오늘도 나라방 출근 완료!
가 보 자 고!!
<4주차 강의 요약>
4주차 강의에서는 subquery와 join의 이론을 학습하고 직접 실습해보았다.
-subquery-
: (a+b)*2 와 같은 수식 처럼 괄호를 지정하고자 할때 subquery문을 사용한다. 즉, ( )를 사용하여 코드를 묶어 주는 것이다.
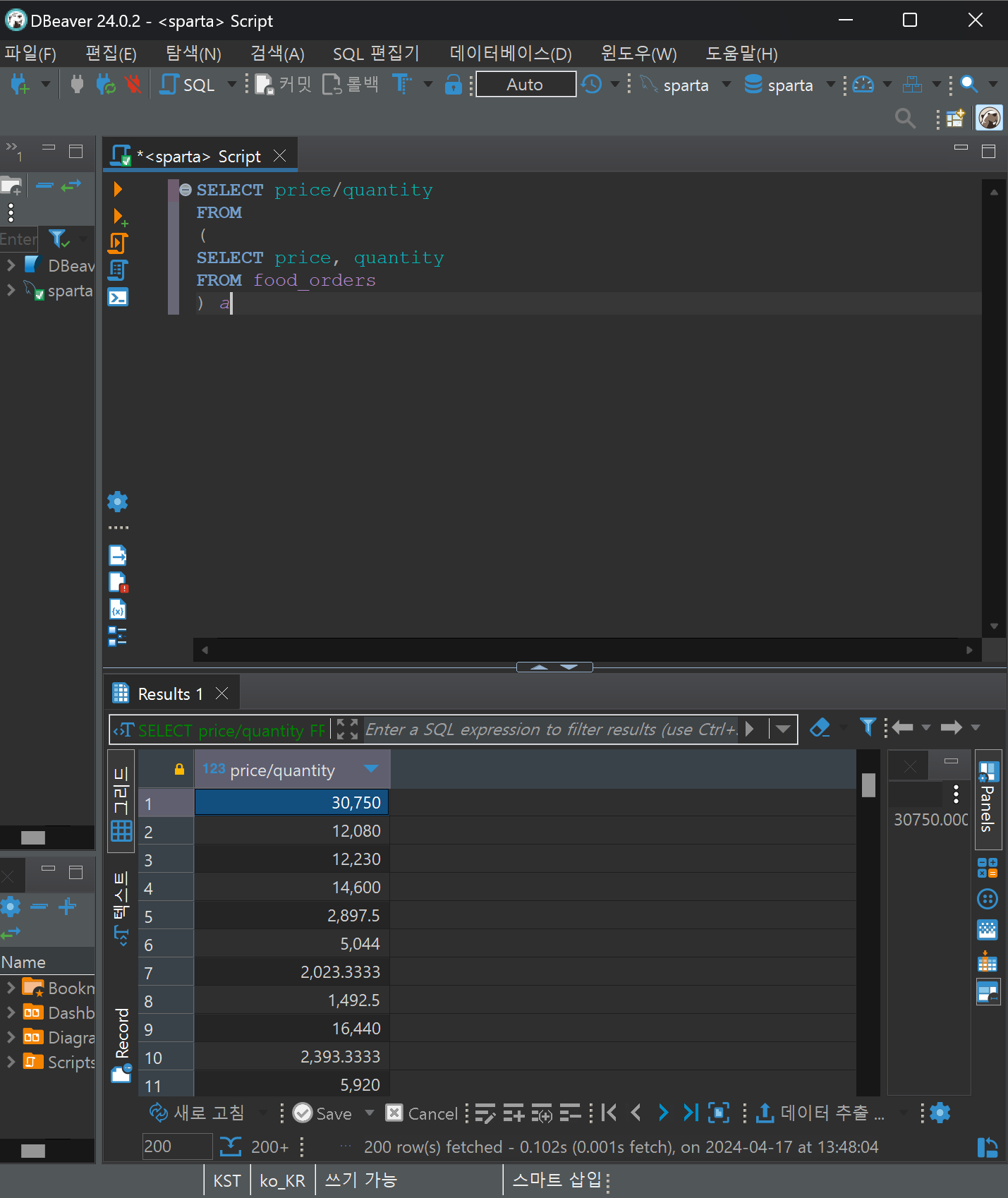
마지막의 a는 임의로 이름을 지정한 것이다.
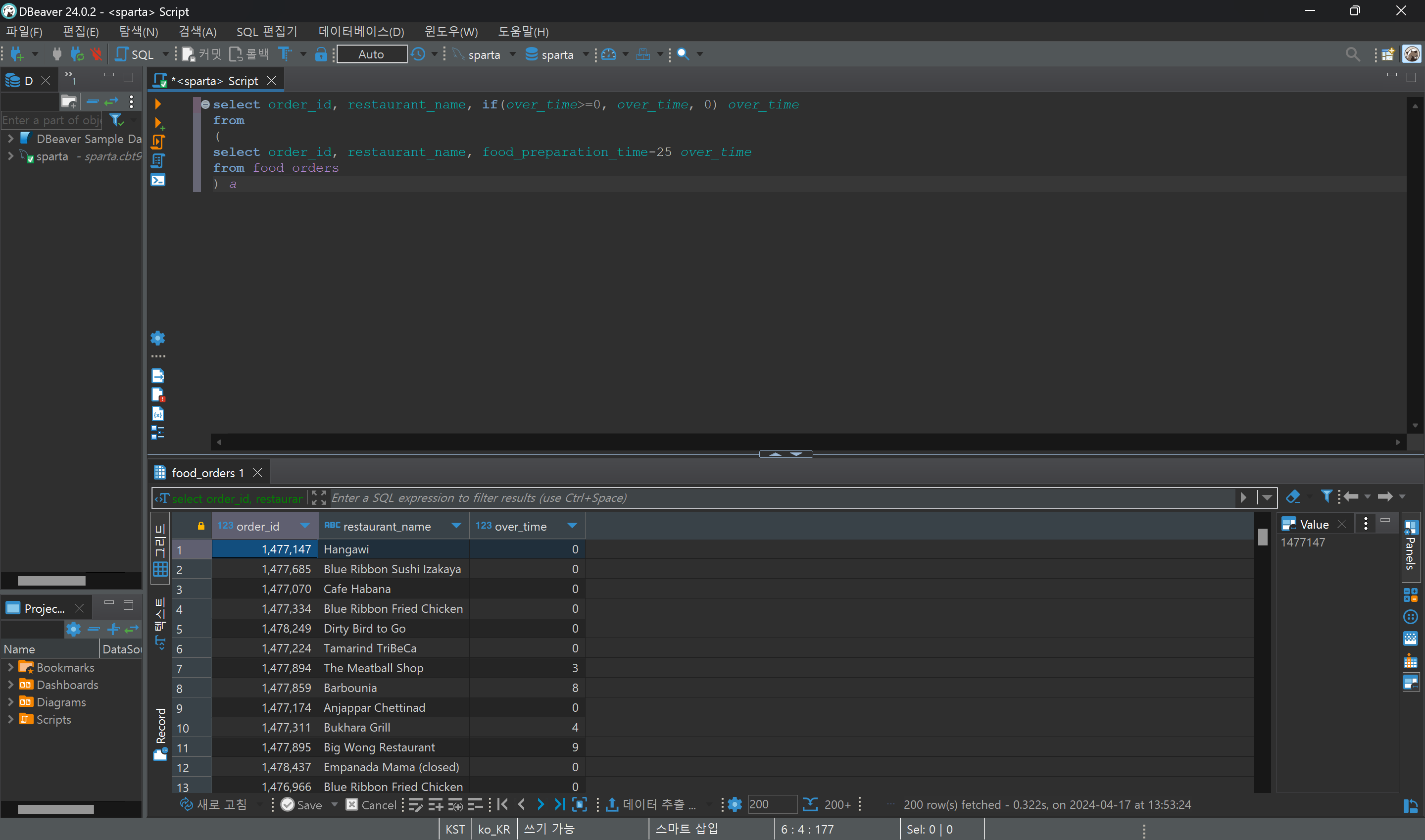
