나는 Big O가 정말 1도 이해가 되지 않았다.
코딩테스트준비고 나발이고 Big O는 뭐야.. O(n)?.. O(log n)?..

너무 알고싶은데 머리로 이해가 되지 않으니 학습이 즐겁지 않았다. 그러던 중 한줄기 빛을 발견한것이 "니꼴라쓰 임늬다~~"
Big O
시간복잡도에 대해 알아보자!
알고리즘의 스피드 표현방법은 "빠르다", "느리다"로 표현하지 않는다. 또한 시간, 몇 초로 세지도 않는다.
왜냐하면 컴퓨터의 하드웨어가 계산속도를 결정하기 때문이다.
그렇다면 알고리즘의 속도표현은 무엇으로 하는가?
"임무완료까지의 step수 로 결정된다!"
목표에 달성하기 위해 컴퓨터가 처리해야할 단계가 적을수록 좋은 알고리즘이라고 할 수 있다.
먼저 선형검색 시간복잡도를 살펴본다면 1~9까지의 숫자중 7이라는 숫자를 찾기 위해서는 7번의 step이 필요하다. 그것을 그래프로 표현하면 이렇다.
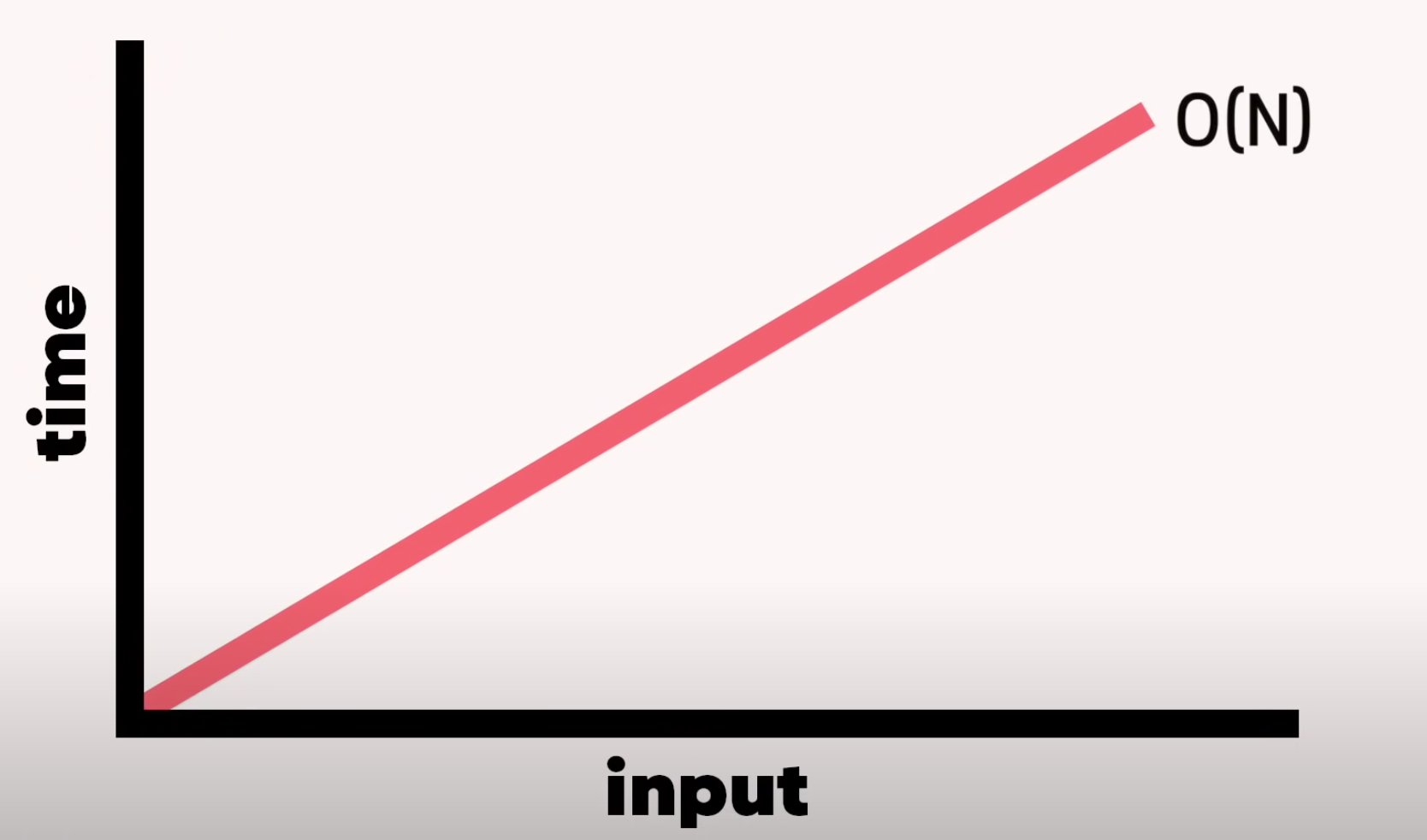
출저:노마드코더 (ps.니꼴라쓰는 사랑입니다ㅜㅜ!!😍)
우선 선형검색의 시간복잡도는 O(n) 으로 이해하고 넘어가도록 한다.
