
스크립트 ?
💻 작업
1. 하위쿼리 : subquery
(sub query : 하위쿼리) - 반드시 괄호로 묶어야함
- 쿼리 안 쿼리 (select 안 select)
select userid, company, dept, pay,avg(pay) from company; -- x
--userid, company, dept, pay : 단일값 , avg(pay) : 다중값이므로
select round(avg(pay)) from company;
select userid, company, dept, pay,1782888 t_avg from company;
--내가 원하는 결과값을 얻기위해선 쿼리는 한개여야함 근데 지금은 2개임
select userid, company, dept, pay,
(select round(avg(pay))from company)t_avg from company; -- 데이터 정확 & 한번에 쿼리 실행 가능 - 그러나 같은 값이 전부 출력되므로 좋은 쿼리는 아님
--company 테이블에서 평균월급보다 적은 월급을 받는 고객정보
select round(avg(pay)) from company; --평균pay
select * from company
where pay < (select round(avg(pay)) from company); -- 262 rows
---------------------------------------------------
--현대자동차에 근무하는 고객정보
select * from company where company like '현대자동차%';
select USERID from company where company like '현대자동차%';
select * from CUSTOM
where userid in (select userid from company where company like '현대자동차%'); -- or을 대신하는 문자열 : in
-- ↓ (두개이상의 테이블 custom / company에서 가져오는 것이므로 호환가능)
-- 하위커리는 조인문과 100프로 호환됨
-- join문을 쓰는게 고급형
select a.*
from custom a, company b
where a.userid = b.userid
and company like '현대자동차%';
---------------------------------------------------