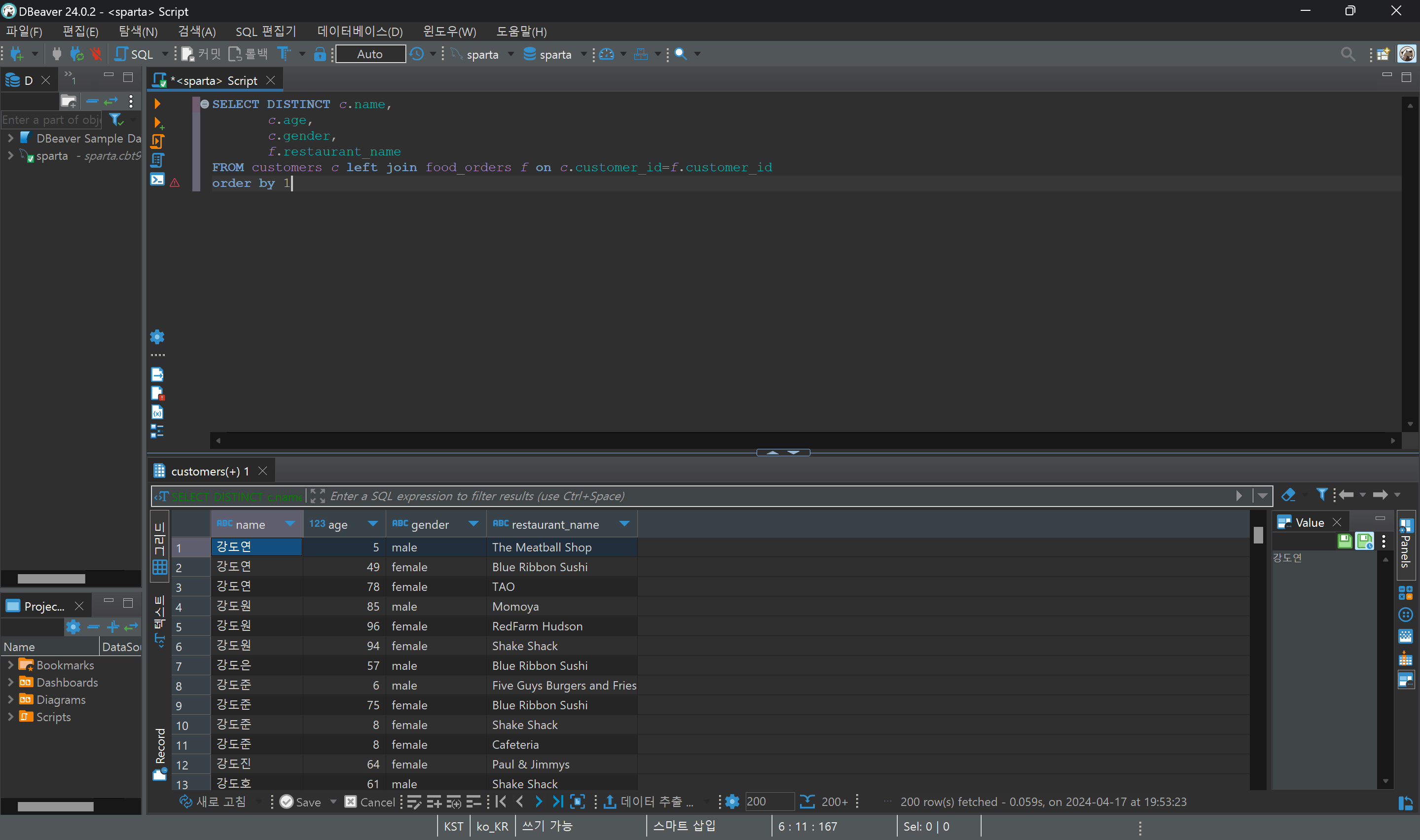
- 배달 초과된 시간을 구하기 위해서 subquery를 사용한 예시이다.
1) 준비시간 - 25분을 'over time'이라고 정의한다.
2) 주문자 ID, 식당 이름, over time을 보여줘.
3) 근데 over time이 0보다 크면 over time 이라고 표시하고, 아니면 그냥 0이라고 표시해줘.
- 만약 subquery를 사용하지 않는다면, over time값에 -가 등장하게 된다.
