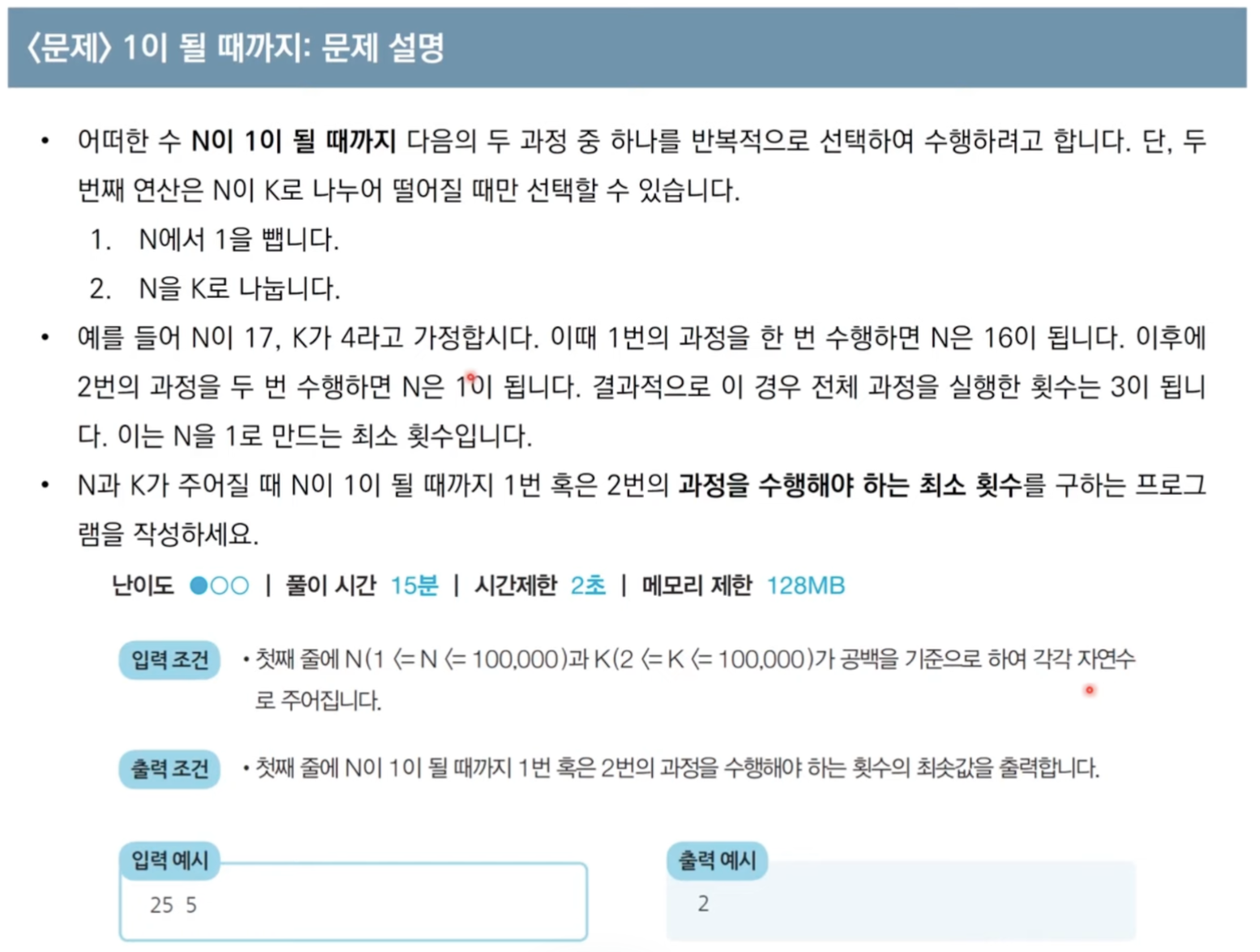
문제 1) 1이 될 때까지
풀이 코드n = 25 k = 5 result = 0 while True: target = (n // k) * k # 현재 k로 나누어떨어지는 값에서 가장 근접한 값 result += (n - target) # target이 될 때까지 1을 빼야하는 개수 n = target if n < k: break n //= k result += 1 result += (n - 1) # 1이 될 때까지 빼야하는 개수 print(result) ## 2
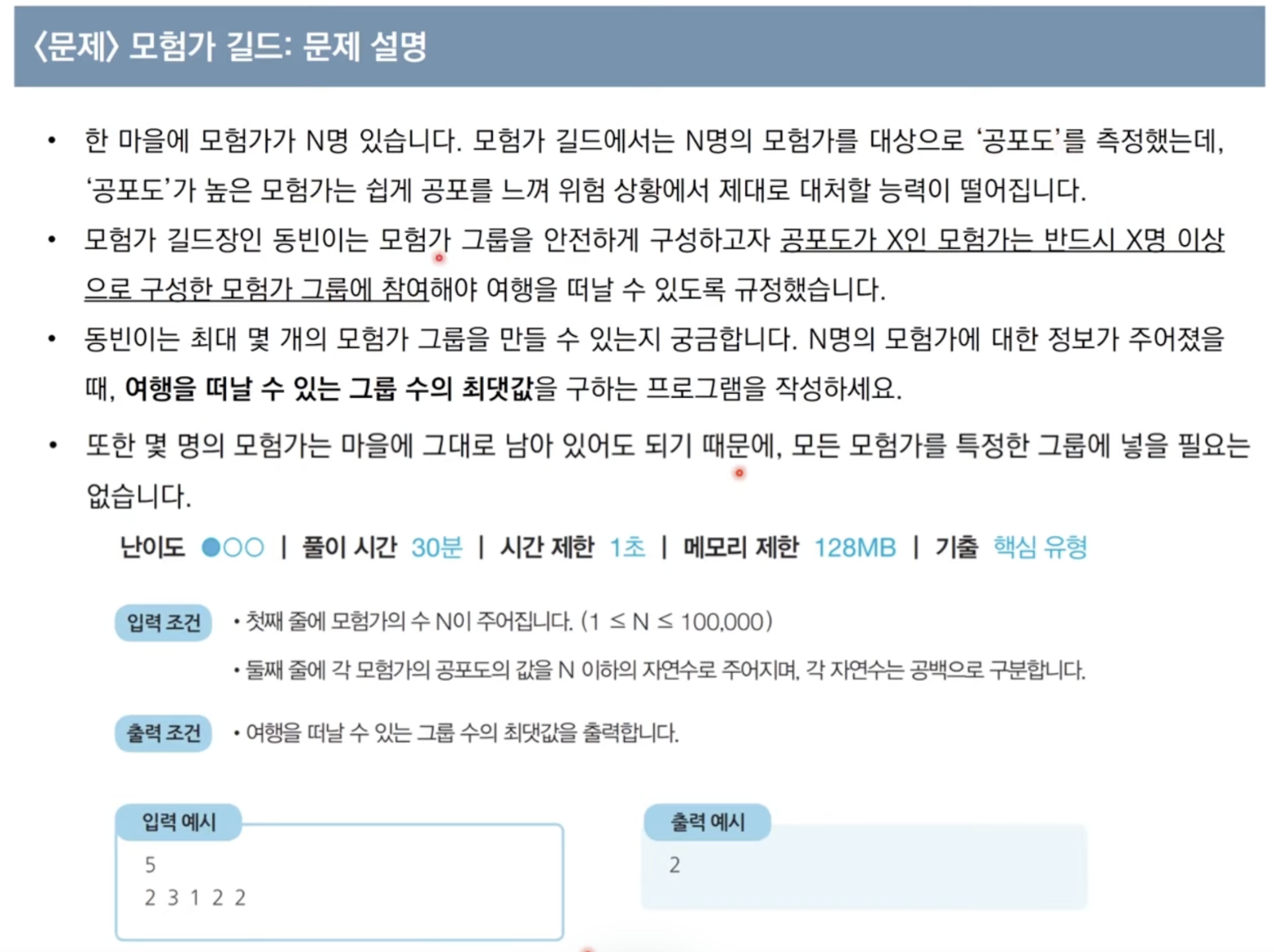
문제 2) 모험가 길드
풀이 코드n = 5 inputStr = "2 3 1 2 2" data = list(map(int, inputStr.split())) data.sort() result = 0 count = 0 # 현재 그룹에 포함된 모험가의 수 for i in data: count += 1 if count >= 1: # 현재 모험가 수 > 공포도일 경우 그룹 생성 result += 1 count = 0 print(result) # 2
구현 (완전 탐색, 브루트포스, 시뮬레이션)
풀이를 구상한 후 그것을 코드로 옮기는 알고리즘 (근데 그게 어려움 🥹)
-
구현 문제 유형 예시
- 알고리즘은 간단하지만 코드가 굉장히 긴 문제 (코드 길이는 라이브러리에 따라 많이 달라서
언어 바이 언어이긴 함) - 실수 연산 & 특정 소수점 자리까지 출력하기 (라이브러리 사용 수준에 따라 난이도 달라짐)
- 문자열을 특정한 기준으로 처리하기 (라이브러리빨.,,)
=> 적절한 라이브러리 학습과 사용이 중요 -> 많이 풀어보깅~
- 알고리즘은 간단하지만 코드가 굉장히 긴 문제 (코드 길이는 라이브러리에 따라 많이 달라서
-
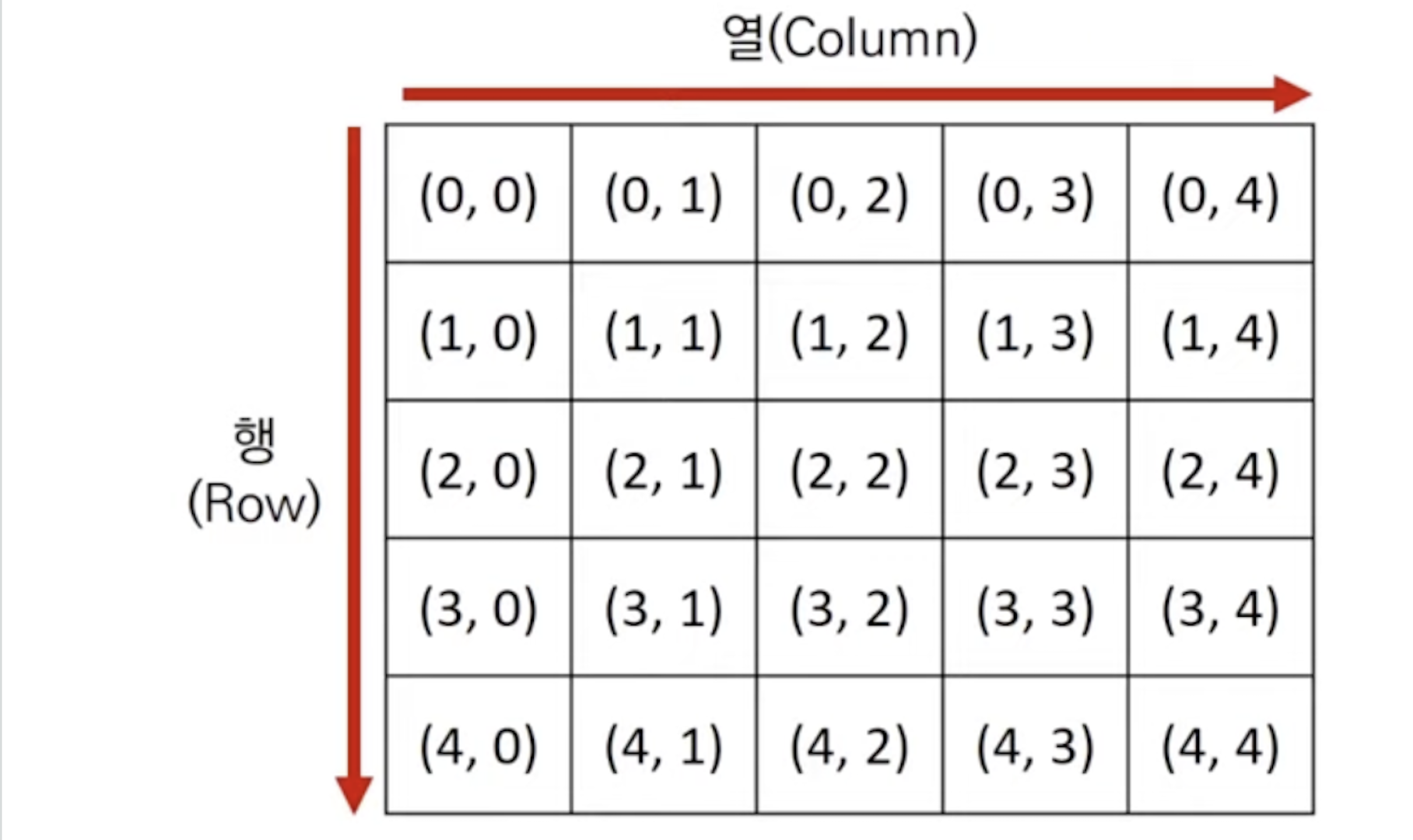
2차원 공간 (행렬), 2차원에서의 방향 벡터(상하좌우)가 자주 활용됨
행렬: 2차원 공간 (2차원 리스트(배열))
- 수와 숫자의 차이
수: 100, 130, 1000 등의 정수숫자:0 - 9사이의 1자릿수 수
구현 예시 문제
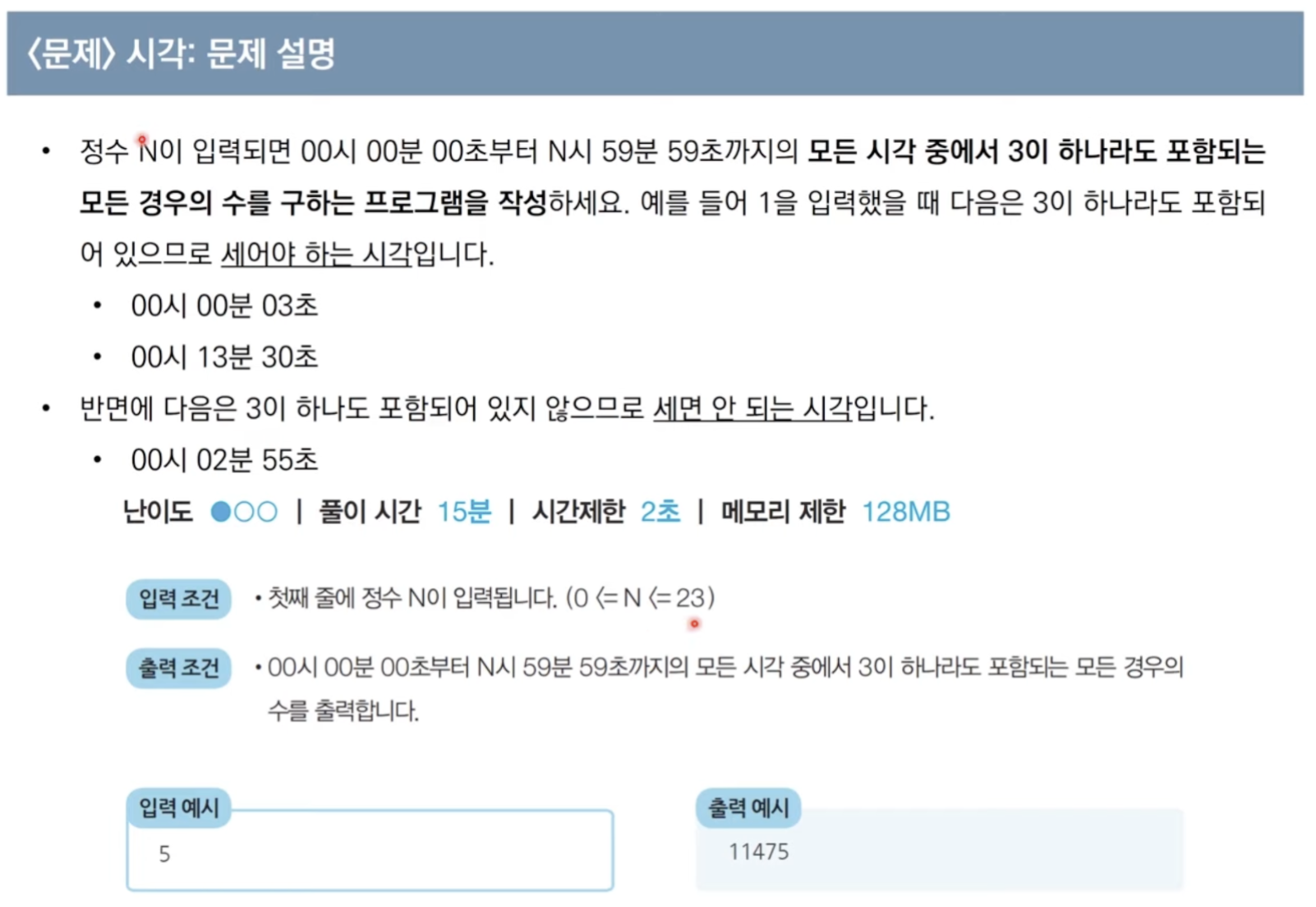
문제 1) 시각
풀이 코드def solution(n, lost, reserve): n = 5 count = 0 if n < 13: hourNum = 1 else: hourNum = 2 count += (15 * 60 * (n + 1)) + (15 * 45 * (n + 1)) + (hourNum * 45 * 45) print(count)나는