Big-o를 사용하는 이유?
개발자라면 좋은 알고리즘에 대해 고민할 것이다.
"이것보다 더 효율적인 코드는 없을까?", "이게 제일 좋은방법이 맞나?" 하는 고민이다. 그것은 바로 시간복잡도를 고민하고 있다는 의미다.
우리가 원하는 목표도달까지 컴퓨터가 처리해야할 스텝 수가 적을 수록 좋은 알고리즘이라고 할 수 있다. Big-O는 이러한 시간복잡도를 표기하는 표기방법 중 하나이다.
📒 시간 복잡도를 표기하는 3가지방법!
- Big-O(빅-오)
- Big-Ω(빅-오메가)
- Big-θ(빅-세타)
의사들은 환자에게 최악의 상황을 알려준다.
개발자는 사용자에게 최악의 실행시간을 알려준다.
우리가 저 세가지 표기방법 중 빅-오를 사용하는 이유는 프로그램이 실행되는 과정에서 발생할 수 있는 최악의 시간까지 고려할 수 있기 때문이다.
"이 정도 시간까지 걸릴 수 있다"를 고려해야 그에 맞는 대응이 가능하다. 요약하자면 이렇다.
1. 시간복잡도를 빠르게 설명할 수 있다.
2. 읽기 쉽고 바로 설명이 가능하다.
3. 알고리즘 분석을 빠르게 할 수 있고
4. 언제 무엇을 쓸지 빠르게 파악이 가능하다.
5. 또한 나 자신의 코드를 평가할 수 있다.
왜냐하면 미래에 이 코드가 어떻게 작동할지 알 수 있기 때문이다.O(1) 이 뭔가요?
예를들어 어떤 배열을 입력받고 그 배열의 요소중 [i]번째 인덱스를 출력하는 메서드를 만들었다고 해보자.
f(String[] arr){
System.out.Print(arr[0]);
}이 메서드는 단 한번으로 실행이 끝나게 된다.(==스텝:1)
arr의 요소가 10개가 들어오던 100개가 들어오던 상관없이 이 메서드는 단 한번이면 충분하다.
input의 크기와 상관없이 스텝의 수는 1이다.
