Instruction Tuning 공부의 목적으로...
기본적으로 instruction tuning은 instruction과 입력을 넣으면 원하는 출력이 나오게 하도록 하는 학습 방식이다. 다양한 instruction+input & output pair를 주고 학습시킴으로써 이 지시를 모델이 이해하도록 하는 게 주 목적. 그래서 다양한 instruction을 필요로 한다. 결국 우리가 원하는 건 하나의 task에만 tuning된 fine-tuning 모델이 아니라, instruction을 이해하기 때문에 새로운 instruction에도 찰떡같이 동작하는 모델이기 때문이다.
- FLAN (https://arxiv.org/pdf/2210.11416.pdf)이 이 분야에서는 유명한 논문. 2024.01 기준으로 1천회 넘게 인용되었다. Google 논문임.
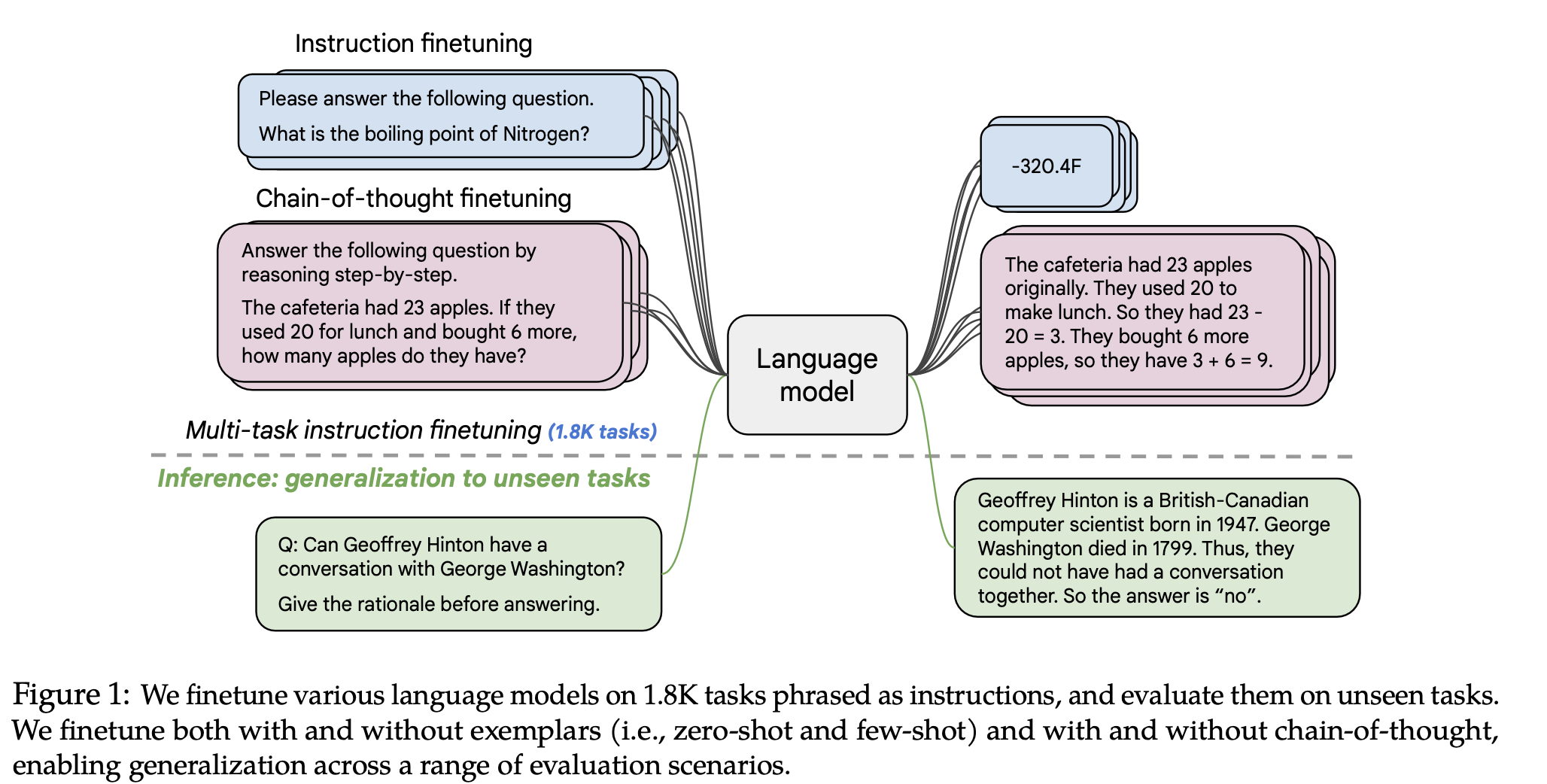
- 특기할만한 점이 무엇이 있는가.