초 + 분 + 시의 시간을 각각 계산해 다 더했는데, 그냥 for문으로 초를 1씩 증가시켜가며 비교할 수도 있음(그래봤자 86400번밖에 안 도니까)
BFS / DFS 알고리즘
많은 양의 데이터에서 원하는 데이터를 찾는 탐색 알고리즘 중, 그래프 탐색 알고리즘에 속함
-
스택: [], append(), pop() 이용stack = [] # 스택 선언 stack.append() # 스택 맨 뒤에 값 추가 stack.pop() # 스택 맨 뒷 값 삭제 print(stack) # 넣은 순서대로 출력 (먼저 넣은 값이 먼저 출력됨) print(stack[::-1]) # 뒷 순서부터 거꾸로 출력 (마지막에 넣은 값이 먼저 출력됨) -
큐: import deque 필수, deque(), append(), popleft(), reverse() 이용from collections import deque # 디큐 임포트 필수 queue = deque() # 큐 선언 queue.append() # 큐 맨 뒤에 값 추가 queue.popleft() # 큐 맨 앞 값 삭제 print(queue) # 넣은 순서대로 출력 queue.reverse() # 순서 거꾸로 뒤집기 print(queue) # 나중에 들어온 순서부터 출력 -
재귀 함수(Recursive Function): 자기 자신을 다시 호출하는 함수
-> 파이썬은최대 재귀 깊이가 정해져있기 때문에, 무한 출력 되지 않게 주의해야함 (종료 조건 명시) -
재귀 함수는 반복문으로도 동일한 기능을 구현가능 (반대도 가능)
-> 재귀 함수가 반복문보다 유리한 경우도 있고, 불리한 경우도 있음 -
함수를 연속적으로 호출하면 컴퓨터 메모리 내부의 스택 프레임에 쌓임
-> 스택 구현시 스택 자료구조 대신 재귀 함수를 이용하는 경우가 많음 (ex) DFS)
DFS (Depth-First Search)
깊이 우선 탐색 알고리즘
스택자료구조(혹은재귀 함수) 이용
풀이 방법)- 탐색 시작 노드를 스택에 삽입하고, 방문 처리
2-1. 스택의 최상단 노드에 방문하지 않은 인접한 노드가 하나라도 있으면 그 노드를 스택에 넣고 방문 처리
2-2. 방문하지 않은 인접 노드가 없으면 스택에서 최상단 노드를 꺼냄 - 더 이상 2번의 과정을 수행할 수 없을 때까지 반복
- 탐색 시작 노드를 스택에 삽입하고, 방문 처리
# 각 노드가 연결된 정보를 표현 (2차원 리스트), 노드와 인덱스 값을 맞추기 위해 0번 인덱스는 만들어두고 사용 안 함
graph = [