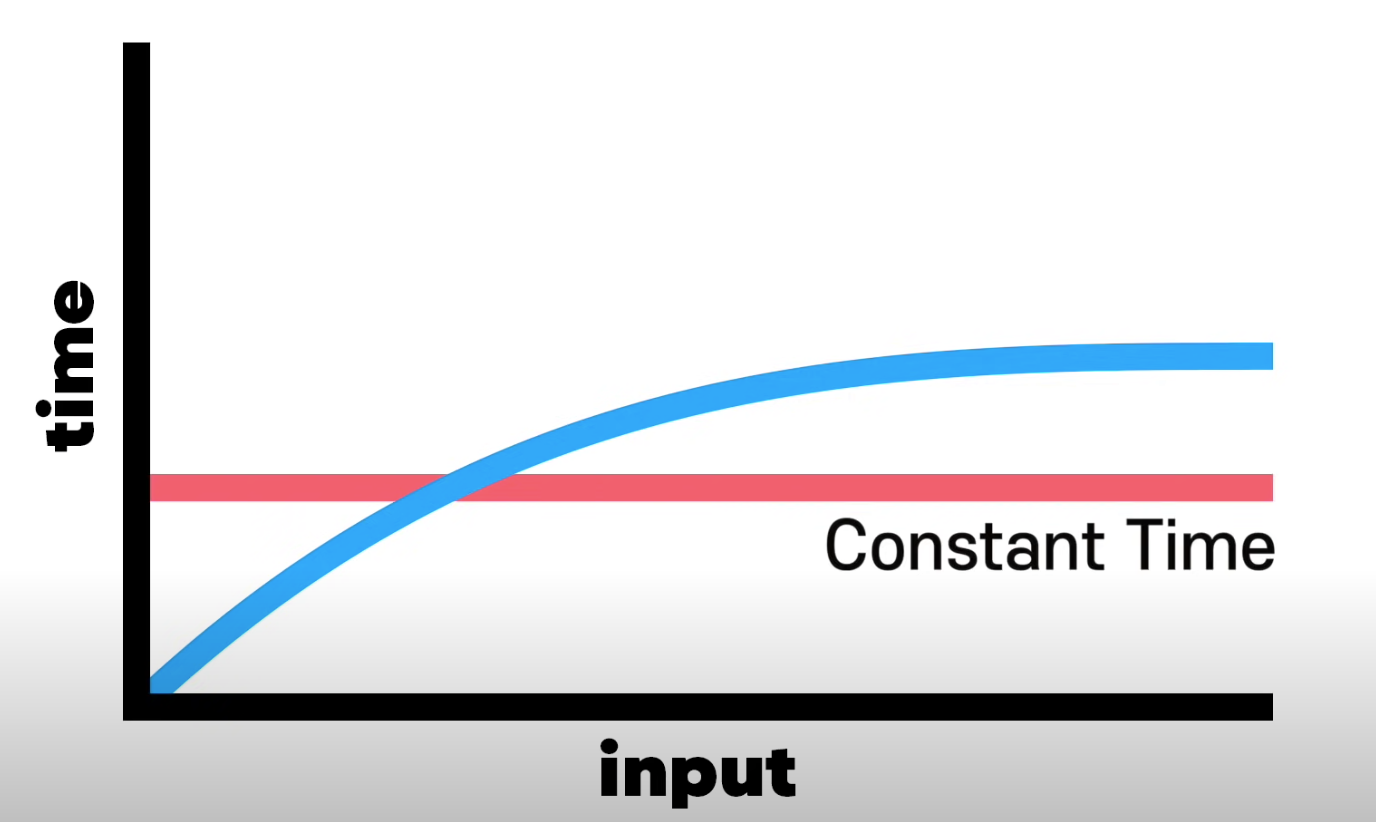
이 메서드의 시간복잡도는 항상 1일테니 상수시간(constant time)이라고 할 수 있다.

또 다른 예시를 살펴보자
f(String[] arr){
System.out.Print(arr[0]); // 1 step
System.out.Print(arr[0]); // 2 step
}아까의 코드를 살 짝 바꿔 arr배열의 0번 인덱스를 2번 출력하는 메서드를 작성했다.
이 메서드가 끝나려면 컴퓨터는 2번의 스텝을 진행할 것이다. 그러면 시간복잡도는 O(2)인 것일까?
❌NO!!❌ 빅-오는 그런 디테일엔 관심 없다. 이 메서드는 여전히 O(1) 이다.
빅오는 상수에 전혀 신경쓰지 않는다. 인풋 사이즈와 상관없이 스텝이 정해진 알고리즘을 O(1)이라고 한다.
O(n)
O(n)은 input값이 증가하면 컴퓨터가 코드를 실행하는 횟수도 증가한다는 것을 의미한다.
