문제

분석
- 공백을 기준으로 문자열을 나누고
- 첫 글자가 알파벳인 경우 대문자로
- 나머지 글자가 알파벳인 경우 소문자로
- 공백을 넣으면서 합치기
위의 네가지 동작을 하면될것같다
풀이 과정
일단 제대로 잘리는가?
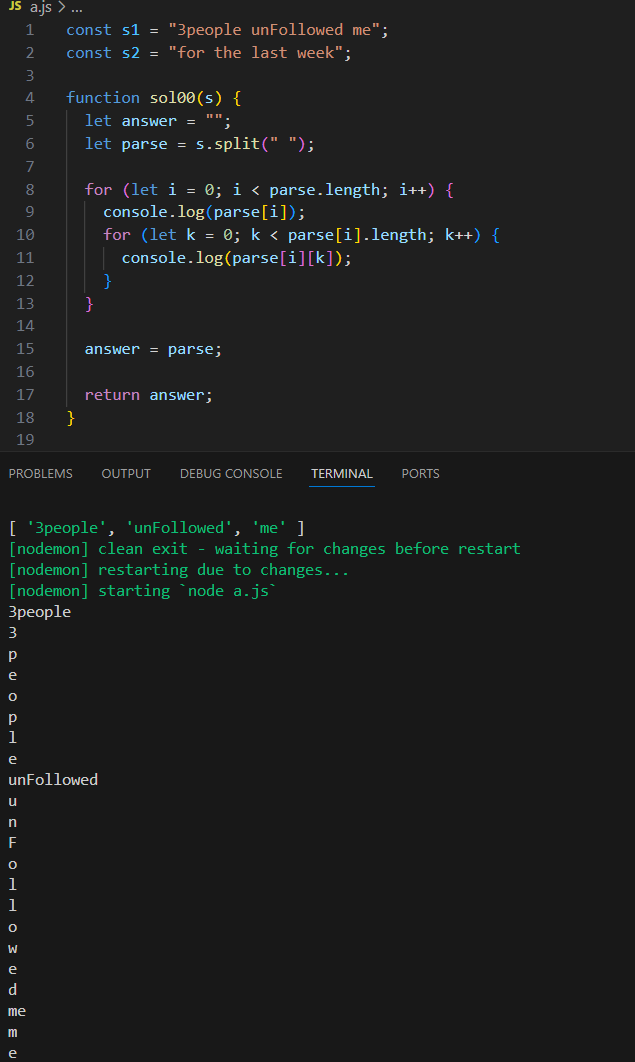
내가 생각한대로 잘 나온다.
이제 parse[i][k]가 유니코드상에서 알파벳 소문자/대문자/숫자인지만 파악하면 될것같다.
유니코드를 변경하자

????
이제보니 안바꾼경우에는 넣지를 않고 있었다.