select * from sales; --특정 id별로 어떤 물건을 판매했는지
select userid,count(*) cnt from sales
group by userid --아이디 별 (group by + 컬럼명) 개수
having count(*) >= 4;
--4회이상 판매기록이 있는 고객들의 정보
select * from CUSTOM
where userid in (select userid from sales
group by userid
having count(*) >= 4);
-- ↓
--join (** 실무에서 많이 쓰임 - in line view(가상테이블))
select a.*,cnt
from custom a, (select userid, count(*) cnt from sales
group by userid having count(*) >= 4) b -- sales를 셀렉트하면서 통계화해서 변형된 것임 = 가상
where a.userid = b.userid;
-- 위에랑 같음
SELECT A.*,cnt
FROM CUSTOM A JOIN (SELECT USERID FROM SALES
GROUP BY USERID HAVING COUNT(*) >= 4) B
ON A.USERID = B.USERID;
2. any / all
https://carami.tistory.com/18 [출처 : carami's story 설명 참조]
any / all
-- any (or) : 무조건 범위값이 포함되어야함 / > any : 최소값보다 큰 데이터 , < any : 최대값보다 작은 데이터
-- aLL (and) : 범위값 포함 x / < all : 최대값보다 큰 데이터 / > all : 최소값보다 큰 데이터
-- min / max 보다는 any / or을 많이 사용함
--point 점수의 범위값 : 132,269
select point from custom where addr1 = '제주도' order by point;
select * from custom where point > any (select point from custom where addr1 = '제주도'); -- 최소값132 보다 큰 데이터
select * from custom where point > (select min(point) from custom where addr1 = '제주도');