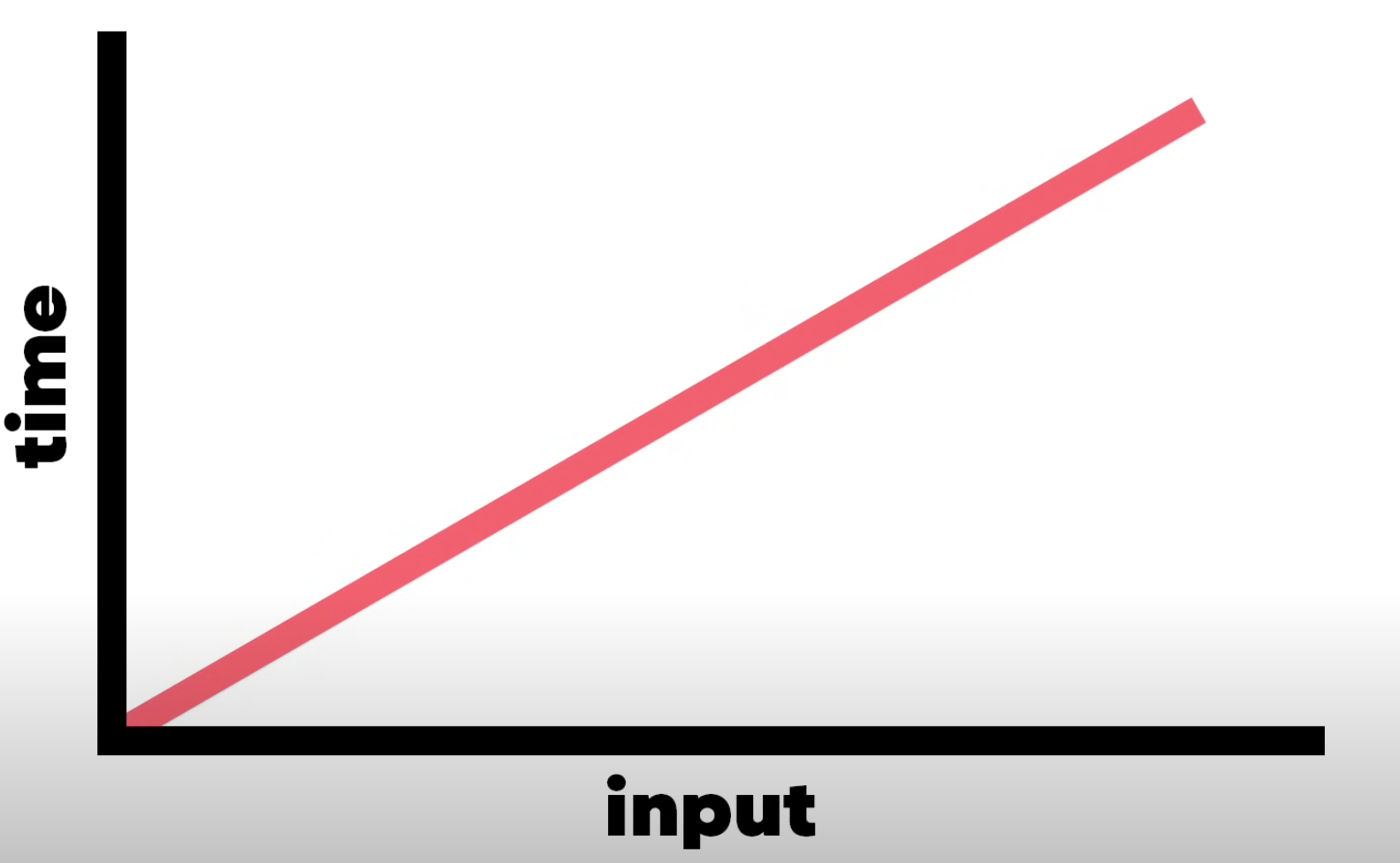
코드로 예를 들자면 이렇다.
f(String[] arr){
for(int i=0; i<arr.length; i++){
System.out.Print(arr[i]);
}
}arr[ ]의 요소가 3개라면 반복문을 통해서 프로그램은 3번을 실행하게 된다. 극단적인 예로 arr[ ]의 요소가 100개로 증가한다면 메서드가 끝나기까지 프로그램은 100번의 step이 있어야만 종료될 것이다.
이와같이 input값이 증가함에 따라 step의 수가 비례하게 증가한다면 그것은 O(n)이라고 할 수 있다.
O(n^2)
앞서 O(n)은 input값이 증가하면 step의 수가 증가하는 것이라고 이해했다.
그렇다면 O(n^2)은 무엇일까?
문자그대로를 이해한다면 input이 n이라고 한다면input값의 거듭제곱만큼 step수가 필요할 것이다.
