[참고자료]
- 레디스Redis가 뭐에요? 레디스 설치하기, 레디스 튜토리얼
- 인메모리 데이터 저장소 Redis, 왜 사용할까? #Redis 파헤치기
- Why RAM is Called
- 메모리 계층 구조
- Redis가 사랑받는 이유에 대하여
- [DB] Redis의 개념과 특징, 아키텍처 - Azderica

1. Redis(Remote Dictionary Server) 사용 이유?
- Redis는 key-value 쌍으로 데이터를 관리할 수 있는 데이터 스토리지(데이터 구조 저장소)이다.

- 영속성을 지원하는 인메모리 데이터 저장소이다.
- 데이터 저장은 메모리를 포함하여 디스크에도 저장할 수 있다. 스냅샷을 통해서 디스크에 담을 수 있는데 이를 통해서 비휘발성의 특징도 가지고 있다.
- 반복적인 스냅샷을 통해 디스크에 저장해 메모리의 여유 공간을 만들 수 있다.
- 따라서 Redis는 서버가 강제 종료되고 재시작 하더라도 disk에 저장해놓은 데이터를 다시 읽어서 데이터가 유실되지 않는다.
- redis의 데이터를 disk에 저장하는 방식은 snapshot, AOF방식이 있다.
Snapshot: RDB와 비슷하게 어떤 특정 시점의 데이터를 Disk에 담는 방식을 뜻한다. Blocking 방식의 SAVE와 Non-blocking 방식의 BGSAVE 방식이 있다.AOF: Redis의 모든 write/update 연산 자체를 모두 log 파일에 기록하는 형태이다. 서버가 재시작 시 write/update를 순차적으로 재 실행하고 데이터를 복구한다.- 가장 좋은 방식은 두 방법을 혼용해서 사용하는 방법으로 주기적으로 snapshot으로 백업을 하고 다음 snapshot까지의 저장을 AOF방식으로 수행하는 방식이다.
- 싱글 쓰레드를 지원한다.
- 사용자가 많기 때문에 정보가 많다.
- ACID(원자성, 일관성, 독립성, 지속성)를 유사하게 지원해서 트랜잭션을 걸 수 있다.
- 여러 프로세스에서 동시에 같은 key에 대한 갱신을 요청할 경우, Atomic 처리로 데이터 부정합 방지 Atomic처리 함수를 제공한다.(원자성을 잘 지킨다)
- 빠른 액세스 속도를 보장받을 수 있다.
- 기존 RDB db 대비 평균 읽기, 쓰기 작업 속도가 1ms(1/1000)미만으로 초당 수백만 건의 처리가 가능하다.
- 리스트형 데이터 입력과 삭제가 MySQL에 비해서 10배정도 빠르다고 한다.
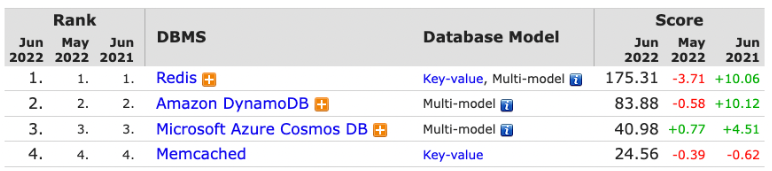
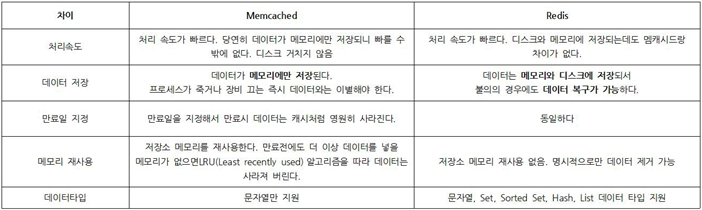
- Memcached와 비교
2. 인메모리(In-memory)?
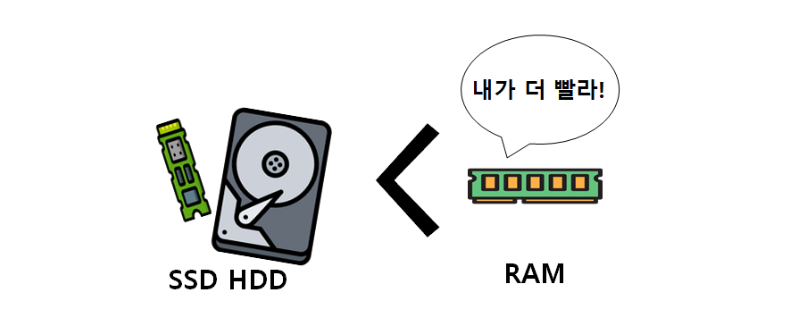
- 인메모리란 컴퓨터의 메인 메모리 RAM에 데이터를 올려서 사용하는 방법을 말한다.