select * from custom where point < any (select point from custom where addr1 = '제주도');-- 최대값269 보다 작은 데이터
select * from custom where point < (select max(point) from custom where addr1 = '제주도');
select * from custom where point > all (select point from custom where addr1 = '제주도'); -- 최대값269 보다 큰 데이터
select * from custom where point > (select max(point) from custom where addr1 = '제주도');
select * from custom where point < all (select point from custom where addr1 = '제주도'); -- 최소값132 보다 작은 데이터
select * from custom where point < (select min(point) from custom where addr1 = '제주도');
select min(point) from custom where addr1 = '제주도'; -- 132
-----------------------------------------------------------------
select point from custom where age>=70;
-----------------------------------------------------------------
select * from custom
where point > all (select point from custom where age>=70); -- 최대값보다 큰 데이터는 모든 정보 제공
-- 긍정 ** in = ' =any '
select * from CUSTOM where userid in (select userid from company where company like '현대자동차%'); -- or을 대신하는 문자열 : in
select * from CUSTOM where userid = any(select userid from company where company like '현대자동차%');
-- 부정 ** not in = ' <>all = not in '
select * from CUSTOM where userid not in (select userid from company where company like '현대자동차%'); -- 446 rows
select * from CUSTOM where userid <> all(select userid from company where company like '현대자동차%'); -- 446 rows
select * from CUSTOM where userid <> any(select userid from company where company like '현대자동차%'); -- 459 rows x
select * from custom where addr1 = '경기도' and age > 30;
select * from (select * from custom where addr1 = '경기도') a where age > 30; --테이블에 별칭 달때는 as쓰면 에러남2. join (in line view)
join(in line view)
- sales 테이블에서 userid별로 구매금액 합계 를 b라는 이름으로 table화 시키고 custom테이블(A)의 userid와 비교
select a.userid, username, addr1, b.합계금액 from custom a,
(select userid,count(*) ncount, sum(price) 합계금액 from sales
group by userid having sum(price)>=1000000) b
where a.userid = b.userid;
-------------------------------------------------------
--평균월급보다 많이 받는 고객정보를 검색
--custom 테이블의 userid와 b (select문의 테이블)의 userid 비교
select * from CUSTOM
where userid in(
select userid from COMPANY
where pay >= (select avg(pay) from company));3. pairwise : 두개씩 비교
pairwise : 두개씩 비교
--부서번호가 30번인 직원의 급여와 보너스가 같은 사원을 검색
-- 두개씩 비교하는거 pay, nvl(bonus,0) : pairwise -반드시 괄호 ↓
