최근 몇 년간 NLP(Natural Language Processing) 분야에서 Transformer 아키텍처 등장 이후 대규모 언어 모델의 발전은 눈부셨는데요, 요즘은 어느 도메인에서나 AI가 대세가 되었습니다. LLM은 범용적으로 활용 가능하지만, 모든 task나 도메인에 최적화되어 있지 않기 때문에 finetuning하여 원하는 task나 도메인에 맞게 최적화 해야합니다. 오늘은 OpenAI의 GPT-3와 유사한 아키텍처를 기반으로 한 EleutherAI의 GPT-Neo 1.3B 모델을 finetuning 해보겠습니다.
token이 없으신 분들은 이 페이지를 참고하세요 (>> Hugging face access token 발급 )
1. Setting
1.1 Hugging face access
# hugging face access token 생성하기
from huggingface_hub import notebook_login
notebook_login()1.2 install libraries
- peft : Parameter-Efficient Fine-Tuning으로, LoRA 등으로 모델을 파인튜닝할때 사용
- trl : Transformers Reinforcement Learning으로, 강화학습으로 파인튜닝할때 사용
- bitsandbytes : quantized weight를 사용하여 추론 속도 향상
!pip3 install -q -U transformers==4.38.0
!pip3 install -q -U datasets==2.17.0
!pip3 install -q -U peft==0.8.2
!pip3 install -q -U trl==0.7.10
!pip install -U bitsandbytes
!pip install -U accelerate1.3 (Optional) BitsAndBytesConfig
사용중인 컴퓨터 자원에 따라 메모리 효율화가 필요할 경우 bitsandbytes 사용해서 4bit 양자화를 설정하여 메모리 사용량을 줄일 수 있습니다.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM,BitsAndBytesConfig
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)2. Train
2.1 Load model and tokenizer
EleutherAI의 GPT계열 모델인 GPT-Neo 모델 로드 및 토크나이저 생성
# 모델 및 토크나이저 불러오기
model_name = "EleutherAI/gpt-neo-1.3B"
tokenizer = AutoTokenizer.from_pretrained(model_name, add_eos_token=True)
model = AutoModelForCausalLM.from_pretrained(model_name,device_map={"":0})2.2 Pre-trained model Inference
프롬프트를 생성하고, input tokeinizing 및 output generation, decoding 과정을 함수화해서 만들어놓습니다.
Finetuning을 하기 전, 함수를 호출하여 Pre-trained model의 생성 능력을 확인합니다
def get_completion(query: str, model, tokenizer) -> str:
device = "cuda:0"
# 프롬프트 템플릿
prompt_template = tokenizer.eos_token + """
user
다음 질문에 어울리는 음식을 추천해주세요.
{query}
\nmodel"""
# 프롬프트 생성
prompt = prompt_template.format(query=query)
# 입력 데이터 토크나이징
encodeds = tokenizer(query, return_tensors="pt", add_special_tokens=True)
model_inputs = encodeds.to(device)
# 응답 생성
generated_ids = model.generate(
**model_inputs,
max_new_tokens=128,
do_sample=True,
top_k=50,
top_p=0.9,
temperature=0.7,
pad_token_id=tokenizer.eos_token_id
)
# 생성된 텍스트 디코딩 및 후처리
decoded = tokenizer.decode(generated_ids[0], skip_special_tokens=True, errors="ignore")
#output = decoded[len(prompt):].strip()
return decoded
# 함수 호출
response = get_completion(query="크리스마스에 먹기 좋은 음식을 추천해줘", model=model, tokenizer=tokenizer)
print("Response:", response)Finetuning 전에는 크리스마스에 먹기 좋은 음식을 추천해달라는 문장에 대해 문맥에 맞지 않는 응답을 보입니다.
output>>
Response: 크리스마스에 먹기 좋은 음식을 추천해줘야 한다.
그는 음식으로 활동을 위해 모두 자유를 받아올게 하고 있었다.
