Apache-Flink 입문 입니다. 간단하게 환경 세팅 후, Flink 예제 하나 정도 살펴봤습니다.
Flink의 공식 문서와 패스트캠퍼스 강의 참고했습니다.
https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/learn-flink/overview/
Flink 소개
Flink 는 오픈소스 스트림 프로세싱 프레임워크 이다. 스트림 프로세싱이라 하면, 말 그대로 '흐르는' 데이터를 처리하는 프레임워크인데, 지속적으로 들어오는 데이터, 즉 실시간으로 계속해서 들어오는 데이터를 처리하는 프레임워크이다. (실시간이 주 목적인데, 배치 프로세싱도 가능하다.)
Flink의 주요한 특징(장점)은 세 가지 정도 있다.
- ⭐️ Fault-tolerance → 시스템 장애 시, 장애 직전으로 돌아가서 다시 시작 가능 (checkpoint 설정으로)
- ⭐️ Rescalability → 실행 도중에 리소스 추가 가능
- ⭐️ Exactly-once → 데이터가 한 번 실행된다는 것을 보장
Flink 는 실시간 데이터를 '처리' 하는 프레임워크이기 때문에, 데이터를 어디를 통해서 어떻게 받아오고, 처리한 데이터를 어디로 어떻게 보내겠다 등등의 '처리' 외의 부수적인 상황에 대해서는 통제하거나, 관여하지 않는다.
즉, 실시간 데이터를 처리하는 Pipeline 에만 온전히 집중할 수 있도록 해준다.
Flink DataStream Flow
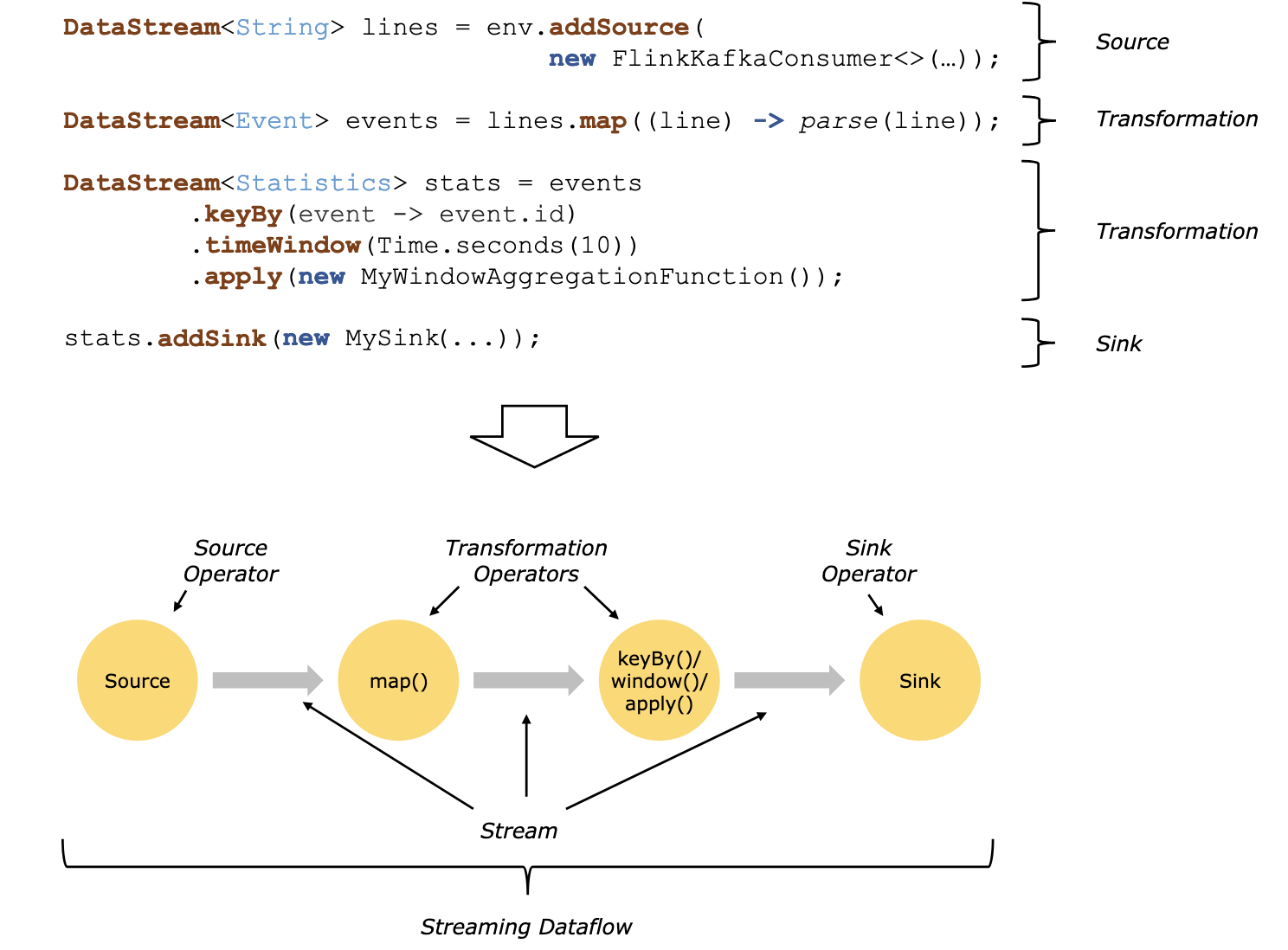
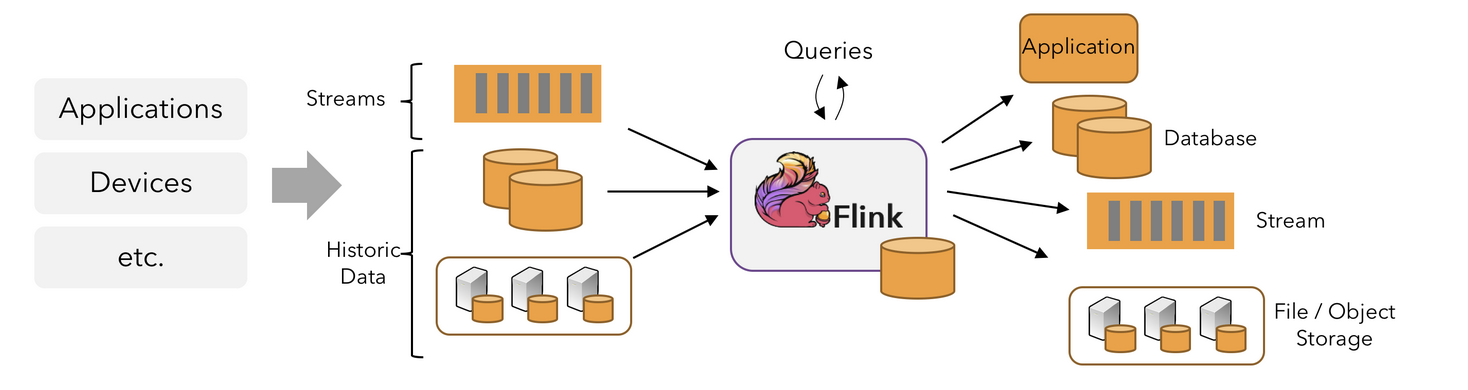
그림 두 장이면 끝이다. Flink는 3개 Step의 매우 단순한 DataStream Flow를 갖는다.
- Source
- 데이터를 어디서 가져올 것인가? 데이터 출처
- Transformation
- 데이터를 어떻게 처리할 것인가? -> 여기에 데이터를 처리하는 주요 로직이 담기게 된다.
- Sink
- 처리한 데이터를 어디로 보낼 것인가? 처리 완료된 데이터 저장소
(Fault-tolerance 에 대한 부분은 추후 Toy 프로젝트를 통해 알아보고자 한다.)