select pname,dno,pay,nvl(bonus,0) from personnel where (pay,nvl(bonus,0))
in (select pay, nvl(bonus,0) from personnel where dno = 30);
select pay, nvl(bonus,0) from personnel where dno = 30; --부서번호가 30번인 사람의 pay,bonus4. dml (insert,update,delete)
dml
SELECT * FROM TAB;
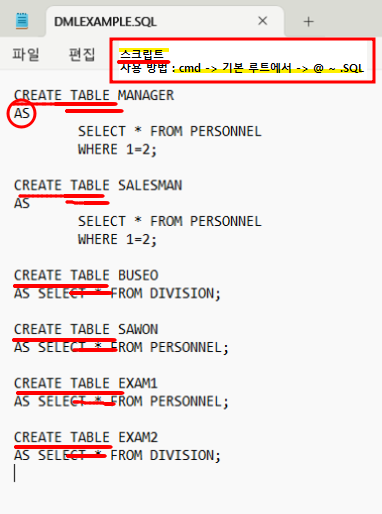
CREATE TABLE MANAGER
AS
SELECT * FROM PERSONNEL -- PERSONNEL 테이블의 구조를 MANAGER로 만들고 거짓이면 데이터는 안가져오고 기본 틀만 복사하는 명령어
WHERE 1=2;
SELECT * FROM MANAGER;
-----------------------------------------------------
CREATE TABLE SALESMAN
AS
SELECT * FROM PERSONNEL
WHERE 1=2;
SELECT * FROM SALESMAN;
-----------------------------------------------------
CREATE TABLE BUSEO
AS SELECT * FROM DIVISION; -- 한번씩 실행 한 후 아래꺼 실행해야함 / division 모든걸 복사해서 buseo에 복사해라
SELECT * FROM BUSEO;
-----------------------------------------------------
CREATE TABLE SAWON
AS SELECT * FROM PERSONNEL;
CREATE TABLE EXAM1
AS SELECT * FROM PERSONNEL;
CREATE TABLE EXAM2
AS SELECT * FROM DIVISION;
select * from tab;
select * from sawon;
select * from division;
--- --- --- --- --- --- --- --- --- --- -- --- --- --- --- --- --- -- --- ---
insert into division values (50, 'OPERATION','045-1234-1234','DAEGU'); -- 4개의 컬럼