[],
[2, 3, 8],
[1, 7],
[1, 4, 5],
[3, 5],
[3, 4],
[7],
[2, 6, 8],
[1, 7],
]
# 각 노드가 방문된 정보를 표현 (1차원 리스트), 노드는 8번까지지만 0번 인덱스는 버리니까 9개
visited = [False] * 9
# DFS 메서드 정의
def dfs(graph, v, visited):
# 현재 노드 방문 처리
visited[v] = True
print(v, end=" ")
# 현재 노드와 연결된 다른 노드를 재귀적으로 방문
for i in graph[v]:
if not visited[i]: dfs(graph, i, visited)
# 정의된 DFS 함수 호출
dfs(graph, 1, visited) # 1 2 7 6 8 3 4 5BFS (Breadth-First Search)
너비 우선 탐색 알고리즘 (그래프에서 가까운 노드부터 우선적으로 탐색)
큐자료구조 이용- 특정 조건에서의 최단 경로 찾기에서 사용됨
풀이 방법)- 탐색 시작 노드를 큐에 삽입하고, 방문 처리
- 큐에서 노드를 꺼낸 뒤, 해당 노드의 인접 노드 중 방문하지 않은 노드를 모두 큐에 삽입하고 방문 처리
- 더 이상 2번의 과정을 수행할 수 없을 때까지 반복
# 각 노드가 연결된 정보를 표현 (2차원 리스트), 노드와 인덱스 값을 맞추기 위해 0번 인덱스는 만들어두고 사용 안 함
graph = [
[],
[2, 3, 8],
[1, 7],
[1, 4, 5],
[3, 5],
[3, 4],
[7],
[2, 6, 8],
[1, 7],
]
# 각 노드가 방문된 정보를 표현 (1차원 리스트), 노드는 8번까지지만 0번 인덱스는 버리니까 9개
visited = [False] * 9
from collections import deque
# BFS 메서드 정의
def bfs(graph, start, visited):
# 큐(Queue) 구현을 위해 deque 라이브러리 사용 후, 현재 노드 방문 처리
queue = deque([start])
visited[start] = True
# 큐가 빌 때까지 반복
while queue:
# 큐에서 하나의 원소를 뽑아 출력하기
v = queue.popleft()
print(v, end=" ")
# 아직 방문하지 않은 인접한 원소들을 큐에 삽입
for i in graph[v]:
if not visited[i]:
queue. append (i)
visited[i] = True
# 정의된 BFS 함수 호출
bfs(graph, 1, visited) # 1 2 3 8 7 4 5 6DFS / BFS 예시 문제