그는 지금까지 공유해서 공유하고 2.3 Dataset
원하는 목적에 맞는 데이터를 학습시켜 줍니다. 저는 GPU 자원의 한계로 인해 간단한 샘플 데이터를 생성해서 작은 데이터셋으로 finetuning 했습니다.
from datasets import Dataset
dataset = Dataset.from_dict({
"instruction": [
"다음 질문에 어울리는 음식을 추천해주세요",
"다음 질문에 어울리는 음식을 추천해주세요",
"다음 질문에 어울리는 음식을 추천해주세요",
"다음 질문에 어울리는 음식을 추천해주세요",
"다음 질문에 어울리는 음식을 추천해주세요"
],
"input": [
"크리스마스에 먹기 좋은 음식은 무엇인가요?",
"크리스마스에 어울리는 특별한 디저트를 추천해 주세요.",
"크리스마스 파티에서 즐길만한 음식과 음료를 추천해 주세요.",
"크리스마스 아침에 어울리는 브런치를 추천해 주세요.",
"크리스마스 저녁을 위한 간단하면서도 특별한 요리를 추천해 주세요."
],
"output": [
"크리스마스에는 칠면조 요리, 글레이즈드 햄, 로스트 치킨 같은 전통적인 요리를 추천합니다. 디저트로는 진저브레드 쿠키나 크리스마스 푸딩이 잘 어울립니다.",
"크리스마스 디저트로는 딸기 생크림 케이크, 민스파이, 그리고 초콜릿 퐁당 같은 달콤한 디저트를 추천드립니다. 크리스마스 분위기를 더해줄 거예요!",
"크리스마스 파티 음식으로는 치즈 플래터, 미니 파이, 그리고 스파게티 같은 간편한 음식을 추천합니다. 음료로는 핫 초콜릿과 에그노그가 잘 어울립니다.",
"크리스마스 아침 브런치로는 에그 베네딕트, 팬케이크, 그리고 베이글과 크림치즈를 추천합니다. 따뜻한 커피와 함께 즐기면 더 좋습니다.",
"크리스마스 저녁 요리로는 크림 스프와 스테이크를 간단히 준비하실 수 있습니다. 곁들여 샐러드와 바게트를 준비하면 완벽한 한 끼가 될 거예요."
]
})
2.4 Generate prompt
모델이 지정된 출력을 제공할 수 있게 하고, 'prompt' 컬럼을 추가하여 text_column값을 추가합니다.
def generate_prompt(data_point):
prefix_text = '"다음 질문에 어울리는 음식을 추천해주세요 \n\n\"'
# input 변수에 값이 들어 있는 샘플
if data_point['input']:
text = f"""user {prefix_text} {data_point["instruction"]} 입력 테스트: {data_point["input"]}
\nmodel{data_point["output"]} """
# input 변숫값이 결측값인 샘플
else:
text = f"""user {prefix_text} {data_point["instruction"]}
\nmodel{data_point["output"]} """
return text
# 데이터셋에 prompt 컬럼 추가
text_column = [generate_prompt(data_point) for data_point in dataset]
dataset = dataset.add_column("prompt", text_column)
dataset["prompt"]output>>
['user "다음 질문에 어울리는 음식을 추천해주세요 \n\n" 다음 질문에 어울리는 음식을 추천해주세요 입력 테스트: 크리스마스에 먹기 좋은 음식은 무엇인가요?\n \nmodel크리스마스에는 칠면조 요리, 글레이즈드 햄, 로스트 치킨 같은 전통적인 요리를 추천합니다. 디저트로는 진저브레드 쿠키나 크리스마스 푸딩이 잘 어울립니다. ',
'user "다음 질문에 어울리는 음식을 추천해주세요 \n\n" 다음 질문에 어울리는 음식을 추천해주세요 입력 테스트: 크리스마스에 어울리는 특별한 디저트를 추천해 주세요.\n \nmodel크리스마스 디저트로는 딸기 생크림 케이크, 민스파이, 그리고 초콜릿 퐁당 같은 달콤한 디저트를 추천드립니다. 크리스마스 분위기를 더해줄 거예요! ',
'user "다음 질문에 어울리는 음식을 추천해주세요 \n\n" 다음 질문에 어울리는 음식을 추천해주세요 입력 테스트: 크리스마스 파티에서 즐길만한 음식과 음료를 추천해 주세요.\n \nmodel크리스마스 파티 음식으로는 치즈 플래터, 미니 파이, 그리고 스파게티 같은 간편한 음식을 추천합니다. 음료로는 핫 초콜릿과 에그노그가 잘 어울립니다. ',
'user "다음 질문에 어울리는 음식을 추천해주세요 \n\n" 다음 질문에 어울리는 음식을 추천해주세요 입력 테스트: 크리스마스 아침에 어울리는 브런치를 추천해 주세요.\n \nmodel크리스마스 아침 브런치로는 에그 베네딕트, 팬케이크, 그리고 베이글과 크림치즈를 추천합니다. 따뜻한 커피와 함께 즐기면 더 좋습니다. ',
