git hub 몇 가지 기능
TCP/UDP
프로그래머스공부하며 느낀 점
참조한 페이지
git hub 몇 가지 기능과 팁
1. PR 후 브랜치 자동 삭제
깃 허브 원격 저장소 - 세팅 - Automatically delete head branches 를 체크하면 PR 이후에 자동으로 브랜치를 삭제해준다.
2. 깃 오거니제이션 git organization
개인 원격 저장소를 다른 유저와 공유하는 것과 큰 차이는 없지만, 권한을 좀 더 조직적으로 관리할 수 있다는 것이 차이이다.
오거니제이션에 유저들을 초대하고, 초대한 유저들을 팀으로 묶고 팀 단위로 각각의 저장소에 초대하고 다른 권한을 줄 수 있다.
3. git hub의 머지방식
PR을 받는 세가지 방식이 있다.
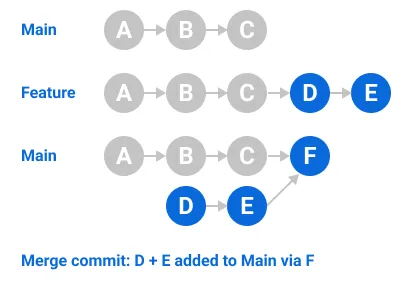
- Merge : 기본적인 방식이다.
모든 커밋 내용을 받아들인다. 쓰기 Write 권한이 있어야한다.
병합 된 브랜치는 두개의 부모 Parent 를 가진다.
$ git checkout master
$ git merge my-branch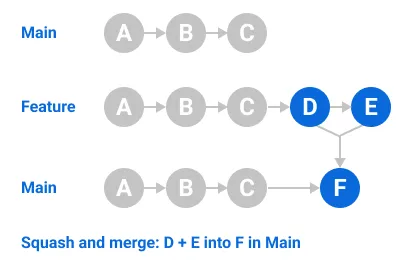
- Squash and Merge :
커밋을 모두 주는 것이 아니라 하나로 합쳐서 주는 방식이다.
부모 커밋을 받은 쪽만 부모가 된다.
$ git checkout master
$ git merge --squash my-branch
$ git commit -m "your-commit-message"- Rebase and merge :
브랜치가 나뉘기 전으로 되돌린뒤, 병합할 브랜치의 커밋을 가장 마지막에 추가해서 마치 처음부터 하나의 브랜치였던 것처럼 만든다.
$ git checkout my-branch
$ git rebase master
$ git checkout master
$ git merge my-branch4. 브랜치 명은 멤버가 아니라 기능으로 짓자
하나의 원격 저장소 Repository 에 여러 브랜치를 만드는 이유는 기능별로 개발한 다음에 합치기 위함이기 때문에, 만드는 팀원의 이름이 아니라 만들고 있는 기능이 중심이되어야한다.
5. nest
백엔드에서 계층 구조 Layered Architecture 를 만들 때 계층별로 한 폴더에 넣는 것이 아니라, 기능별로 한 폴더에 넣는 것이라고 한다.
TCP/UDP
내가 알고 있는 것
TCP : 데이터의 송수신간에 무결성을 보장한다. 느리다.
UDP : 데이터가 패킷단위로 별개로 전송된다. 전송만 하기 때문에 무결성이 보장되지 않지만 빠르다.
조사하여 정리한 것
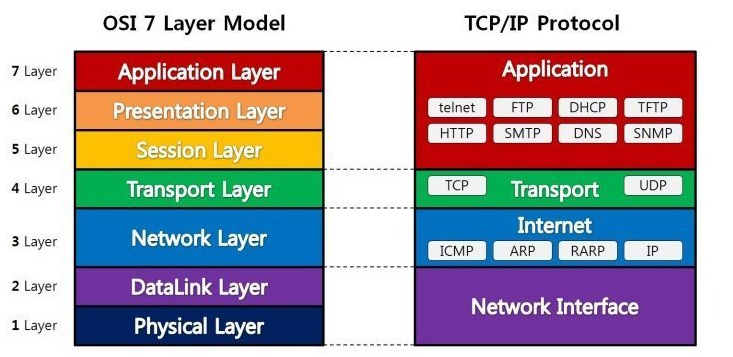
* 공통점 :
1. TCP/IP 계층의 통신 계층에 존재한다.
2. 포트 번호를 이용하여 주소를 지정한다.
3. 헤더에 데이터 오류 검사를 위한 체크섬이 존재한다. (크기 16 bits)
*차이점 -
코드블럭 : TCP
기울이기 : UDP
-
연결방식
.연결 지향 프로토콜 : 클라이언트와 서버가 연결 된 상태에서 데이터를 주고받는다.
.가상 회선 방식 : 발신자와 수신자를 연결하여, 패킷을 전송하기 위한 논리적 경로를 배정한다.
. 비연결 프로토콜 : 각각의 패킷이 논리 경로 없이 독립적으로 전송된다. -
스트림 연결
.바이트 스트림 연결
. 메세지 스트림 연결 -
제어방식
.흐름제어 : 데이터 처리 속도를 조절하여, 수신자의 버퍼 오버플로우 방지, 수신자가 윈도우 크기 window size 로 정할 수 있다.