문제 1) 음료수 얼려 먹기

풀이 코드
n, m = map(int, input().split())
graph = []
for i in range(n):
graph.append(list(map(int, input().split())))
def dfs(x, y):
if x <= -1 or x >= n or y <= -1 or y >= m: return False
if graph[x][y] == 0:
graph[x][y] = 1
dfs(x - 1, y)
dfs(x + 1, y)
dfs(x, y - 1)
dfs(x, y + 1)
return True
return False
result = 0
for i in range(n):
for j in range(m):
if dfs(i, j) == True: result += 1
print(result)문제 2) 미로 탈출

풀이 코드
from collections import deque
n, m = map(int, input().split())
graph = []
for i in range(n):
graph.append(list(map(int, input().split())))
# 이동할 방향 정의 (상하좌우)
dx = [-1, 1, 0, 0]
dy = [0, 0, -1, 1]
def bfs(x, y):
queue = deque()
queue.append((x, y))
# 큐가 빌 때까지 반복
while queue:
# 맨 앞 요소 하나 꺼내기
x, y = queue.popleft()
# 현재 위치에서 상하좌우로 확인
for i in range(4):
nx = x + dx[i]
ny = y + dy[i]
# 그래프 범위 넘거나, 괴물 있으면 continue
if nx < 0 or nx >= n or ny < 0 or ny >= m: continue
if graph[nx][ny] == 0: continue
# 해당 노드를 처음 방문하는 경우에만 최단 거리 기록
if graph[nx][ny] == 1: # 1 이상일 수도 있음
graph[nx][ny] = graph[x][y] + 1
queue.append((nx, ny))
# 목적지 (n-1, m-1)까지의 거리 반환
return graph[n - 1][m - 1]
print(bfs(0, 0))정렬 알고리즘 (Sorting)
데이터를 특정한 기준에 따라 순서대로 나열하는 알고리즘
- 대부분의 표준 정렬 라이브러리는 최악의 경우에도
O(NlogN)시간복잡도를 보장함