'user "다음 질문에 어울리는 음식을 추천해주세요 \n\n" 다음 질문에 어울리는 음식을 추천해주세요 입력 테스트: 크리스마스 저녁을 위한 간단하면서도 특별한 요리를 추천해 주세요.\n \nmodel크리스마스 저녁 요리로는 크림 스프와 스테이크를 간단히 준비하실 수 있습니다. 곁들여 샐러드와 바게트를 준비하면 완벽한 한 끼가 될 거예요. ']2.5 Train test split
입력 데이터에 대한 tokenize를 적용하고 5:5로 train test를 split 합니다.
# 데이터셋 셔플
dataset = dataset.shuffle()
# 토크나이저로 인코딩
dataset = dataset.map(lambda samples: tokenizer(samples["prompt"]),
batched=True)
# 데이터 분할
dataset = dataset.train_test_split(test_size=0.5)
train_data = dataset["train"]
test_data = dataset["test"]
print(train_data)
print(test_data)output>>
Dataset({
features: ['instruction', 'input', 'output', 'prompt', 'input_ids', 'attention_mask'],
num_rows: 2
})
Dataset({
features: ['instruction', 'input', 'output', 'prompt', 'input_ids', 'attention_mask'],
num_rows: 3
})2.6 peft 설정
parameter efficient finetuning을 위해 peft 모듈(LoRA 등) 임포트 및 그래디언트 체크포인팅 활성화(메모리 효율화), prepare_model_for_kbit_training을 통한 양자화 최적화(메모리 최적화)를 적용합니다.
from peft import LoraConfig, PeftModel, prepare_model_for_kbit_training, get_peft_model
model.gradient_checkpointing_enable()
model = prepare_model_for_kbit_training(model)
print(model)모델 구조
GPTNeoForCausalLM(
(transformer): GPTNeoModel(
(wte): Embedding(50257, 2048)
(wpe): Embedding(2048, 2048)
(drop): Dropout(p=0.0, inplace=False)
(h): ModuleList(
(0-23): 24 x GPTNeoBlock(
(ln_1): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(attn): GPTNeoAttention(
(attention): GPTNeoSelfAttention(
(attn_dropout): Dropout(p=0.0, inplace=False)
(resid_dropout): Dropout(p=0.0, inplace=False)
(k_proj): Linear(in_features=2048, out_features=2048, bias=False)
(v_proj): Linear(in_features=2048, out_features=2048, bias=False)
(q_proj): Linear(in_features=2048, out_features=2048, bias=False)
(out_proj): Linear(in_features=2048, out_features=2048, bias=True)
)
)
(ln_2): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(mlp): GPTNeoMLP(
(c_fc): Linear(in_features=2048, out_features=8192, bias=True)
(c_proj): Linear(in_features=8192, out_features=2048, bias=True)
(act): NewGELUActivation()
(dropout): Dropout(p=0.0, inplace=False)
)
)
)
(ln_f): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
)
(lm_head): Linear(in_features=2048, out_features=50257, bias=False)
)2.7 LoRA 적용 및 Train
LoRA 적용을 위해 모델에서 선형 레이어(torch.nn.Linear)를 탐색하고, 해당 레이어의 이름을 반환하여 이를 기반으로 학습 대상 레이어를 설정
def find_all_linear_names(model):
lora_module_names = set()
for name, module in model.named_modules():
if isinstance(module, torch.nn.Linear): # Linear 레이어 탐색
names = name.split('.')