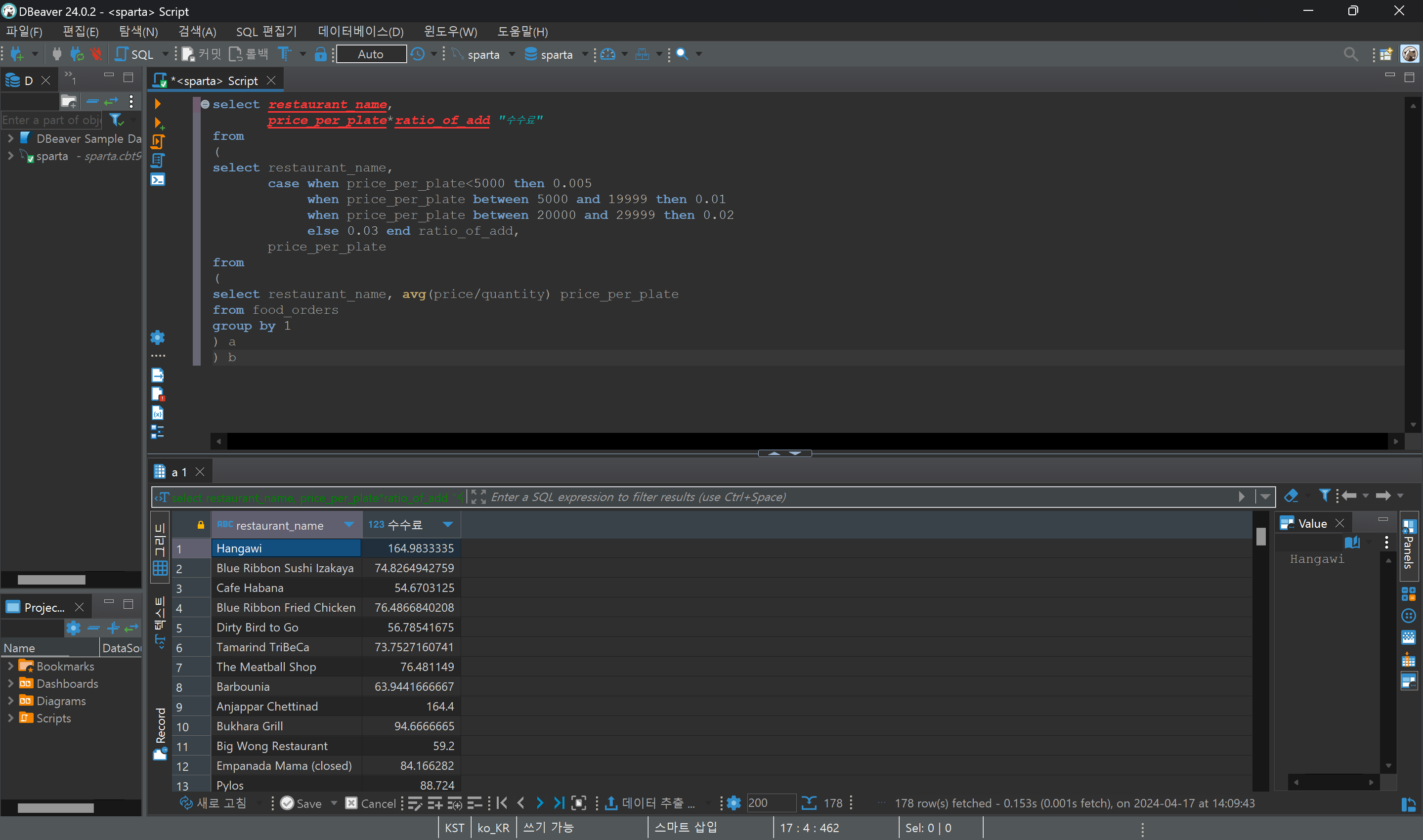
subquery문을 해석할 땐, 가장 안에 있는 괄호부터 파악하기!
1) price_per_plate 라는 이름으로 단가를 구한 뒤,
2) 정해진 수수료 구간에 따라 case when을 사용하여 ratio_of_add를 구한다.
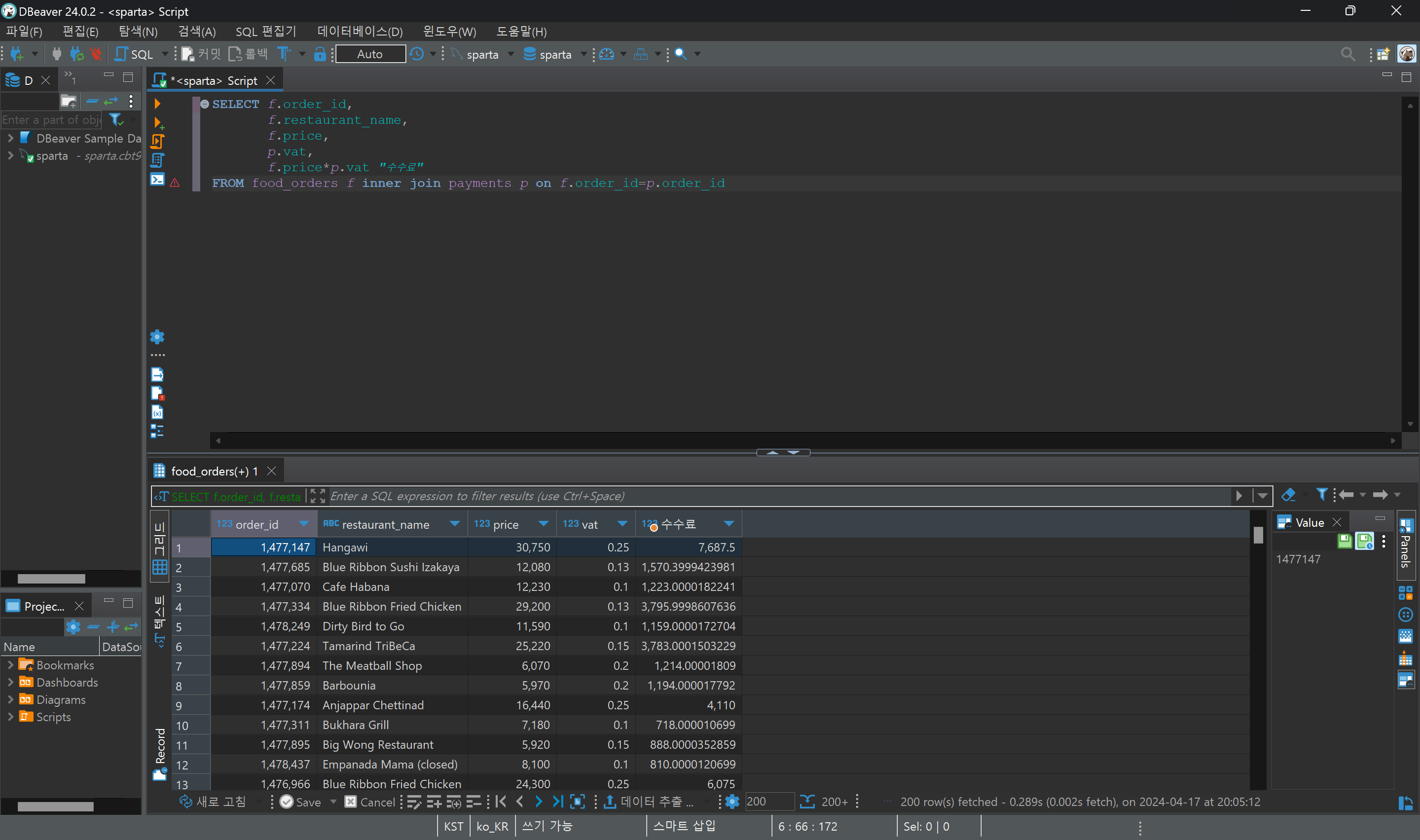
3) price_per_plate와 ratio_of_add를 곱하여 "수수료"라고 컬럼을 생성하고
4) 식당 이름과 함께 결과값을 보여줘.