-> 정렬을 구현하라는 거 아니면 라이브러리 이용하깅.,,
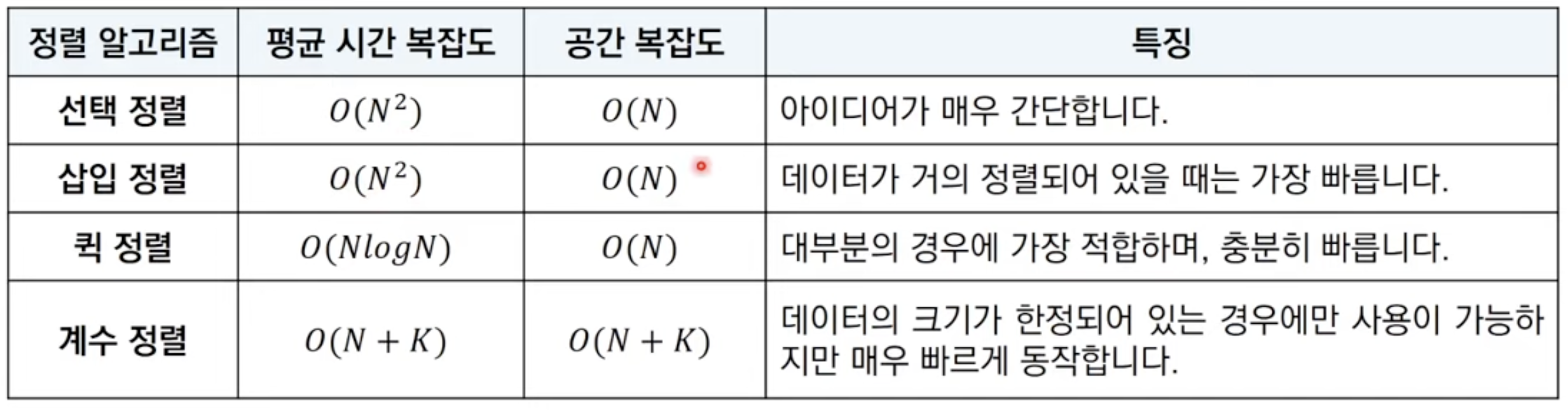
선택 정렬
처리되지 않은 데이터(탐색 범위) 중, 가장 작은 데이터를 선택해 맨 앞 데이터와 바꾸는 것을 반복함
- 선택 정렬의 탐색 범위는 정렬을 수행할 때마다 1개씩 작아지고, 탐색 범위가 마지막 원소가 될 때까지 반복 수행해야함
->O(N^2)의 시간복잡도 소요됨
array = [7, 5, 9, 0, 3, 1, 6, 2, 4, 8]
for i in range(len(array)):
min_index = i # 탐색 범위 중 첫 번째 idx
for j in range(i + 1, len(array)):
if array[min_index] > array[j]:
min_index = j # 더 작은 수 발견하면 그 수 idx로 바꿈
array[i], array[min_index] = array[min_index], array[i] # 서로 값 바꿈 (맨 앞과 제일 작은 수 값 바꾸기) -> 스와프 연산
print(array) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]삽입 정렬
처리되지 않은 데이터를 하나씩 가져다가 적절한 위치에 삽입하는 알고리즘
-> 일반적으로 선택 정렬보다 효율적
- 반복문이 2번 중첩되기 때문에
O(N^2)의 시간복잡도 소요됨
-> 리스트가 거의 정렬되어 있는 상태라면 매우 빠름 (리스트가 이미 정렬된 상태라면O(N)시간복잡도도 가능)
array = [7, 5, 9, 0, 3, 1, 6, 2, 4, 8]
for i in range(1, len(array)): # 0번이 기준점이기 때문에 1부터 시작
for j in range(i, 0, -1): # 인덱스 i부터 1까지 1씩 감소하며 반복
if array[j] < array[j - 1]:
array[j], array[j - 1] = array[j - 1], array[j] # 본인보다 큰 값일 경우 1칸씩 왼쪽으로 이동, 스와프 연산
else: break # 본인보다 작은 값이면 그 위치에서 멈춤
print(array) # [0,1,2,3,4,5,6,7,8,9]퀵 정렬
기준 데이터를 설정한 후, 그 기준보다 큰 데이터와 작은 데이터의 위치를 바꿈
-> 기본적인 퀵 정렬은 첫 번째 데이터를 기준 데이터(pivot)로 설정
- 평균적으로
O(NlogN)의 시간복잡도 가짐 (중앙 분할일 때)
-> 최악의 경우O(N^2)가짐 (중앙 분할이 아닌 한 쪽으로 편향되어있으면... ex) 이미 정렬된 데이터)