- 왜 메모리에 데이터를 올릴까? 이유는 명확하게도 속도 때문이다.
- SSD,HDD 같은 저장공간에서 데이터를 가져오는 것보다 RAM에 올려진 데이터를 가져오는데 걸리는 속도가 수백배(HDD 기준) 이상 빠르다. 때문에 Redis는 빠른 속도가 큰 장점이다.
- 다만, RAM을 메인 데이터베이스로 사용하지 않는 이유는 비용이라는 큰 걸림돌 때문이고, Key-Value형태의 NoSQL이라는 점이다. noSQL은 복잡한 데이터를 저장하는 데이터 베이스로 사용하기에는 어려움이 있다.
- 따라서 Redis의 가장 적합한 역할은 캐시 데이터베이스 서버다.
예를 들어, 게임의 랭킹 상위 100위를 보여주는 기능이 있다고 해보자. 랭킹 정보를 사용자에게 제공하기 위해 오라클같은 관계형 데이터베이스에 랭킹 정보를 저장을 하고 order by 로 불러올 수 있다. 그런데 사용자 수가 폭발적으로 증가해 수백만명으로 늘어나게 되면 어떻게 될까? 보여주는건 100명의 데이터뿐이지만 시간이 점점 오래 걸리게 될 것이다. 이러한 문제를 해결하기 위해 캐시에 상위 100명의 랭킹정보를 담고 있다면 좋은 해결책이 될 것이다.
3. HashMap을 쓰지 않고, Redis 연동 클라이언트를 사용하는 이유?
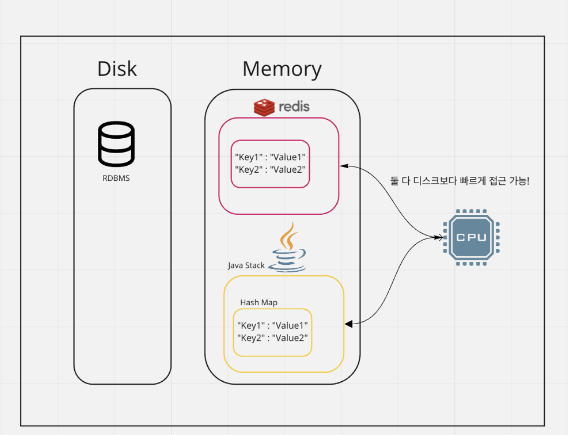
나는 원래 Java - SpringBoot로 개발 하던 사람이었다. Redis를 접하고 가장 먼저 든 생각은 ‘그냥 hash map구조 아니야?’ 였다. 그래서 처음엔 구지 인스턴스에 redis를 설치하면서 까지 사용해야할 필요를 못 느꼈다.
그러나, 서버가 1대 있다는 가정이 아닌, 분산 환경을 대입하면 장점이 드러난다.
1) 분산 환경에서의 Redis 장점
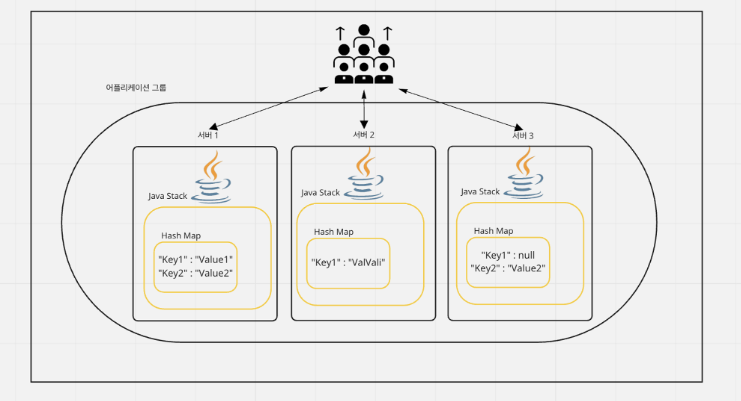
유저의 요청이 크게 늘어나 서버를 몇 대 증설하였지만, 동일한 해쉬맵 데이터를 참조해야할 상황이 있다고 가정한다.
이 때 원격 프로세스간에 동일한 해쉬맵 데이터를 참조해야 한다면, 분산 환경에서 원격 프로세스간 데이터를 동기화 하기 어렵다.
이 때, 아래의 그림과 같이 ¹별도의 레디스 서버를 구성하고, 해당 레디스에서 값을 꺼내 쓴다면 메모리 기반 데이터 구조의 빠른 응답성을 확보함과 동시에 데이터 불일치 문제를 해결할 수 있다.