[예시 문제]
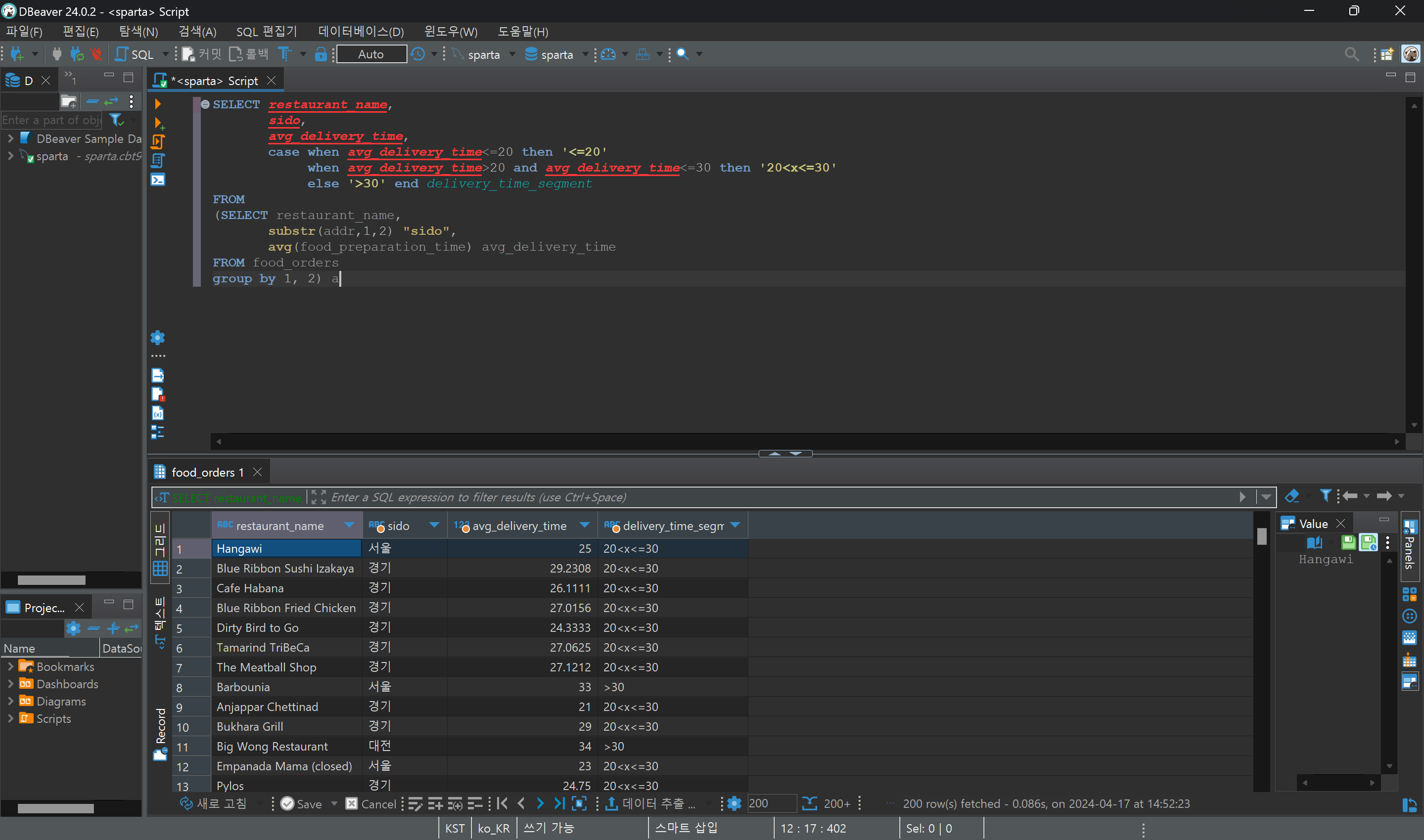
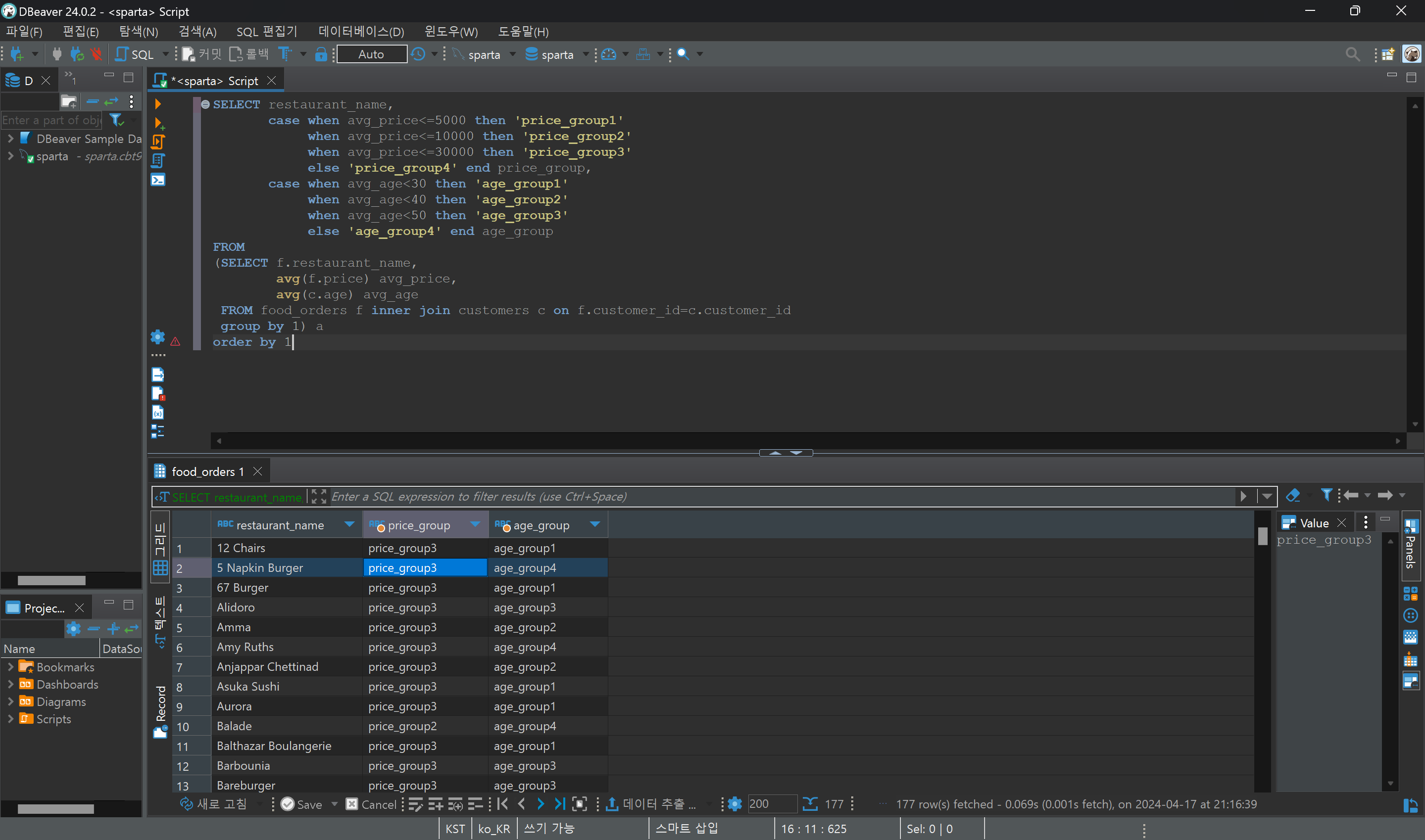
1. 음식점의 지역과 평균 배달 시간으로 segmentation하기
- 이름이 중복되는 식당들이 있으므로 group by 1, 2를 통해 구분한다.
