[CODEKATA]
<멸종위기의 대장균 찾기>
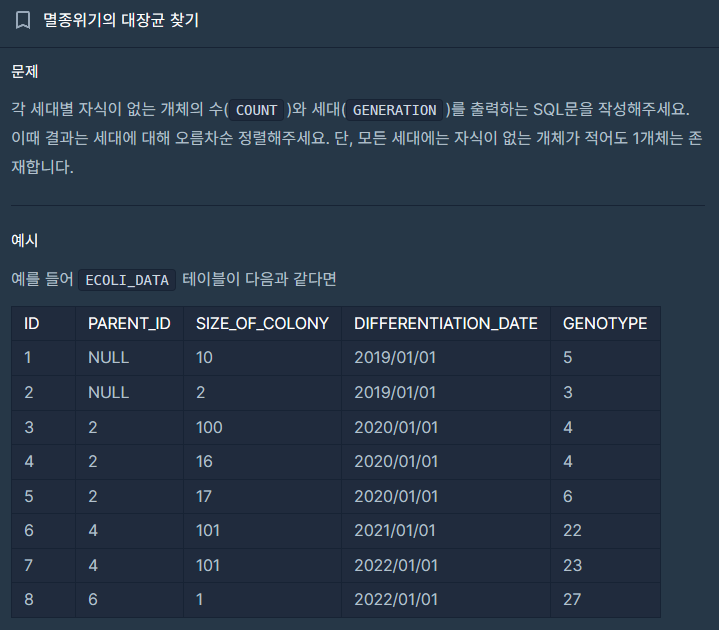
문제 조건
- 각 세대별 자식이 없는 개체 = PARENT_ID 컬럼에 ID값이 존재하지 않는 개체
- 각 세대별 자식이 없는 개체의 수(COUNT) 컬럼 생성
- 세대(GENERATION)을 출력하는 SQL문 = recursive로 반복하여 컬럼 생성
풀이 방법
with recursive cte as(select 추출을 원하는 컬럼들, 1 as 반복문을 생성할 컬럼 from 기본테이블 where 재귀쿼리의 조건 union all 위 쿼리에 아래 쿼리 연산 select 추출을 원하는 컬럼들, 1+반복문을 생성할 컬럼 from cte 하나씩 불려 나감 where 언제까지 반복할건데?)
1. 재귀 쿼리 셋팅 : 1세대 쿼리 생성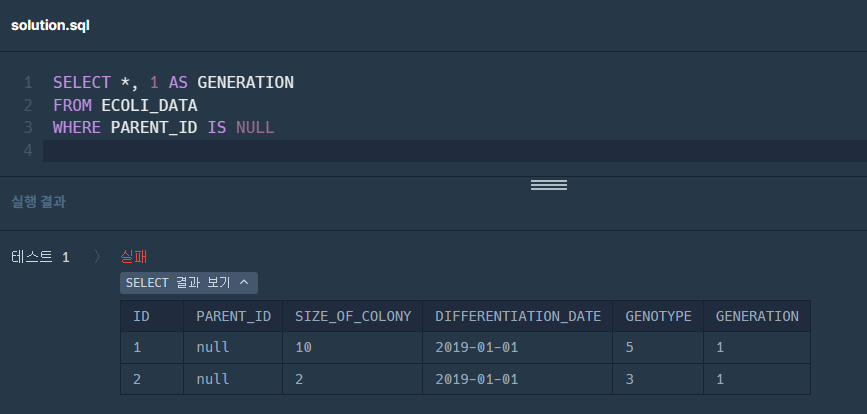
1-1. ECOLI_DATA(전체 테이블)의 PARENT_ID와 CTE(재귀쿼리)의 ID가 같은 값일 경우, 자식을 배양했다. 즉, e.PARENT_ID=a.ID 조건으로 inner join한다.
❗ with 쿼리가 1세대의 데이터만 추출한 것이므로, 1세대 데이터 확인을 통해 원하는 값을 추출했음을 알 수 있다.