주로 2중 for문(모든 2중for문이라는 건 아님!!)일 경우 O(n^2)시간복잡도가 적용된다. 코드로 살펴보자.
f(int 5){
for(int i=0; i<5; i++){
for(int j=0; j<5; j++){
System.out.Print(arr[i][j]);
}
}
}input의 숫자(5)만큼 for문이 반복문을 도는 돌 때 그 아래의 for문이 input의 크기만큼 한번 더 반복문을 실행하고 있다.
for문이 한번 돌 때 1초씩 증가한다고 예를 들면 아래의 for문을 끝내기까지는 총 25초가 소요된다.
이와같이 input값보다 step횟수가 제곱의 크기만큼 증가한다면 이것은 O(n^2)라고 할 수 있다.
그래프로 이해하면 이렇다.
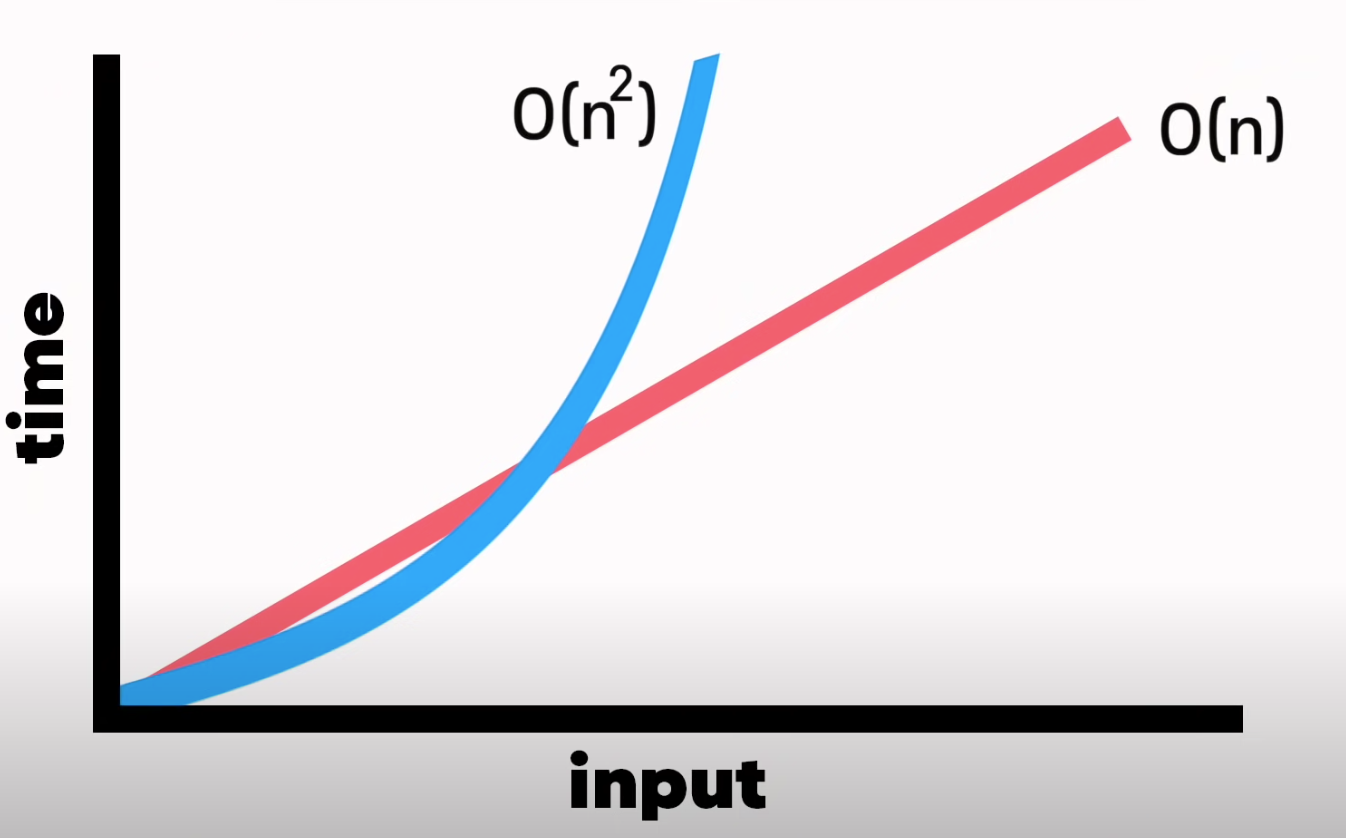
O(n)은 데이터의 크기와 비례하여 처리시간이 증가하는 반면 O(n2)는 처음에는 O(n)보다 처리속도가 빠른 듯 보이지만 데이터가 커지면서 처리속도가 2배 이상 늦어진다는 것을 알 수 있다.