select * from division;
desc division; --형식 확인
insert into division (dno) values (60);
select * from division;
insert into division (pname,position) values ('ACCOUNT','DAEJEON'); --에러 : dno는 NULL이 못들어감으로
insert into personnel (pno,pname,pay,dno) values (7711,'YOUNG',4000,20);
select * from personnel;--암시적 NULL 삽입 : 값을 명시적으로 NULL로 지정하지 않는 경우
desc personnel;
insert into division values (80, 'PLANNING', '063-1111-1111',NULL);--명시적 NULL 삽입 : 해당 열에 직접 NULL을 명시
select * from division;
insert into personnel (pno,pname,job,startdate,dno) values ('1234','YOU','salesman',sysdate,10); --꺼낼때 to_
select * from personnel; 스크립트 저장 방법 ①
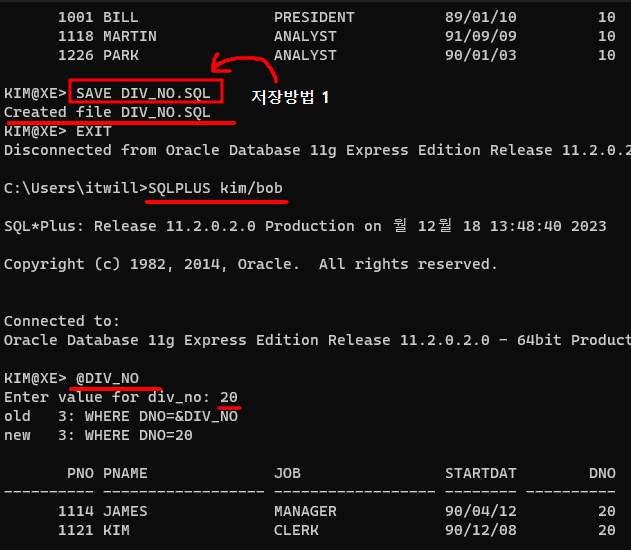
스크립트 저장 방법 ②
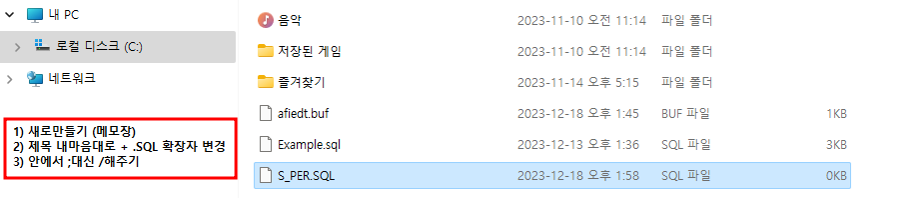
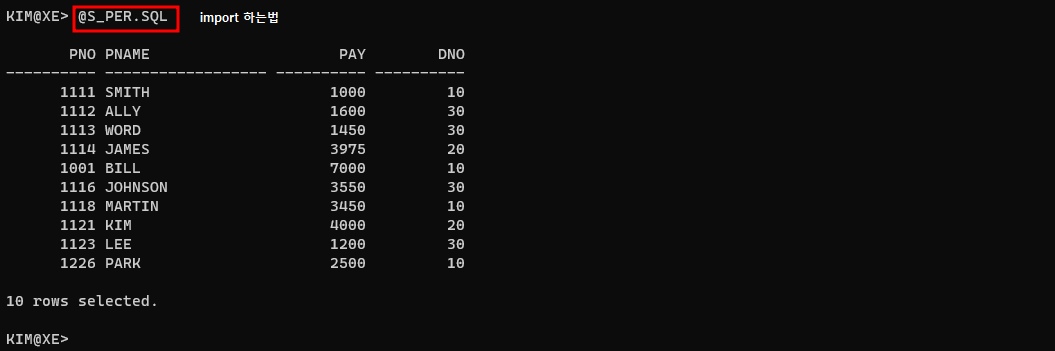
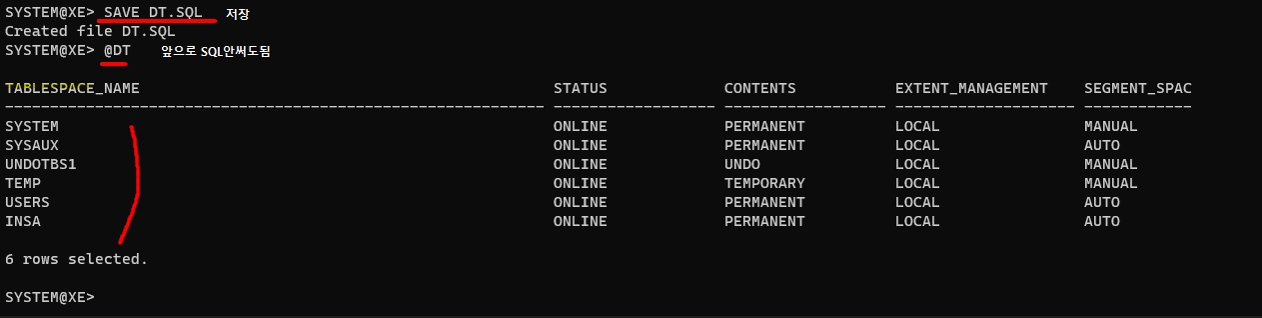
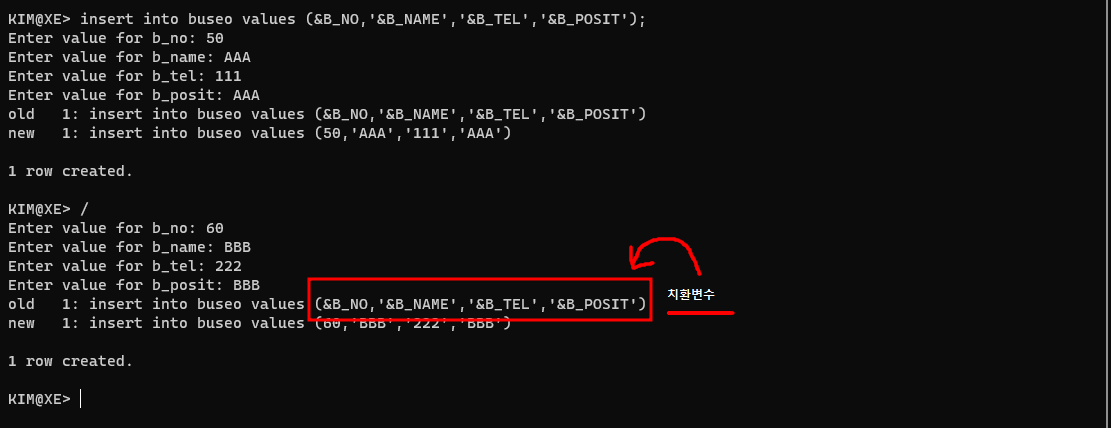
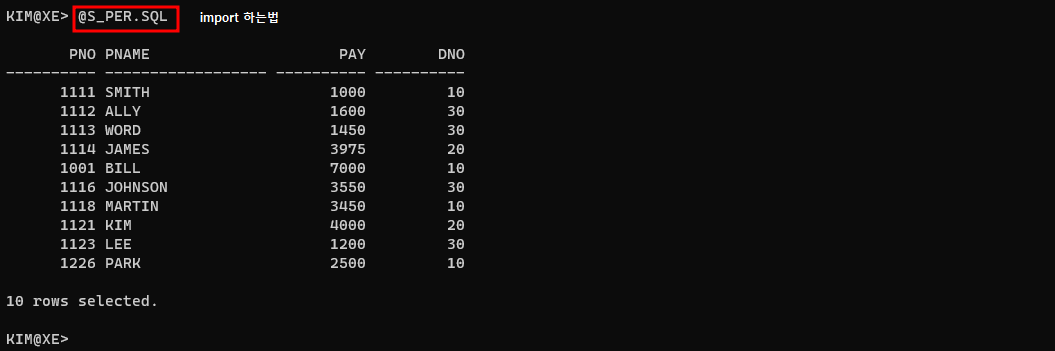
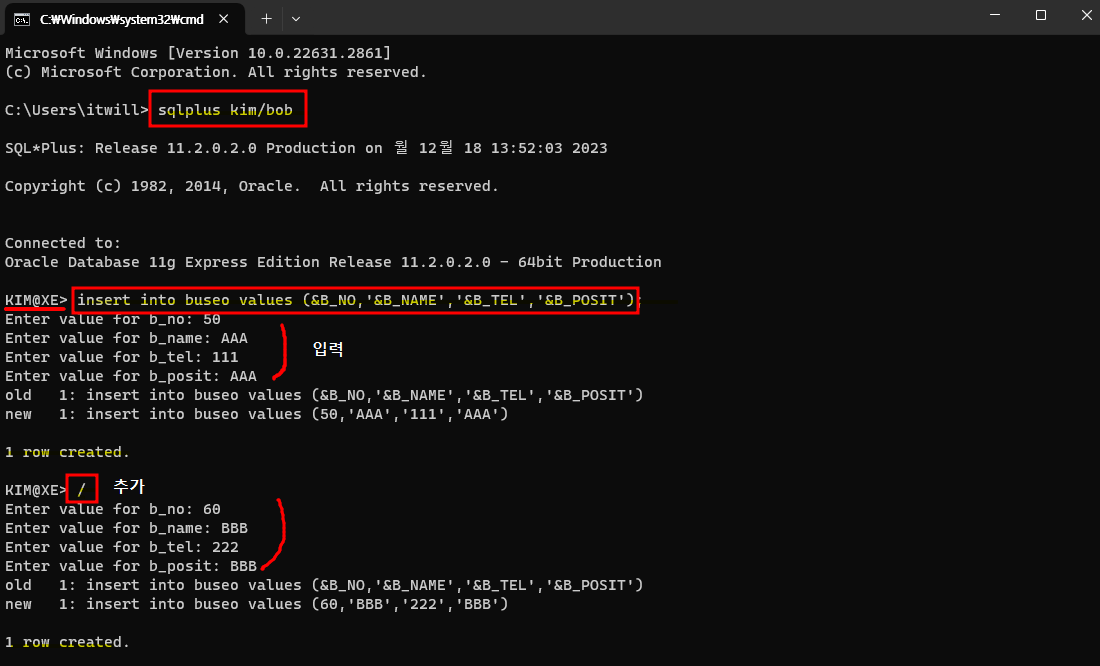
5. 치환변수
- 오라클에만 있음
치환변수
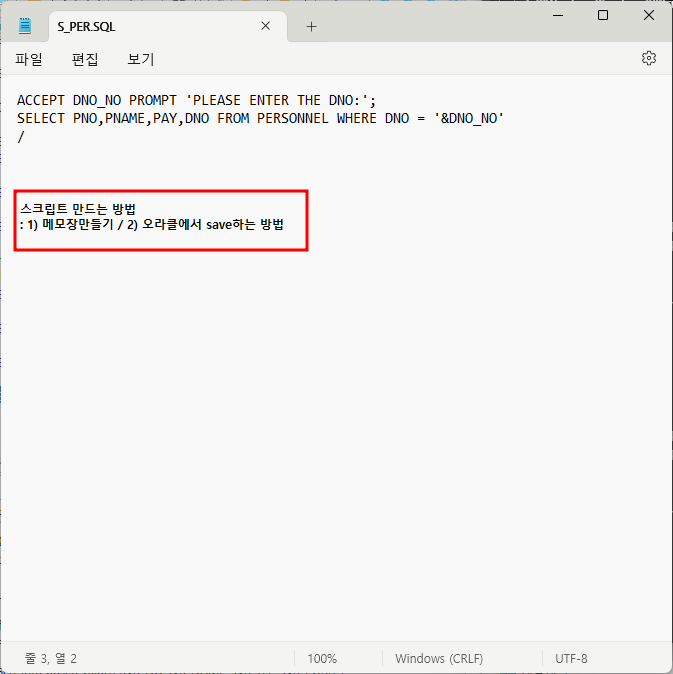
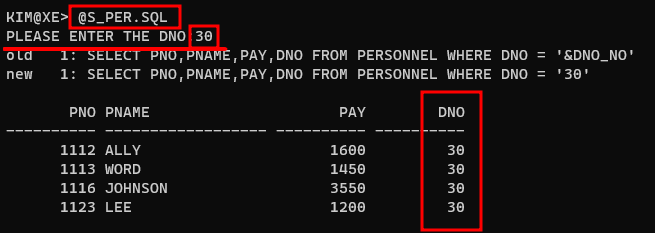
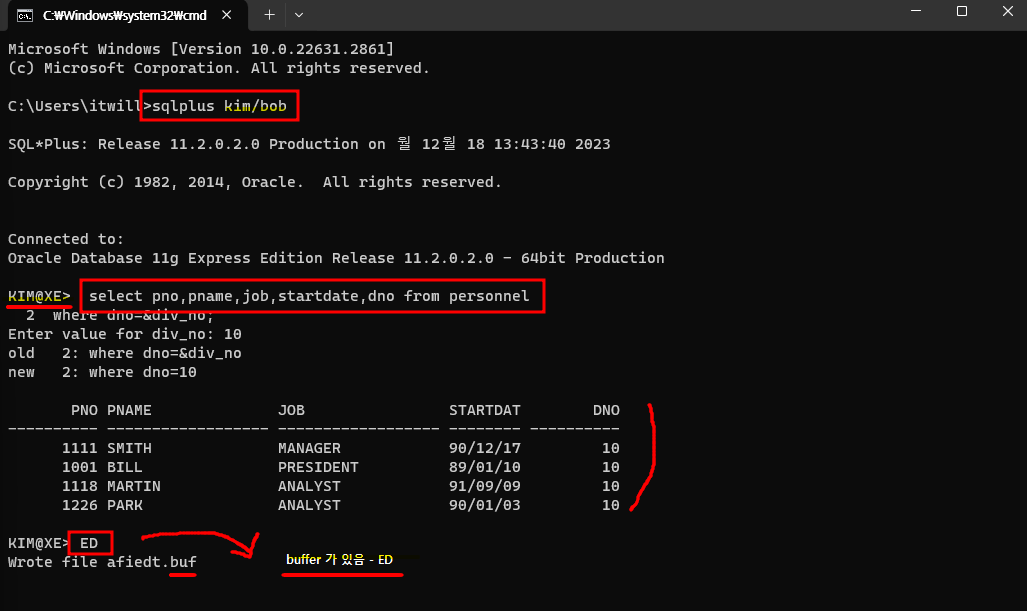
select pno,pname,job,startdate,dno from personnel where dno=&div_no; -- &div_no 치환변수
