👉 Clean Architecture
Robert C. Martin이 작성한 블로그 글 에서 정립한 용어로, 기존의 계층형 아키텍쳐가 가지던 의존성에서 벗어나게 하는 설계를 제공한다.
클린 아키텍처에서는 외부 인터페이스에 독립적으로 구현을 할 수 있도록 한다.
계층형 아키텍처의 의존성은 항상 다음 계층(아래 방향)을 가리킨다.
반대로 클린 아키텍처의 의존성은 원 안쪽을 향한다.
즉, 바깥쪽 원에 해당하는 어떠한 것들도 안쪽 원에는 영향을 주지 않는다.
클린 아키텍처는 확장 가능하고 테스트가 가능한 프로그램(TDD에 용이한)을 만드는 것에 용이한 구조를 제공한다.
이 아키텍처는 바깥 레이어가 정해지지 않아도 서비스를 구축해나갈 수 있도록 하는 것을 목표로 한다.
👉 중요하게 생각하는 것들
- 내부 데이터와 로직들은 안쪽을 향해야 한다.
- 요청은 안쪽으로 들어와 바깥쪽으로 나간다.
-> 요청 진행 방향이 변화되는 경우는 존재하지 않는다. - DI(Dependency Injection) : 인터페이스의 변경이 코드의 변화를 일으키지 않도록 한다.
- DB, UI 등은 바뀌어도 프로그램 자체는 문제 없이 돌아가도록하는 세부 사항으로 취급한다.
👉 요소
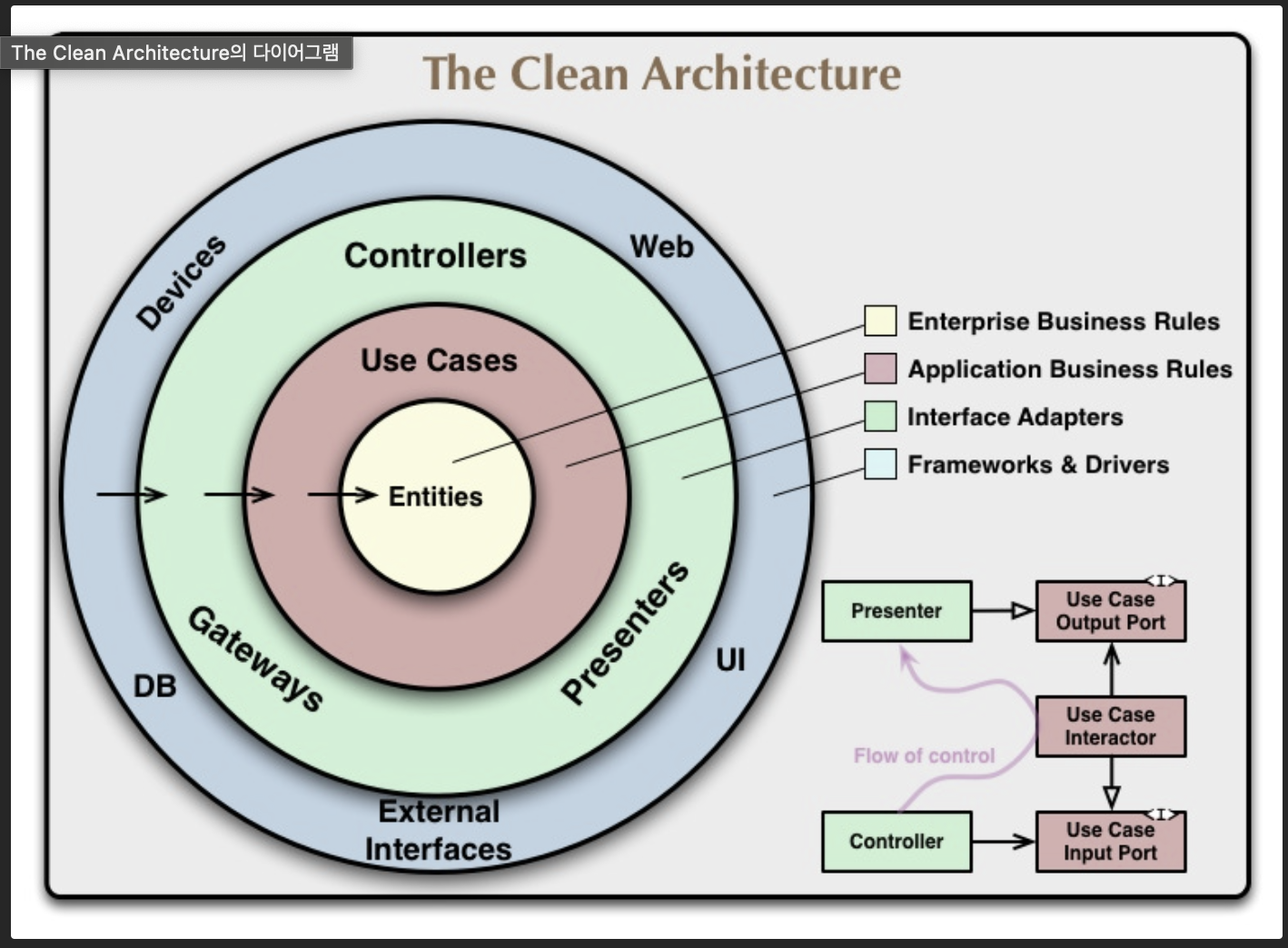
.jpg)
바깥쪽 원에 위치할 수록 중요하지 않고 언제든 바뀔 수 있는 세부사항으로 취급한다.