# 파이썬의 슬라이싱, 리스트 컴프리헨션을 이용한 퀵 정렬 구현 (! 추천 !)
array = [5, 7, 9, 0, 3, 1, 6, 2, 4, 8]
def quick_sort(array):
if len(array) <= 1: return array # 리스트 속 원소가 1개 이하면 종료
pivot = array[0] # 피벗은 첫 번째 원소
tail = array[1:] # 피벗을 제외한 리스트(0번 원소 제외)
left_side = [x for x in tail if x <= pivot] # 분할된 왼쪽 부분
right_side = [x for x in tail if x > pivot] # 분할된 오른쪽 부분
# 분할 이후 왼쪽 / 오른쪽에서 각각 정렬 수행하고, 전체 리스트 반환
return quick_sort(left_side) + [pivot] + quick_sort(right_side)
print(quick_sort(array)) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# 일반 버전의 퀵 정렬 구현
array = [5, 7, 9, 0, 3, 1, 6, 2, 4, 8]
def quick_sort(array, start, end):
if start >= end: return # 원소가 1개인 경우 종료
pivot = start # 피벗은 첫 번째 원소로 설정
left = start + 1
right = end
while(left <= right): # 엇갈릴 때까지 반복
while(left <= end and array[left] <= array[pivot]): # 피벗보다 큰 데이터를 찾을 때까지 반복
left += 1
while(right > start and array[right] >= array[pivot]): # 피벗보다 작은 데이터를 찾을 때까지 반복
right -= 1
# 엇갈렸다면 작은 데이터와 피벗을 교체 (상대적으로 작은 게 피벗쪽, 큰 게 바깥쪽)
if(left〉 right): array[right], array[pivot] = array[pivot], array[right]
# 엇갈리지 않았다면 작은 데이터와 큰 데이터를 교체
else: array[left], array[right] = array[right], array[left]
# 분할 이후 왼쪽 부분과 오른쪽 부분에서 각각 정렬 수행
quick_sort(array, start, right - 1)
quick_sort(array, right + 1, end)
quick_sort(array, 0, len(array) - 1)
print(array) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]계수 정렬 (Counting Sort)
각각의 데이터가 등장한 횟수를 세는 정렬 알고리즘
-> 매우 빠름(최악의 경우에도 O(N + K) 시간복잡도 & 공간복잡도 보장, N = 데이터 개수, K = 데이터의 최댓값)
-> 특정 조건(데이터의 크기 범위가 제한되어 정수 형태로 표현할 수 있을 때) 성립할 때만 사용 가능
- 동일한 값을 가지는 데이터가 여러 개 등장할 때 효과적
-> 때론 굉장히 비효율적일 수도 있음 (ex) 데이터가 0, 999999일 때)
array = [7, 5, 9, 0, 3, 1, 6, 2, 9, 1, 4, 8, 0, 5, 2] # 모든 원소의 값이 0보다 크거나 같다고 가정
# 모든 범위를 포함하는 리스트 선언(모든 값은 0으로 초기화)
count = [0] * (max(array) + 1)
for i in range(len(array)):
count[array[i]] += 1 # 각 데이터에 해당하는 인덱스의 값 증가
for i in range(len(count)): # 리스트에 기록된 정렬 정보 확인
for j in range(count[i]):
print(i, end=' ') # 0 0 1 1 2 2 3 4 5 5 6 7 8 9 9정렬 예시 문제
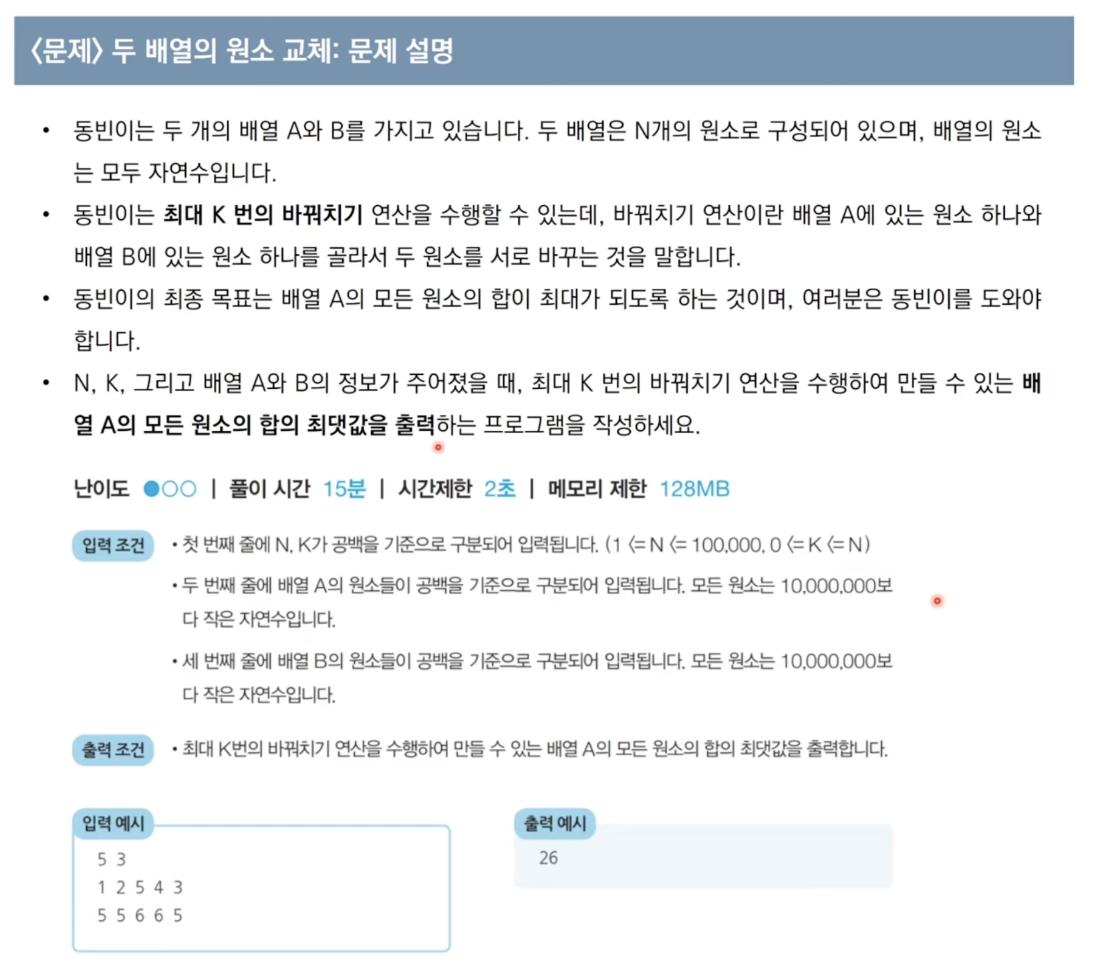
문제 1) 두 배열의 원소 교체
풀이 코드n, k = map(int, input().split()) arrA = list(map(int, input().split)) arrB = list(map(int, input().split)) arrA.sort() arrB.sort() while True: if arrA[k] >= arrB[-k]: k -= 1 else: break arrA = arrA[k:] + arrB[-k:] print(sum(arrA))
이진 탐색 알고리즘
정렬되어 있는 리스트에서 탐색 범위를 절반씩 좁혀가며 목표 값을 찾는 방법
=> 주어진 범위가 크면 이진 탐색을 떠올리기 !!
