Transformer에 대해 알아보자
대부분의 내용, 이미지는
Seq2Seq: https://wikidocs.net/24996
Attention: https://wikidocs.net/22893
에서 참고하였습니다.
일단 그 시초인 Seq2Seq에서 출발해 보자
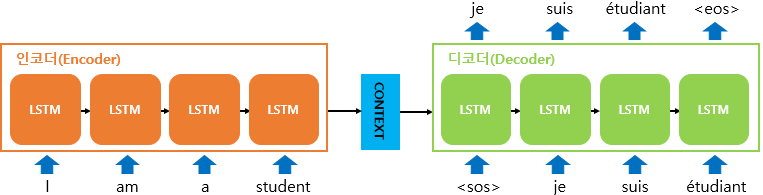
Seq2Seq
Encoder - Decoder 구조를 가지고 그 내부에 RNN block들이 들어있다.
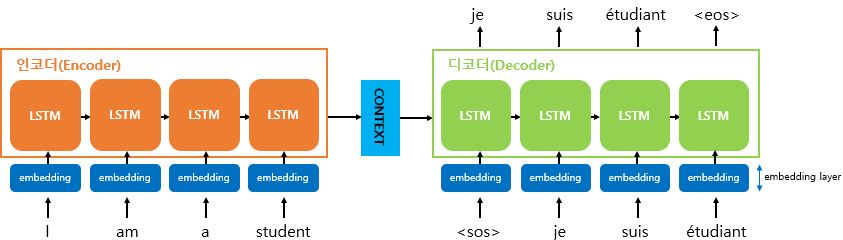
- 입력 문장의 각 토큰의 임베딩을 뽑아 인코더 각 RNN block의 input으로 사용한다.
- 인코더의 마지막 RNN block의 출력이
Context Vector이 디코더의 첫번째 input이 된다. <'sos'>: Start of Sentence,Context vector부터 시작하여, 이전 RNN block에서 나온 출력 벡터와 결과 단어의 임베딩을 현재 RNN block의 input으로 사용한다.
결과 단어는 출력 벡터를 Dense layer, Softmax layer를 거쳐 결정된다.
Seq2Seq의 문제점:
- 벡터 크기를 고정시켜 두고, 단어에 해당하는 모든 정보를 압축하려니 정보가 손실된다.
- RNN의 특성상 나타나는
기울기 소실문제가 나타나서 문장이 길어지면 성능이 떨어진다.
Attention
Attention으로 개선한다.
디코더에서 각 단어를 예측할 때 인코더의 input들을 참조할 건데, 굳이 처음부터 끝까지 다 볼 필요 없이 중요한 부분만 집중(Attention)해서 보자.
Attention(Q, K, V) = Attention Value
함수 모양으로 보면 간단히 이렇다. 여기서,
Query(Q): 디코더에서 현재 시점의 출력 벡터,
Key(K): 인코더의 각 Block
Value(V): 인코더 각 Block의 값
Dot-product Attention
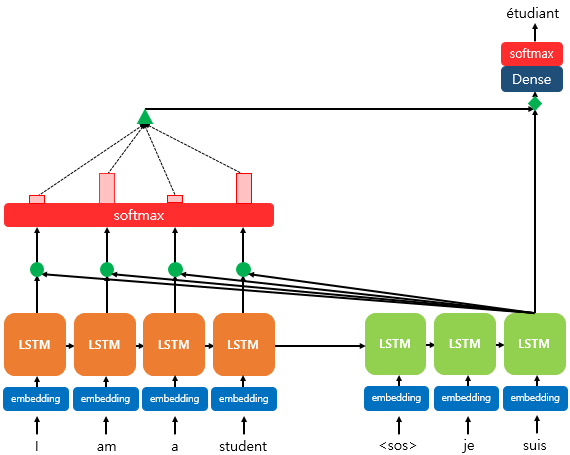
Attention score를 구한다
인코더의 각 출력 벡터를 이라 하고,
그리고 디코더의 구하려는 시점의 출력 벡터를 라 하자.
내적으로 값들을 각각 구해서 Softmax 함수에 집어 넣으면 인코더의 Input 각 단어들과 얼마나 유사한지의 확률 값을 얻을 수 있다.
최종 Attention score
로 얻어진다.
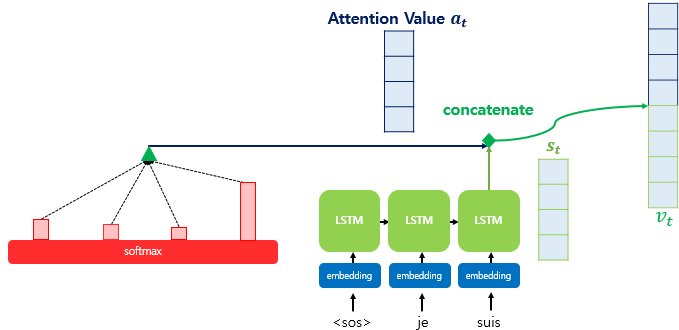
나온 와 를 concatenate해서 Weight matrix 와 계산을 통해 출력층(최종 Softmax layer) 의 입력을 계산한다.
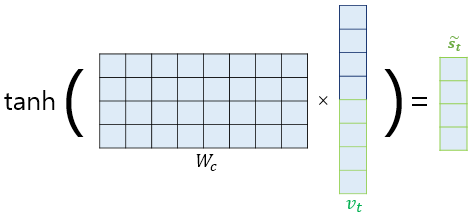
끝으로 다른 Weight matrix 와 다시 계산하고 Softmax layer에 넣어 준다.
이렇게 디코더에서 t 시점의 최종 단어를 예측할 수 있다.