- 지역명을 두글자까지만 추출하기 위해 substr을 사용한다.
- 배달 시간의 평균을 먼저 구한 뒤, 평균값으로 segmentation하기 위해서 subquery를 사용한다.
[예시 문제]
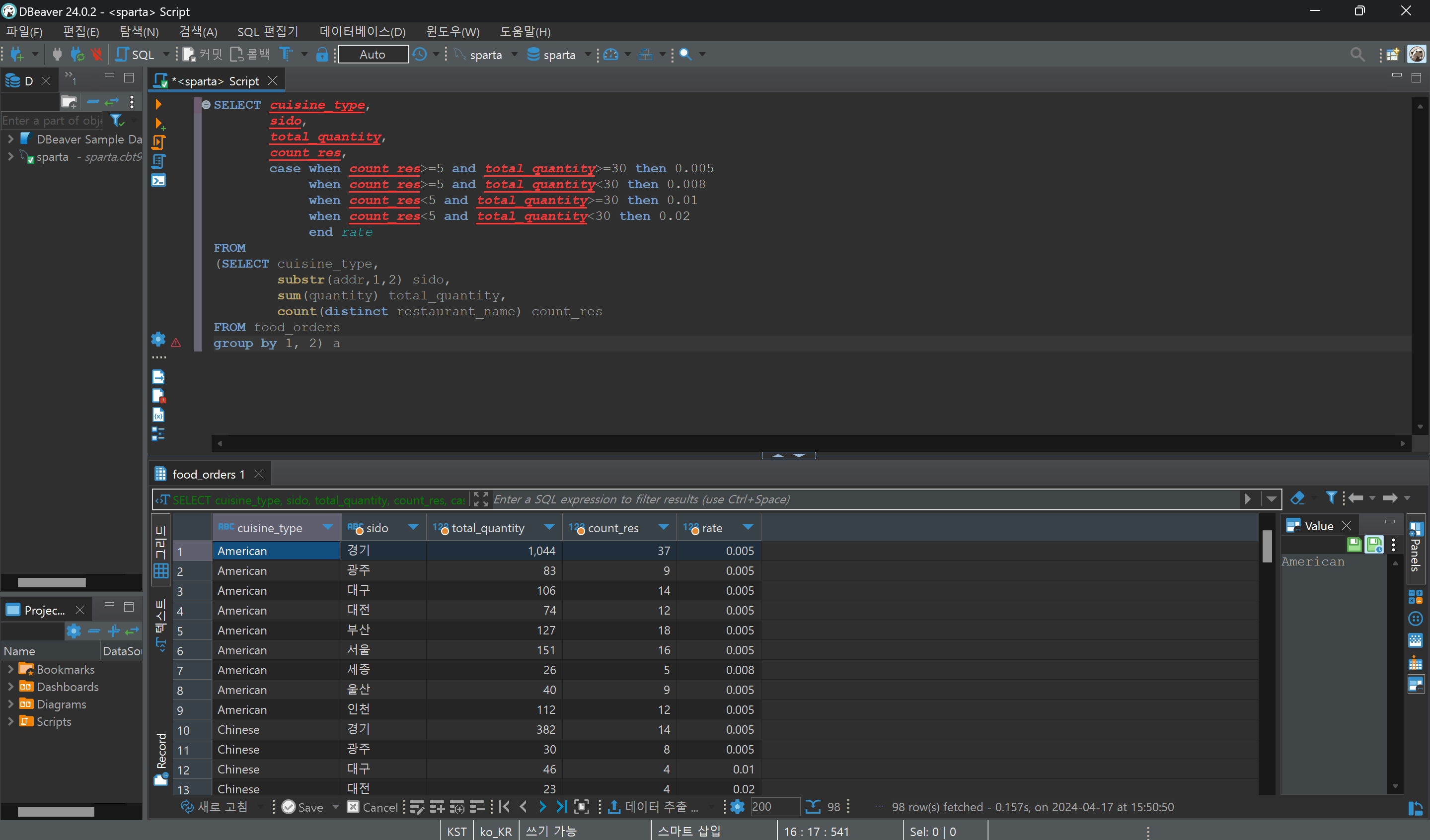
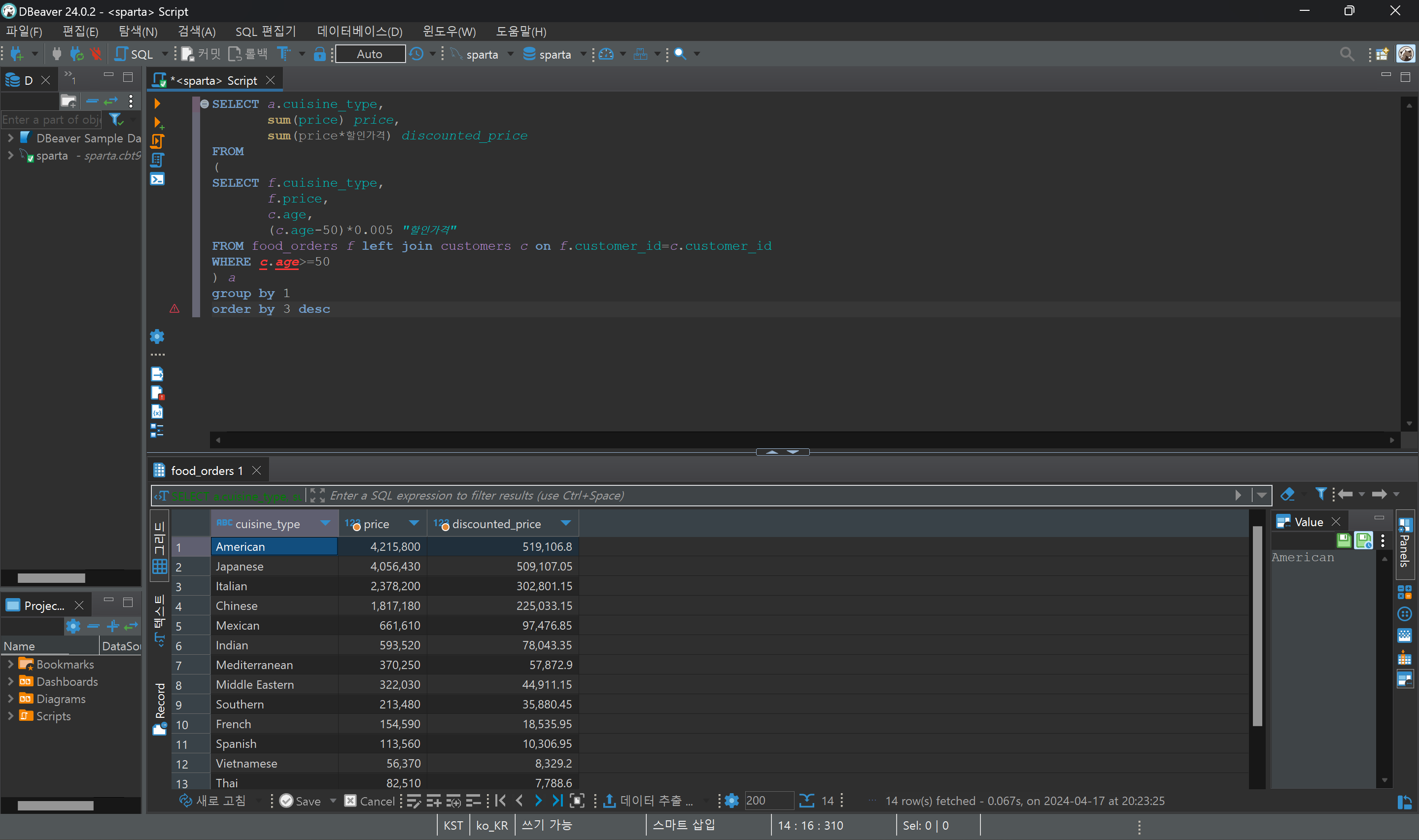
2. 음식 타입별 지역별 총 주문수량과 음식점 수를 연산하고, 주문수량과 음식점수 별 수수료율 산정하기
음식점수 5개 이상, 주문수 30개 이상 = 수수료 0.05%