- 태스크를 늘려보았고, (태스크 종류는? 종류의 다양성이 중요할까, 아니면 숫자가 늘어나는 게 중요한 걸까?)
- 모델 사이즈를 크게 가져가보았고, (모델 사이즈와 어떤 연관이 있을까?)
- CoT를 적용해보았다. (이게 어떤 영향이 있었을까?!)
1. 인트로
인트로에서 떠먹여주는 정보에 의하면
- 모델 사이즈가 커질 수록, 태스크 개수가 많아질 수록 더더 잘함!!
- CoT를 넣어야 reasoning을 잘한다.
그래서 1.8k 태스크에 대해 540B짜리 Flan-PaLM을 구웠다고 함. (540B라니.. 역시 자본인가)
그렇게 구운 Flan-PaLM은 그냥 PaLM보다 성능이 좋다고 함. (당연한 거 아닐까?)
그리고 자비롭게도 T5에도 구워주셨다: Flan-T5가 그렇게 탄생. 80M부터 11B까지.
2. Flan Fine-tuning
그래서 Flan은 어떻게 학습하는 건데? 아니 애초에 무엇의 약자이지? Fintuning Language Models의 약자입니다.
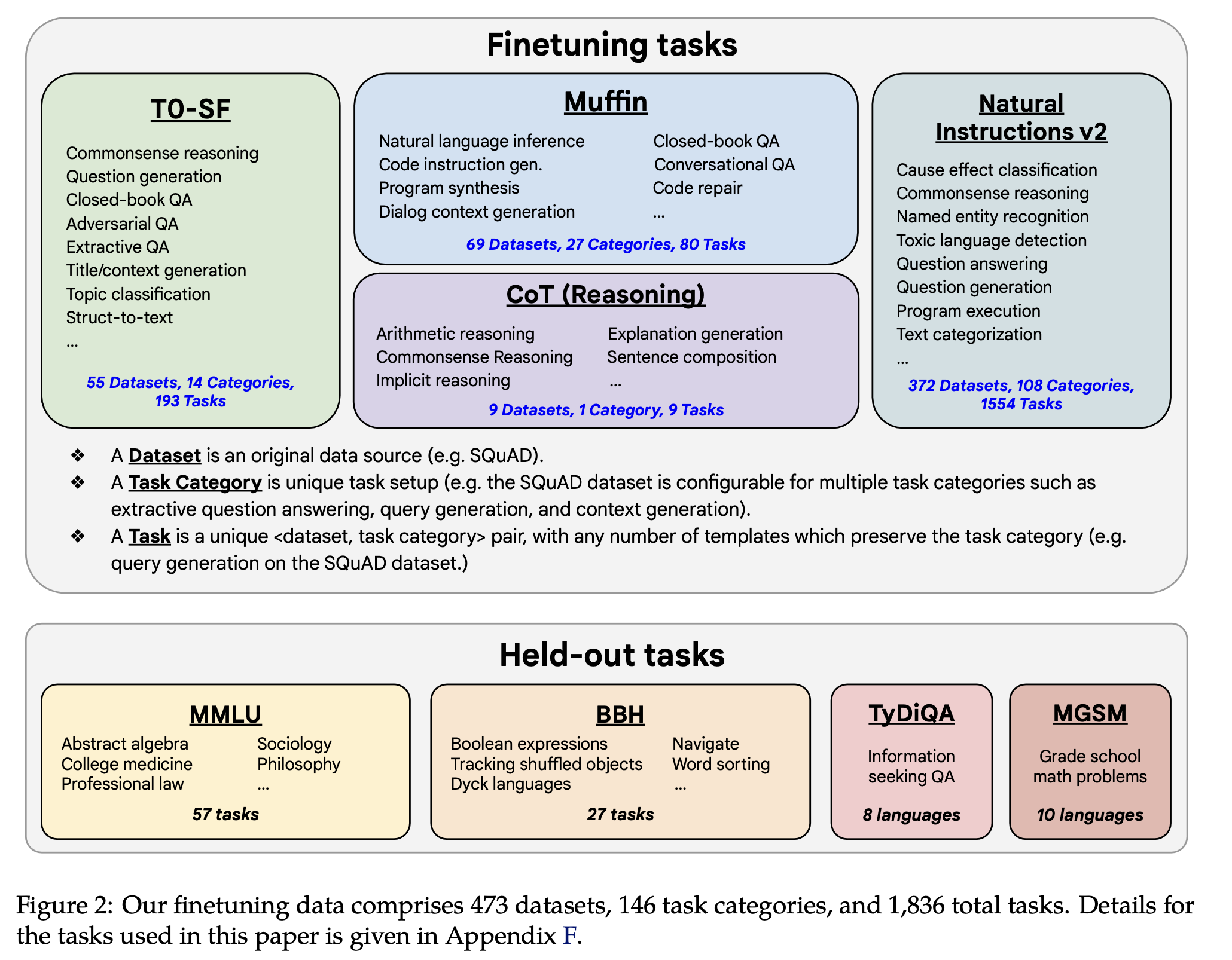
데이터
가장 중요하겠쥬?!
기존 논문들을 보면 task는 많으면 많을 수록 좋다길래 prior work의 데이터를 싹 갖다 썼습니다. T0-SF (193 tasks), Muffin (80 Tasks), CoT (9 Tasks), NIV2 (1,554 Tasks). 도합 1,836 tasks.
- T0-SF는 T0 데이터셋에서 muffin과 겹쳐지는 데이터셋을 뺀 거. T0 데이터셋은 P3라고도 하는 것 같으니 참고. (T0 논문: https://arxiv.org/pdf/2110.08207.pdf)