lora_module_names.add(names[-1]) # 마지막 이름만 추가
return list(lora_module_names)
# LoRA 대상 모듈 찾기
target_modules = find_all_linear_names(model)
print("LoRA 대상 모듈:", target_modules) LoRA 대상 모듈: ['q_proj', 'out_proj', 'k_proj', 'v_proj', 'lm_head', 'c_proj', 'c_fc']from peft import LoraConfig, get_peft_model
# LoRA Config 정의
lora_config = LoraConfig(
r=8, # LoRA 랭크 값
lora_alpha=32, # Scaling Factor
target_modules=target_modules, # LoRA 적용 대상 모듈
lora_dropout=0.1, # 드롭아웃 비율
bias="none", # Bias 적용 여부
task_type="CAUSAL_LM" # 작업 유형: Causal Language Modeling
)
# LoRA 모델 적용
model = get_peft_model(model, lora_config)
# 모델 구조 출력 (디버깅용)
print(model)
# 학습 가능한 파라미터 개수 확인
def get_trainable_parameters(model):
trainable = sum(p.numel() for p in model.parameters() if p.requires_grad)
total = sum(p.numel() for p in model.parameters())
return trainable, total
trainable, total = get_trainable_parameters(model)
print(f"Trainable: {trainable} | Total: {total} | Percentage: {trainable / total * 100:.4f}%")전체에서 약 0.5%의 가중치만 업데이트하면 파인튜닝이 달성됨
PeftModelForCausalLM(
(base_model): LoraModel(
(model): GPTNeoForCausalLM(
(transformer): GPTNeoModel(
(wte): Embedding(50257, 2048)
(wpe): Embedding(2048, 2048)
(drop): Dropout(p=0.0, inplace=False)
(h): ModuleList(
(0-23): 24 x GPTNeoBlock(
(ln_1): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(attn): GPTNeoAttention(
(attention): GPTNeoSelfAttention(
(attn_dropout): Dropout(p=0.0, inplace=False)
(resid_dropout): Dropout(p=0.0, inplace=False)
(k_proj): lora.Linear(
(base_layer): Linear(in_features=2048, out_features=2048, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=2048, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=2048, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(v_proj): lora.Linear(
(base_layer): Linear(in_features=2048, out_features=2048, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=2048, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=2048, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(q_proj): lora.Linear(
(base_layer): Linear(in_features=2048, out_features=2048, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=2048, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=2048, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(out_proj): lora.Linear(
(base_layer): Linear(in_features=2048, out_features=2048, bias=True)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=2048, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=2048, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
)
)
(ln_2): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(mlp): GPTNeoMLP(
(c_fc): lora.Linear(