Apache-Flink 환경 세팅
세팅 전, JobManager와 TaskManager를 사용하게 되는데,
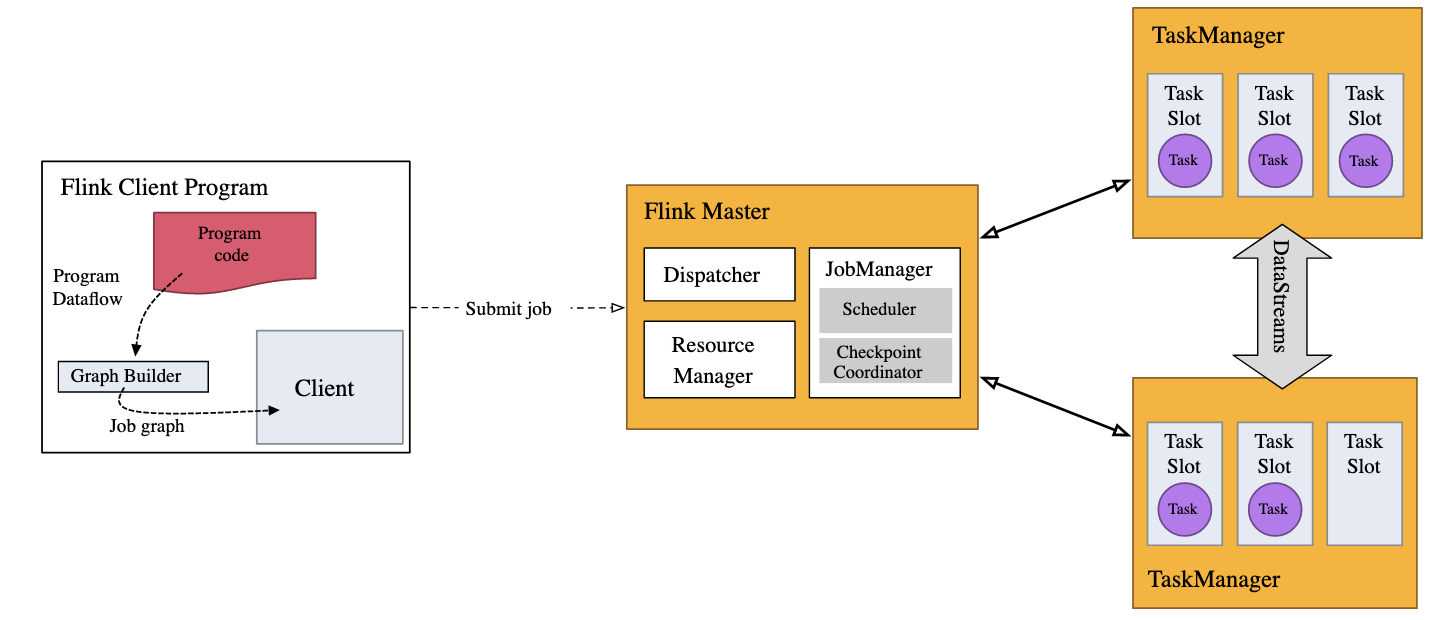
Flink는 기본적으로 parallel and distributed 하다. 이를 담당하는 애들이 JobManager와 TaskManager인데, TaskManager는 말 그대로 어떤 task slot 에서 task를 수행하는 역할을 하고, JobManager가 TaskManager에게 task들을 분배하는 역할을 한다.
docker 가 설치되어 있는 환경에서, (필자는 인텔맥북을 쓰고 있다.)
$ FLINK_PROPERTIES="jobmanager.rpc.address: jobmanager"
$ docker network create flink-network
$ docker run \
--rm \
--name=jobmanager \
--network flink-network \
--publish 8081:8081 \
--env FLINK_PROPERTIES="${FLINK_PROPERTIES}" \
flink:latest jobmanagerJobManager 를 launch 했다.
$ docker run \
--rm \
--name=taskmanager \
--network flink-network \
--env FLINK_PROPERTIES="${FLINK_PROPERTIES}" \
flink:latest taskmanager다음으로 TaskManager 를 launch 했다.