CoT는 arithmetic reasoning, multi-hop reasoning, natural language inference로 구성되어 있다고 함. 저자들이 CoT를 활용한 reasoning 능력을 중요하게 생각한듯함.
어떻게 학습한 거지?
각 모델별 자세한 hyperparameters는 논문 (2.2) 참조*
어떻게 평가할 거임??
MMLU (시험 문제. 수학, 역사, 법, 의학 등), BBH (Big-Bench 종류), TyDiQA (QA인데 이제 multilingual을 곁들인), MSGM (수학문제인데 이것도 multilingual을 곁들인).
MMLU & BBH: Direct, CoT 두가지 방식 (같은 걸 두 방식으로 푼 게 아니라, 데이터셋이 나뉨)
TyDiQA: Direct
MSGM: CoT
For MMLU and BBH, we evaluate both the ability to directly predict the answer via direct prompting, where the model directly gives the answer (Brown et al., 2020; Srivastava et al., 2022), as well as via chain-of-thought (CoT) prompting, where the model must provide a reasoning chain before giving the final answer (Wei et al., 2022b).
few-shot을 주고 평가. (five-shot for MMLU, three-shot for BBH, one-shot for TyDiQA, and 8-shot for MGSM)
평가 결과는 normalized average로 report.
3. 모델 크기와 태스크 개수가 성능에 미치는 영향은?
이게 궁금해서 해봤다고 함.