(base_layer): Linear(in_features=2048, out_features=8192, bias=True)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=2048, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=8192, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(c_proj): lora.Linear(
(base_layer): Linear(in_features=8192, out_features=2048, bias=True)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=8192, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=2048, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(act): NewGELUActivation()
(dropout): Dropout(p=0.0, inplace=False)
)
)
)
(ln_f): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
)
(lm_head): lora.Linear(
(base_layer): Linear(in_features=2048, out_features=50257, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=2048, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=50257, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
)
)
)
Trainable: 7496328 | Total: 1323072136 | Percentage: 0.5666%SFTTrainer를 불러와서 모델을 학습시킬 수 있게 클래스를 정의하고 학습 수행
# SFTTrainer 사용
import transformers
from trl import SFTTrainer
tokenizer.pad_token = tokenizer.eos_token
torch.cuda.empty_cache()
trainer = SFTTrainer(
model=model,
train_dataset=train_data,
eval_dataset=test_data,
dataset_text_field="prompt",
peft_config=lora_config,
args=transformers.TrainingArguments(
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
warmup_steps=0.03,
max_steps=50,
learning_rate=2e-4,
logging_steps=1,
output_dir="outputs",
optim="paged_adamw_8bit",
save_strategy="epoch"
),
data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False),
)trainer.train()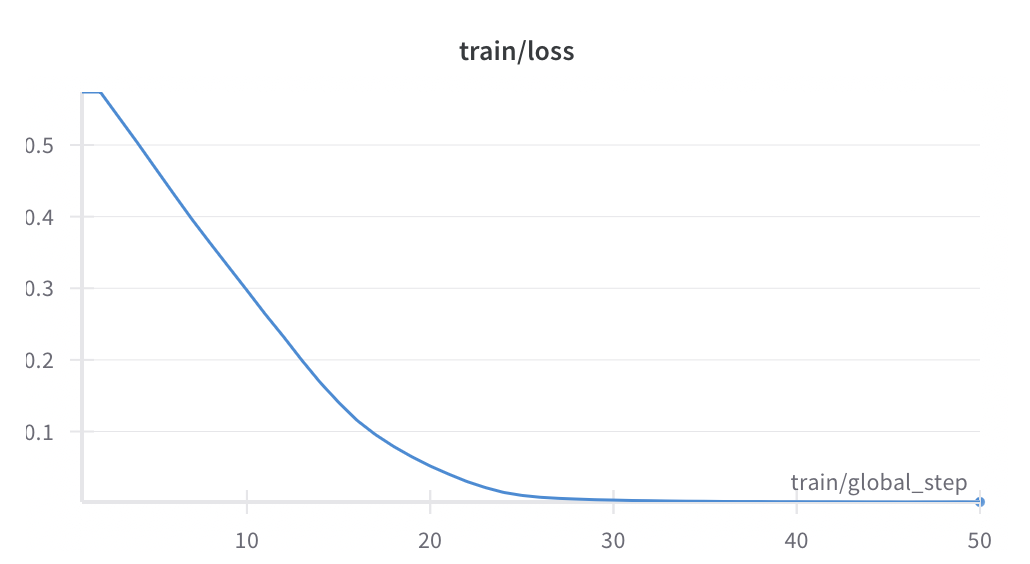 Fine-tuning Training loss
Fine-tuning Training loss
3.Evalutation
3.1 Save model
fine-tuned model을 'gpt-neo-kr'이라는 이름으로 지정하고 new_model에 저장하고, merged_model에 new_model과 base_model을 결합합니다.
LoRA는 pre-trained model에 저차원의 행렬을 추가해서 효율적으로 모델을 업데이트하는데 base_model과 new_model을 결합해야 추론 속도, 모델 성능을 동시에 개선하고 모델의 표현력을 높일 수 있습니다.
new_model = "gpt-neo-ko"
trainer.model.save_pretrained(new_model)
base_model = AutoModelForCausalLM.from_pretrained(
model_name,
low_cpu_mem_usage=True,
return_dict=True,
torch_dtype=torch.float16,
device_map={"": 0},
)
merged_model= PeftModel.from_pretrained(base_model, new_model)
merged_model= merged_model.merge_and_unload()
# merged model 저장
merged_model.save_pretrained("merged_model",safe_serialization=True)3.2 Test
pre-trained 모델은 문맥에 맞지 않는 문장을 생성한 반면 fine-tuning 후에는 원하는 대답을 생성하는 것을 확인할 수 있습니다.
result = get_completion(query="크리스마스에 먹기 좋은 음식은 무엇인가요?", model=merged_model, tokenizer=tokenizer)
print(result)크리스마스에 먹기 좋은 음식은 무엇인가요?
model 음식은 칠면조 요리, 파이, 음식 같은 전통적인 요리를 추천합니다. 음식 테스트 크리스마스에는 칠면조 요