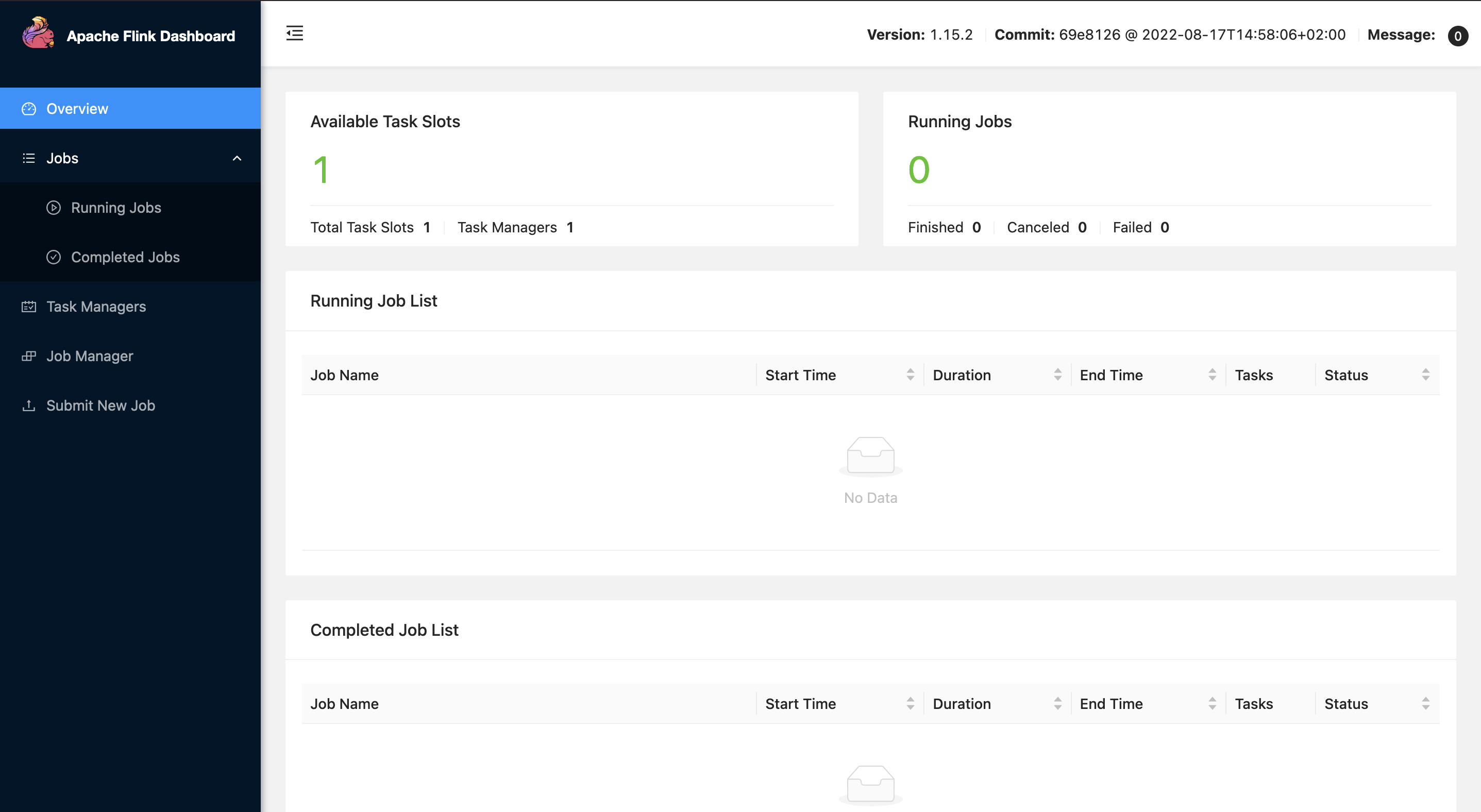
이렇게 로컬에서 기본적으로 Task Manager 1개를 가진 Flink 대시보드를 launch 할 수 있다.