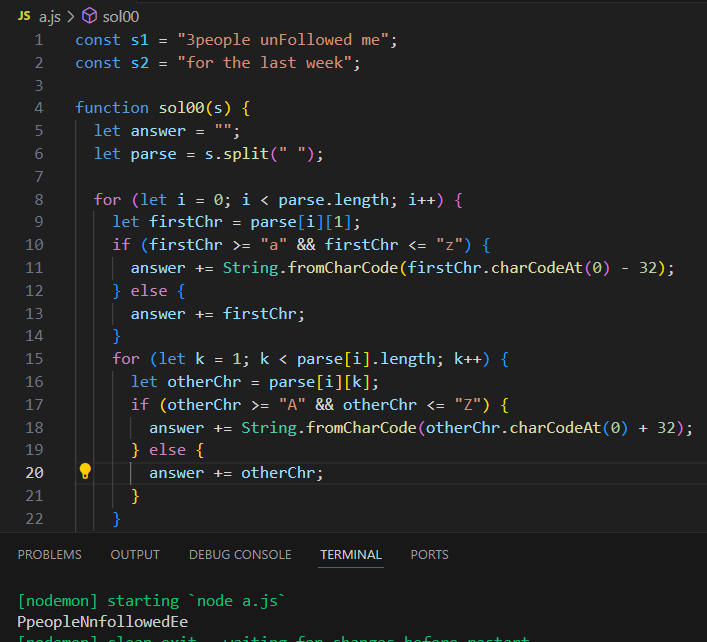
이제 띄워쓰기만 추가하면된다
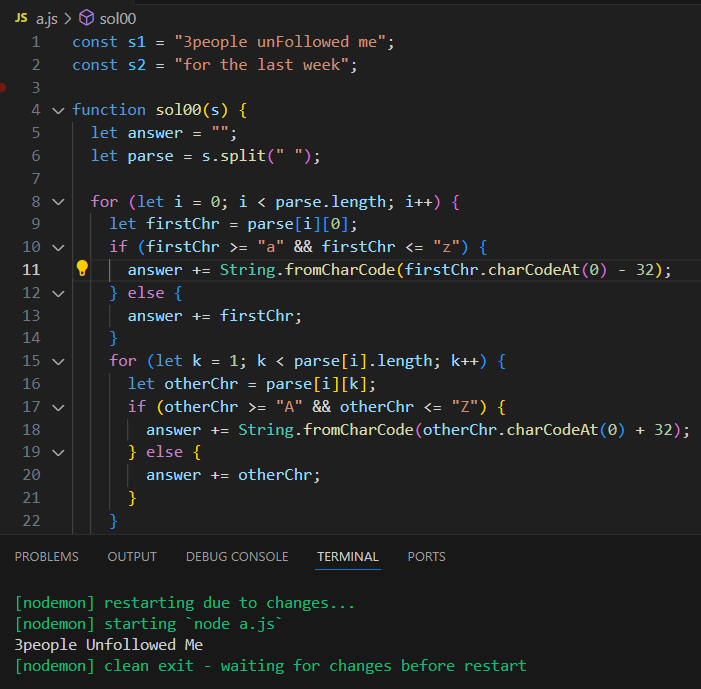
약간의 오류를 수정하니 완료되었다.
Parse를 하지 않는 버전
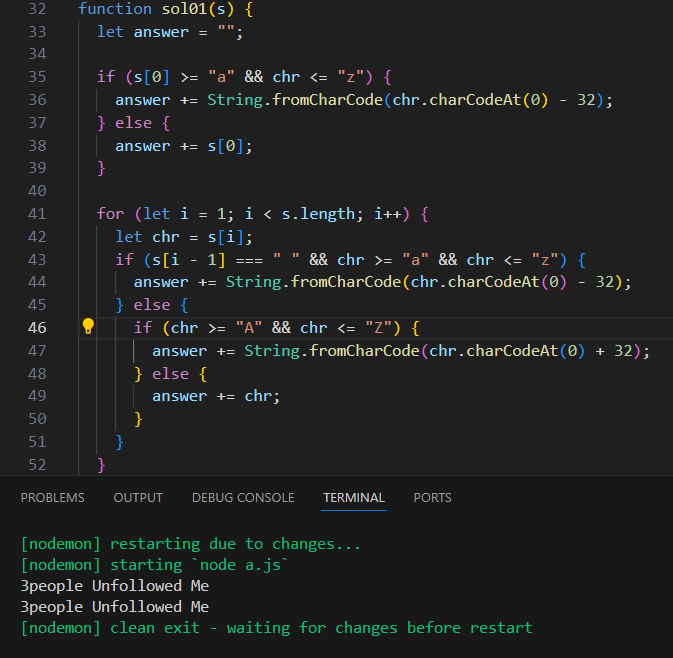
parseInt가 없으니 더 빠를 것 같다
뭐가 문젠데...

사실 upper/lowerCase가 생각 안나서 유니코드로 변환한거긴한데 결과값에 문제가 생길줄은 몰랐다.
테스트 케이스가뭔지 알수가 없으니 대체 어디서 오류가 난지도 모르겠다.