✅ Entity
가장 중요한 핵심이 되는 부분이다.
Id로 구별이 가능하고 영구히 보관이 가능한 것들을 주로 Entity로 가진다.
Entity는 factory pattern 등을 이용하여 외부에서 생성이 가능하도록 할 수 있다.
✅ Use Case
수행하는 업무(일)을 가리킨다.
따라서, 실행할 수 있는 형태를 가지고 있다.
✅ Controllers
✅ Interface
Interface는 클린 아키텍처에서 세부 사항으로 취급한다.
이를 통해서 변경이 일어나도 핵심인 내부는 영향을 받지 않는 구조를 만들어낼 수 있다.
Interface라는 사실만 동일하다면 바꿔치기를 할 때 문제 발생 없이 프로그램의 변경(확장)을 이루어낼 수 있다.
바꿔치기를 통해 기능의 변경(확장)을 이루기에 어댑터(adapter)의 집합으로 볼 수 있다.
👉 경계
클린 아키텍처에서 가장 중요하게 생각해야할 것은 경계 부분이다.
각 계층들이 명확하게 분리가 되어있기 때문에, 서로 데이터를 주고 받기 위해서는 entity의 형태로 데이터가 경계를 넘나들어야 한다.
경계를 넘나드는 데이터는 항상 안쪽 원에서 사용하는 데이터의 형태이어야한다.
Factory를 통해서 각 객체가 생성되도록 하고 validation은 factory에서 실행하도록 한다.
Validation을 factory에서 진행하기 때문에 각 계층이 바뀌더라도 검증에 대한 부분은 문제 없이 진행될 수 있다.
👉 클린 아키텍처의 장점
각 계층이 명확하게 분리되어있기 때문에 테스트와 유지 보수가 용이해지는 장점이 있다.
인터페이스에 대한 의존성이 없어져 인터페이스가 바뀌더라도 클라이언트는 그대로 사용할 수 있다는 장점이 있다.
기존에 계층형 아키텍처가 가지던 데이터베이스에 대한 의존성이 없어지기 때문에, 데이터베이스가 정해지지 않아도 다른 부분들을 개발할 수 있다는 점 역시 장점이다.
👉 가볍게 적용해본 후기
클린 아키텍처를 (조금이나마) 적용을 하면서 개발을 진행해보니 다른 계층을 신경쓰지 않고 하나의 계층만 명확히하면 된다는 사실이 매우 편리했다.
아무래도 프로젝트를 하다보면 각 부분들이 연결되어있는 부분들 때문에 어디서부터 시작해야할지 감이 안잡혔는데, 클린 아키텍처를 통해 진행을 하다보니 하나의 계층만 신경을 쓰면 되어서 이전에 있던 혼란스러움은 조금 덜어내면서 진행할 수 있던 듯하다.
각 계층별로 데이터를 주고 받을 때 계속해서 객체를 생성해야한다는 점이 번거롭고, 같은 정보를 가지는 객체를 왜 계속 생성을 해야하는 것일까하는 의문도 가졌지만 처음 몇 번의 번거로움을 감수한다면 이후에는 오히려 신경써야할 것이 줄어드는 것도 같다.
아직 제대로 적용해본 것도 공부해야할 것들도 많지만 아무튼 가볍게라도 사용해본 경험으로써는 나쁘지 않은 듯하다.

좋은 설명이네요. 아래 코드의 변화를 일으키지 않다는 게 이해가 잘 안 되네요. -_-;;;
DI(Dependency Injection) : 인터페이스의 변경이 코드의 변화를 일으키지 않도록 한다.