-> O(logN) 시간복잡도를 가짐
n, target = list(map(int, input().split())) # 10, 7 -> n(원소의 개수)과 target(찾고자 하는 값)
array = list(map(int, input().split())) # 1 3 5 7 9 11 13 15 17 19 -> 전체 원소 입력 받기
# 재귀 함수를 이용한 이진 탐색
def binary_search(array, target, start, end):
if start > end: return None
mid = (start + end) // 2
# 목표값 찾은 경우 중간 인덱스 반환
if array[mid] == target: return mid
# 중간점의 값보다 목표값이 작은 경우 왼쪽 확인
elif array[mid] > target: return binary_search(array, target, start, mid - 1)
# 중간점의 값보다 목표값이 큰 경우 오른쪽 확인
else: return binary_search(array, target, mid + 1, end)
# 이진 탐색 소스코드 구현 (반복문)
def binary_search(array, target, start, end):
while start <= end:
mid = (start + end) // 2
# 목표값 찾은 경우 중간 인덱스 반환
if array[mid] == target: return mid
# 중간점의 값보다 목표값이 작은 경우 왼쪽 확인
elif array[mid] > target: end = mid - 1
# 중간점의 값보다 목표값이 큰 경우 오른쪽 확인
else: start = mid + 1
return None
# 결과
result = binary_search(array, target, 0, n - 1) # 3-
파이썬으로
이진 탐색풀 때 사용하는 라이브러리bisect_left(a, x): 정렬된 순서를 유지하면서 배열에 x를 삽입할 수 있는 가장 첫번째(왼쪽) 인덱스를 반환bisect_right(a, x): 정렬된 순서를 유지하면서 배열에 x를 삽입할 수 있는 가장 마지막(오른쪽) 인덱스를 반환