그나마 걸리는건 공백문자가 연속으로 나올 수 있다는 조건이다. 공백 연속은 물론 공백을 시작이나 끝에 넣어도 정상적으로 작동하는데 이유를 모르겠다.
주어진 문자가 내가 생각한 문자열 범위 (65~122)외에도 영어 알파벳은 없는 것으로 알고 있다. 설마 영어말고 다른 로마자 대소문자도 테스트 케이스에 들어있는게 아니면 말이 안된다.
속도 비교하기
나의 코드
function sol00(s) {
let answer = "";
answer += s[0].toUpperCase();
for (let i = 1; i < s.length; i++) {
let chr = s[i];
if (s[i - 1] === " ") {
answer += chr.toUpperCase();
} else {
answer += chr.toLowerCase();
}
}
return answer;
}시간 복잡도는 이다.
다른 사람의 코드
return s.split(" ").map(v => v.charAt(0).toUpperCase() + v.substring(1).toLowerCase()).join(" ");
}split(" ") : 공백을 기준으로 새로운 배열을 만든다.
map(...) : 생성된 배열에 처리를 행한다
join(" ") : 공백을 사이에 두고 문자열로 합친다
charAt(0).toUpperCase() : 첫 문자를 대문자로 만든다.
substring(1).toLowerCase() : 둘째 문자부터 마지막 글자까지 소문자로 만든다
시간 복잡도는 이다.
굴려보자
아래와같은 코드를 작성하여 굴렸다
// const s = " 3people unFollowed me ";
const s =
"f4B8 9gH J2k3 m0N1 lX7 Q9 2P T4r 8U3v Z5 6wY j2A9 M0k pQ5 L3d1 F8Jk Q2z 7Xy 9W4e T1R3 g5b H6A0 pN2 U3m q7L O9P2 nY4 v5Z3 B7x K0c3 lQ1 r8W";
function repeatSentence(s, n1) {
return Array(n1).fill(s).join(" ");
}
function repeatWords(s, n2) {
return s
.split(" ")
.map((word) => word.repeat(n2))
.join(" ");
}
const n1 = 100;
const n2 = 100;
const s1 = repeatSentence(s, n1);
const s2 = repeatWords(s, n2);
function sol00(s) {
let answer = "";
answer += s[0].toUpperCase();
for (let i = 1; i < s.length; i++) {
let chr = s[i];
if (s[i - 1] === " ") {
answer += chr.toUpperCase();
} else {
answer += chr.toLowerCase();
}
}
return answer;
}
function sol10(s) {
return s
.split(" ")
.map((v) => v.charAt(0).toUpperCase() + v.substring(1).toLowerCase())
.join(" ");
}
function runtime(func, a) {
const n = 10000;
const startTime = Date.now();
for (let i = 0; i < n; i++) {
func(a);
}
const endTime = Date.now();
const executionTime = endTime - startTime;
console.log(
`${func.name} 함수 반복 횟수 ${n}회, 실행시간 : ${executionTime} ms`
);
}
const list = [sol00, sol10];
for (let i = 0; i < list.length; i++) {
for (let k = 0; k < 3; k++) {
runtime(list[i], s);
}
console.log(`문장이 ${n1}배로 길어진 경우`);
for (let k = 0; k < 3; k++) {
runtime(list[i], s1);
}
console.log(`문장안의 단어가 ${n2}배로 커진경우`);
for (let k = 0; k < 3; k++) {
runtime(list[i], s2);
}
console.log("---");
}

문장 마디의 갯수가 늘어나는 경우 split(" ")에서 가지는 원소의 갯수가 늘어나서 나의 코드가 더 빠른것같고, 반대로 마디의 길이가 늘어나는 경우 마디의 길이만큼 if문을 실행해야해서 나의 코드가 더 느린것 같다
배운 점
-
모든 상황에 대해서 완벽한 예외처리를 할 수 없다면 만들어진 매서드를 가져다 쓰자
-
if문을 안쓰고도 돌아가도록 만들어보자
-
같은 일을 하는 함수라도 구현방법에 따라서 특화되는 케이스가 다르다