O(log n)
O(log n)은 이진 탐색 트리에서 확인 할 수 있다.
이진트리 탐색은 지수의 정 반대개념이다.
이진트리탐색은 코드를 실행할 때 마다 매번 step을 반으로 나눈다. 따라서 input값이 아무리 커져도 step의 횟수는 input의 크기만큼 커지지 않는다는 이야기다. input이 5일 때와 100일 때 이 둘의 차는 95씩이나 나지만 가지고있는 step갯수는 큰 차이가 없다. 왜냐하면 스텝을 하나씩 진행할 때마다 input값은 반으로 나뉘기 때문이다.
그래프를 보자.
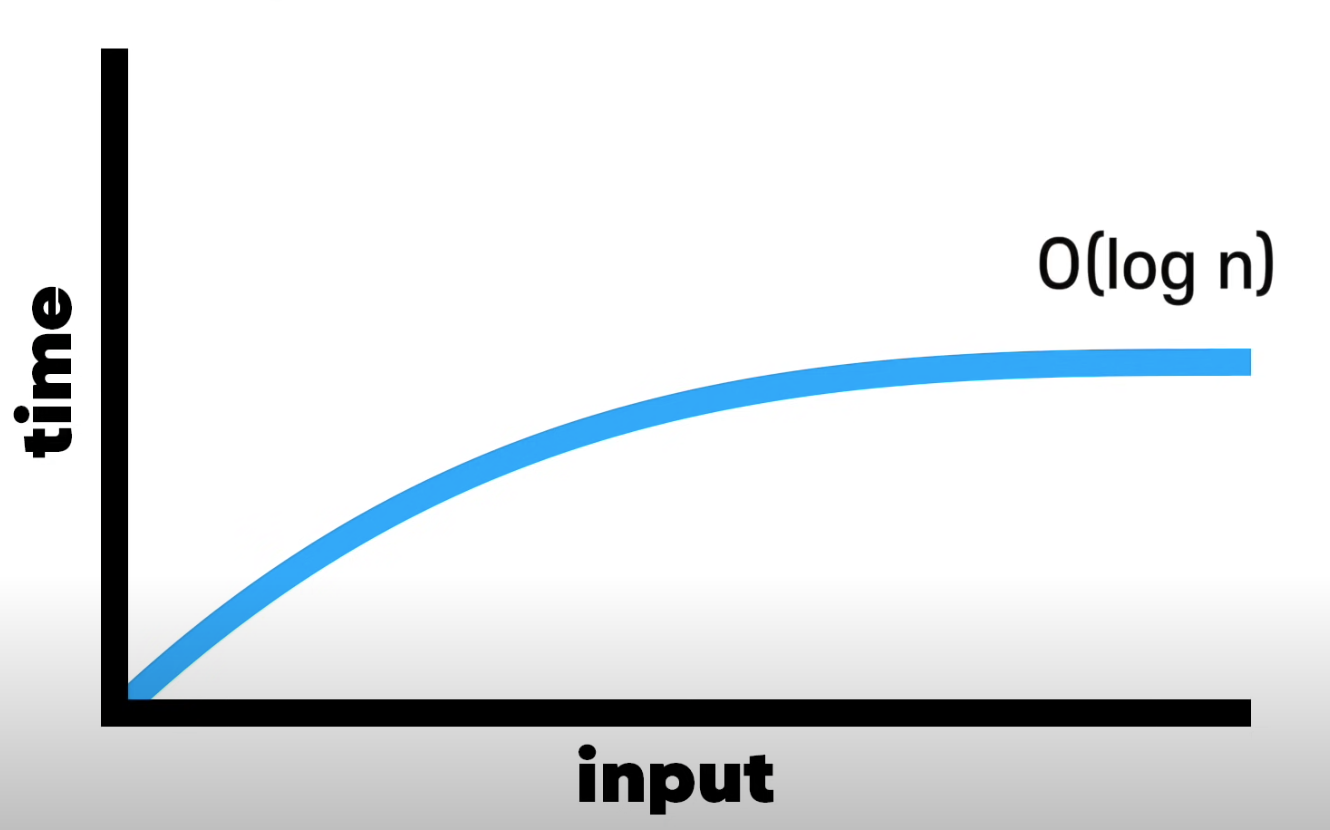
O(n)보다는 빠르고
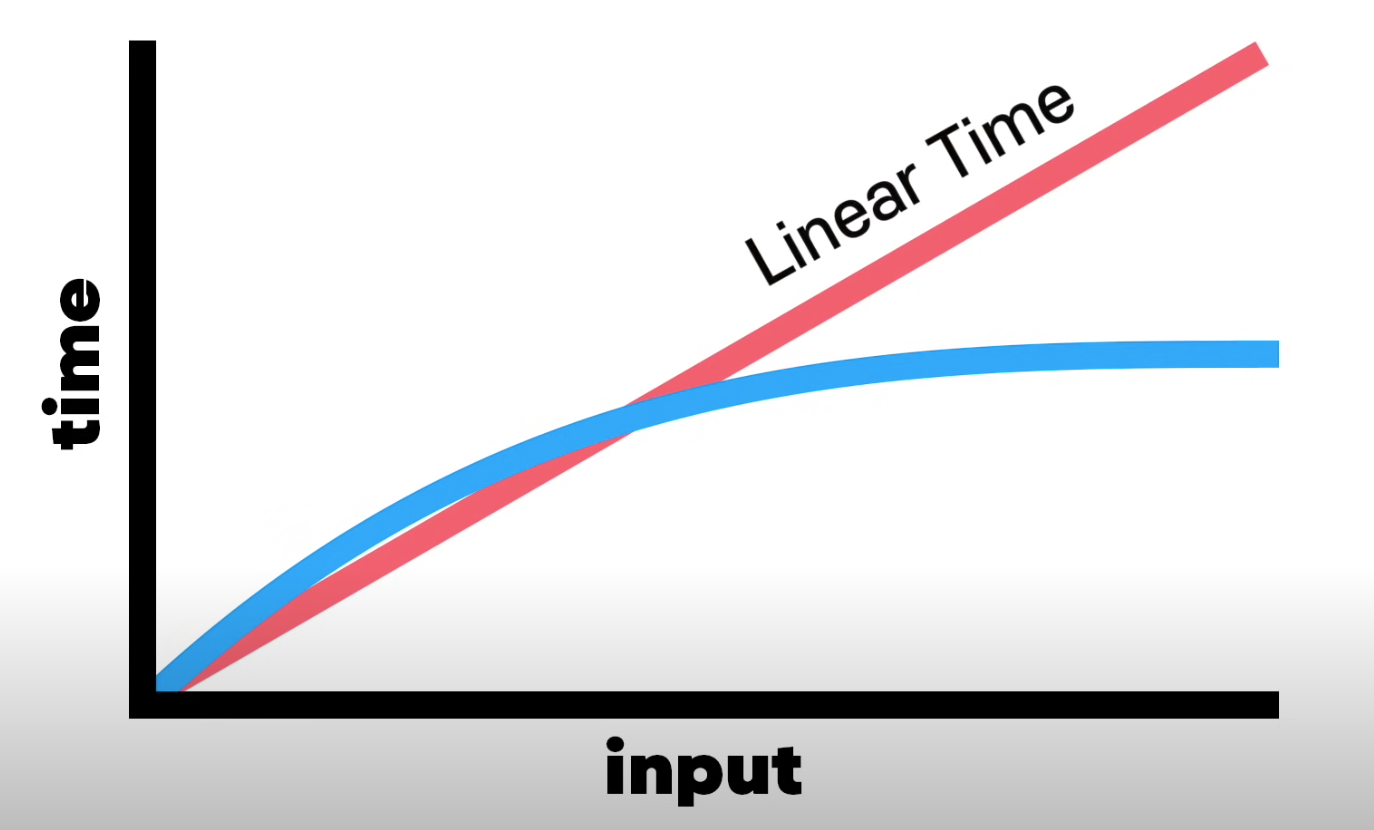
O(1)보다는 당연히 느리다.