select * from buseo;
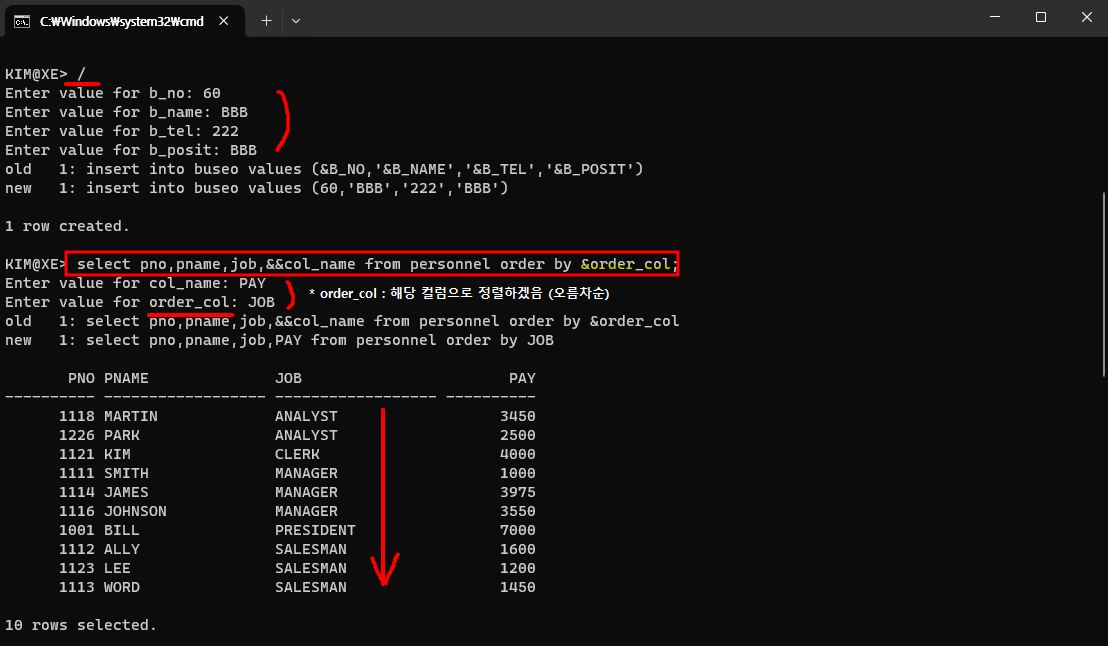
insert into buseo values (&B_NO,'&B_NAME','&B_TEL','&B_POSIT');
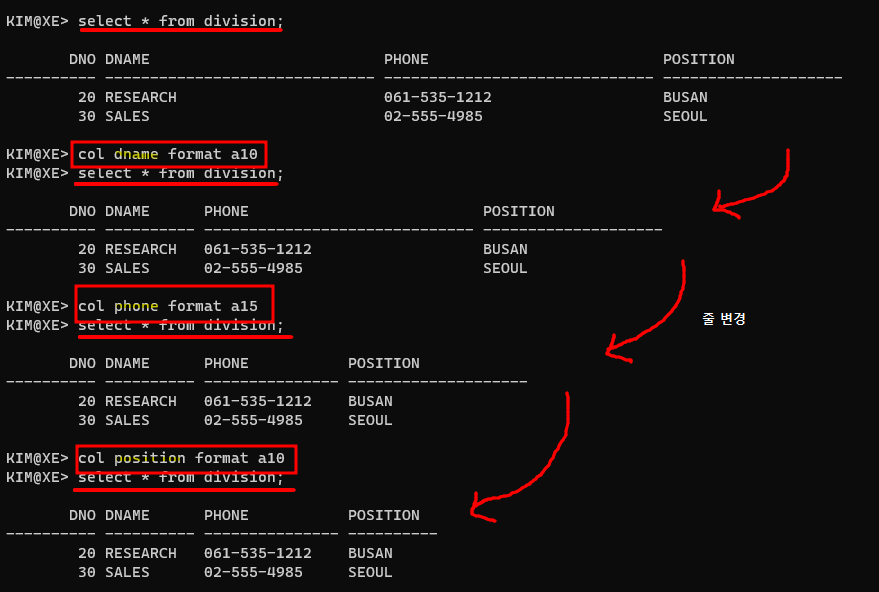
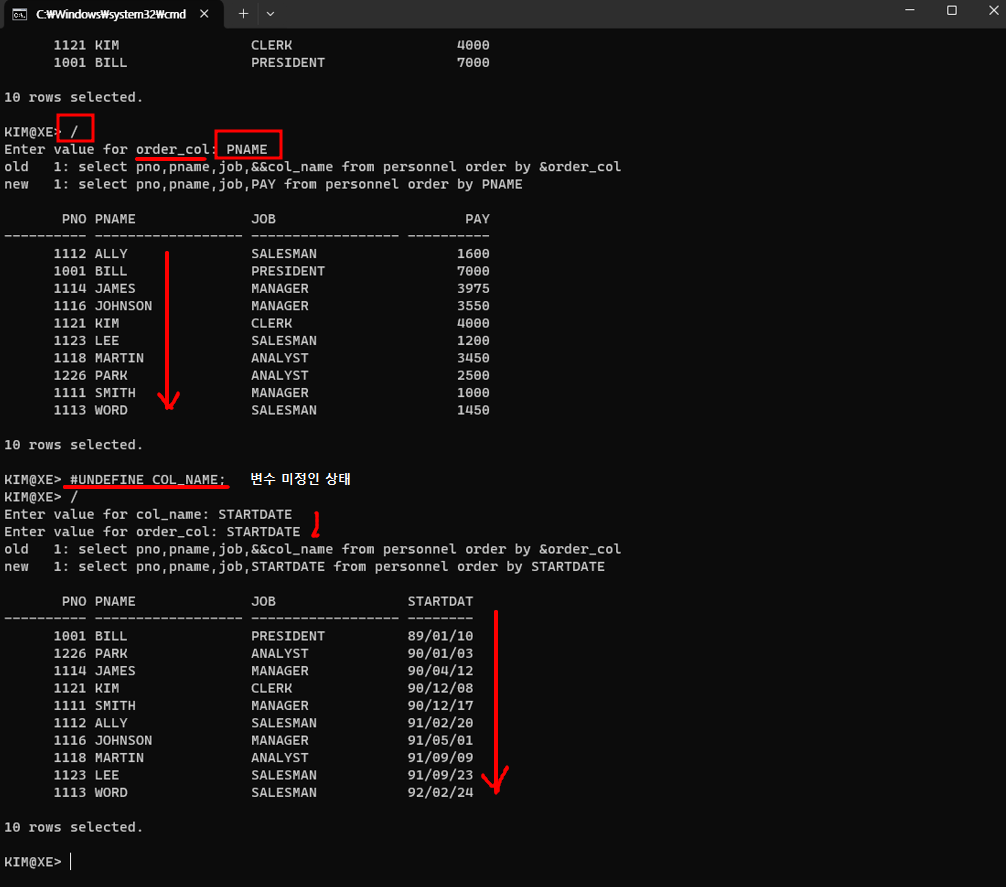
select pno,pname,job,&&col_name from personnel order by &order_col;6. system 관리자모드
system - 관리자모드
select * from dba_tablespaces; --관리자들이 보는 데이터- LOCAL = 오라클
select tablespace_name,status,contents,extent_management,segment_space_management from dba_tablespaces; --간단하게 원하는것만 추린것7. subquery : 이미 있는 table에 데이터 넣기
subquery
- 이미 있는 table에 데이터 넣겠음
select * from manager; -- 이미 MANAGER table이 있고
desc manager;
select * from personnel where job = 'MANAGER'; -- 그 상태에서 데이터 넣을건데,
insert into manager (pno,pname,pay,startdate) -- 내가 넣고자하는 컬럼에 넣겠다
select pno,pname,pay,startdate from personnel where job = 'MANAGER';
select * from manager;
select * from salesman;
insert into salesman -- 이미 있는 salesman에
select * from personnel where job = 'SALESMAN'; -- 넣는것 -----------------------???8. update + set + 조건문 필수
update : update + set + 조건문 필수
select * from personnel where pno = 1111; -- 먼저 데이터 있는지 확인
update personnel set dno = 30 where pno = 1111; --조건문 (변경 전 where절) 필수 !