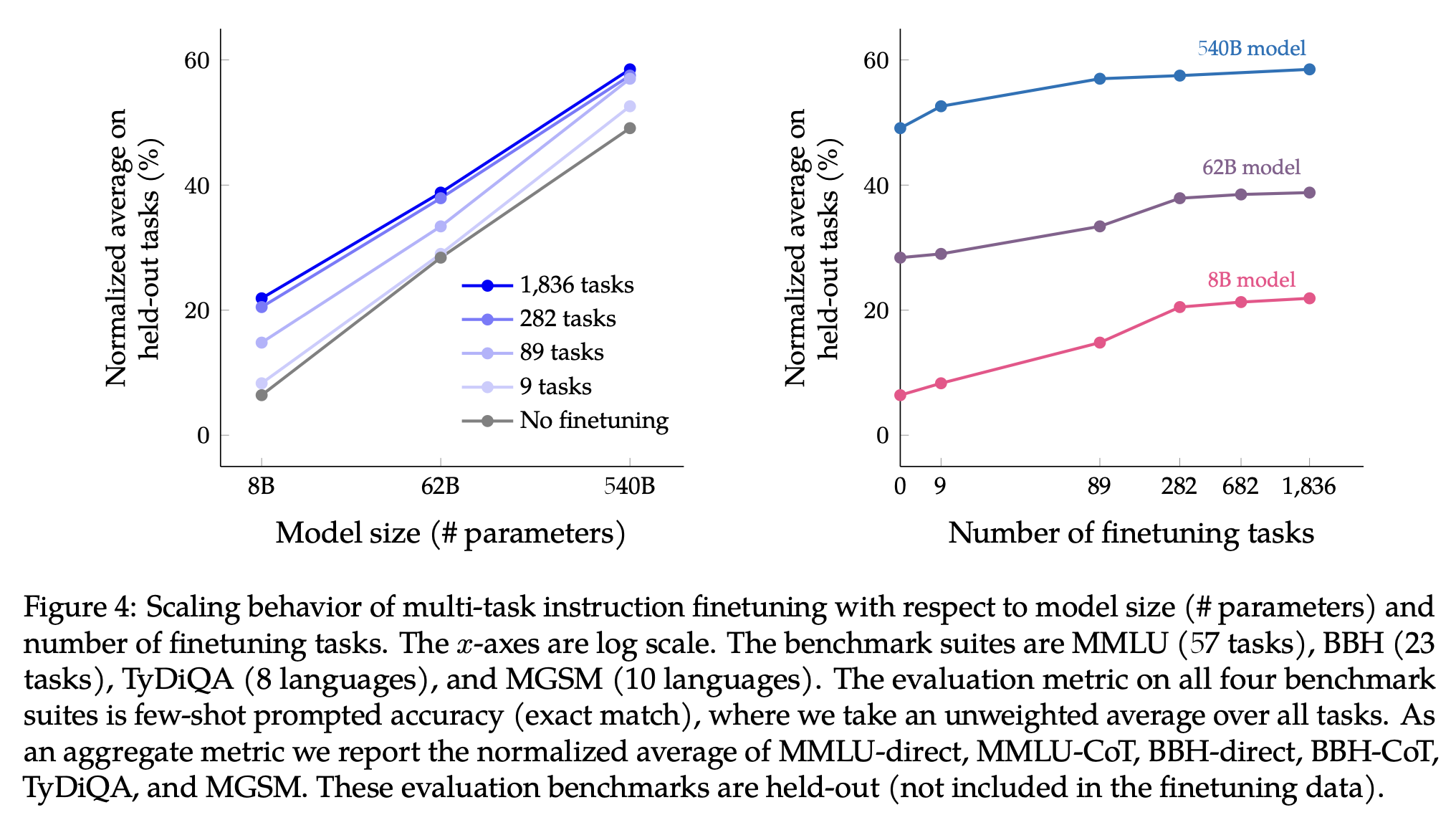
인트로에서 말했듯 모델 사이즈가 커질 수록 성능은 좋아지고, 또 더 많은 태스크에 학습했을 수록 성능이 좋아진다. 근데 1.8k랑 282 태스크의 성능 갭이 크지 않네?
- 여기에 대해 저자들은 두 가지 설명이 있다고 밝혔는데, 첫째로는 추가된 1.5k 태스크가 별로 diverse하지 않았을 가능성, 그래서 모델이 뭔가 새로운 지식을 습득하지 못했을 가능성. 두번째로는 instruction fine-tuning이 기존에 사전학습으로 갖고 있던 지식을 다르게 표현하는 방법을 배우는 건데, 그 태스크 관점에서는 282개의 태스크로도 충분해서 그 이상은 이제 큰 도움이 안 된다는 설명.
- 음,, 어떤 가설이 맞을까? 당연히 1번이라고 생각했는데 2번도 꽤나 설득력이 있다. 그래도 아무래도 1번 아닐까? held-out task가 충분히 다양했더라면 1번처럼 1.8k로 학습한 것이 더 보여질 여지가 있는 거... 아닐까? 학습 태스크의 다양성도 중요하겠지만, 그것을 얼마나 잘 측정할 것인가도 중요하니까.