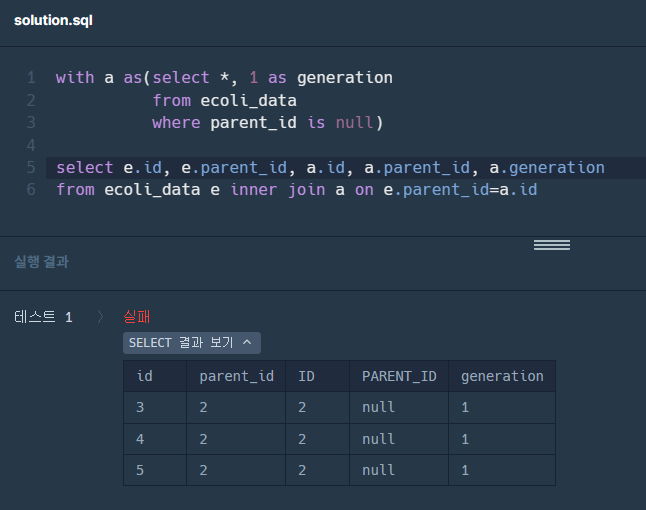
2. recursive를 통해 재귀쿼리를 완성한다. union all 기준 위 쿼리가 초기 설정값이고, 아래 쿼리가 반복되는 쿼리이다.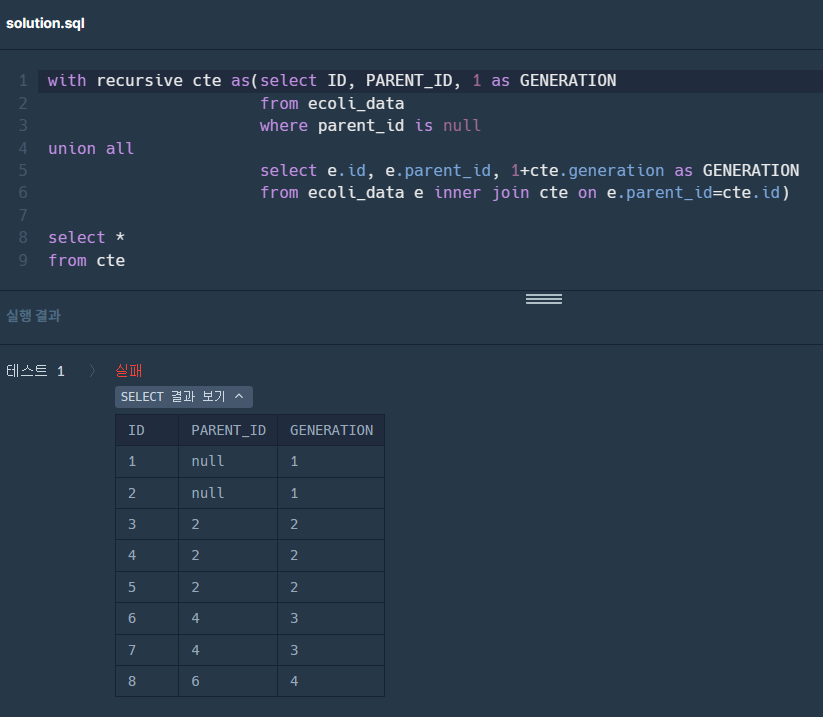
2-1. 이대로 count를 하면, 각 세대별 자식이 있는 개체의 수를 센다.
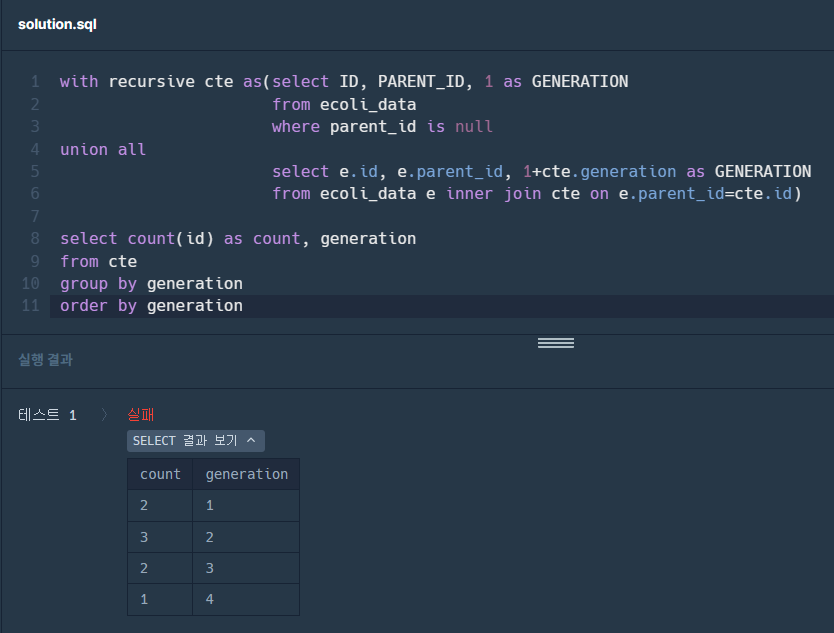
❗ 하지만, 문제는 각 세대별 자식이 없는 개체의 수를 요구하고 있다.
3. cte(재귀쿼리)에서 데이터를 추출하되, where not ~ in( )을 사용하여 테이블에 속하지 않는 컬럼을 추출할 수 있도록 한다.