음식점수 5개 이상, 주문수 30개 미만 = 수수료 0.08%
음식점수 5개 미만, 주문수 30개 이상 = 수수료 1%
음식점수 5개 미만, 주문수 30개 미만 = 수수료 2%
- 총 주문수량을 연산하기 위해 sum을 사용한다.
- 음식점수를 알기위해 count(distint restaurant_name) 을 사용한다.
❗주의사항❗
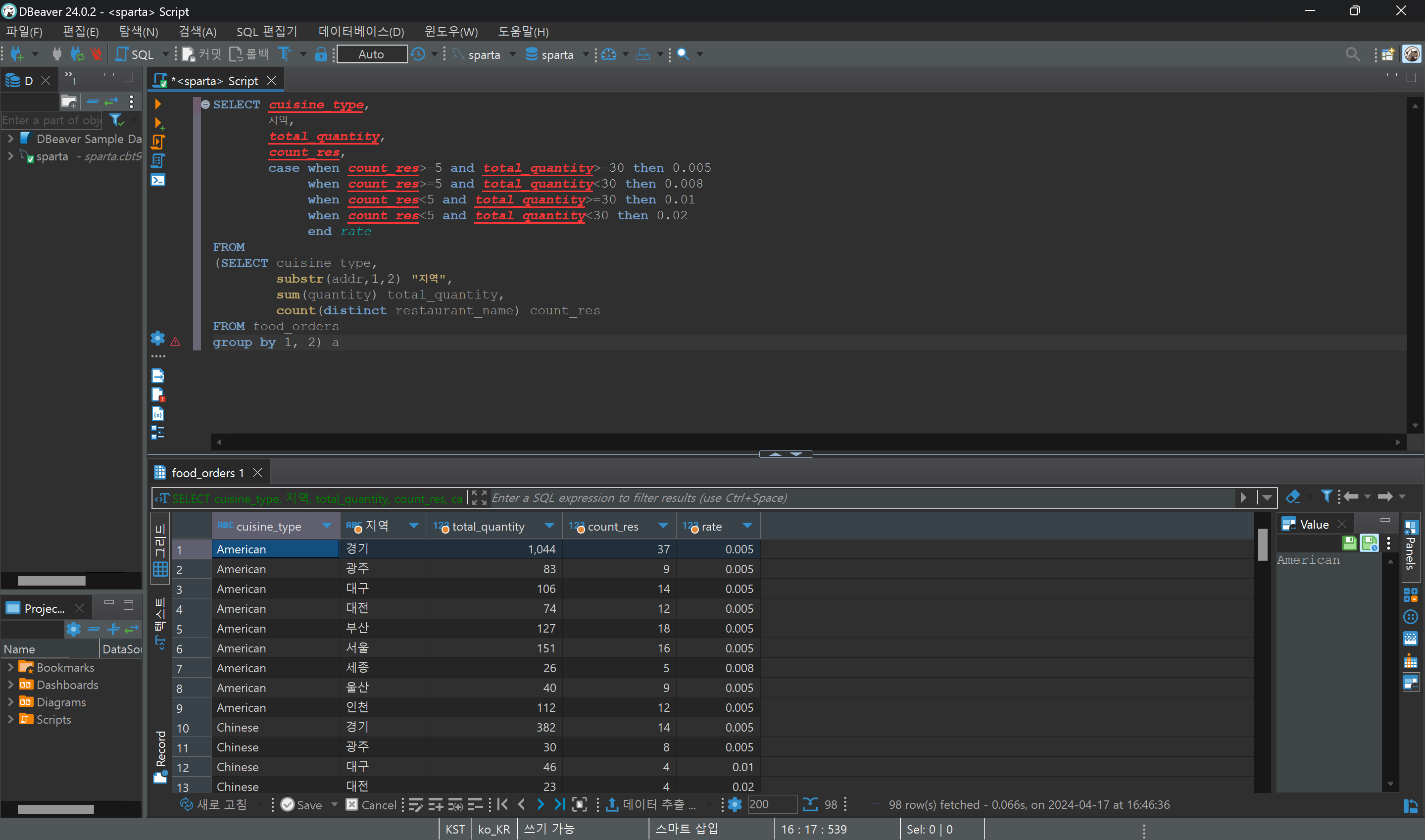
1. sido를 end rate 아래에 작성하면 subquery에 속하게 된다.