4. CoT Fine-tuning
인트로에서 두 번째로 나왔듯 CoT가 얼마나 효과적인가? 를 탐구한 섹션.
CoT를 통해 reasoning과 zero-shot 성능이 향상될 수 있다는 사실을 보여줌. 단 9개의 CoT 데이터셋만으로..!
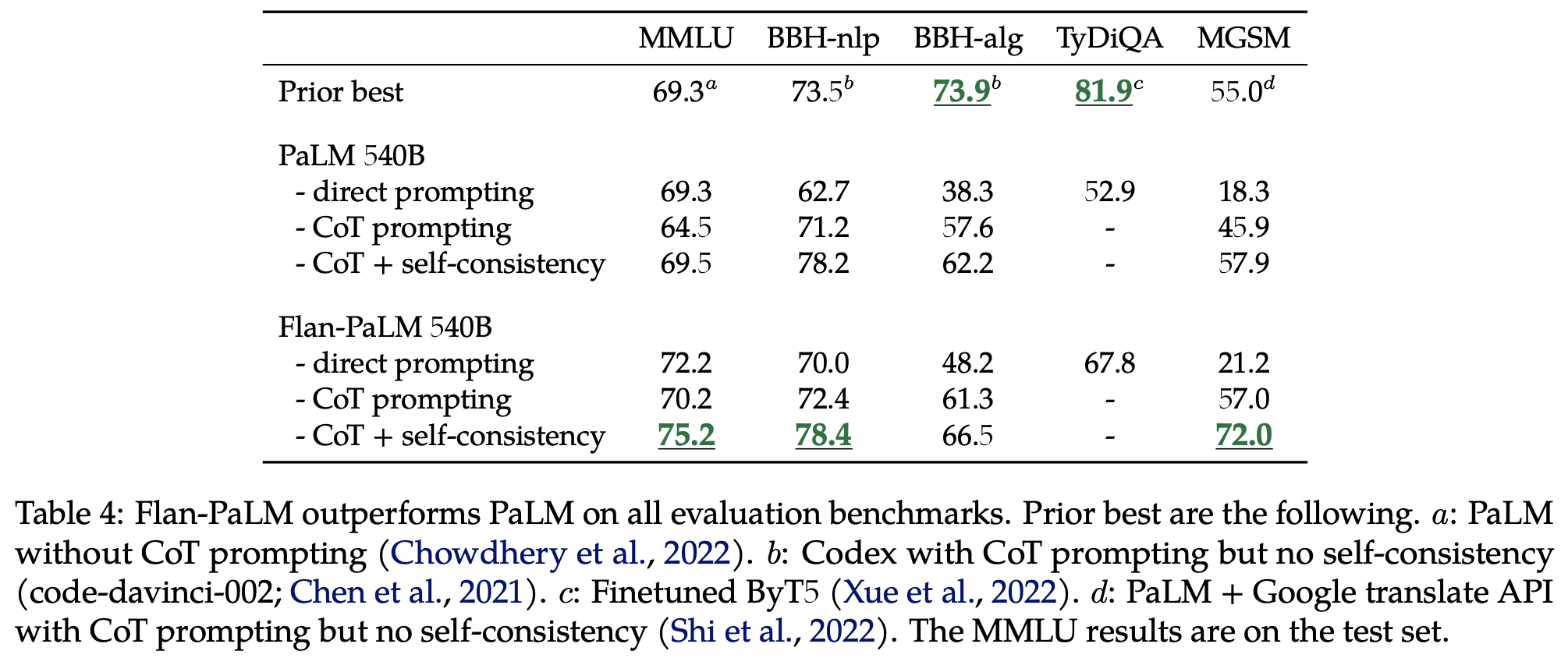
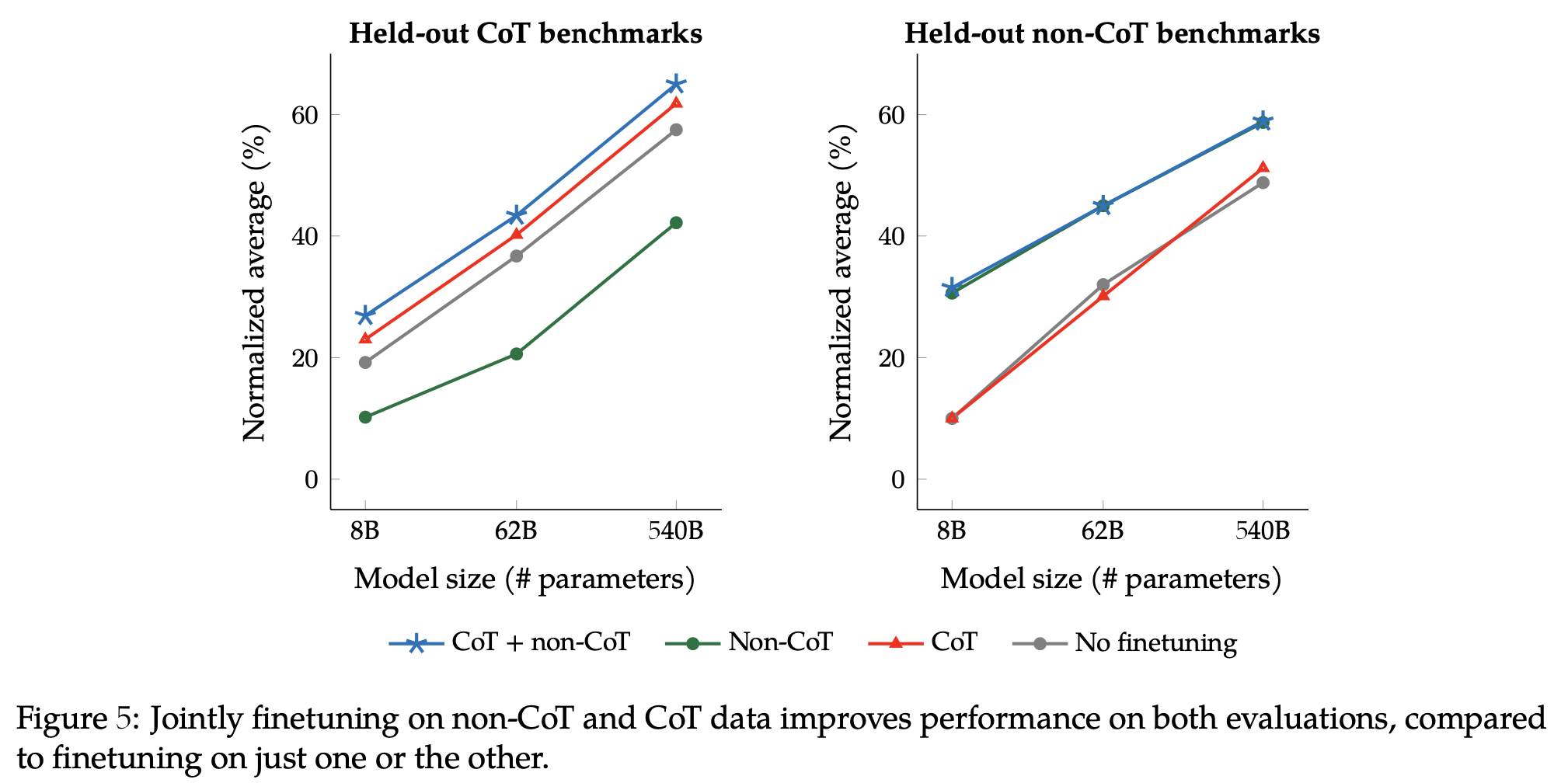
표랑 그래프 꼼꼼히 읽고 이해해야 하는데 조금 귀찮아서... 스킵...