update personnel set job = 'SALESMAN', manager = 7711, startdate = sysdate, pay = 5000, bonus = 2000 where pno = 1111;
select * from division;
select * from personnel where dno = 30;
select * from personnel where dno = (select dno from division where dname = 'SALES');
update personnel set job = 'SALESMAN' where dno = (select dno from division where dname = 'SALES');
select * from PERSONNEL
where dno in (select dno from division where dname = 'SALES');9. join문
join
select a.* from personnel a, division b
where a. dno = b.dno and dname = 'SALES';
--오라클,MY-SQL에서는 안되는데, 씨퀄서버에서는 가능
-- 하위쿼리를 JOIN문으로 바꾸고 -> UPDATE문도 가능
update personnel set job = 'SALESMAN'
from personnel a, division b
where a. dno = b.dno and dname = 'SALES';10. delete
delete : 삭제
select * from personnel where pno = 1111;
delete from personnel where pno = 1111; -- from 생략가능
delete from buseo;11. rollback / commit
rollback : 초기화 / commit : 저장
rollback;
select * from buseo;
select * from salesman;
select * from manager;
select * from personnel where dno = 30;
select * from personnel;
-----------------------------------------------------
--하위커리 활용해서 삭제하기
select * from personnel where dno = 10;
select dno from division where dname = 'FINANCE';
delete personnel where dno = (select dno from division where dname = 'FINANCE');
commit; -- 저장 (복구불가)12. insert / update / delete 에러
insert 에러
select * from personnel;
insert into personnel (pno,pname,dno)
values (1112,'SONG',99); -- 들어가지 못함 / 지금은 중복값 허용 x
-- Primary Key 특징 :
-- 1) null값 허용 x = NOT NULL
-- 2) 중복값 허용 x
-- 3) 오로지 table당 어떤 컬럼이던간에 1개만 만들 수 있음
select * from user_constraints; --constraints 제약조건 : 특정컬럼마다 제약조건 줄 수 있음
select * from personnel;
desc personnel;update 에러
select * from division;
select * from personnel;
--division 와 personnel은 연결되어있음 : Foriegn Key -personnel의 dno는 division의 dno 참조함
insert into personnel (pno,dno) values(1117,10); -- ㅇ 10번 부서는 있지만
insert into personnel (pno,dno) values(1117,50); -- x 50번 부서는 없기때문에
select * from user_constraints;
update personnel set dno = 50 where pno = 1117; -- x 50번 부서가 없어서
update personnel set dno = 20 where pno = 1117; -- ㅇ
select * from personnel;delete 에러
select * from division;
select * from personnel;
delete division where dno = 40; -- x personnel은 연결되어있어서 못지움
delete division where dno = 10; -- ㅇ
commit;-
transaction
-
insert / delete 할때 자동으로 transaction 함
-
여러개의 작업 ex) A -> B 계좌로 송금하는 여러작업
-
작업 중 에러생기면 : rollback / 완료 : commit / 반드시??
-
transaction lock : lock 걸면 뒤에 있는 얘한테 웨이팅번호

어제보다 조금 더 성장하기!