2. sido를 지역으로 변경하고 싶을때 substr(addr, 1, 2) "지역"을 사용한다면 컬럼명만 설정된다. 하지만 상단의 SELECT에 "지역"을 사용한다면 컬럼 속의 모든 string 값을 다 지역으로 변경해달라는 뜻이다.
3. 아래에서 "지역"을 통해 컬럼명을 설정하였기때문에 위에는 지역 으로 사용하면 된다.
[예시 문제]
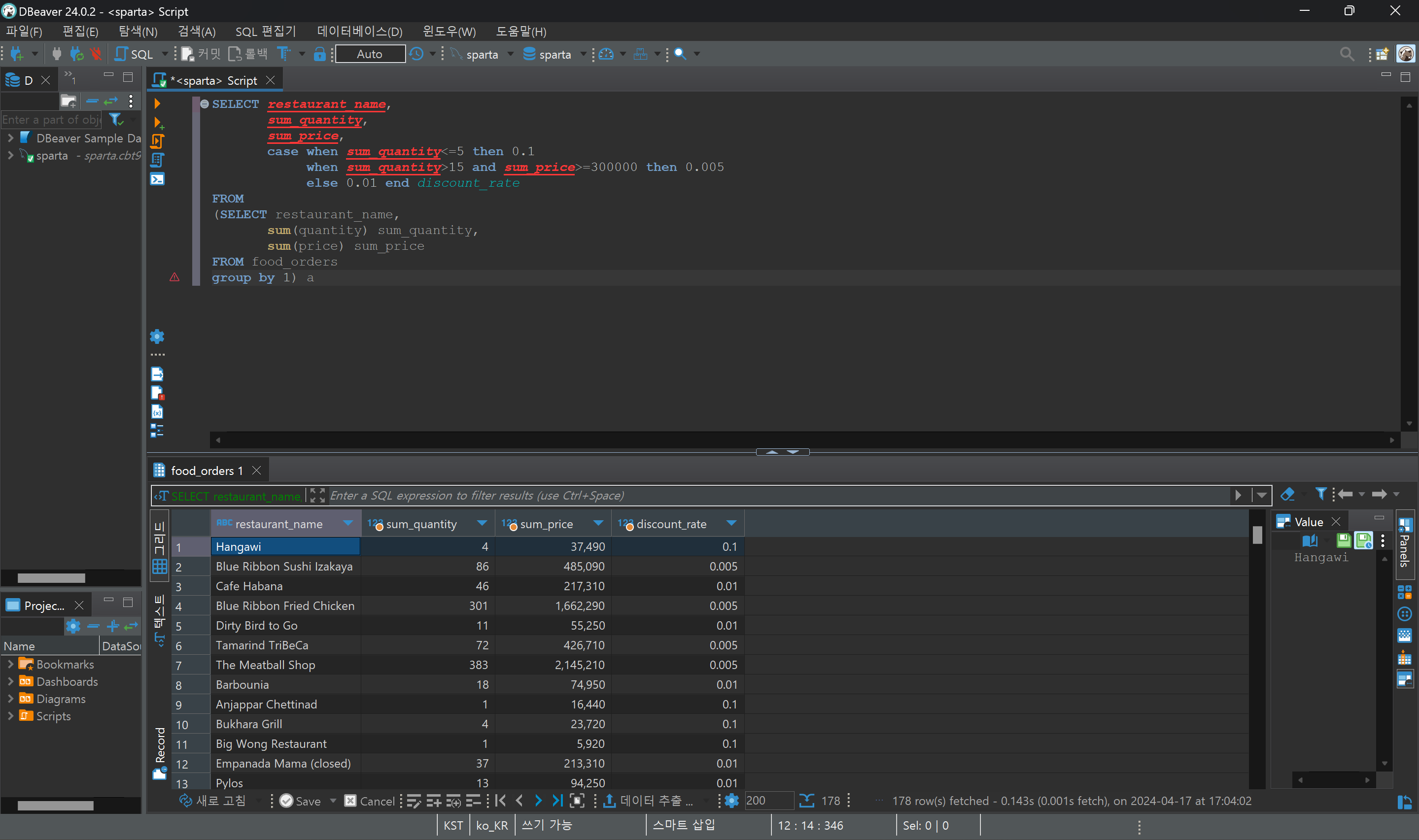
3. 음식점의 총 주문수량과 주문 금액을 연산하고, 주문 수량을 기반으로 수수료 할인율 구하기
수량이 5개 이하 = 10%
수량이 15개 초과, 총 주문금액이 300000 이상 = 0.5%
이외에는 일괄 1%
-join-
: 필요한 데이터가 여러 테이블에 흩어져 있는 경우 데이터를 불러올 떄 사용한다.

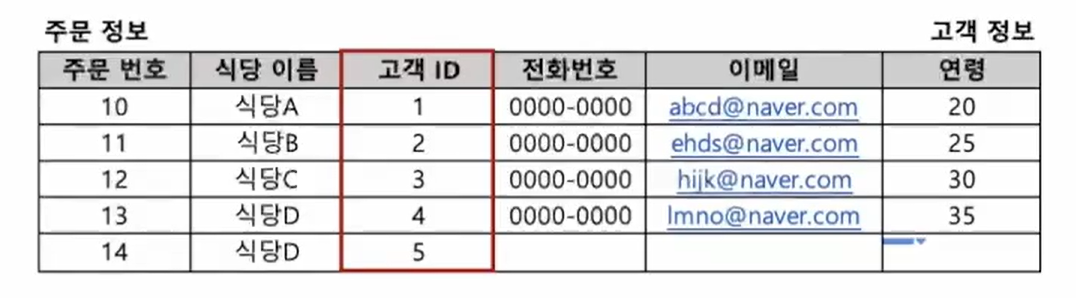
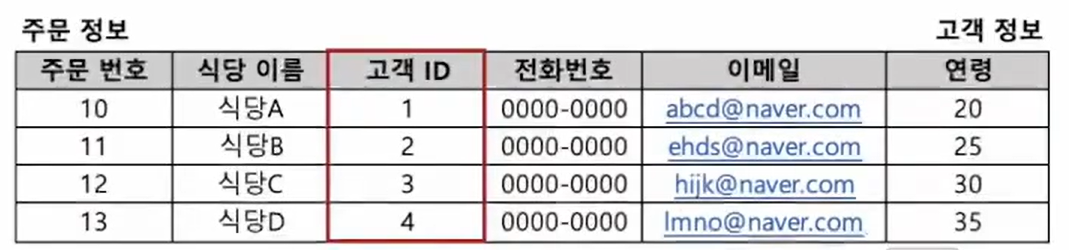
- left join : 공통 컬럼(키값)을 기준으로, 하나의 테이블 값이 없더라도 모두 조회해줘
즉, A와 B의 원하는 컬럼을 합치되, A에 속한 컬럼들만 합쳐줘.