우선 CoT가 필요하다... 정도로 ㅇㅋ하고 넘어감
5. 다 합치면
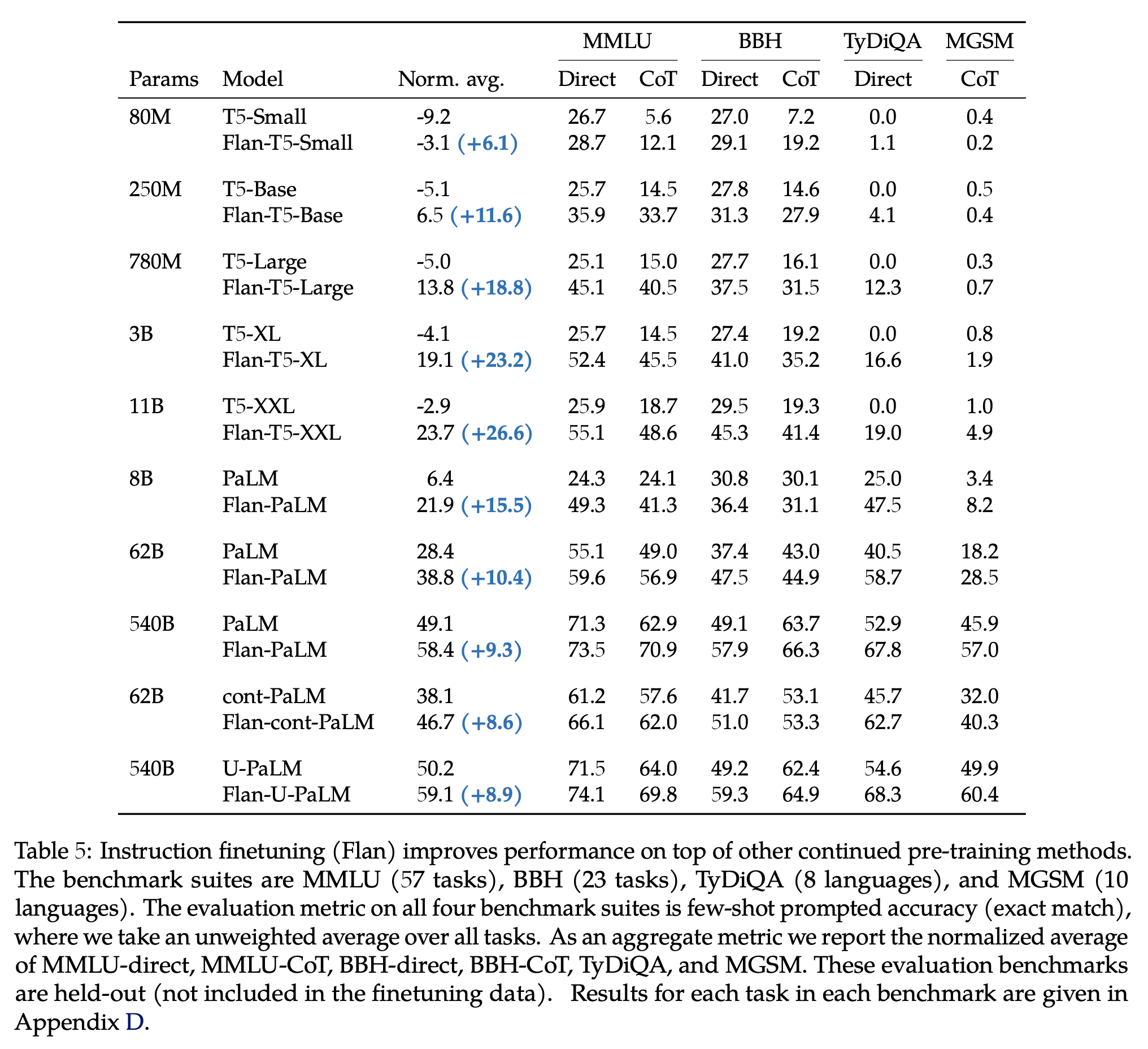
이 Norm. avg.는 뭔지, 왜 -부터 시작하는지... 잘 모르겠으나... 우선 Flan을 쓴게 일관적으로 더 나아짐. 특히 T5는 multi-lingual feature가 없었어서 T5가 다른 모델보다 더 flan의 덕을 봤다.
6. Open-ended generation
에 대해 human preference를 측정했는데 (PaLM vs. Flan-PaLM) Flan-PaLM이 79% of time 선택됨.
7. 디스커션
- Scaling curves for instruction finetuning.
- CoT finetuning is critical for reasoning abilities.
- Instruction finetuning generalizes across models.
- Instruction finetuning improves usability and mitigates some potential harms.
- Instruction finetuning is relatively compute-efficient.
이렇게 FLAN 논문을 살펴보았다. 논문 본문의 내용은 사실 많지 않고 간단.
FLAN에서 사용한 데이터셋, FLAN의 발견만 기억하면 됨.
부록이 아주 빵빵하니 부록도 보면 좋긴 하겠다. FAQ와 실제 qualitative examples, bias&harms와 디테일한 실험 결과들이 있다.