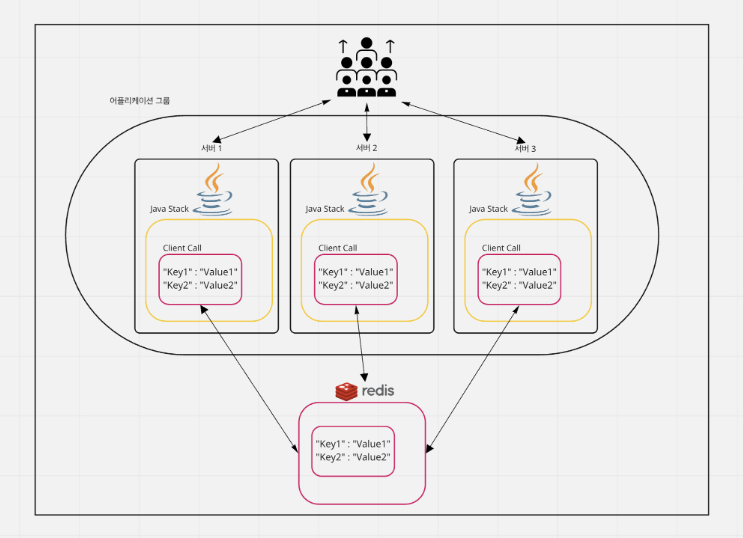
2) DBMS로서의 장점
또한 어플리케이션을 종료하면 휘발되어 사라져버리는 HashMap과 달리, Redis는 다양한 영속성(디스크 백업) 옵션을 제공한다.
- 영속성
- TTL: 일정 시간이 지나면 데이터를 삭제하여 용량이 작은 메모리를 효율적으로 관리할 수 있다. → hashMap은 기능 x
- 분산 데이터 저장소 구성: Redis Cluster 등 분산 환경에서 안정적인 데이터 관리 가능 → hashMap은 동기화x
- 보안체계: 악성 스크립트 공격으로 부터 안전 보장, TLS지원
4. 결론: Redis를 적용해야 하는 이유
🚨 의견(1): 프로젝트에 redis를 적용하니 팀원 중 한 명이 Redis는 비용이 많이 나가는데, 빈 객체를 생성해서 hash-map구조로 하는게 더 경제적이지 않느냐는 의견을 냈다.
어찌보면 맞는 말 같기도 하지만 '사업규모가 커져 분산 환경을 사용해야한다면?', '보안에 문제가 생긴다면?' 과 같은 부분을 함께 고민해야한다. 단순 프로젝트성이라면 빈 객체로 hash-map구조를 사용하여 구현해도 되지만 실제 프로덕션 환경임을 간과해선 안된다고 생각이 들었다.
사용자의 정보 = 기업의 돈과 직결되어 있기 때문이다.
🚨 의견(2): 데이터서버에서 redis까지 사용할 이유가 있는가?
현재의 서버에서 성능이슈가 발생할 가능성에 대해 따져본다면 나의 결론은, 충분히 필요하다이다.
왜냐하면,
-
지금 데이터서버가 단일서버로 운영하고 있다하더라도 추후 예정된 신규사업에서 146대의 카메라와 2-3개의 리프트 카메라가 30분마다 최소 4-500개의 img가 서버에 전송될 예정이다.
-
현재, DB에는 34개의 클라이언트가 있고 이 클라이언트는 하나의 서버에 정시 혹은 30분 간격으로 데이터 전송(img, json) 요청을 하고 있다.
-
회사의 규모가 확장함에 따라 신규사업과 같은 곳이 20곳만 된다고 하더라도 8mb크기의 image를 450개씩 30분마다 전송한다고 가정한다면, 처리해야할 총 데이터량은 대략 72GB에 이른다. 이는 인스턴스의 상당한 부담이 될 수 있다.
이 요청마다 매번 db에서 조회를 하게되면 데이터베이스 과부하 뿐 아니라 EC2에서도 상당한 부담이 될 것이라고 생각한다. 그렇기 때문에 캐시 서버를 사용하는 이유다. 캐시 서버의 가장 대표적인 것이 redis이다.
- redis의 get/set명령어는 초당 10만개 정도까지 처리할 수 있다.

캐시 서버인 redis를 사용하게 된다면, 매 요청마다 db에서 조회를 하지 않고, 클라이언트가 웹 서버에 요청을 보낼 때마다 웹 서버는 데이터를 DB에서 가져오기 전에 Cache에 데이터가 있는지 확인한다.
캐시 서버에 데이터가 있으면 데이터를 DB에 데이터를 요청하지 않고 바로바로 클라이언트에 데이터를 반환하는데 이를 cache Hit라고 한다.
반대의 경우는 cache Miss라고 한다. cache 서버에 데이터가 없으면 DB에 해당 데이터를 요청한다. DB는 사용자가 원하는 데이터를 반환해주고, 웹 서버는 반환된 데이털르 다음 사용을 위해 캐시에 저장한 후 클라이언트에 반환한다. 따라서 이후, 같은 요청이 들어온다면 그때는 cache hit이 발생하는 구조다.