from bisect import bisect_left, biect_right arr = [1, 2, 4, 4, 8] x = 4 print(bisect_left(arr, x)) # 2 -> 2번 자리에 껴야함([1, 2, ✅ 4, 4, 8]) print(bisect_right(arr, x)) # 4 -> 4번 자리에 껴야함([1, 2, 4, 4, ✅ 8]) --- # 특정 범위 사이에 속하는 데이터 개수 구하기 from bisect import bisect_left, bisect_right def count_by_range(a, left_value, right_value): right_index = bisect_right(a, right_value) left_index = bisect_left(a, left_value) return (right_index - left_index) a= [1, 2, 3, 3, 3, 3, 4, 4, 8, 9] print(Count_by_range(a, 4, 4)) # 2 print(count_by_range(a, -1, 3)) # 6 -
파라메트릭 서치(Parametric Search)
: 최적화 문제(최댓값, 최솟값 찾기 등)를결정 문제(Yes or No)로 바꿔서 해결하는 기법
이진 탐색 예시 문제
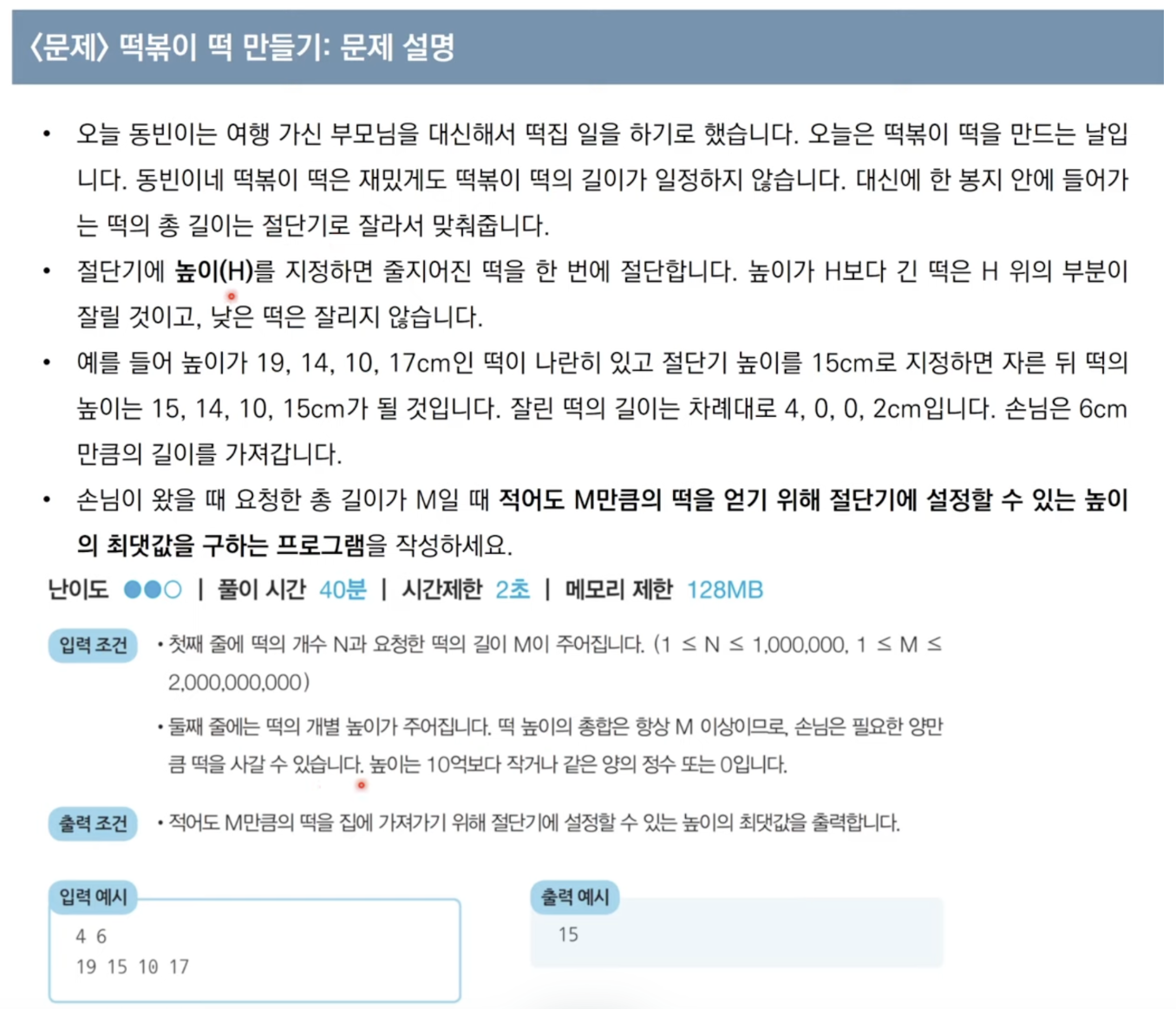
문제 1) 떡볶이 떡 만들기
풀이 코드n, m = map(int, input().split()) tteoks = list(map(int, input().split())) start = 0 end = max(tteoks) result = 0 while start <= end: mid = (start + end) // 2 cutLen = sum([i - mid for i in tteoks if i > mid]) # 자른 떡의 양 if cutLen < m: end -== 1 # 떡이 부족한 경우 else: # 떡의 양이 충분한 경우 result = mid # 최대한 큰 값이 정답이니까 저장 start = mid += 1 print(result)
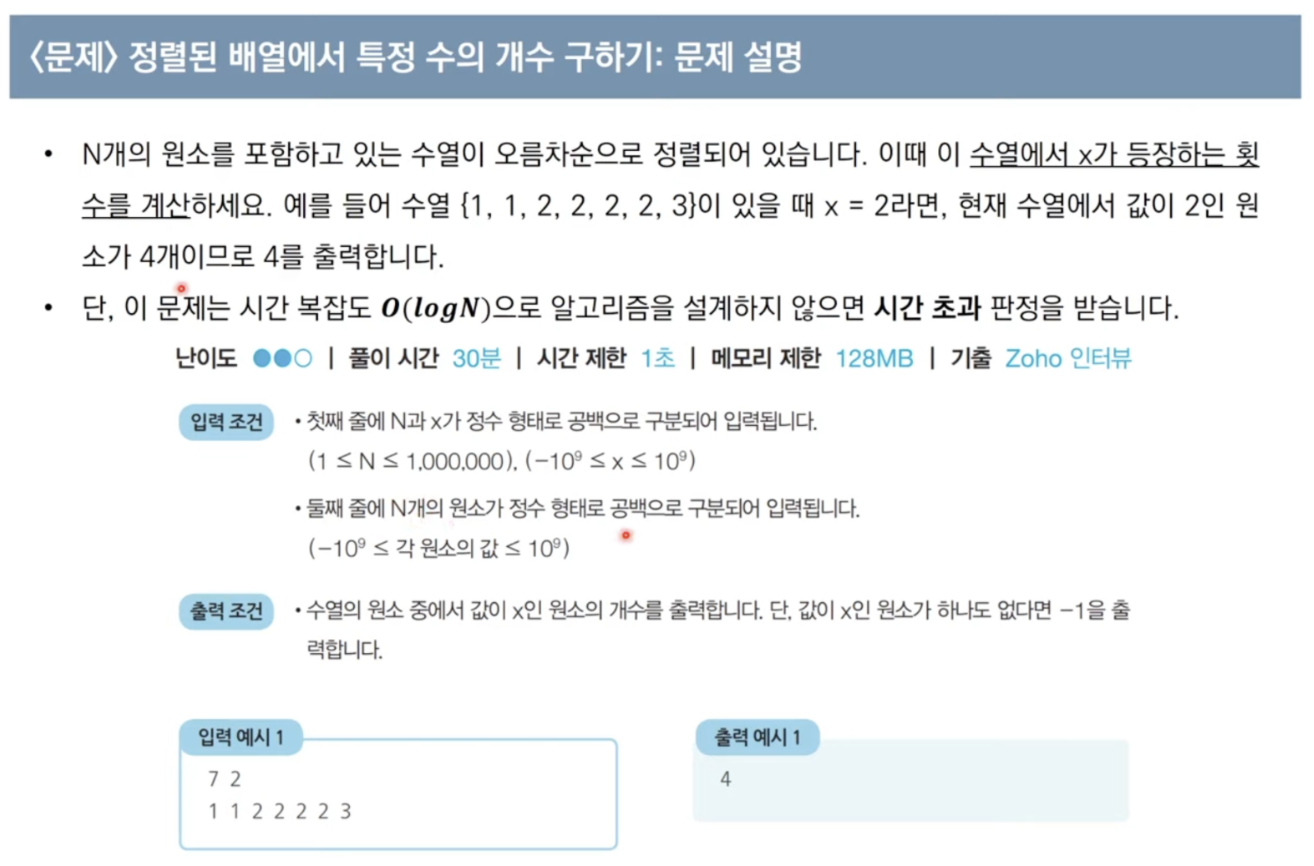
문제 2) 정렬된 배열에서 특정 수의 개수 구하기
풀이 코드n, m = map(int, input().split()) arr = list(map(int, input().split())) startX = bisect_left(arr, 2) endX = bisect_right(arr, 2) count = endX - startX if count == 0: print(-1) else: print(count)
알고리즘
예시 문제
문제 1)
풀이 코드
문제 2)
풀이 코드