.혼잡제어 : 네트워크 내의 패킷 수가 넘치지 않도록 방지
. 흐름/혼잡 제어 미지원 -
신뢰성과 속도
.ACK를 연속으로 보내며 중복되거나, 일정시간동안 수신아 안될 경우 재전송을 요청한다. 신뢰성이 높지만, 느리다.
. 데이터의 수신여부를 확인하지 않는다. 빠르지만, 신뢰성이 낮다. -
통신방식
.1:1 방식
. 1:1 , 1:N , N:N 방식 모두 가능하다. -
사용처
.HTTP, Email, 파일 전송 등 신뢰성이 중요한 작업에 사용된다.
. DNS, streaming 과 같은 속도가 중요한 작업에 사용된다.
ACK 란?
TCP 통신에서 패킷의 도착 여부를 알기위한 번호
SEQuence number 에 데이터의 크기(Byte)를 더한 값이다.
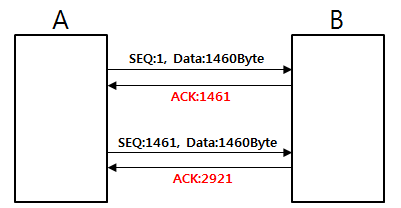
송신측에서 SEQ가 1에 데이터 크기가 1460 Byte 인 패킷을 보냈다면,
수신측에서는 1+1460 = 1461 인 ACK 를 보낸다.
이제 송신측에서는 받은 ACK 값인 1461 을 SEQ로 가지는 패킷을 보내고,
수신측 역시 SEQ 가 1461 에 데이터 크키가 1460 Byte 인 패킷을 받았으므로,
1461 + 1460 = 2921 의 값을 가지는 ACKnowledgement 를 보낸다.
위의 그림에서는 A 와 B의 데이터 전송이 일방적이지만 실제로는 쌍방향이라고한다.
프로그래머스
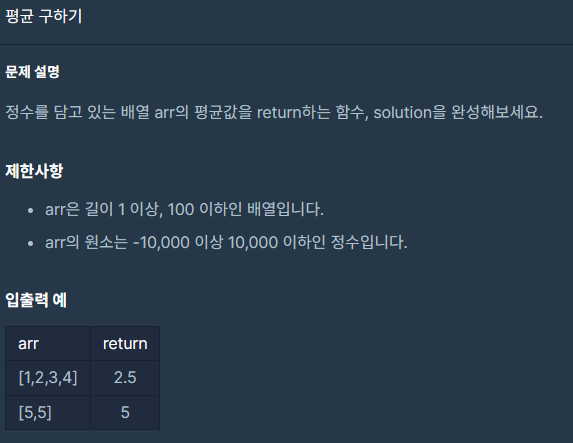
그냥 for문으로 구현하면 가독성이 좋게 나올 것같다.
나의 풀이
function solution(arr) {
var answer = 0;
const loop = arr.length
for (let i = 0 ; i < loop ; i++){
answer += arr[i]
}
answer /= loop
return answer;
}그냥 무난하다 다른사람도 이렇게 만들었을 것같다.
다른 사람의 풀이1
function average(array){
var sum = 0;
//함수를 완성하세요
for(var info of array){
sum += info;
}
return sum/array.length;
}정말로 나와 다를게 없다.
다른 사람의 풀이2
function average(array){
return array.reduce((a,b) => a+b) / array.length;
}효과적으로 보인다. 하지만 매 반복마다 나누기가 있어서 처리할 양이 많으면 느려질것같다. 내 코드랑 하나로 합쳐보자.
키메라 풀이
우선 위의 세 풀이의 평균 속도를 보자
나의 풀이 : 0.041875 ms
다른풀이1 : 0.114375 ms
다른풀이2 : 0.0425 ms
오잉... 내 풀이와 다른사람 1은 거의 똑같은데 속도차이가 거의 2.5배가 난다?...
for 문안에 var ~ of ~ 를 넣는게 ~ ; ~ ; ~ 를 넣는거보다 비효율적인가?...
일단 키메라로 만들어보자...
function solution(arr) {
const length = arr.length
answer = arr.reduce((a,b) => a+b)
return answer/length
}키메라 : 0.5125 ms
오히려 더느려졌으므로 reduce를 쓰는것보다는 for문을 쓰는게 나은것같다.
특이한 점으로는 매 계산마다 나누는것보다는 마지막 한번만 나누는게 더 빠를것 같았는데, 실제로는 그렇지 않았다는 것이다.
공부하며 느낀 점
- 오늘은 플랫폼 개발은 거의 하지 못했다. 대신에 평소에 github를 잘못 쓰던 점을 발견해서 정리하고 고칠 수 있었다.
- 코드가 간결하거나 반복에서 단계를 하나 제거한다고 무조건 더 빨라지지는 않는 다는 것을 배웠다.
참조한 페이지
Managing the automatic deletion of branches
[GitHub] GitHub PR(Pull Request) 머지 후에 브랜치 자동 삭제하기
GitHub에서 협업 용 단체(Organization) 만드는 방법
[GitHub] Organization Team 관리
About pull request merges
[Git] Merge 종류
3.6 Git 브랜치 - Rebase 하기
TCP 와 UDP 차이를 자세히 알아보자
TCP와 UDP의 특징 및 차이점 알아보기
[Network] TCP와 UDP의 특징과 차이점
[TCP/UDP] TCP와 UDP의 특징과 차이
[패킷분석] TCP 통신에서 ACK ?
[네트워크] TCP