O(2^n)
Big-O표기법 중 가장 느린 시간 복잡도를 가진다.
재귀로 구현하는 피보나치 수열은 O(2^n)의 시간복잡도를 가진 대표적인 알고리즘이다.
public int fibonacci(int n) {
if(n <= 1) {
return 1;
}
return fibonacci(n - 1) + fibonacci (n - 2);
}하나의 값을 얻기위해 2의 제곱의 제곱의 제곱을 하는..!!!굉장히 비 효율적인 시간복잡도라고 할 수 있다.

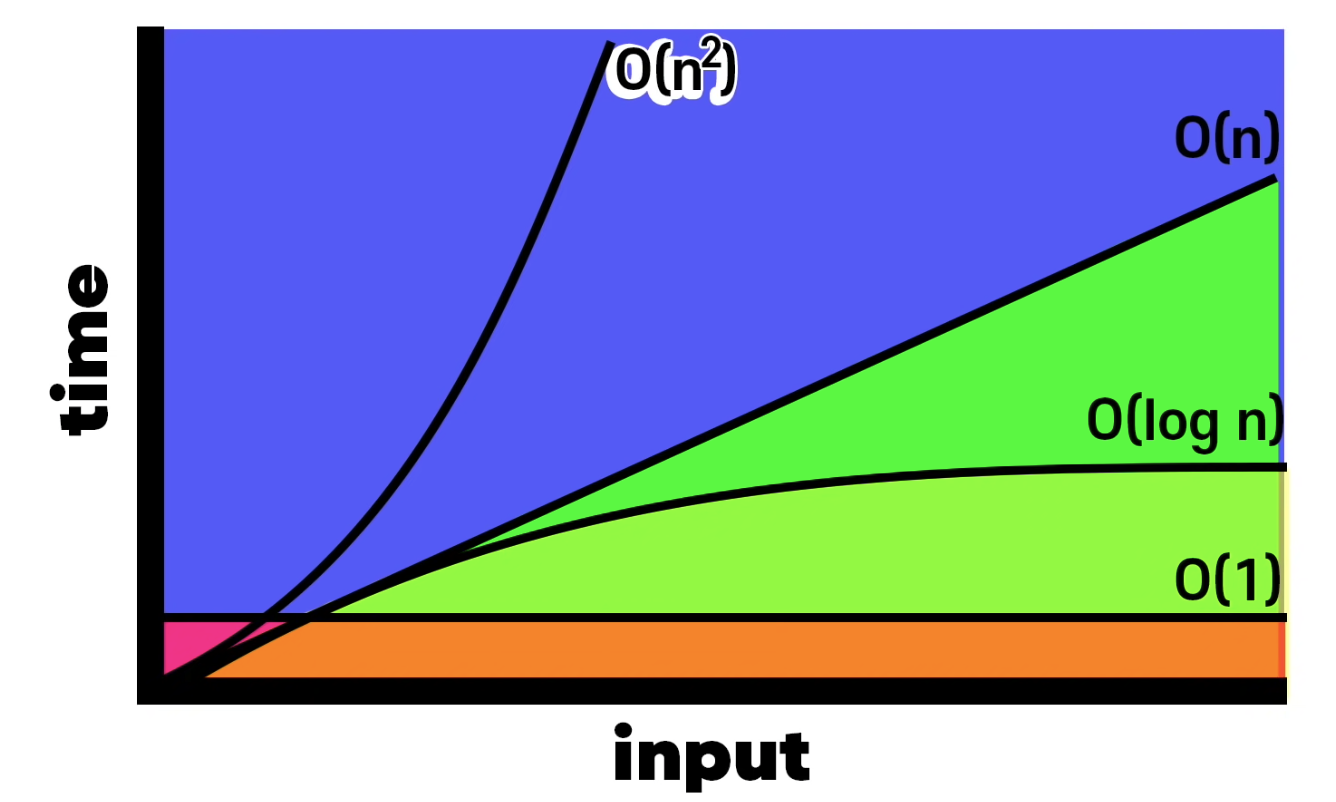
⭐️ Big O의 속도를 빠른순으로 순차적으로 나열하면 이렇다.
O(1) < O(log n) < O(n) < O(n^2) < O(2^n) < O(n!)
나만 보기 아까우니 널리널리 퍼뜨리자!!