5. Redis 비용 문제?
redis를 사용할 때 3가지 방법이 있다.
1) AWS의 Redis Cloud를 사용하는 방법과, 2) AWS ElastiCache를 사용 하는 방법, 그리고 3) EC2인스턴스에 Redis를 설치하는 방법이다.
결론적으로 말하면, 나는 EC2인스턴스에 Redis를 설치할 예정이다.
- AWS Redis Cloud는 30MB의 무료 Database 1개를 제공한다. -> 비용 발생
- AWS ElasticCache는 완전 관리형 서비스이지만 과금의 문제가 크다 -> 비용 발생
- EC2로컬에 Redis설치 -> 무료, 그러나 백업은 직접관리해야함. 하지만 우리 프로젝트에서 백업은 필요없고 임시데이터만 저장할 의도기 때문에 필요없음.
6. Redis 설치 방법
현재는 내 로컬에 redis를 설치하여 실행했다. 로컬에서 redis서버를 꺼버리면 redis를 사용할 수 없기에 다른 방법을 찾아봐야 했다. 아직은 적용 전이지만 해볼 수 있는 것은,
1. AWS에 ElastiCache를 사용해서 redis 캐시 서버 만들기
2. AWS의 EC2에 직접 redis 설치하기1번에 대한 방법은 ElastiCache는 AWS의 내부에서만 사용이 가능하기 때문에 test가 생각보다 쉽지 않다. 그래서 접근이 쉬운 2번의 방법을 생각하고 있다.
방법: AWS의 EC2에 직접 redis 설치하기
- ssh로 EC2에 접속한 뒤 직접 redis를 설치하여 백그라운드로 돌려놓는 방식
EC2 인스턴스 생성하기
- 인스턴스를 생성한다.
- 이후 보안그룹을 설정해주어야 하는데 인스턴스를 생성할 때 ssh, https, http 를 체크해주면 기본적으로 이 세 포트는 접근이 가능하도록 보안그룹이 열려있다.
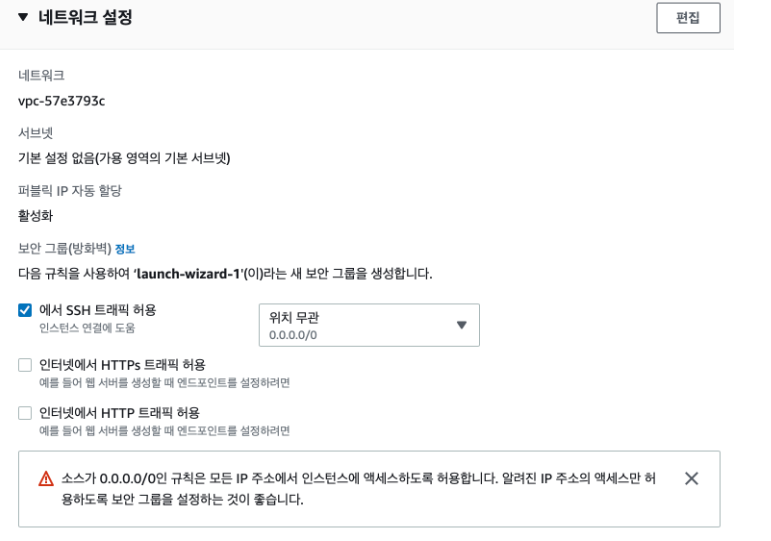
- 하지만 우리는 redis로도 접속을 해야하기 때문에 보안그룹에 들어가서 TCP에 6379번 포트를 열어준다.
- 그리고 탄력적 IP에 들어가서 IP를 하나 생성해주고 위에서 만든 EC2 인스턴스를 연결해준다.
ssh -i EC2
-
EC2 서버에 접속한다.
-
인스턴슬르 선택하고 오른쪽 상단 연결버튼을 누르면 SSH로 연결할 수 있는 명령어가 뜬다.
-
ssh -i ~ 와 같은 형식으로 적혀있을 건데 그것을 복사해준다.

-
인스턴스 생성 시 새로 발급받은 보안키 페어가 있는 곳으로 이동하여 명령어를 실행시켜 준다.
-
보안키 에러 시
ssh-keygen -R [EC2 ip]다른 에러 중,
- ssh 명령어가 실행되지 않고 Connection timeout이 발생한다면
- 보안그룹에 22번 포트로 ssh 가 열려있는지?
- 인스턴스 상태를 재부팅 시키기
- 혹은 인스턴스 상태를 중지했다가 다시 실행하기
등의 방법이 있다. 22번 포트의 접근 ip를 내 ip로 바꾸고 인스턴스를 중지한 뒤 재부팅하면 접속이 가능하다.
본론: EC2 설치