3-1. 각 id가 parent_id에 없는 데이터만 추출한다.
select id, generation, parent_id from cte where not id in (select distinct parent_id #여기서 distinct는 크게 상관 없다. from ecoli_data where parent_id is not null)
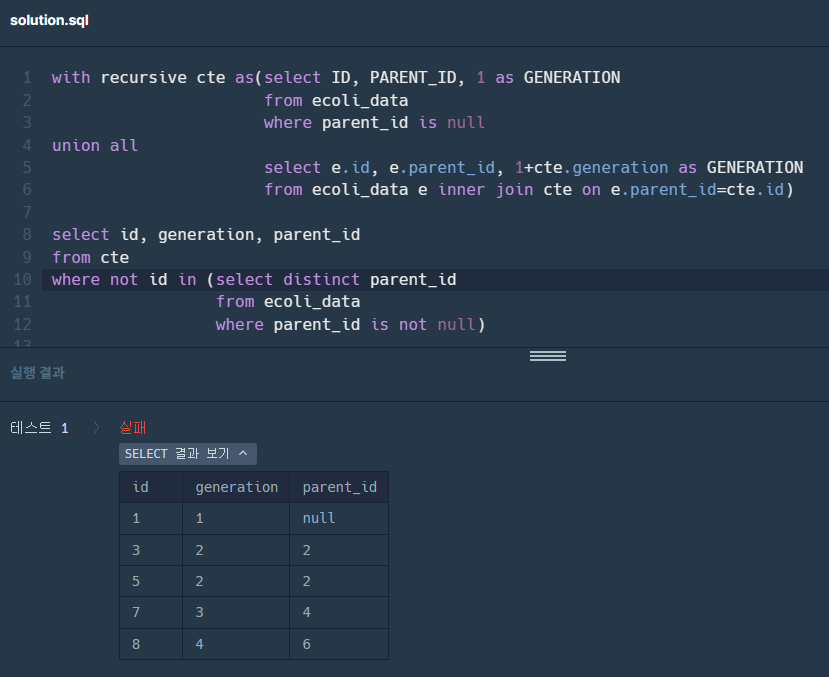
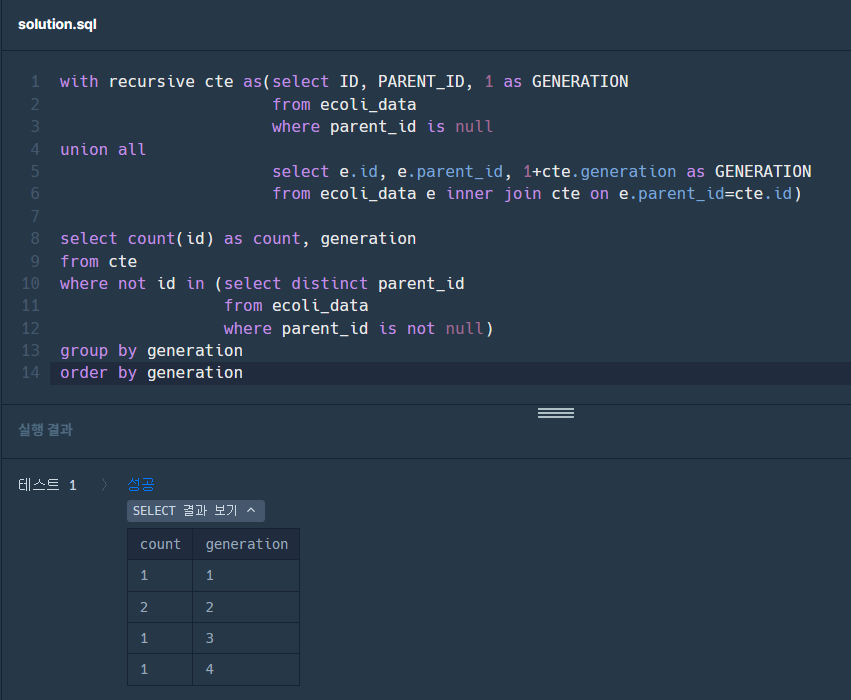
3-2. 각각의 parent_id별로 없는 id를 추출하여 generation별로 count하고, 오름차순으로 정리한다.
select count(id), generation from cte where not id in (select distinct parent_id #여기서 distinct는 count때문에 해야한다. from ecoli_data where parent_id is not null) group by generation order by generation;
Programmers 기준, Lv.5 수준의 SQL 코딩 테스트 문제인 만큼, 굉장히 까다롭고 복잡하지만,
이렇게 하나 하나 천천히 분리해서 이해하면 쉽게 다가 올 것이다.
이 문제를 풀면서 recursive와 with를 처음 접해봤는데,
음.. 이해한 것 같다!

First time, Last time, Every time.