고객ID 5와 같이 A에만 속하는 값을 제외하진 않지만, B의 데이터를 조회하진 않는다.
SELECT 조회 할 컬럼
FROM 테이블a a left join 테이블b b on a.공통컬럼명=b.공통컬럼명
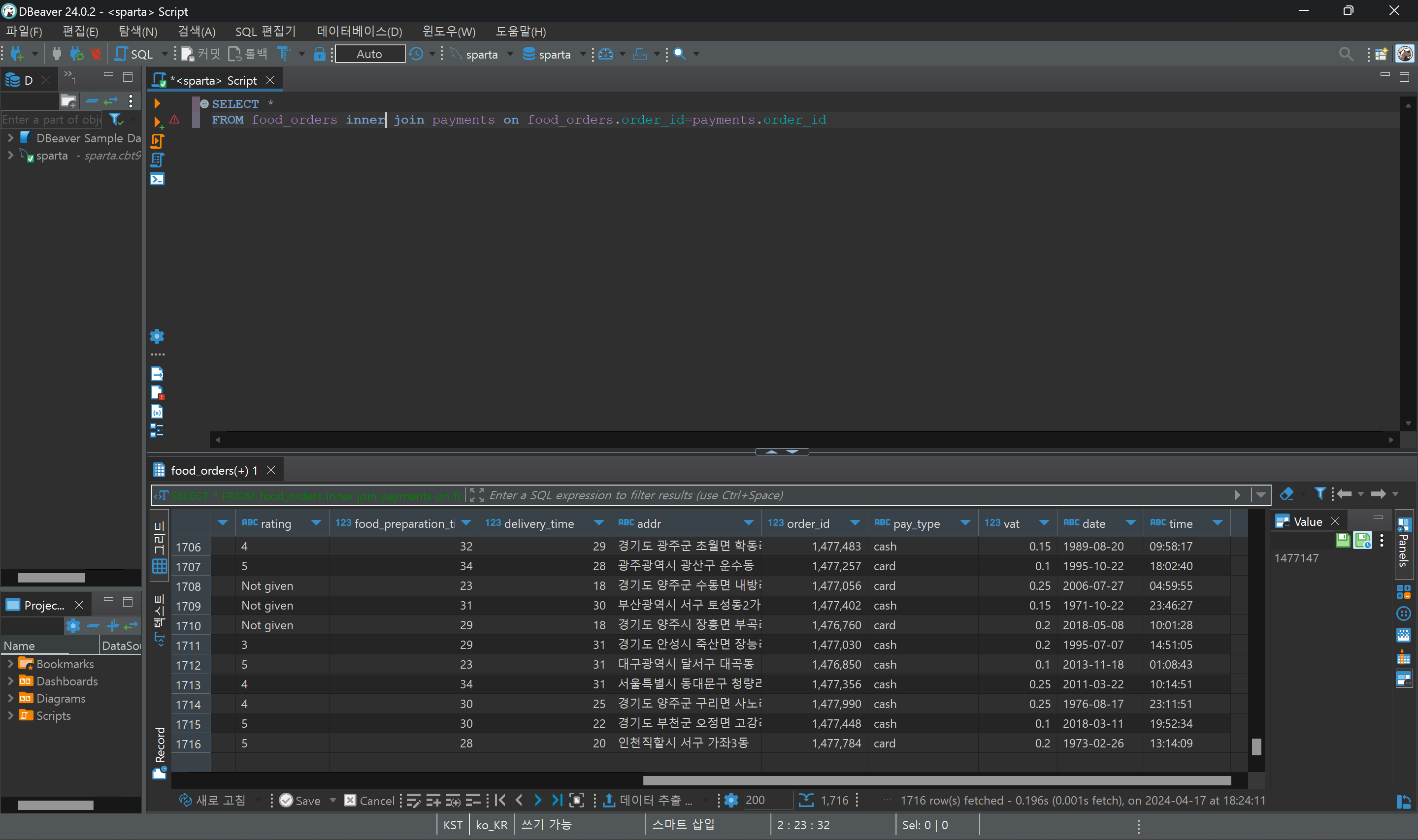
- inner join : 공통 컬럼(키값)만 불러와줘
즉, A와 B 모두에 속하는 값만 조회한다.
고객ID 5는 A에만 속하므로 제외한다.
SELECT 조회 할 컬럼
FROM 테이블a a inner join 테이블b b on a.공통컬럼명=b.공통컬럼명
💡Tip
1. join을 사용할 때 테이블명의 별칭을 정할 수 있다.
2. 공통 컬럼의 컬럼명이 다른 경우에도 a.name=b.이름 으로 사용할 수 있다.
3. 필터링을 할땐 순서대로 WHERE 절을 사용하면 된다.
4. 결과값에서 중복을 제거하기 위해서는 distinct를 사용하면 된다.
5. join으로 묶어준다면, 두 테이블에서 데이터를 연산할 수 있다.
6. subquery, group by, order by, 사칙연산 등 사용 가능하다.
[3주차 강의 문제]
- 식당별 평균 음식 주문 금액과 주문자의 평균 연령을 기반으로 Segmentation 하기
- 평균 음식 주문 금액 기준 : 5,000 / 10,000 / 30,000 / 30,000 초과
- 평균 연령 : ~ 20대 / 30대 / 40대 / 50대 이상
+) 후기
강의를 들으면서 결과값이 왜 그렇게 나오는지는 이해하지만,
어떤 원리로 그런 결과가 나오고,
어떤 이유로 그런 코드를 적용시켜야 하는지가 궁금했다.
팀원분들께 여쭤보기도 하고, 튜터님께도 여쭤보면서 SQL을 더 깊게 이해해가고 있는 것 같다.
코딩을 배우면 배울수록 왜 '컴퓨터 언어'라고 불리는지 알게 되는 것 같다.
어렵기도 한데.. 실행시켰을 때 정확한 값이 도출되는 것을 보면서 희열을 느낀다.
내일도 화이팅!
